רגרסיה
הערה
עיין בכרטיסייה טקסט ותמונות לפרטים נוספים!
מודלים של רגרסיה מאומנים לחזות ערכי תוויות מספריות על סמך נתוני אימון הכוללים גם תכונות וגם תוויות ידועות. התהליך לאימון מודל רגרסיה (או למעשה, כל מודל למידת מכונה מפוקח) כולל איטרציות מרובות שבהן אתה משתמש באלגוריתם מתאים (בדרך כלל עם כמה הגדרות פרמטריות) כדי לאמן מודל, להעריך את ביצועי החיזוי של המודל ולחדד את המודל על ידי חזרה על תהליך האימון עם אלגוריתמים ופרמטרים שונים עד שתשיג רמה מקובלת של דיוק חזוי.
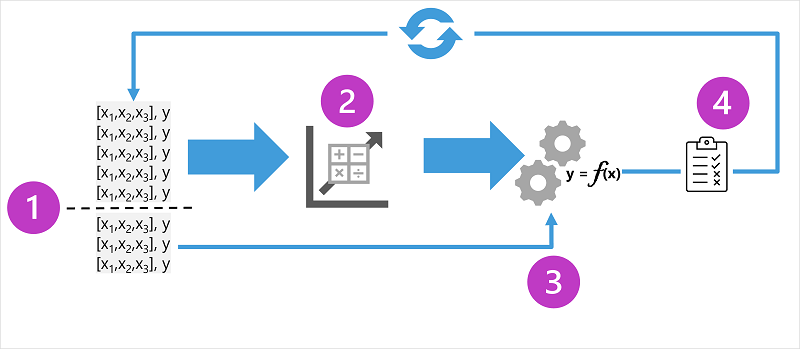
התרשים מציג ארבעה מרכיבים מרכזיים בתהליך ההדרכה עבור מודלים של למידת מכונה בפיקוח:
- פצל את נתוני האימון (באופן אקראי) כדי ליצור מערך נתונים שבעזרתו ניתן לאמן את המודל תוך עיכוב תת-קבוצה של הנתונים שבהם תשתמש כדי לאמת את המודל המאומן.
- השתמש באלגוריתם כדי להתאים את נתוני האימון למודל. במקרה של מודל רגרסיה, השתמש באלגוריתם רגרסיה כגון רגרסיה ליניארית.
- השתמש בנתוני האימות שהסתרת כדי לבדוק את המודל על-ידי חיזוי תוויות עבור התכונות.
- השווה את התוויות הידועות בפועל במערך נתוני האימות לתוויות שהמודל חזה. לאחר מכן צבור את ההבדלים בין ערכי התווית החזוייםוהממשיים כדי לחשב מדד המציין עד כמה מדויק המודל חזה עבור נתוני האימות.
לאחר כל אימון, אימות והערכה של איטרציה, אתה יכול לחזור על התהליך עם אלגוריתמים ופרמטרים שונים עד להשגת מדד הערכה מקובל.
דוגמה - רגרסיה
בואו נחקור רגרסיה עם דוגמה פשוטה שבה נאמן מודל לחזות תווית מספרית (y) על סמך ערך תכונה בודד (x). רוב התרחישים האמיתיים כוללים ערכי תכונות מרובים, מה שמוסיף מורכבות מסוימת; אבל העיקרון זהה.
לדוגמא שלנו, בואו נישאר עם תרחיש מכירת הגלידה שדיברנו עליו קודם. עבור התכונה שלנו, ניקח בחשבון את הטמפרטורה (נניח שהערך הוא הטמפרטורה המקסימלית ביום נתון), והתווית שאנו רוצים לאמן מודל לחזות היא מספר הגלידות שנמכרו באותו יום. נתחיל עם כמה נתונים היסטוריים הכוללים שיאים של טמפרטורות יומיות (x) ומכירות גלידה (y):

|

|
|---|---|
| טמפרטורה (x) | מכירת גלידה (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
אימון מודל רגרסיה
נתחיל בפיצול הנתונים ושימוש בתת-קבוצה שלהם כדי להכשיר מודל. להלן מערך נתוני האימון:
| טמפרטורה (x) | מכירת גלידה (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
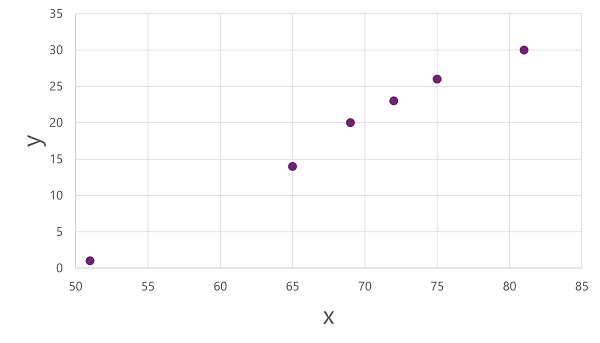
כדי לקבל תובנה כיצד ערכי xו-y אלה עשויים להיות קשורים זה לזה, אנו יכולים לשרטט אותם כקואורדינטות לאורך שני צירים, כך:
עכשיו אנחנו מוכנים להחיל אלגוריתם על נתוני האימון שלנו ולהתאים אותו לפונקציה שמפעילה פעולה על x כדי לחשב y. אלגוריתם אחד כזה הוא רגרסיה ליניארית, הפועלת על ידי גזירת פונקציה המייצרת קו ישר דרך ההצטלבויות של ערכי xו-y תוך מזעור המרחק הממוצע בין הקו לנקודות המשורטטות, כך:
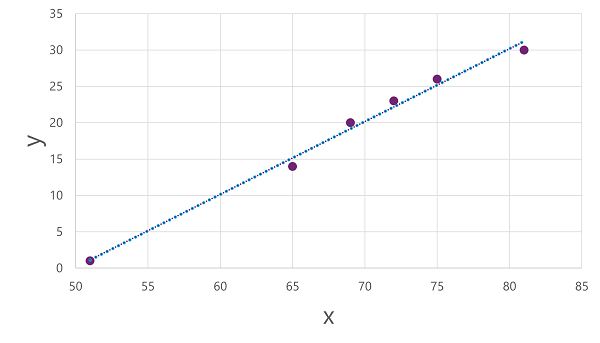
הקו הוא ייצוג חזותי של הפונקציה שבה שיפוע הקו מתאר כיצד לחשב את הערך של y עבור ערך נתון של x. הקו מיירט את ציר ה-x ב-50, כך שכאשר x הוא 50, y הוא 0. כפי שניתן לראות מסמני הציר בתרשים, הקו משתפל כך שכל עלייה של 5 לאורך ציר ה-x מביאה לעלייה של 5 במעלה ציר ה-y ; אז כאשר x הוא 55, y הוא 5; כאשר x הוא 60, y הוא 10 וכן הלאה. כדי לחשב ערך של y עבור ערך נתון של x, הפונקציה פשוט מחסירה 50; במילים אחרות, ניתן לבטא את הפונקציה כך:
f(x) = x-50
אתה יכול להשתמש בפונקציה זו כדי לחזות את מספר הגלידות שנמכרות ביום עם כל טמפרטורה נתונה. לדוגמה, נניח שתחזית מזג האוויר אומרת לנו שמחר זה יהיה 77 מעלות. אנחנו יכולים ליישם את המודל שלנו כדי לחשב 77-50 ולחזות שמחר נמכור 27 גלידות.
אבל עד כמה המודל שלנו מדויק?
הערכת מודל רגרסיה
כדי לאמת את המודל ולהעריך עד כמה הוא חוזה, שמרנו כמה נתונים שעבורם אנו יודעים את ערך התווית (y). הנה הנתונים ששמרנו:
| טמפרטורה (x) | מכירת גלידה (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
אנו יכולים להשתמש במודל כדי לחזות את התווית עבור כל אחת מהתצפיות במערך נתונים זה על סמך ערך התכונה (x); ולאחר מכן השווה את התווית החזויה (ŷ) לערך התווית הידוע בפועל (Y).
שימוש במודל שאימנו קודם לכן, המקיף את הפונקציה f(x) = x-50, מביא לתחזיות הבאות:
| טמפרטורה (x) | מכירות בפועל (y) | מכירות חזויות (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
אנו יכולים להתוות הן את התוויות החזויות והן את התוויות בפועל מול ערכי התכונה כך:
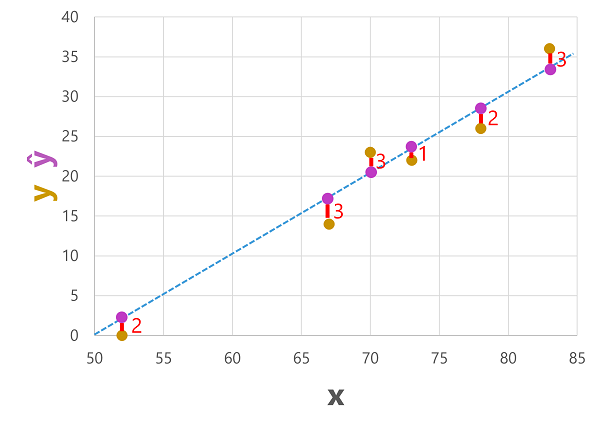
התוויות החזויות מחושבות על ידי המודל כך שהן נמצאות בשורת הפונקציה, אך יש שונות מסוימת בין ערכי ŷ המחושבים על ידי הפונקציה לבין ערכי y בפועל ממערך נתוני האימות; המסומן בתרשים כקו בין ערכי Ŷו-Y שמראה עד כמה החיזוי היה רחוק מהערך בפועל.
מדדי הערכת רגרסיה
בהתבסס על ההבדלים בין הערכים החזויים לערכים בפועל, אתה יכול לחשב כמה מדדים נפוצים המשמשים להערכת מודל רגרסיה.
שגיאה מוחלטת ממוצעת (MAE)
השונות בדוגמה הזו מצביעה על ידי כמה גלידות כל תחזית הייתה שגויה. אין זה משנה אם החיזוי היה מעל או מתחת לערך בפועל (כך למשל, -3 ו- +3 מציינים שניהם שונות של 3). מדד זה ידוע כשגיאה המוחלטת עבור כל חיזוי, וניתן לסכם אותו עבור כל קבוצת האימות כשגיאה המוחלטת הממוצעת (MAE).
בדוגמת הגלידה, הממוצע (הממוצע) של השגיאות המוחלטות (2, 3, 3, 1, 2 ו-3) הוא 2.33.
שגיאה ממוצעת בריבוע (MSE)
מדד השגיאה המוחלטת הממוצעת לוקח בחשבון את כל הפערים בין התוויות החזויות לתוויות בפועל באופן שווה. עם זאת, ייתכן שרצוי יותר שיהיה מודל שגוי באופן עקבי בכמות קטנה מאשר מודל שעושה פחות שגיאות אך גדולות יותר. דרך אחת לייצר מדד ש"מגביר" שגיאות גדולות יותר על ידי ריבוע השגיאות הבודדות וחישוב הממוצע של הערכים בריבוע. מדד זה ידוע בשם השגיאה הריבועית הממוצעת (MSE).
בדוגמת הגלידה שלנו, הממוצע של הערכים המוחלטים בריבוע (שהם 4, 9, 9, 1, 4 ו-9) הוא 6.
שגיאת שורש ממוצע בריבוע (RMSE)
השגיאה הריבועית הממוצעת עוזרת לקחת בחשבון את גודל השגיאות, אך מכיוון שהיא מרובע את ערכי השגיאה, המדד המתקבל כבר לא מייצג את הכמות הנמדדת על ידי התווית. במילים אחרות, אנו יכולים לומר שה-MSE של המודל שלנו הוא 6, אבל זה לא מודד את הדיוק שלו במונחים של מספר הגלידות שנחזו באופן שגוי; 6 הוא רק ציון מספרי המציין את רמת השגיאה בתחזיות האימות.
אם אנו רוצים למדוד את השגיאה במונחים של מספר הגלידות, עלינו לחשב את השורש הריבועי של ה-MSE; שמייצר מדד שנקרא, באופן לא מפתיע, שגיאה בריבוע שורש ממוצע. במקרה זה √6, שהם 2.45 (גלידות).
מקדם קביעה (R2)
כל המדדים עד כה משווים את הפער בין הערכים החזויים לערכים בפועל על מנת להעריך את המודל. עם זאת, במציאות, יש שונות אקראית טבעית במכירות היומיות של גלידה שהמודל לוקח בחשבון. במודל רגרסיה ליניארית, אלגוריתם האימון מתאים לקו ישר הממזער את השונות הממוצעת בין הפונקציה לערכי התווית הידועים. מקדם הקביעה (המכונה בדרך כלל R2 או R-Squared) הוא מדד המודד את שיעור השונות בתוצאות האימות שניתן להסביר על ידי המודל, בניגוד להיבט חריג כלשהו של נתוני האימות (לדוגמה, יום עם מספר חריג מאוד של מכירות גלידות בגלל פסטיבל מקומי).
החישוב עבור R2 מורכב יותר מאשר עבור המדדים הקודמים. הוא משווה את סכום ההבדלים בריבוע בין תוויות חזויות לתוויות בפועל עם סכום ההבדלים בריבוע בין ערכי התווית בפועל והממוצע של ערכי התווית בפועל, כך:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
אל תדאג יותר מדי אם זה נראה מסובך; רוב כלי למידת המכונה יכולים לחשב את המדד עבורך. הנקודה החשובה היא שהתוצאה היא ערך בין 0 ל-1 המתאר את שיעור השונות המוסבר על ידי המודל. במילים פשוטות, ככל שערך זה קרוב יותר ל-1, כך המודל מתאים יותר לנתוני האימות. במקרה של מודל רגרסיית הגלידה, ה-R2 המחושב מנתוני האימות הוא 0.95.
אימון איטרטיבי
המדדים שתוארו לעיל משמשים בדרך כלל להערכת מודל רגרסיה. ברוב התרחישים בעולם האמיתי, מדען נתונים ישתמש בתהליך איטרטיבי כדי לאמן ולהעריך שוב ושוב מודל, המשתנה:
- בחירה והכנה של תכונות (בחירת התכונות שיש לכלול במודל, וחישובים המיושמים עליהן כדי להבטיח התאמה טובה יותר).
- בחירת אלגוריתם (חקרנו רגרסיה ליניארית בדוגמה הקודמת, אך ישנם אלגוריתמי רגרסיה רבים אחרים)
- פרמטרים של אלגוריתם (הגדרות מספריות לשליטה בהתנהגות האלגוריתם, הנקראות באופן מדויק יותר היפרפרמטרים כדי להבדיל בינם לבין הפרמטרים xו-y ).
לאחר חזרות מרובות, נבחר המודל שמביא למדד ההערכה הטוב ביותר המקובל עבור התרחיש הספציפי.