नोट
इस पेज तक पहुँच के लिए प्रमाणन की आवश्यकता होती है. आप साइन इन करने या निर्देशिकाओं को बदलने का प्रयास कर सकते हैं.
इस पेज तक पहुँच के लिए प्रमाणन की आवश्यकता होती है. आप निर्देशिकाओं को बदलने का प्रयास कर सकते हैं.
In this step of the unification process, choose and exclude columns to merge within your unified profile table. For example, if three tables had email data, you might want to keep all three separate email columns or merge them into a single email column for the unified profile. Dynamics 365 Customer Insights - Data automatically combines some columns. For individual customers, you can group related profiles into a cluster.
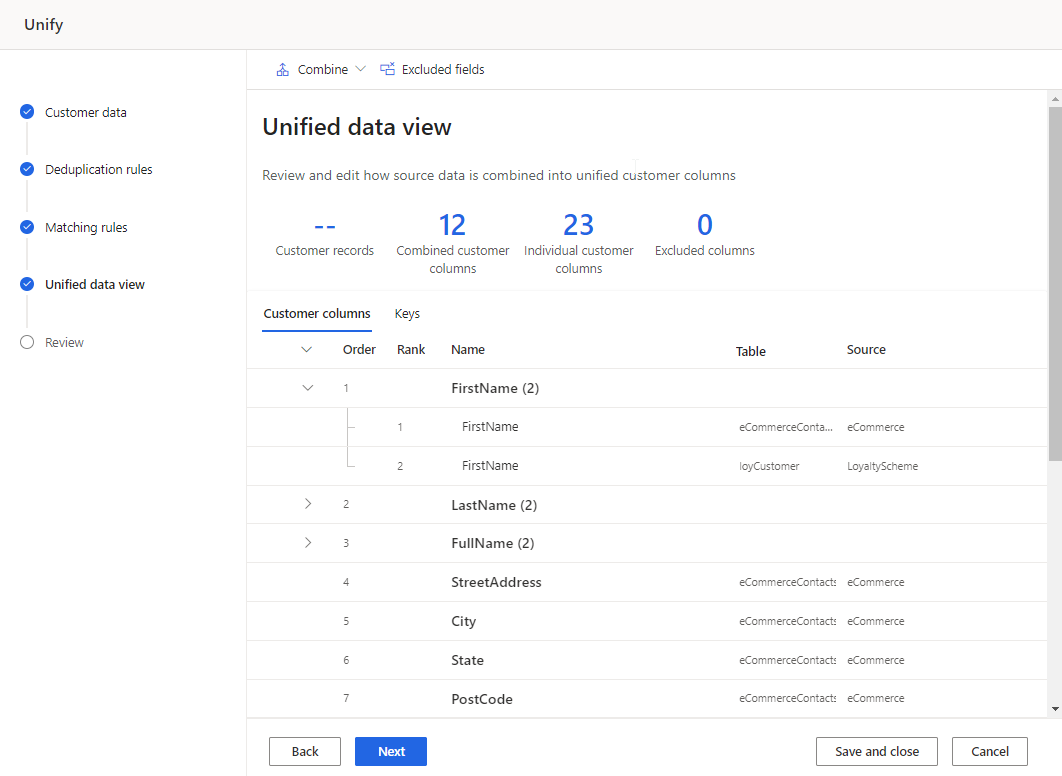
Review and update the customer columns
Review the list of columns that will be unified under the Customer columns tab of the table. Make any changes if applicable.
For any combined fields, you can:
For any single fields, you can:
Optionally, generate the customer ID configuration.
Optionally, group profiles into households or clusters.
Edit a merged field
Select a merged column and choose Edit. The Combine columns pane displays.
Specify how to combine or merge the fields from one of three options:
Importance: Identifies the winner value based on importance rank specified for the participating fields. It's the default merge option. Select Move up/down to set the importance ranking.
Note
The system uses the first non-null value. For example, given tables A, B, and C ranked in that order, if A.Name and B.Name are null, then the value from C.Name is used.
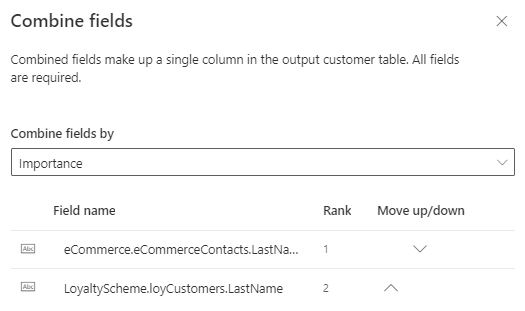
Most recent: Identifies the winner value based on the most recency. Requires a date or a numeric field for every participating table in the merge fields scope to define the recency.
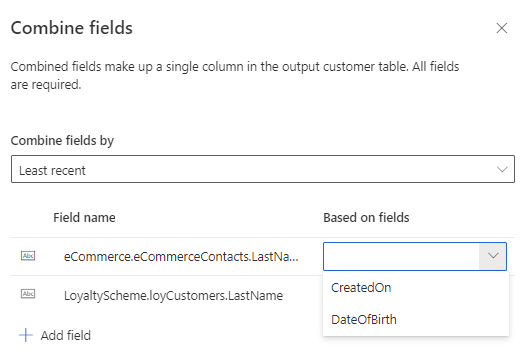
Least recent: Identifies the winner value based on the least recency. Requires a date or a numeric field for every participating table in the merge fields scope to define the recency.
You can add more fields to participate in the merge process.
You can rename the merged column.
Select Done to apply your changes.
Rename fields
Change the display name of merged or separate fields. You can't change the name of the output table.
Select the column and choose Rename.
Enter the new display name.
Select Done.
Separate merged fields
To separate merged fields, find the column in the table. Separated fields show as individual data points on the unified customer profile.
Select the merged column and choose Separate fields.
Confirm the separation.
Exclude fields
Exclude a merged or separate field from the unified customer profile. If the field is used in other processes, such as a segment, remove it from these processes. Then, exclude it from the customer profile.
Select a column and choose Exclude.
Confirm the exclusion.
To see the list of all excluded fields, select Excluded columns. If necessary, you can readd the excluded column.
Change the order of fields
Some tables contain more details than others. If a table includes the latest data about a field, you can prioritize it over other tables when merging values.
Select the field.
Choose Move up/down to set the order or drag and drop them in the desired position.
Combine fields manually
Combine separated fields to create a merged column.
Select Combine > Fields. The Combine columns pane displays.
Specify the merge winner policy in the Combine fields by dropdown.
Select Add field to combine more fields.
Provide a Name and an Output field name.
Select Done to apply the changes.
Combine a group of fields
When you combine a group of fields, Customer Insights - Data treats the group as a single unit, and chooses the winner record based on a merge policy. When merging fields without combining them into a group, the system chooses the winner record for each field based on the table order ranking set up in the Matching rules step. If a field has a null value, Customer Insights - Data continues to look at the other data sources until it finds a value. If this mixes information in an unwanted way or you want to set a merge policy, combine the group of fields.
Example
Monica Thomson matches across three data sources: Loyalty, Online, and POS. Without combining the mailing address fields for Monica, the winner record for each field is based on the first ranked data source (Loyalty), except Addr2 which is null. The winner record for Addr2 is Suite 950 resulting in an incorrect mix of address fields (200 Cedar Springs Road, Suite 950, Dallas, TX 75255). To ensure data integrity, combine the address fields into a group. Grouping doesn't change how the data is stored or displayed.
Table1 - Loyalty
| Full_Name | Addr1 | Addr2 | City | State | Zip |
|---|---|---|---|---|---|
| Monica Thomson | 200 Cedar Springs Rd | Dallas | TX | 75255 |
Table2 - Online
| Name | Addr1 | Addr2 | City | State | Zip |
|---|---|---|---|---|---|
| Monica Thomson | 5000 15th Street | Suite 950 | Redmond | WA | 98052 |
Table3 - POS
| Full_Name | Add1 | Add2 | City | State | Zip |
|---|---|---|---|---|---|
| Monica Thomson | 100 Main Street | Suite 100 | Seattle | WA | 98121 |
Create a group of fields (preview)
Select Combine > Group of fields.
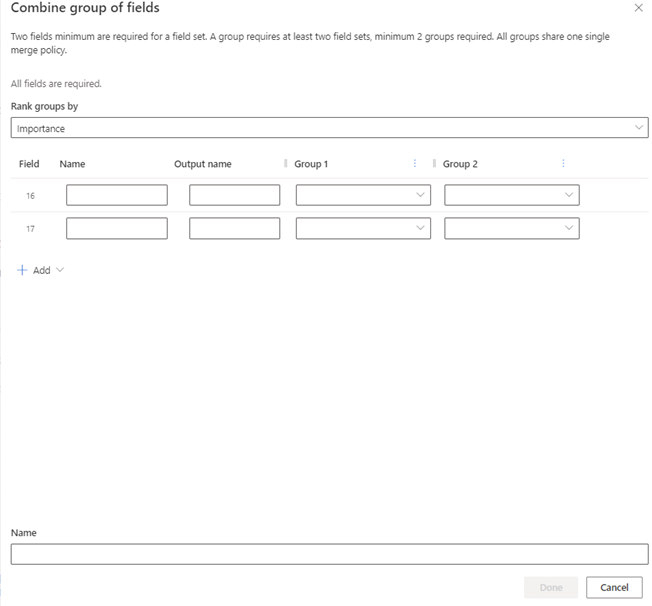
Specify which group of fields to select as the winner in the Rank groups by dropdown. The same merge policy is used for all the fields that make up the group.
- Importance: Identifies the winner group by looking at the groups in order starting with Group 1. If all fields are null, the next group is considered. Importance is the default value.
- Most recent: Identifies the winner group by referencing a field in the group you select to indicate recency. The field can be a date, time, or numeric as long as it can be ranked largest to smallest.
- Least recent: Identifies the winner group by referencing a field in the group you select to indicate recency. The field can be a date, time, or numeric as long as it can be ranked smallest to largest.
To add more than two fields for your combined group, select Add > Field. Add as many as 10 fields.
To add more than two data sources for your combined group, select Add > Group. Add as many as 15 data sources.
Enter the following information for each field you're combining:
- Name: Unique name of the field you want in the grouping. You can’t use a name from your data sources.
- Output name: Automatically filled in and displays in the Customer profile.
- Group 1: The field from the first data source that corresponds to the Name. The ranking of your data sources indicates the order in which the system identifies and merges the records by Importance.
Note
In the drop-down for a group, the list of fields is categorized by data source.
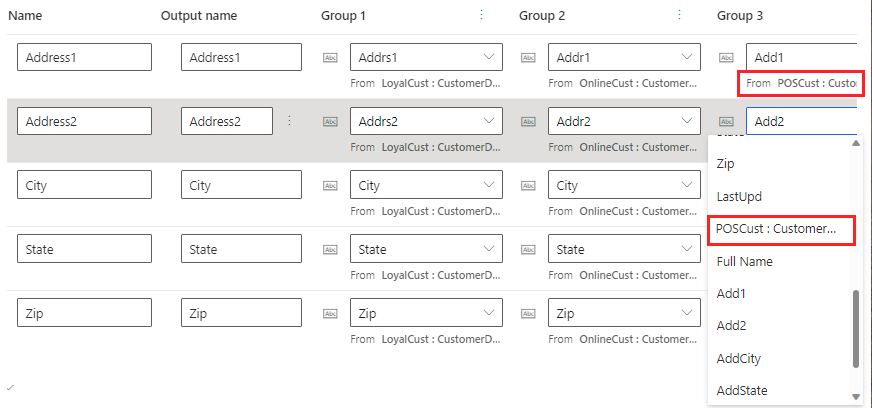
- Group2: The field in the next data source that corresponds to the Name. Repeat for each data source you include.
Provide a Name for the combined group of fields, such as mailing address. This name displays on the Unified data view step but doesn't appear in the Customer profile.
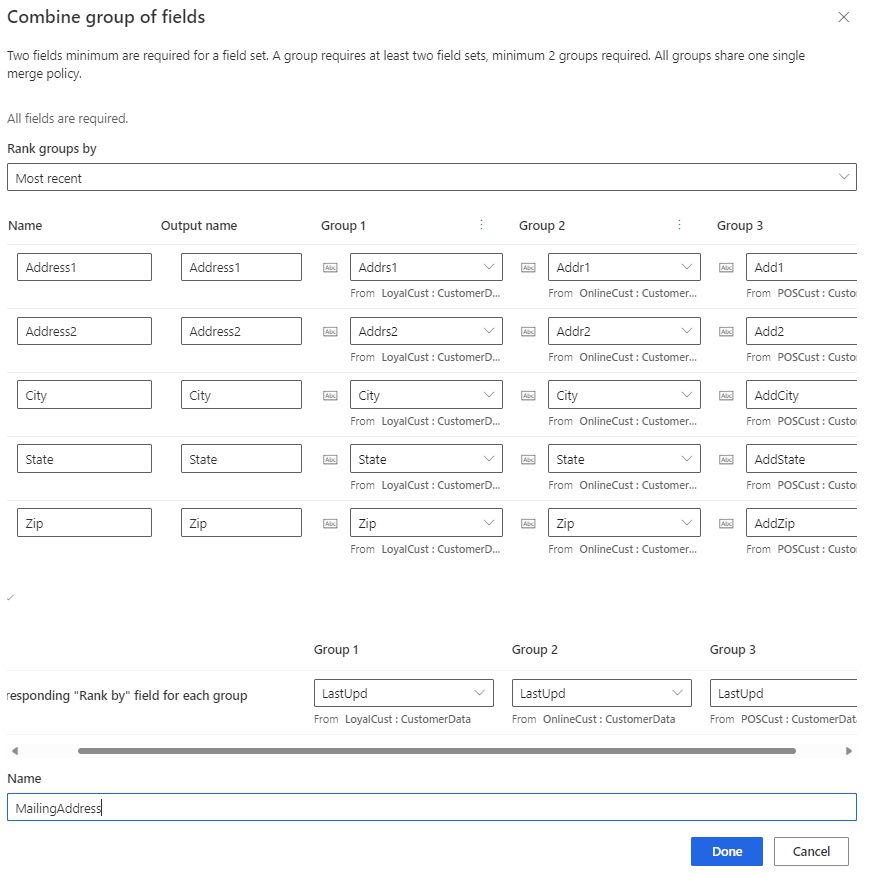
Select Done to apply the changes. The name for the combined group displays on the Unified data view page, but not in the Customer profile.
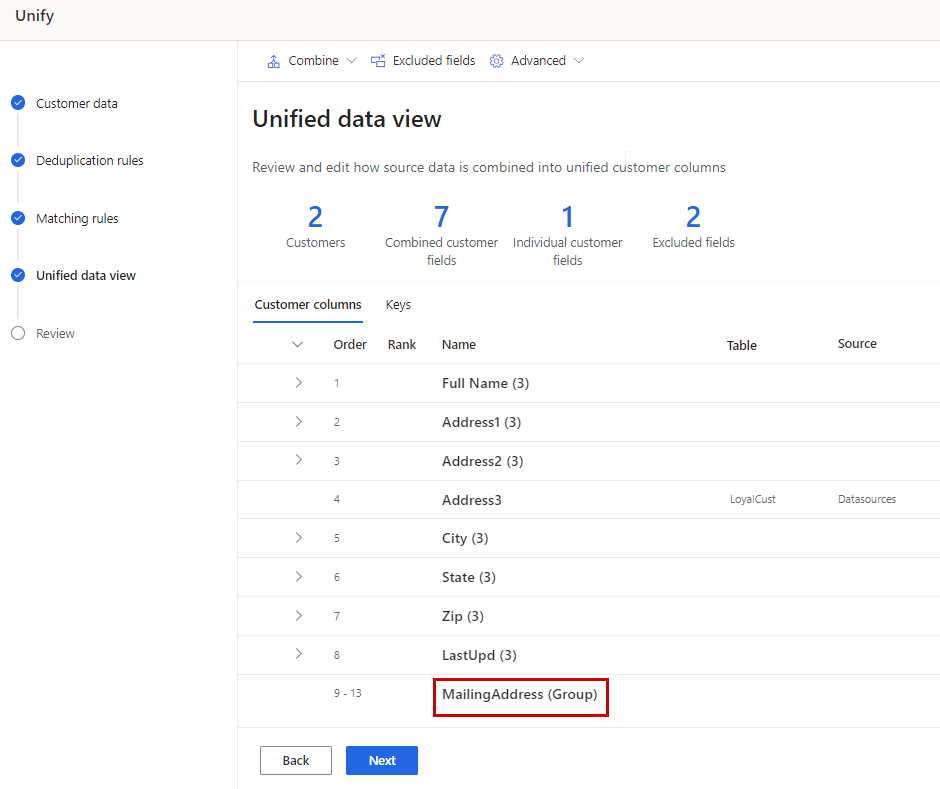
Group profiles into households or clusters
For individual customers, you can define rules to group related profiles into a cluster. There are currently two types of clusters available – household and custom clusters. The system automatically chooses a household with predefined rules if the Customer table contains the semantic fields Person.LastName and Location.Address. You can also create a cluster with your own rules and conditions, similar to match rules.
Anyone in a shared group (same last name and address) gets a common cluster ID added to their profile. After unification, you can search on the cluster ID to easily find other members of the same household. Clusters aren't the same as segments. Cluster IDs identify a relationship between a few people. Segments group large sets of people. A given customer can belong to many different segments.
Select Advanced > Create cluster.
Choose between a Household or a Custom cluster. If the semantic fields Person.LastName and Location.Address exist in the Customer table, household is automatically selected.
Provide a name for the cluster and select Done.
Select the Clusters tab to find the cluster you created.
Specify the rules and conditions to define your cluster.
Select Done. The cluster is created when the unification process is complete. The cluster identifiers are added as new fields to the Customer table.
Configure customer ID generation
The CustomerId field is a unique GUID value that is automatically generated for each unified customer profile. We recommend using this default logic. However, in rare circumstances you can specify the fields to use as inputs to generate the CustomerId.
Select the Keys tab.
Hover on the CustomerId row and select Configure.
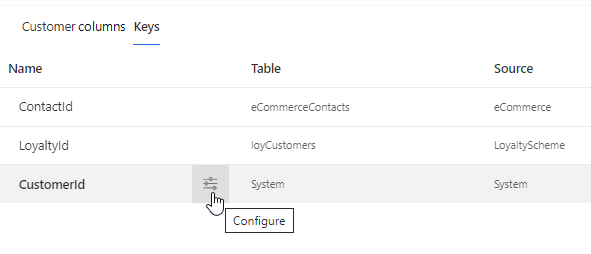
Select up to five fields that will comprise a stable, unique customer ID. Records that don’t match your configuration use a system-configured ID instead.
Only include columns that are either not expected to change such as a government-issued ID, or when changed, a new CustomerId is appropriate. Avoid columns that might change such as phone, email, or address.
Select Done.
For each input to the CustomerId generation, the first non-null TableName + field value are used. Tables are checked for non-null values in the table order defined on the Matching rules unification step. If the source table or input field values change, the resulting CustomerId will change.