סיווג בינארי
הערה
עיין בכרטיסייה טקסט ותמונות לפרטים נוספים!
סיווג, כמו רגרסיה, הוא טכניקה פיקוח של למידת מכונה; ולכן פועל בהתאם לאותו תהליך איטרטיבי של הדרכה, אימות והערכה של מודלים. במקום לחשב ערכים מספריים כמו מודל רגרסיה, האלגוריתמים המשמשים לתרגל מודלי סיווג מחשבים ערכי הסתברות עבור הקצאת מחלקה ואת מדדי ההערכה המשמשים להערכת ביצועי המודל, משווים את הכיתות החזויות לכיתות בפועל.
אלגוריתמים של סיווג בינארי משמשים להכשרת מודל שמנבא אחת משתי תוויות אפשריות עבור מחלקה אחת. במהותו, חיזוי True או False. ברוב התרחישים האמיתיים, תצפיות הנתונים המשמשות לתרגל ולאימות המודל מורכבות מערכים מרובים של תכונות (x) וערך y שהוא 1 או 0.
Example - סיווג בינארי
כדי להבין כיצד הסיווג הבינארי פועל, בוא נבחן דוגמה פשוטה המשתמשת בתכונה אחת (x) כדי לחזות אם התווית y היא 1 או 0. בדוגמה זו, נשתמש ברמת הגלוקוז בדם של מטופל כדי לחזות אם לחולה יש סוכרת או לא. הנה הנתונים שבהם נדריך את המודל:

|

|
|---|---|
| גלוקוז בדם (x) | סוכרת? (y) אני לא יכול לעשות את זה. |
| 67 | 0 |
| 103 | 1 |
| 114 | 1 |
| 72 | 0 |
| 116 | 1 |
| 65 | 0 |
הדרכת מודל סיווג בינארי
כדי לתרגל את המודל, נשתמש באלגוריתם כדי להתאים את נתוני ההדרכה לפונקציה המחשבת את ההסתברות שתווית הכיתה אמת (במילים אחרות, שיש למטופל סוכרת). ההסתברות נמדדת כערך בין 0.0 ל- 1.0, כך שההסתברות הכוללת עבור כל הכיתות האפשריות היא 1.0. לכן, לדוגמה, אם ההסתברות לסוכרת למטופל היא 0.7, קיימת הסתברות מקבילה של 0.3 שהמטופל אינו חולה סוכרת.
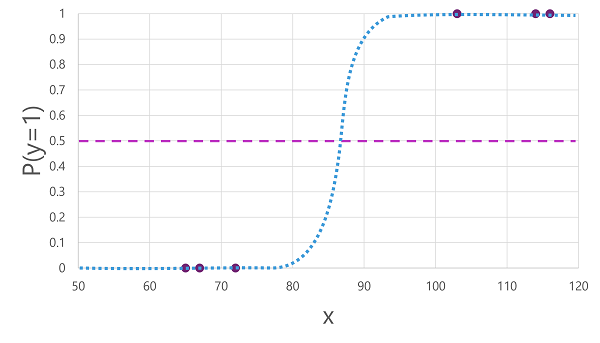
קיימים אלגוריתמים רבים שניתן להשתמש בהם לסיווג בינארי, כגון רגרסיה לוגיסטית , אשר מפיקה פונקציית sigmoid (בצורת S) עם ערכים בין 0.0 ל- 1.0, באופן הבא:
הערה
למרות שמו, רגרסיה לוגיסטית של למידת מכונה משמשת עבור סיווג, לא רגרסיה. הנקודה החשובה היא אופיה הלוגיסטי של הפונקציה שהיא מפיקה, המתארת עקומה בצורת S בין ערך תחתון לערך עליון (0.0 ו- 1.0 בעת שימוש עבור סיווג בינארי).
הפונקציה שיוצרת האלגוריתם מתארת את ההסתברות ש- y הוא true (y=1) עבור ערך נתון של x. מבחינה מתמטית, באפשרותך לבטא את הפונקציה כך:
f(x) = P(y=1 | x)
עבור שלוש מתוך שש התצפיות נתוני האימון, אנו יודעים ש- y הוא true בוודאות , ולכן ההסתברות לתצפיות אלה היא ש- y=1 הוא 1.0 ובשלושה האחרים, אנו יודעים ש- y הוא ללא ספק False, ולכן ההסתברות ש- y=1 הוא 0.0. העקומה בצורת S מתארת את התפלגות ההסתברות כך שהתווה ערך של x בשורה מזהה את ההסתברות התואמת ש- y הוא 1.
הדיאגרמה כוללת גם קו אופקי כדי לציין את הסף שבו מודל המבוסס על פונקציה זו ינבא True (1) או False (0). הסף נמצא באמצע הנקודה עבור y (P(y) = 0.5). עבור ערכים בנקודה זו ואילך, המודל ינבא True (1); בעוד שעבור ערכים מתחת לנקודה זו, הוא ינבא False (0). לדוגמה, עבור חולה עם רמת גלוקוז בדם של 90, הפונקציה תגרום לערך הסתברות של 0.9. מאחר ש- 0.9 גבוה מהסף של 0.5, המודל ינבא True (1) במילים אחרות, החולה צפוי לקבל סוכרת.
הערכת מודל סיווג בינארי
בדומה לנסיגה, בעת תרגול מודל סיווג בינארי, אתה מחזיק בחזקת קבוצת משנה אקראית של נתונים שבה יש לאמת את המודל המוכשרת. נניח שהחזקנו את הנתונים הבאים כדי לאמת את מסווג הסכרת שלנו:
| גלוקוז בדם (x) | סוכרת? (y) אני לא יכול לעשות את זה. |
|---|---|
| 66 | 0 |
| 107 | 1 |
| 112 | 1 |
| 71 | 0 |
| 87 | 1 |
| 89 | 1 |
החלת הפונקציה הלוגיסטית שגזרנו קודם לכן על ערכי x התוצאה היא התוויית הנתונים הבאה.
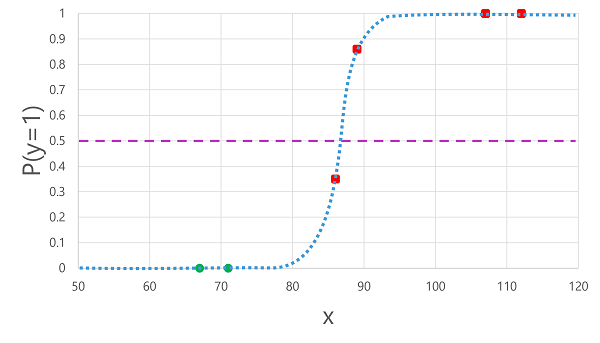
בהתבסס על ההסתברות שחושבה על-ידי הפונקציה מעל או מתחת לסף, המודל יוצר תווית צפויה של 1 או 0 עבור כל תצפית. לאחר מכן נוכל להשוות את תוויות המחלקה החזויות () לתוויותהמחלקה בפועל (y), כפי שמוצג כאן:
| גלוקוז בדם (x) | אבחון סוכרת בפועל (y) | אבחון סוכרת חזותית () |
|---|---|---|
| 66 | 0 | 0 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 0 | 0 |
| 87 | 1 | 0 |
| 89 | 1 | 1 |
מדדי הערכת סיווג בינאריים
השלב הראשון בחישוב מדדי הערכה עבור מודל סיווג בינארי הוא בדרך כלל יצירת מטריצה של מספר החיזויים הנכונים והחיזויים השגויים עבור כל תווית מחלקה אפשרית:
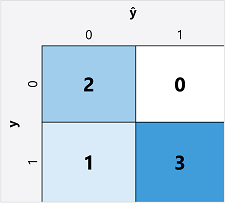
פריט חזותי זה נקרא מטריצת בלבול, והוא מציג את סכומי החיזוי שבהם:
- =0 ו- y=0: שליליים אמיתיים (TN)
- =1 ו- y=0: תוצאות חיוביות מוטעות (FP)
- =0 ו- y=1: שליליות מוטעות (FN)
- =1 ו- y=1: תוצאות חיוביות True (TP)
הסידור של מטריצת הבלבול הוא כך שתחזיות נכונות (True) מוצגות בקו אלכסוני מקצה עליון שמאלי לקצה הימני התחתון. לעתים קרובות, חוזק הצבע משמש לציון מספר החיזויים בכל תא, כך שמבט מהיר על מודל שמנבא היטב אמור לחשוף מגמה אלכסונית מוצלת מאוד.
דיוק
המדד הפשוט ביותר שניתן לחשב ממטריצת הבלבול הוא דיוק - שיעור החיזויים שהמודל קיבל נכון. הדיוק מחושב באופן הבא:
(TN+TP) ÷ (TN+FN+FP+TP)
במקרה של סוכרת שלנו דוגמה, החישוב הוא:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
לכן, עבור נתוני האימות שלנו, מודל סיווג הסכרת יצר חיזויים נכונים 83% של הזמן.
רמת הדיוק עשויה תחילה להיראות כמו מדד טוב להערכה של מודל, אך שקול זאת. נניח של-11% האוכלוסייה יש סוכרת. באפשרותך ליצור מודל שמנבא תמיד 0, והוא ישיג דיוק של 89%, למרות שהוא לא מנסה ממשי להבחין בין המטופלים על-ידי הערכת התכונות שלהם. מה שאנחנו באמת צריכים הוא הבנה עמוקה יותר של הביצועים של המודל בחיזוי 1 עבור מקרים חיוביים ו- 0 עבור מקרים שליליים.
זוכר
האחזור הוא מדד המודד את היחס בין מקרים חיוביים שהמודל זיהה כראוי. במילים אחרות, בהשוואה למספר המטופלים שיש להם סוכרת, כמה מהדגם ניזוי להיות סוכרת?
הנוסחה לאחזור היא:
TP ÷ (TP+FN)
לדוגמה, סוכרת:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
אז הדגם שלנו זיהה כראוי 75% מטופלים שיש להם סוכרת כמו סוכרת.
דיוק
דיוק הוא מדד דומה לאחזור, אך מודדת את החלק היחסי של מקרים חיוביים חזויים שבהם התווית האמיתית חיובית בפועל. במילים אחרות, איזה חלק של המטופלים חזו על ידי המודל לקבל סוכרת בעצם יש סוכרת?
הנוסחה לקבלת דיוק היא:
TP ÷ (TP+FP)
לדוגמה, סוכרת:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
אז 100% של המטופלים שנבא המודל שלנו שיש סוכרת לעשות למעשה סוכרת.
F1-score
F1-score הוא מדד כללי המשלב אחזור ודיוק. הנוסחה עבור F1-score היא:
(2 x דיוק x אחזור) ÷ (דיוק + אחזור)
לדוגמה, סוכרת:
(2 x 1.0 x 0.75) ÷ (1.0 + 0.75)
= 1.5 ÷ 1.75
מספר הנוסחה = 0.86
שטח מתחת לעקומת (AUC)
שם אחר לאחזור הוא שיעור חיובי אמיתי ( TPR), ויש מדד שווה ערך שנקרא שיעור חיובי מוטעה ( FPR) המחושב כ - FP÷(FP+TN). אנחנו כבר יודעים שה- TPR עבור המודל שלנו בעת שימוש בסף של 0.5 הוא 0.75, ואנחנו יכולים להשתמש בנוסחה עבור FPR כדי לחשב ערך של 0÷2 = 0.
כמובן, אם נשנה את הסף שמעליו המודל מנבא אמת (1), הוא ישפיע על מספר התחזיות החיוביות והשלילית; לכן, שנה את מדדי TPR ו- FPR. מדדים אלה משמשים לעתים קרובות להערכת מודל על-ידי התוויית עקומת מאפייני אופרטור שהתקבלה ( ROC) משווה בין TPR ל- FPR עבור כל ערך סף אפשרי בין 0.0 ל- 1.0:
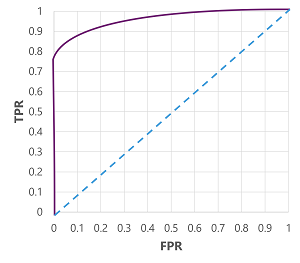
עקומה ROC עבור מודל מושלם תרוצץ ישר לאורך ציר ה- TPR בצד שמאל ולאחר מכן לאורך ציר ה- FPR בחלק העליון. מאחר שאזור התוויית הנתונים עבור העקומה מודדת 1x1, האזור תחת עקומה מושלמת זו יהיה 1.0 (כלומר, המודל נכון ל- 100% של הזמן). לעומת זאת, קו אלכסוני מהקצה השמאלי התחתון לימין העליון מייצג את התוצאות שניתן להשיג באמצעות ניחוש אקראי של תווית בינארית; הפקת שטח תחת העקומה של 0.5. במילים אחרות, בהינתן שתי תוויות כיתה אפשריות, סביר להניח ש- 50% נכון של הזמן.
במקרה של מודל הסכרת שלנו, העקומת לעיל מופקת, והאזור מתחת למדד העקומה ( AUC) הוא 0.875. מאחר ש- AUC גבוהה מ- 0.5, אנו יכולים להסיק שהמודל פועל טוב יותר בחיזוי אם לחולה יש סוכרת או לא מאשר ניחוש אקראי.