רשתות עצביות סובביות
הערה
עיין בכרטיסייה טקסט ותמונות לפרטים נוספים!
היכולת להשתמש במסננים כדי להחיל אפקטים על תמונות שימושית במשימות עיבוד תמונות, כגון ביצוע עם תוכנה לעריכת תמונות. עם זאת, המטרה של חזון המחשב היא לעתים קרובות לחלץ משמעות, או לפחות תובנות שניתן לפעול על פיהן, מתוך תמונות; אשר דורשים יצירה של מודלים של למידת מכונה המוכשרת לזהות תכונות בהתבסס על כמויות גדולות של תמונות קיימות.
תשר
יחידה זו מניחה שאתה מכיר את העקרונות הבסיסיים של למידת מכונה, ושידע מושגי לגבי למידה עמוקה עם רשתות עצביות. אם אתה חדש בלמידת מכונה, שקול להשלים את המודול מבוא למושגים של למידת מכונה ב- Microsoft Learn.
אחת מהארכיטקטורה הנפוצות ביותר של מודלים של למידת מכונה עבור חזון מחשב היא רשת עצבית נפוצה (CNN), סוג של ארכיטקטורת למידה עמוקה. CNNs משתמשות במסננים כדי לחלץ מפות של תכונות מספריות מתמונות, ולאחר מכן הזן את ערכי התכונות במודל למידה עמוק כדי ליצור חיזוי תוויות. לדוגמה, תמונה, התווית מייצגת את הנושא הראשי של התמונה (במילים אחרות, מהי תמונה זו של?). ייתכן שתכשיר מודל CNN עם תמונות מסוגים שונים של פירות (כגון תפוח, בננה וכתום) כך שהתווית החזוי היא סוג פירות בתמונה נתונה.
במהלך ההדרכה עבור CNN, ליבת סינון מוגדרת תחילה באמצעות ערכי משקל שנוצרו באופן אקראי. לאחר מכן, עם התקדמות תהליך ההדרכה, התחזיות של המודלים מוערכות כנגד ערכי תוויות ידועים ומשקלי המסנן מותאמים לשיפור הדיוק. בסופו של דבר, מודל הסיווג של תמונת פירות מאומן משתמש במשקלי המסננים אשר לחלץ תכונות בצורה הטובה ביותר לעזור לזהות סוגים שונים של פירות.
הדיאגרמה הבאה מתארת כיצד פועל CNN עבור מודל סיווג תמונה:
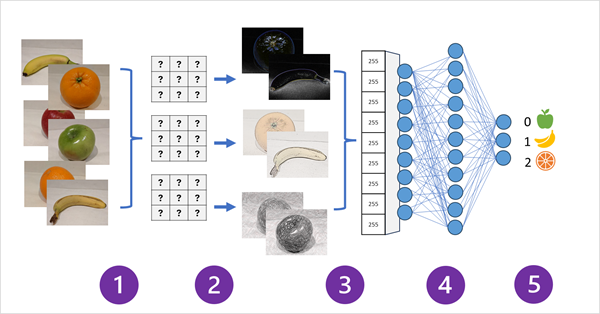
- תמונות עם תוויות מוכרות (לדוגמה, 0: apple, 1: banana או 2: orange) יתוונו לרשת כדי להכשיר את המודל.
- שכבות אחד או יותר של מסננים משמשות לחילוץ תכונות מכל תמונה כאשר היא עוברת אכילה ברשת. הליבה של המסנן תחל עם משקלים שהוקצו באופן אקראי ותפיק מערכים של ערכים מספריים הנקראים תכונות. שכבות נוספות עשויות "לאגד" או "להקטין" את מפות התכונות כדי ליצור מערכים קטנים יותר המדגישים את התכונות החזותיות העיקריות שחולצו על ידי המסננים.
- מפות התכונות שטוחות למערך חד-ממדי של ערכי תכונות.
- ערכי התכונות מוכלים לרשת עצבית מחוברת במלואה.
- שכבת הפלט של הרשת העצבית משתמשת בפונקציה מסוג softmax או פונקציה דומה כדי ליצור תוצאה המכילה ערך הסתברות עבור כל מחלקה אפשרית, לדוגמה [0.2, 0.5, 0.3].
במהלך ההדרכה, הסתברות הפלט מושווה לתווית המחלקה בפועל - לדוגמה, תמונה של בננה (מחלקה 1) צריכה לכלול את הערך [0.0, 1.0, 0.0]. ההבדל בין הניקוד החזוי לבין תוצאות המחלקה בפועל משמש לחישוב אובדן במודל, לבין המשקלים ברשת העצבית המחוברת במלואה ולהליבה של המסנן בשכבות חילוץ התכונות השתנה כדי להפחית את האובדן.
תהליך ההדרכה חוזר על פני מספר תקופות עד לתפקוד מיטבי של משקלים. לאחר מכן, המשקלים נשמרים ובאפשרותך להשתמש במודל כדי לחזות תוויות עבור תמונות חדשות שעבורן התווית אינה ידועה.
הערה
ארכיטקטורות CNN כוללות בדרך כלל שכבות מסנן רב-מסובב ושכבות נוספות כדי להקטין את הגודל של מפות תכונות, להגביל את הערכים שחולצו ולטפל בערכי התכונות באופן אחר. שכבות אלה הושמטו בדוגמה פשוטה זו כדי להתמקד במושג העיקרי, כלומר, מסננים משמשים לחילוץ תכונות מספריות מתמונות, ולאחר מכן משמשות ברשת עצבית לחיזוי תוויות תמונה.