למידה עמוקה
הערה
עיין בכרטיסייה טקסט ותמונות לפרטים נוספים!
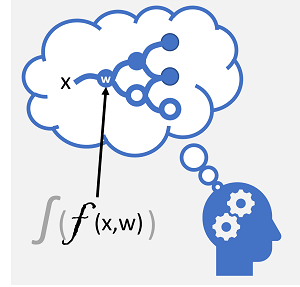
למידה עמוקה היא צורה מתקדמת של למידת מכונה שמנסה לחקות את האופן שבו המוח האנושי לומד. המפתח ללמידה עמוקה הוא יצירת רשת עצבית מלאכותית המדמה פעילות אלקטרוכימית בנוירונים ביולוגים באמצעות פונקציות מתמטיות, כפי שמוצג כאן.
| רשת עצבית ביולוגית | רשת עצבית מלאכותית |
|---|---|

|
|
| נוירונים אש בתגובה לגירוי אלקטרוכימי. כאשר הוא מופעל, האות מועבר לנוירונים מחוברים. | כל נוירון הוא פונקציה הפועלת על ערך קלט (x) ועל משקל (w). הפונקציה גולשת בפונקציית הפעלה הקובעת אם להעביר את הפלט. |
רשתות עצביות מלאכותיות מורכבות משכבות מרובות של נוירונים - למעשה הגדרה של פונקציה מקוננת עמוקה. ארכיטקטורה זו היא הסיבה שהשיטה נקראת למידה עמוקה והמודלים המיוצרים על-ידיה נקראים לעתים קרובות רשתות עצביות עמוקות (DNN). באפשרותך להשתמש ברשתות עצביות עמוקות עבור סוגים רבים של בעיות בלמידת מכונה, כולל רגרסיה וסיווג, כמו גם מודלים מיוחדים יותר לעיבוד שפה טבעית וחזון מחשבים.
בדיוק כמו בטכניקות אחרות של למידת מכונה המוזכרות במודול זה, למידה עמוקה כרוכה בהדרכה מתאימה לפונקציה ה יכולה לחזות תווית (y) בהתבסס על הערך של אחת או יותר מהתכונות (x). הפונקציה (f(x)) היא השכבה העליונה של פונקציה מקוננת שבה כל שכבה של הרשת העצבית כובצת פונקציות הפועלות על x ועל ערכי העובי (w) המשויכים אליהן. האלגוריתם המשמש לתרגל את המודל כרוך בהאכלה איטרטיבית של ערכי התכונות (x) ונתוני ההדרכה קדימה דרך השכבות כדי לחשב ערכי פלט עבור , אימות המודל כדי להעריך את המרחק של ערכי ה - y המחושבים מערכי y הידועים (פעולה המשבתת את רמת השגיאה, או אובדן , במודל), ולאחר מכן שינוי המשקל (w) כדי להפחית את הירידה. המודל המוכשרת כולל את ערכי המשקל הסופיים אשר התוצאה היא החיזויים המדויקים ביותר.
דוגמה - שימוש בלמידה עמוקה עבור סיווג
כדי להבין טוב יותר כיצד פועל מודל רשת עצבית עמוק, בואו נבחן דוגמה שבה רשת עצבית משמשת להגדרת מודל סיווג עבור מינים של פינגווין.
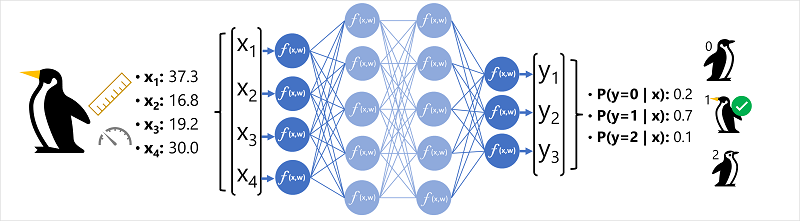
נתוני התכונות (x) מורכבים ממידות מסוימות של פינגווין. באופן ספציפי, המידות הן:
- אורכו של חשבון הפינגווין.
- העומק של חשבון הפינגווין.
- אורכו של הסנפירים של הפינגווין.
- משקל הפינגווין.
במקרה זה, x הוא וקטור של ארבעה ערכים, או מבחינה מתמטית, x=[x1,x2,x3,x4].
התווית שאנחנו מנסים לחזות (y) היא המין של הפינגווין, ושקיימים שלושה מינים אפשריים זה יכול להיות:
- עדי תם
- ג'נטו
- תות ראש
זוהי דוגמה לבעיית סיווג, שבה מודל למידת המכונה חייב לחזות את המחלקה הצפויה ביותר שאליה משתייכת תצפית. מודל סיווג עושה זאת על-ידי חיזוי תווית המורכבת מההסתברות עבור כל מחלקה. במילים אחרות, y הוא וקטור של שלושה ערכי הסתברות; אחת עבור כל אחת מהכיתות האפשריות: [P(y=0|x), P(y=1|x), P(y=2|x)].
התהליך להסיק שיעור פינגווין חזוי באמצעות רשת זו הוא:
- וקטור תכונה עבור תצפית פינגווין הוא להזין לתוך שכבת הקלט של הרשת העצבית, אשר מורכב נוירון עבור כל ערך x . בדוגמה זו, הווקטור x הבא משמש כקלט: [37.3, 16.8, 19.2, 30.0]
- הפונקציות עבור השכבה הראשונה של הנוירונים מחשבות סכום משקולת על-ידי שילוב ערך x במשקל w , והעברתן לפונקציית הפעלה הקובעת אם היא עומדת בסף שיש להעביר שכבה הבאה.
- כל נוירון בשכבה מחובר לכל הנוירונים בשכבה הבאה (ארכיטקטורה לעתים נקראת רשת מחוברת במלואה ) כך שתוצאות כל שכבה מתכלות קדימה דרך הרשת עד שהן מגיעות שכבת פלט.
- שכבת הפלט מפיקה וקטור של ערכים; במקרה זה, שימוש בפונקציה מסוג softmax או פונקציה דומה לחישוב התפלגות ההסתברות עבור שלוש הכיתות האפשריות של הפינגווין. בדוגמה זו, וקטור הפלט הוא: [0.2, 0.7, 0.1]
- רכיבי הווקטור מייצגים את ההסתברות עבור מחלקות 0, 1 ו- 2. הערך השני הוא הגבוה ביותר, ולכן המודל מנבא שמין הפינגווין הוא 1 (Gentoo).
כיצד לומדת רשת עצבית?
משקלים ברשת עצבית הם מרכזיים באופן המחשבת ערכים חזויות עבור תוויות. במהלך תהליך ההדרכה, המודל לומד את משקלי התוצאה לחיזויים המדויקים ביותר. נבחן את תהליך ההדרכה ביתר פירוט כדי להבין כיצד למידה זו מתבצעת.
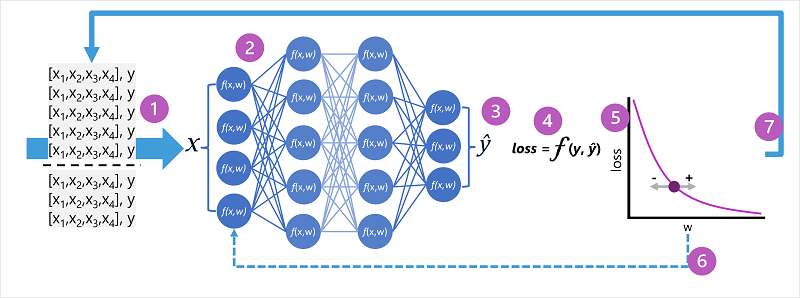
- ערכות הנתונים של הדרכה ואימות מוגדרות, ותכונות ההדרכה מתכלות בשכבת הקלט.
- הנוירונים בכל שכבה של הרשת להחיל את המשקל שלהם (אשר מוקצים באופן אקראי בהתחלה) ולהזנת הנתונים דרך הרשת.
- שכבת הפלט מפיקה וקטור המכיל את הערכים המחושבים עבור . לדוגמה, פלט עבור חיזוי סיווג פינגווין עשוי להיות [0.3. 0.1. 0.6].
- פונקציית אובדן משמשת להשוואה בין ערכי y החזויים לבין ערכי y הידועים ולצובר את ההפרש (המכונה 'אובדן'). לדוגמה, אם המחלקה הידועה עבור המקרה שהחזרה את הפלט בשלב הקודם היא Chinstrap, ערך y צריך להיות [0.0, 0.0, 1.0]. ההבדל המוחלט בין וקטור זה לבין הווקטור הוא [0.3, 0.1, 0.4]. במציאות, פונקציית ההפסד מחשבת את השונות המצטברת עבור מקרים מרובים ומסכמת אותה כערך אובדן יחיד.
- מאחר שהרשת כולה היא למעשה פונקציה מקוננת אחת גדולה, פונקציית מיטוב יכולה להשתמש בחשבון משלים כדי להעריך את ההשפעה של כל משקל ברשת על אובדן, ולקבוע כיצד ניתן להתאים אותה (למעלה או למטה) כדי להפחית את כמות האובדן הכולל. טכניקת המיטוב הספציפית עשויה להשתנות, אך בדרך כלל כרוכה בגישה של ירידה הדרגתית שבה כל משקל גדל או קטן כדי למזער את הירידה.
- השינויים במשקלים מוחלים לאחור בשכבות ברשת, ומחליף את הערכים שהיו בשימוש בעבר.
- התהליך חוזר על עצמו על איתציות מרובות (שנקראות תקופות) עד שההפסד ממוזער והמודל מננבא במדויק.
הערה
אף על פי שיהיה קל יותר לחשוב על כל אחד ממקרהי נתוני ההדרכה שעוברים ברשת אחד בכל פעם, במציאות הנתונים אצווה למטריצות ומעובדים באמצעות חישובים אלגבריים ליניאריים. מסיבה זו, הדרכת רשת עצבית מתבצעת בצורה הטובה ביותר במחשבים עם יחידות עיבוד גרפיות (GPU) הממוטבת למניפולציה של וקטורים מטריצות.