नोट
इस पृष्ठ तक पहुंच के लिए प्राधिकरण की आवश्यकता होती है। आप साइन इन करने या निर्देशिकाएँ बदलने का प्रयास कर सकते हैं।
इस पृष्ठ तक पहुंच के लिए प्राधिकरण की आवश्यकता होती है। आप निर्देशिकाएँ बदलने का प्रयास कर सकते हैं।
Summary
| Item | Description |
|---|---|
| Release State | General Availability |
| Products | Power BI (Semantic models) Power BI (Dataflows) Fabric (Dataflow Gen2) |
| Authentication Types Supported | Feed Key Organizational account |
Prerequisites
- An Azure Cosmos DB account.
Capabilities supported
- Import
- DirectQuery (Power BI semantic models)
- Advanced options
- Number of Retries
- Enable "AVERAGE" function Passdown
- Enable "SORT" Passdown for multiple columns
Connect to Azure Cosmos DB
To connect to Azure Cosmos DB data:
Launch Power BI Desktop.
In the Home tab, select Get Data.
In the search box, enter Cosmos DB v2.
Select Azure Cosmos DB v2, and then select Connect.
On the Azure Cosmos DB v2 connection page, for Cosmos Endpoint, enter the URI of the Azure Cosmos DB account that you want to use. For Data Connectivity mode, choose a mode that's appropriate for your use case, following these general guidelines:
For smaller data sets, choose Import. When you use import mode, Power BI works with Cosmos DB to import the contents of the entire data set for use in your visualizations.
DirectQuery mode enables query pushdown to the Cosmos DB container for execution and improves the performance of the connector. For partitioned Cosmos DB containers, a SQL query with an aggregate function is passed down to Cosmos DB if the query also contains a filter (WHERE clause) on the Partition Key. For example, if the partition key is defined to be "Product," then a SQL query that can be passed down and executed on Cosmos DB server can be:
SELECT SUM(ColumnName) FROM TableName where Product = 'SampleValue'
Note
Use Azure Synapse Link for Azure Cosmos DB if you would like to execute cross-partitioned aggregate functions against the Cosmos DB container.
More information:
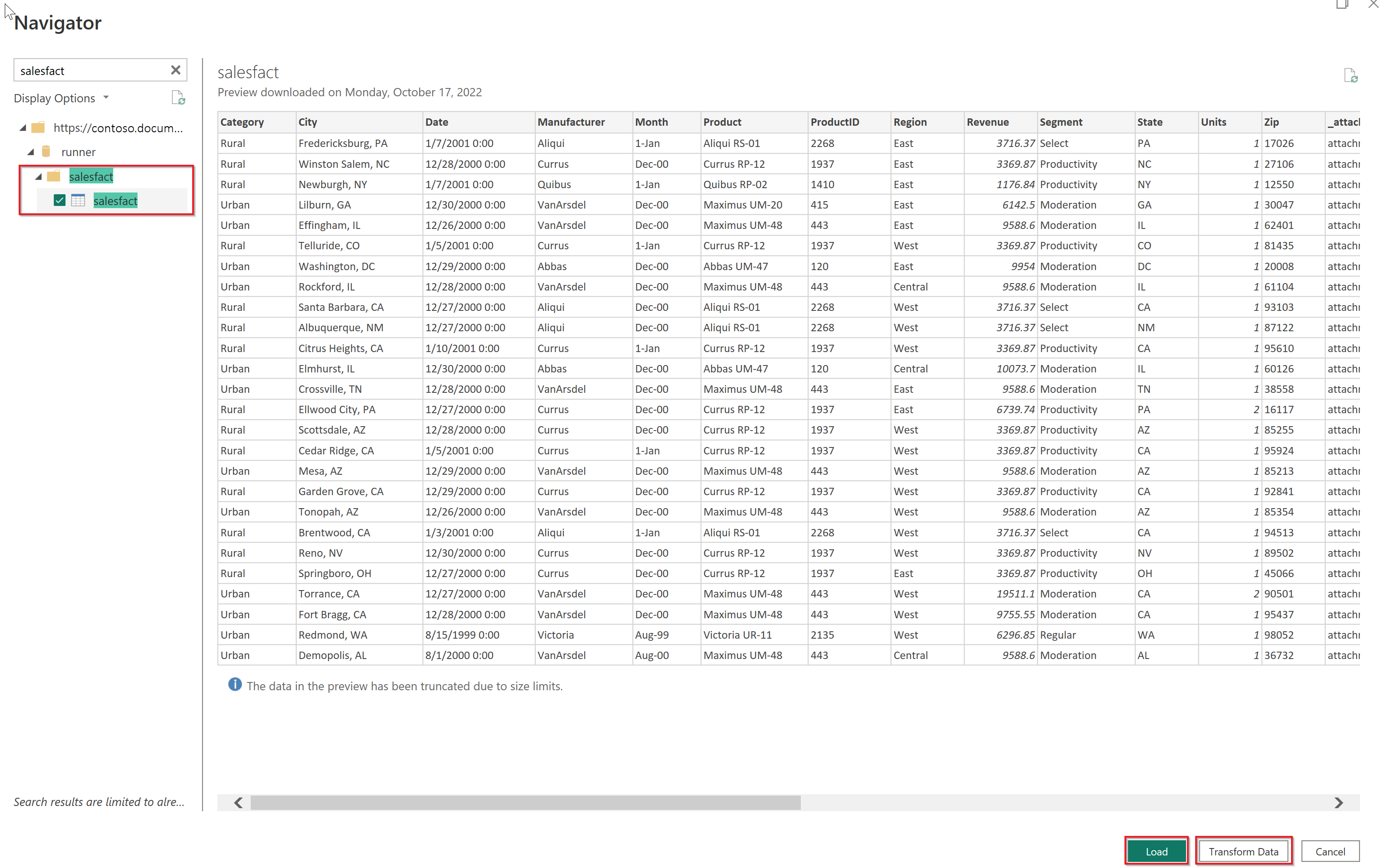
At the prompt to configure data source authentication, either enter the Account key or sign in to your Organizational account. Then select Connect. Your data catalog, databases, and tables appear in the Navigator dialog box.
In the Display Options pane, select the check box for the data set that you want to use.
The most optimal way to specify the Partition Key filter (so that the aggregate functions can be pushed down to Cosmos DB) is to use dynamic M parameters. To use dynamic M parameters, you would create a data set with unique Partition Key values, create a parameter, add it as a filter on the main data set, bind it to the unique Partition key data set, and use it as a slicer for the main data set. Use the following steps to enable dynamic M parameters for Partition Key filtering.
a. Create a data set with unique partition key values:
In Navigator, select Transform Data instead of Load to bring up the Power Query editor. Right-click on the queries data set, and then select Duplicate to create a new data set.
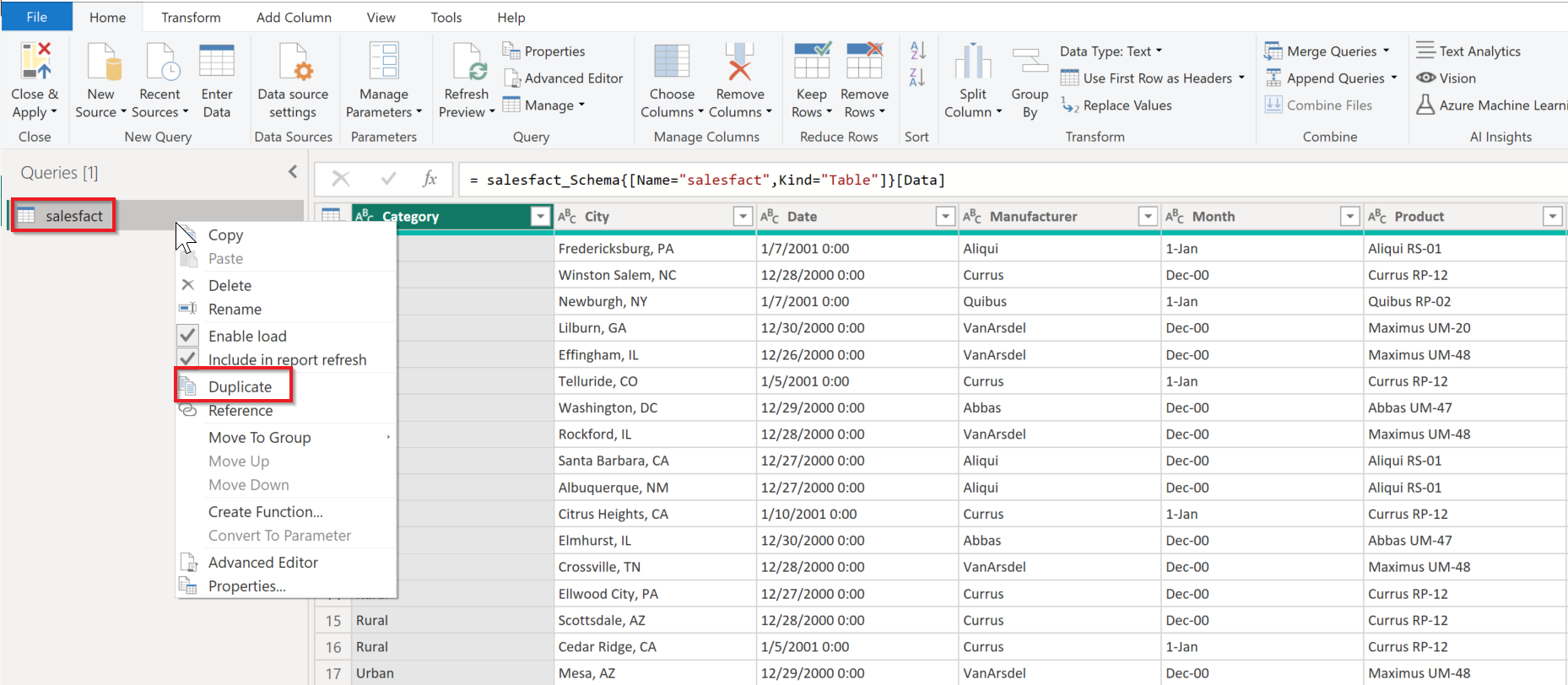
Rename the new Partition Key model, then right-click on the Cosmos DB partition key column. In this example, Product is the Cosmos DB partition key column. Select Remove Other Columns, and then select Remove Duplicates.

b. Create a parameter for dynamic filtering:
In the Power Query editor, select Manage Parameters > New Parameter. Rename the new parameter to reflect the filter parameter and input a valid value as Current Value.
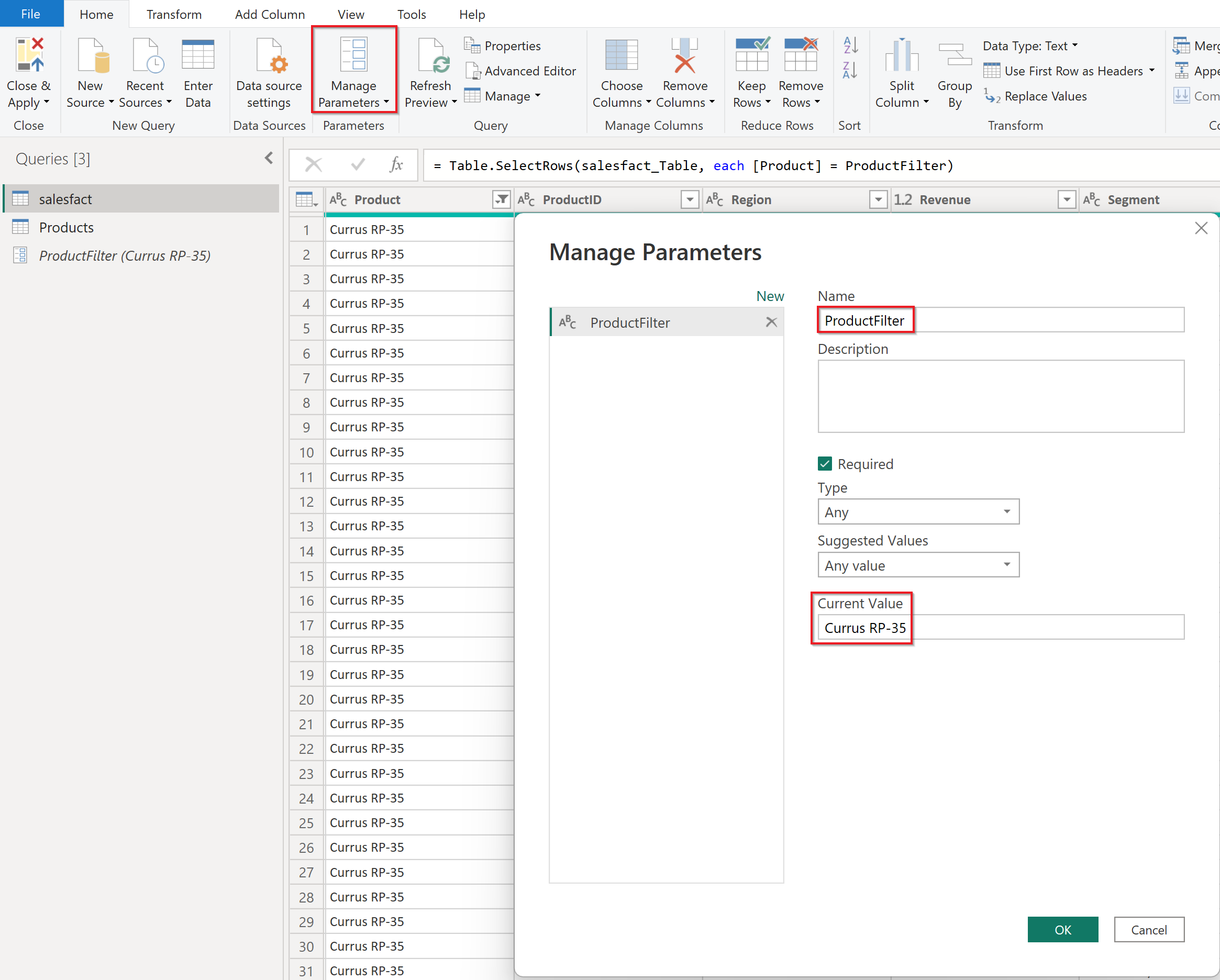
c. Apply parameterized filter on the main data set:
Select the dropdown icon of the Partition Key column, then select Text Filters > Equals. Change the filter type from Text to Parameter. Then choose the parameter that was created in step b. Select Close & Apply on top left corner of the Power Query editor.

d. Create Partition Key values slicer with parameter binding:
In Power BI, select the Model tab. Then select the Partition Key field. From the Properties pane, select Advanced > Bind to parameter. Choose the parameter that was created in step b.
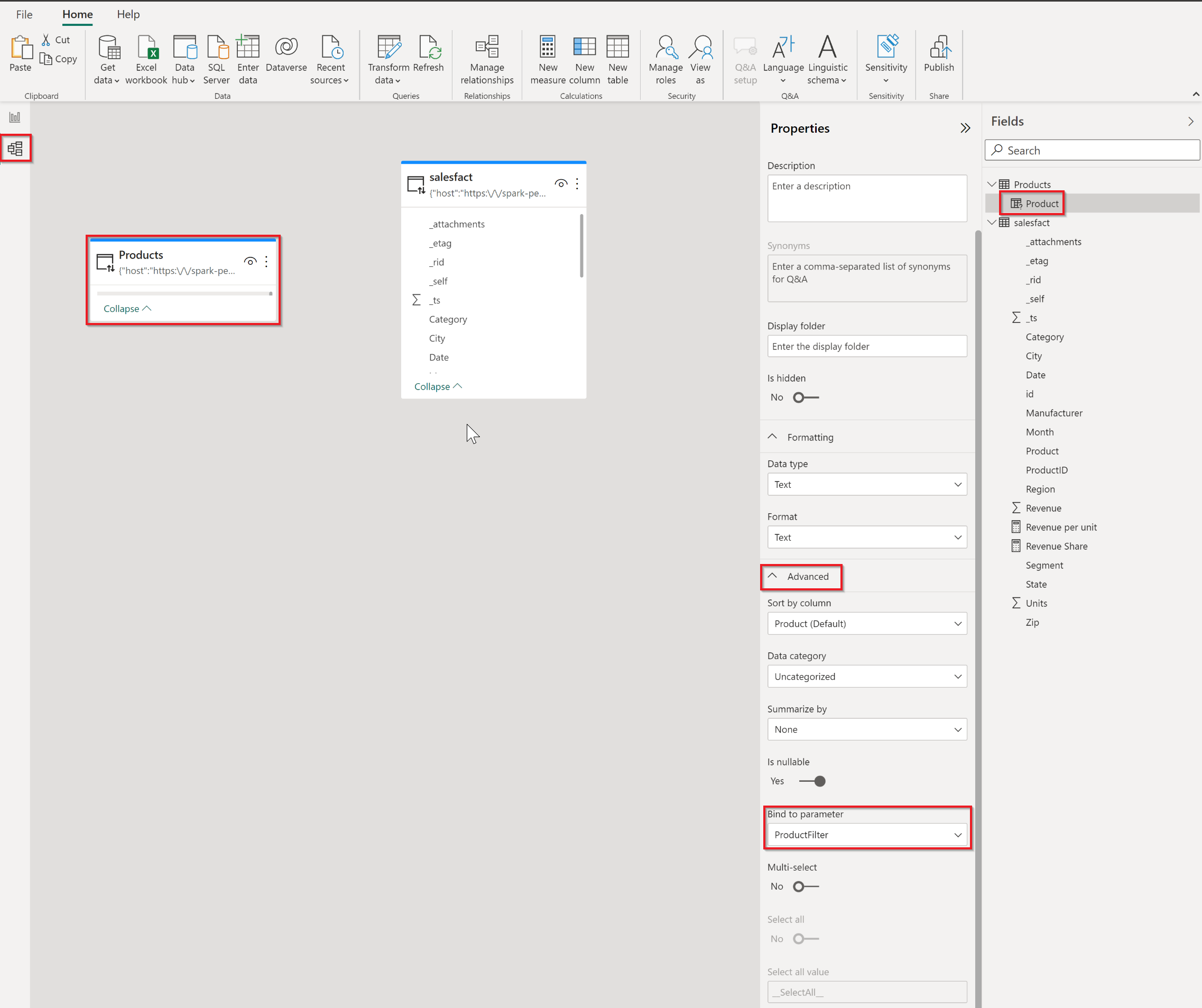
Select the Report tab and add a slicer with the unique Partition Key.

e. Add visualizations and apply Partition Key filter from the slicer:
Since the chosen partition key value on the slicer is bound to the parameter (as done in step d) and the parameterized filter is applied on the main data set (as done in step c), the chosen partition key value is applied as a filter on the main data set and the query with the partition key filter is passed down to Cosmos DB in all visualizations.
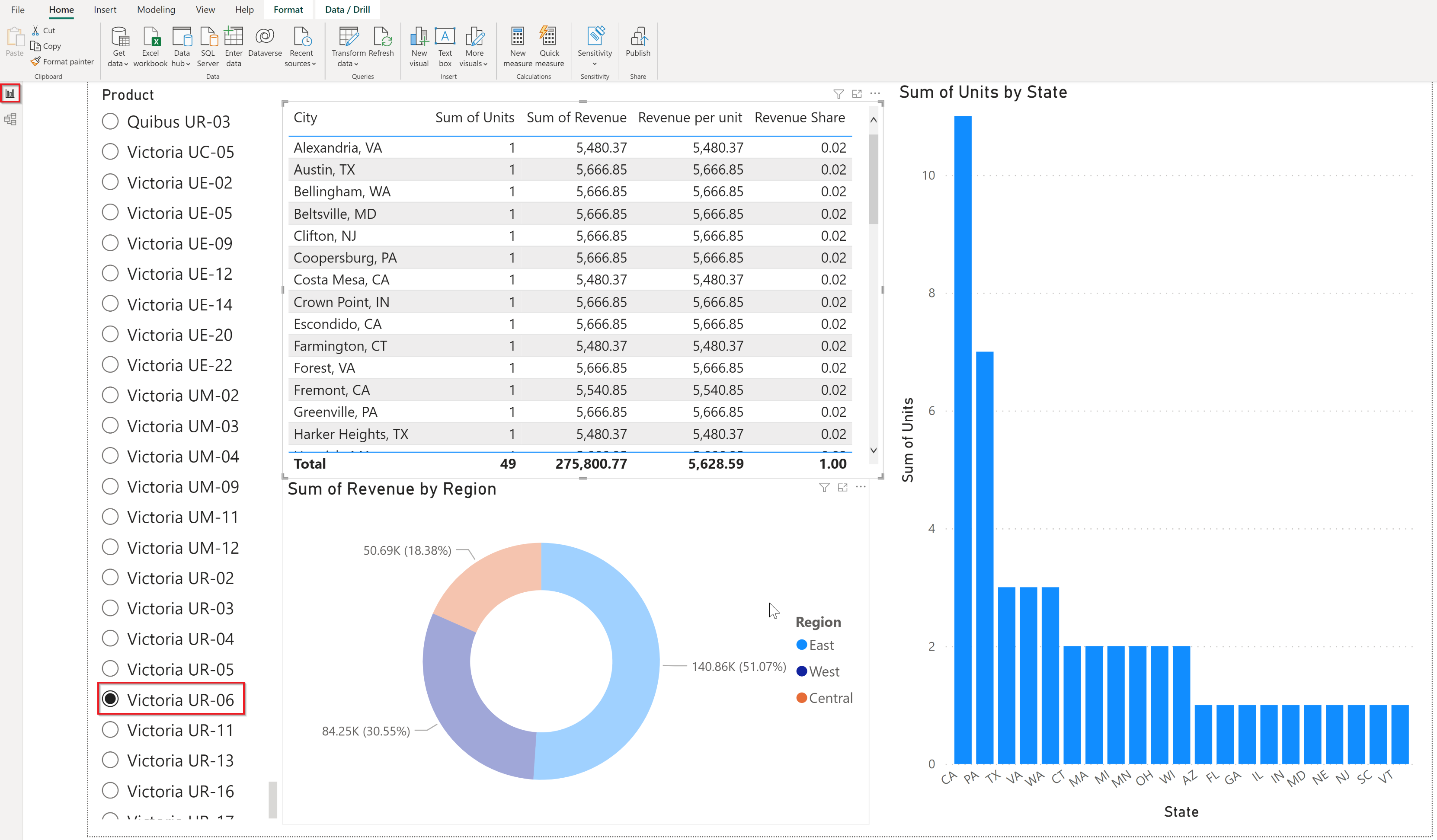







Advanced options
Power Query provides a set of advanced options that you can add to your query if needed.
The following table lists all of the advanced options you can set in Power Query.
| Advanced option | Description |
|---|---|
| Number of Retries | How many times to retry if there are HTTP return codes of 408 - Request Timeout, 412 - Precondition Failed, or 429 - Too Many Requests. The default number of retries is 5. |
| Enable AVERAGE function Passdown | Specifies whether the connector allows pass-down of the AVG aggregate function to the Cosmos DB. The default value is 1 and the connector attempts to pass-down the AVG aggregate function down to Cosmos DB, by default. If the argument contains string, boolean, or null values for the AVG aggregate function, an undefined result set is returned by the Cosmos DB server. When set to value of 0, the AVG aggregate function isn't passed down to the Cosmos DB server, and the connector handles performing the AVG aggregation operation itself. |
| Enable SORT Passdown for multiple columns | Specifies whether the connector allows multiple columns to be passed down to Cosmos DB when specified in the ORDER BY clause of the SQL query. The default value is 0. If more than one column is specified in the ORDER BY clause, the connector doesn't pass down the columns by default. Instead, it handles performing the order by itself. When set to value of 1, the connector attempts to pass-down multiple columns to Cosmos DB when specified in the ORDER BY clause of the SQL query. To allow multiple columns to be passed down to Cosmos DB, make sure to have composite indexes set on the columns in the respective collections. For partitioned collections, a SQL query with ORDER BY is passed down to Cosmos DB only if the query contains a filter on the partitioned key. Also, if there are more than eight columns specified in the ORDER BY clause, the connector doesn't pass down the ORDER BY clause and instead handles the ordering execution itself. |
Known issues and limitations
For partitioned Cosmos DB containers, a SQL query with an aggregate function is passed down to Cosmos DB if the query also contains a filter (WHERE clause) on the Partition Key. If the aggregate query doesn't contain a filter on the Partition Key, the connector performs the aggregation.
The connector doesn't pass down an aggregate function if it's called upon after TOP or LIMIT is applied. Cosmos DB processes the TOP operation at the end when processing a query. For example, in the following query, TOP is applied in the subquery, while the aggregate function is applied on top of that result set:
SELECT COUNT(1) FROM (SELECT TOP 4 * FROM EMP) EIf DISTINCT is provided in an aggregate function, the connector doesn't pass the aggregate function down to Cosmos DB if a DISTINCT clause is provided in an aggregate function. When present in an aggregate function, the Cosmos DB SQL API doesn't support DISTINCT.
For the SUM aggregate function, Cosmos DB returns undefined as the result set if any of the arguments in SUM are string, boolean, or null. However, if there are null values, the connector passes the query to Cosmos DB in such a way that it asks the data source to replace a null value with zero as part of the SUM calculation.
For the AVG aggregate function, Cosmos DB returns undefined as result set if any of the arguments in SUM are string, boolean, or null. The connector exposes a connection property to disable passing down the AVG aggregate function to Cosmos DB in case this default Cosmos DB behavior needs to be overridden. When AVG passdown is disabled, it isn't passed down to Cosmos DB, and the connector handles performing the AVG aggregation operation itself. For more information, go to "Enable AVERAGE function Passdown" in Advanced options.
Azure Cosmos DB Containers with large partition key aren't currently supported in the Connector.
Aggregation passdown is disabled for the following syntax due to server limitations:
When the query isn't filtering on a partition key or when the partition key filter uses the OR operator with another predicate at the top level in the WHERE clause.
When the query has one or more partition keys appear in an IS NOT NULL clause in the WHERE clause.
The V2 connector doesn't support complex data types such as arrays, objects, and hierarchical structures. We recommend the Fabric Mirroring for Azure Cosmos DB feature for those scenarios.
The V2 connector uses sampling of the first 1,000 documents to come up with the inferred schema. It's not recommended for schema evolution scenarios when only part of the documents are updated. As an example, a newly added property to one document in a container with thousands of documents might not be included in the inferred schema. We recommend the Fabric Mirroring for Azure Cosmos DB feature for those scenarios.
Currently the V2 connector doesn't support non-string values in object properties.
Filter passdown is disabled for the following syntax due to server limitations:
- When the query containing one or more aggregate columns is referenced in the WHERE clause.