डेटा एकीकरण के लिए प्रत्येक तालिका में डुप्लिकेट निकालें
एकीकरण के डीडुप्लीकेशन नियम चरण, स्रोत तालिका से किसी ग्राहक के लिए डुप्लिकेट रिकॉर्ड ढूंढता है और हटाता है, ताकि प्रत्येक ग्राहक को प्रत्येक तालिका में एक ही पंक्ति द्वारा दर्शाया जा सके। प्रत्येक तालिका को किसी विशेष ग्राहक के रिकार्ड की पहचान करने के लिए नियमों का उपयोग करके अलग से डुप्लिकेट किया जाता है।
नियमों को क्रमानुसार संसाधित किया जाता है। किसी तालिका में सभी रिकॉर्डों पर सभी नियम चलाए जाने के बाद, एक सामान्य पंक्ति साझा करने वाले मिलान समूहों को एक एकल मिलान समूह में संयोजित कर दिया जाता है।
डिडुप्लिकेशन नियमों को परिभाषित करें
एक अच्छा नियम एक विशिष्ट ग्राहक की पहचान करता है। अपने डेटा पर विचार करें. ईमेल जैसे फ़ील्ड के आधार पर ग्राहकों की पहचान करना पर्याप्त हो सकता है। हालाँकि, यदि आप एक ही ईमेल साझा करने वाले ग्राहकों में अंतर करना चाहते हैं, तो आप दो शर्तों वाला नियम चुन सकते हैं, जो ईमेल + प्रथम नाम पर आधारित हो। अधिक जानकारी के लिए, डिडुप्लीकेशन सर्वोत्तम अभ्यास देखें.
डीडुप्लीकेशन नियम पृष्ठ पर, एक तालिका चुनें और डीडुप्लीकेशन नियम परिभाषित करने के लिए नियम जोड़ें का चयन करें।
टिप
यदि आपने अपने एकीकरण परिणामों को बेहतर बनाने में सहायता के लिए डेटा स्रोत स्तर पर तालिकाओं को समृद्ध किया है, तो पृष्ठ के शीर्ष पर समृद्ध तालिकाओं का उपयोग करें का चयन करें। अधिक जानकारी के लिए, डेटा स्रोतों के लिए संवर्धन देखें।
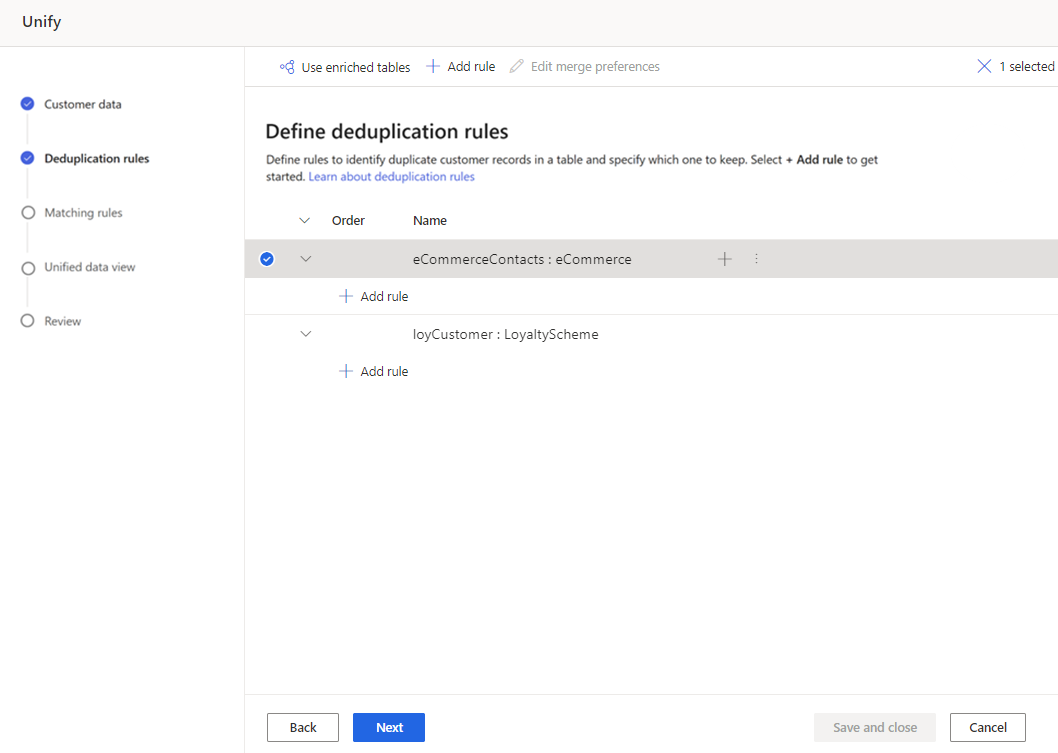
नियम जोड़ें पैन में, निम्नलिखित जानकारी दर्ज करें:
फ़ील्ड चुनें: तालिका से उपलब्ध फ़ील्ड की सूची में से वह फ़ील्ड चुनें जिसे आप डुप्लिकेट के लिए जांचना चाहते हैं। उन फ़ील्ड को चुनें, जो हर एक ग्राहक के लिए विशिष्ट हैं. उदाहरण के लिए, एक ईमेल पता, या नाम, शहर और फ़ोन नंबर का संयोजन.
सामान्यीकरण: स्तंभ के लिए सामान्यीकरण विकल्प का चयन करें. सामान्यीकरण केवल मिलान वाले चरण को प्रभावित करता है, तथा डेटा को परिवर्तित नहीं करता।
- अंक: संख्याओं को दर्शाने वाले यूनिकोड प्रतीकों को सरल संख्याओं में परिवर्तित करता है।
- प्रतीक: प्रतीकों और विशेष वर्णों को हटाता है जैसे !"#$%&'()*+,-./:;<=>?@[]^_`{|}~. उदाहरण के लिए, Head&Shoulder बन जाता है HeadShoulder.
- टेक्स्ट टू लोअर केस: बड़े अक्षरों को छोटे अक्षरों में बदलता है। "सभी बड़े अक्षर और शीर्षक केस" बदलकर "सभी बड़े अक्षर और शीर्षक केस" हो जाएंगे।
- प्रकार (फ़ोन, नाम, पता, संगठन): नाम, पदवी, फ़ोन नंबर और पते को मानकीकृत करता है.
- यूनिकोड से ASCII: यूनिकोड वर्णों को उनके ASCII अक्षर समकक्ष में परिवर्तित करता है। उदाहरण के लिए, उच्चारण वाला ề, e वर्ण में परिवर्तित हो जाता है।
- रिक्त स्थान: सभी रिक्त स्थान हटाता है. हैलो वर्ल्ड बन जाता है हैलोवर्ल्ड.
- उपनाम मैपिंग: आपको स्ट्रिंग युग्मों की एक कस्टम सूची अपलोड करने की अनुमति देता है, ताकि उन स्ट्रिंग्स को इंगित किया जा सके, जिन्हें हमेशा सटीक मिलान माना जाना चाहिए।
- कस्टम बाईपास: आपको स्ट्रिंग्स की एक कस्टम सूची अपलोड करने की अनुमति देता है, ताकि उन स्ट्रिंग्स को इंगित किया जा सके, जिनका कभी मिलान नहीं किया जाना चाहिए।
परिशुद्धता: परिशुद्धता का स्तर निर्धारित करें. परिशुद्धता का उपयोग सटीक मिलान और फ़ज़ी मिलान के लिए किया जाता है, और यह निर्धारित करता है कि मिलान माने जाने के लिए दो स्ट्रिंग्स को कितना करीब होना चाहिए।
- बेसिक: निम्न (30%), मध्यम (60%), उच्च (80%), और सटीक (100%) में से चुनें. केवल उन रिकॉर्डों का मिलान करने के लिए सटीक का चयन करें जो 100 प्रतिशत मेल खाते हों।
- कस्टम: वह प्रतिशत सेट करें जिसका मिलान रिकॉर्डों से होना आवश्यक है. सिस्टम केवल इस सीमा को पार करने वाले रिकार्डों का मिलान करता है।
नाम: नियम का नाम.
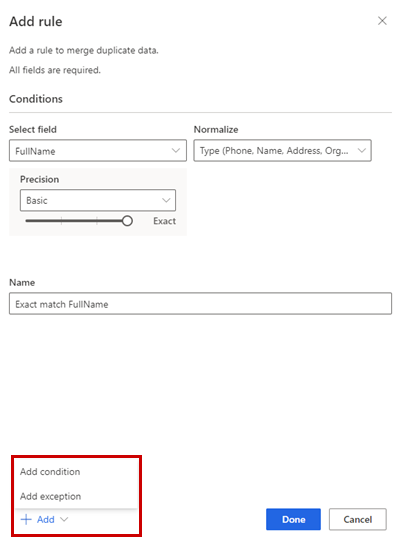
वैकल्पिक रूप से, नियम में और शर्तें जोड़ने के लिए जोड़ें>शर्त जोड़ें चुनें. शर्तों को तार्किक AND ऑपरेटर से जोड़ा जाता है और इस प्रकार केवल तब निष्पादित किया जाता है जब सभी शर्तें पूरी होती हैं.
वैकल्पिक रूप से, नियम में अपवाद जोड़ने के लिए >अपवाद जोड़ें जोड़ें । अपवादों का उपयोग झूठे सकारात्मक और झूठे नकारात्मक के दुर्लभ मामलों को संबोधित करने के लिए किया जाता है।
नियम बनाने के लिए हो गया चुनें।
वैकल्पिक रूप से, अधिक नियम जोड़ें.
एक तालिका का चयन करें और फिर मर्ज प्राथमिकताएँ संपादित करें.
मर्ज प्राथमिकताएँ फलक में:
यदि कोई डुप्लिकेट पाया जाता है तो कौन सा रिकॉर्ड रखना है, यह निर्धारित करने के लिए तीन विकल्पों में से एक चुनें:
- सर्वाधिक भरे गए: सबसे अधिक भरे गए स्तंभों वाले रिकॉर्ड को विजेता रिकॉर्ड के रूप में पहचानता है। यह डिफ़ॉल्ट मर्ज विकल्प है.
- सबसे हालिया: सबसे हालियाता के आधार पर विजेता रिकॉर्ड की पहचान करता है। रीजेंसी को परिभाषित करने के लिए एक तारीख या संख्यात्मक क्षेत्र की आवश्यकता होती है.
- सबसे कम हालिया: सबसे कम हालियाता के आधार पर विजेता रिकॉर्ड की पहचान करता है। रीजेंसी को परिभाषित करने के लिए एक तारीख या संख्यात्मक क्षेत्र की आवश्यकता होती है.
यदि बराबरी हो, तो विजेता रिकार्ड वह होगा जिसका प्राथमिक कुंजी मान MAX(PK) या बड़ा होगा।
वैकल्पिक रूप से, किसी तालिका के अलग-अलग स्तंभों पर मर्ज प्राथमिकताएँ परिभाषित करने के लिए, फलक के नीचे उन्नत का चयन करें। उदाहरण के लिए, आप विभिन्न रिकार्डों से नवीनतम ईमेल तथा सबसे पूर्ण पता रखना चुन सकते हैं। तालिका का विस्तार करके उसके सभी स्तंभ देखें और यह निर्धारित करें कि अलग-अलग स्तंभों के लिए कौन-सा विकल्प उपयोग करना है। यदि आप नवीनता-आधारित विकल्प चुनते हैं, तो आपको नवीनता को परिभाषित करने वाला दिनांक/समय फ़ील्ड भी निर्दिष्ट करना होगा।
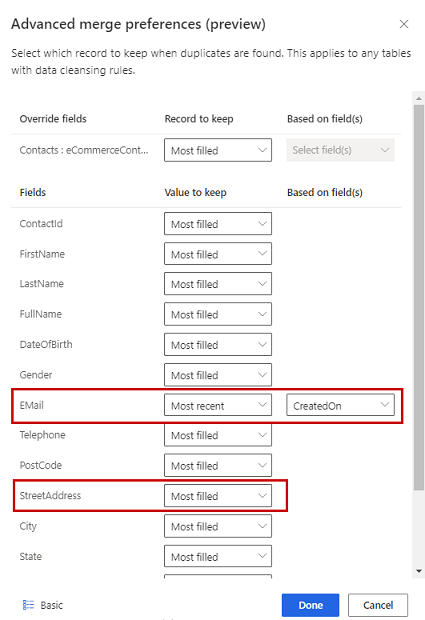
अपनी मर्ज प्राथमिकताएं लागू करने के लिए संपन्न चुनें.
डीडुप्लीकेशन नियमों और मर्ज प्राथमिकताओं को परिभाषित करने के बाद, अगला चुनें.
