סיווג מרובה מחלקה
הערה
עיין בכרטיסייה טקסט ותמונות לפרטים נוספים!
סיווג מרובה מחלקות משמש לחיזוי הכיתות האפשריות מרובות שאליהן משתייכת תצפית. כטכניקה פיקוח של למידת מכונה, היא פועלת בהתאם לאותה רכבת איטרטיבית , אימות והערכה של תהליך כסווג רגרסיה וסיווג בינארי שבו קבוצת משנה של נתוני ההדרכה מוחזקת מאחור כדי לאמת את המודל המוכשר.
דוגמה - סיווג מרובה מחלקה
אלגוריתמים לסווג ברמה מרובת משמשים לחישוב ערכי הסתברות עבור תוויות מחלקה מרובות, ומאפשרים למודל לחזות את המחלקה הסבירה ביותר עבור תצפית נתונה.
בואו לחקור דוגמה שבה יש לנו כמה תצפיות של פינגווינים, שבו אורך הסנפירים (x) של כל פינגווין מתועד. עבור כל תצפית, הנתונים כוללים את זן הפינגווין (y), המקודד באופן הבא:
- 0: אדלי
- 1: גנטו
- 2: צ'ינסטריפ
הערה
בדומה בדוגמאות קודמות במודול זה, תרחיש אמיתי יכלול ערכי תכונות (x) מרובים. נשתמש בתכונה אחת כדי לשמור על פריטים פשוטים.
|

|
|---|---|
| אורך סנפיר (x) | זנים (y) |
| 167 | 0 |
| 172 | 0 |
| 225 | 2 |
| 197 | 1 |
| 189 | 1 |
| 232 | 2 |
| 158 | 0 |
הדרכת מודל סיווג מרובה מחלקה
כדי להכשיר מודל סיווג רב-מחלקתי, עלינו להשתמש באלגוריתם כדי להתאים את נתוני ההדרכה לפונקציה המחשבת ערך הסתברות עבור כל מחלקה אפשרית. קיימים שני סוגים של אלגוריתמים שבהם ניתן להשתמש כדי לעשות זאת:
- אלגוריתמים של One-vs-Rest (OvR)
- אלגוריתמים רב-גורמיים
אלגוריתמים של One-vs-Rest (OvR)
אלגוריתמים של One-vs-Rest מסמנים פונקציית סיווג בינארי עבור כל מחלקה, כאשר כל אחד מהם מחשב את ההסתברות שתצפית היא דוגמה של מחלקת היעד. כל פונקציה מחשבת את ההסתברות של התצפית להיות מחלקה ספציפית בהשוואה לכל מחלקה אחרת. עבור מודל הסיווג של המין הפינגווין שלנו, האלגוריתם ייצור למעשה שלוש פונקציות סיווג בינאריות:
- f0(x) = P(y=0 | x)
- f1(x) = P(y=1 | x)
- f2(x) = P(y=2 | x)
כל אלגוריתם יוצר פונקציית sigmoid המחשבת ערך הסתברות בין 0.0 ל- 1.0. מודל המוכשרת באמצעות אלגוריתם מסוג זה מנבא את המחלקה עבור הפונקציה המפיקה את פלט ההסתברות הגבוה ביותר.
אלגוריתמים רב-גורמיים
כגישה חלופית, השתמש באלגוריתם רב-אומיאלי, אשר יוצר פונקציה יחידה המחזירה פלט מרובה ערכים. הפלט הוא וקטור (מערך של ערכים) המכיל את התפלגות ההסתברות עבור כל המחלקות האפשריות - עם ניקוד הסתברות עבור כל מחלקה, כאשר הסכום מסתכם עד 1.0:
f(x) =[P(y=0|x), P(y=1|x), P(y=2|x)]
דוגמה לפונקציה מסוג זה היא פונקציית softmax , שעשויה ליצור פלט כמו בדוגמה הבאה:
[0.2, 0.3, 0.5]
הרכיבים בווקטור מייצגים את ההסתברות עבור מחלקות 0, 1 ו- 2 בהתאמה; לכן, במקרה זה, המחלקה עם ההסתברות הגבוהה ביותר היא 2.
ללא קשר לסוג האלגוריתם שבו נעשה שימוש, המודל משתמש בפונקציה המתוצאת כדי לקבוע את המחלקה הצפויה ביותר עבור קבוצה נתונה של תכונות (x) ולנבא את תווית המחלקה המתאימה (y).
הערכת מודל סיווג מרובה מחלקה
באפשרותך להעריך מסווג מרובה מחלקה על-ידי חישוב מדדי סיווג בינארי עבור כל מחלקה בודדת. לחלופין, באפשרותך לחשב מדדים מצטברים שמחשבים את כל הכיתות.
נניח שאומתנו את מסווג Multiclass שלנו, וששגנו את התוצאות הבאות:
| אורך סנפיר (x) | זנים בפועל (y) | מינים חזויים () |
|---|---|---|
| 165 | 0 | 0 |
| 171 | 0 | 0 |
| 205 | 2 | 1 |
| 195 | 1 | 1 |
| 183 | 1 | 1 |
| 221 | 2 | 2 |
| 214 | 2 | 2 |
מטריצת הבלבול עבור מסווג מרובה מחלקה דומה לזה של מסווג בינארי, למעט העובדה שהיא מציגה את מספר החיזויים עבור כל שילוב של תוויות מחלקה חזויות (y) ותוויות מחלקה בפועל (y):
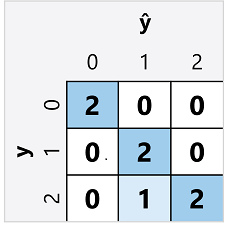
מתוך מטריצת בלבול זו, אנו יכולים לקבוע את המדדים עבור כל מחלקה בודדת באופן הבא:
| מחלקה | חיובי אמיתי | שלילי אמיתי | תוצאה חיובית מוטעית | שלילי כוזב | דיוק | זוכר | דיוק | F1-Score |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 5 | 0 | 0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 2 | 4 | 1 | 0 | 0.86 | 1.0 | 0.67 | 0.8 |
| 2 | 2 | 4 | 0 | 1 | 0.86 | 0.67 | 1.0 | 0.8 |
כדי לחשב את מדדי הדיוק, האחזור והדיוק הכוללים, עליך להשתמש בסכום הכולל של מדדי TP, TN, FP ו- FN :
- דיוק כללי = (13+6)÷(13+6+1+1) = 0.90
- אחזור כללי = 6÷(6+1) = 0.86
- דיוק כללי = 6÷(6+1) = 0.86
הציון הכולל של F1 מחושב באמצעות מדדי האחזור והמדויק הכוללים:
- כללי F1-score = (2x0.86x0.86)÷(0.86+0.86) = 0.86