שנאי ראייה ומודלים רב-מודאליים
הערה
עיין בכרטיסייה טקסט ותמונות לפרטים נוספים!
CNNs כבר בהליבה של פתרונות ראייה מחשבים במשך שנים רבות. למרות שהן משמשות בדרך כלל לפתרון בעיות סיווג תמונות כפי שתואר קודם לכן, הן גם הבסיס למודלים מורכבים יותר של ראייה ממוחשבת. לדוגמה, אובייקטים משלבים שכבות חילוץ תכונות CNN עם זיהוי של אזורי בעלי עניין בתמונות כדי לאתר מחלקות אובייקט מרובות באותה תמונה. התקדמות רבה בראייה ממוחשבת במהלך העשורים הונעה על ידי שיפורים במודלים מבוססי CNN.
עם זאת, תחום בינה מלאכותית אחר - עיבוד שפה טבעית (NLP), סוג אחר של ארכיטקטורת רשת עצבית, שנקראת שנאי אפשר פיתוח מודלים מתוחכמים לשפה.
מידול סמנטי לשפה - רובוטריקים
רובוטריקים פועלים על-ידי עיבוד כמויות אדירות של נתונים, ושפת הקידוד אסימונים (המייצגים מילים בודדות או צירופי מילים) כהטבעות מבוססות וקטור (מערכים של ערכים מספריים). טכניקה הנקראת תשומת לב משמשת להקצאת ערכי הטמעה המשקפים היבטים שונים של אופן השימוש בכל אסימון בהקשר של אסימונים אחרים. אתה יכול לחשוב על ההטמעות כווקטורים במרחב רב מימדי, שבו כל ממד מטמיע תכונה לשונית של אסימון על סמך ההקשר שלו בטקסט האימון, ויוצר קשרים סמנטיים בין אסימונים. אסימונים הנמצאים בשימוש נפוץ בהקשרים דומים מגדירים וקטורים מיושרים יותר מאשר מילים לא קשורות.
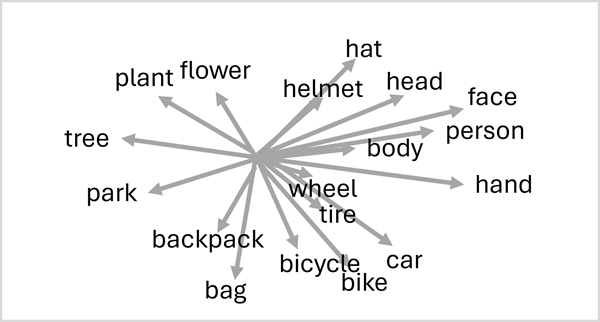
אסימונים שדומים באופן סמנטי מקודדים בהוראות דומות, יוצר מודל שפה סמנטי שמאפשר לבנות פתרונות NLP מתוחכמים לניתוח טקסט, תרגום, יצירת שפה ומשימות אחרות.
הערה
במציאות, מקודדים ברשתות שנאי יוצרים וקטורים עם ממדים רבים נוספים, ומפרידים קשרי גומלין סמנטיים מורכבים בין אסימונים בהתבסס על חישובים אלגבריים ליניאריים. המתמטיקה המעורבת מורכבת, כמו הארכיטקטורה של מודל שנאי. המטרה שלנו כאן היא רק לספק מושגית האופן שבו קידוד יוצר מודל שכוכסן קשרי גומלין בין ישויות.
מודל סמנטי לתמונות - שנאי ראייה
הצלחת השנאים כדרך לבניית מודלי שפה הובילה את חוקרי הבינה המלאכותית לשקול אם אותה גישה תהיה יעילה עבור נתוני תמונה. התוצאה היא פיתוח מודלים של שנאי ראייה (ViT), בהם מאומן מודל באמצעות נפח גדול של תמונות. במקום לקודד אסימונים מבוססי טקסט, השנאי מחלץ טלאים של ערכי פיקסלים מהתמונה, ויוצר וקטור ליניארי מערכי הפיקסלים.

אותה טכניקת תשומת לב המשמשת במודלים של שפה להטמעת קשרים הקשריים בין אסימונים, משמשת לקביעת קשרים הקשריים בין התיקונים. ההבדל העיקרי הוא שבמקום לקודד מאפיינים לשוניים בווקטורי ההטמעה, הערכים המוטבעים מבוססים על תכונות חזותיות, כמו צבע, צורה, ניגודיות, מרקם וכן הלאה. התוצאה היא קבוצה של וקטורים מוטמעים שיוצרת "מפה" רב-ממדית של תכונות חזותיות על סמך האופן שבו הן נראות בדרך כלל בתמונות האימון.
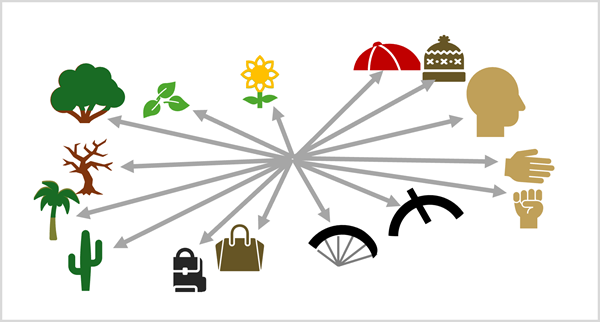
כמו במודלים של שפה, ההטמעות גורמות לכך שתכונות חזותיות המשמשות בהקשר דומה מקבלות כיוונים וקטוריים דומים. לדוגמה, המאפיינים החזותיים הנפוצים בכובע עשויים להיות קשורים בהקשר למאפיינים החזותיים הנפוצים בראש; כי שני הדברים נראים לעתים קרובות יחד. למודל אין הבנה מה זה "כובע" או "ראש"; אבל זה יכול להסיק קשר סמנטי בין המאפיינים החזותיים.
מביאים הכל יחד - דגמים מולטי-מודאליים
שנאי שפה יוצר הטמעות המגדירות אוצר מילים לשוני המקודד קשרים סמנטיים בין מילים. שנאי ראייה יוצר אוצר מילים חזותי שעושה את אותו הדבר עבור תכונות חזותיות. כאשר נתוני האימון כוללים תמונות עם תיאורי טקסט משויכים, אנו יכולים לשלב את המקודדים משני השנאים הללו במודל רב-מודאלי ; ולהשתמש בטכניקה הנקראת קשב חוצה מודלים כדי להגדיר ייצוג מרחבי מאוחד של ההטמעות, כך.
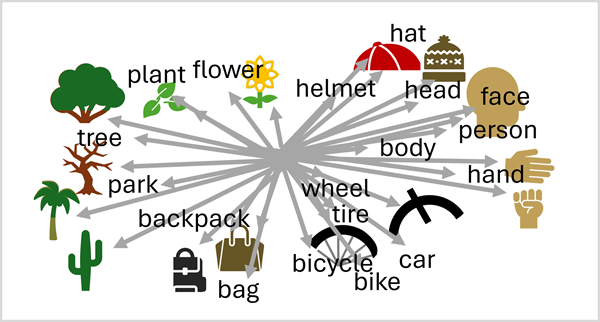
שילוב זה של הטמעת שפה וראייה מאפשר למודל להבחין בקשרים סמנטיים בין שפה לתכונות חזותיות. יכולת זו בתורה מאפשרת למודל לחזות תיאורים מורכבים עבור תמונות שהוא לא ראה בעבר, על ידי זיהוי תכונות חזותיות וחיפוש במרחב הווקטורי המשותף אחר שפה משויכת.

אדם בפארק עם כובע ותיק גב