बैच समापन बिंदुओं को समझें और बनाएं
बैच भविष्यवाणियां उत्पन्न करने के लिए एक मॉडल प्राप्त करने के लिए, आप मॉडल को बैच समापन बिंदु पर तैनात कर सकते हैं।
आप सीखेंगे कि एसिंक्रोनस बैच स्कोरिंग के लिए बैच एंडपॉइंट का उपयोग कैसे करें।
बैच भविष्यवाणियां
बैच पूर्वानुमान प्राप्त करने के लिए, आप एक मॉडल को एक समापन बिंदु पर तैनात कर सकते हैं। एक समापन बिंदु एक HTTPS समापन बिंदु है जिसे आप बैच स्कोरिंग कार्य ट्रिगर करने के लिए कॉल कर सकते हैं। ऐसे समापन बिंदु का लाभ यह है कि आप बैच स्कोरिंग कार्य को किसी अन्य सेवा, जैसे Azure Synapse Analytics या Azure Databricks से ट्रिगर कर सकते हैं। एक बैच समापन बिंदु आपको मौजूदा डेटा अंतर्ग्रहण और परिवर्तन पाइपलाइन के साथ बैच स्कोरिंग को एकीकृत करने की अनुमति देता है।
जब भी समापन बिंदु लागू किया जाता है, तो Azure मशीन लर्निंग कार्यस्थान पर एक बैच स्कोरिंग कार्य सबमिट किया जाता है। कार्य सामान्यतया एक कंप्यूट क्लस्टर एकाधिक इनपुट स्कोर करने के लिए उपयोग करता है। परिणामों को डेटास्टोर में संग्रहीत किया जा सकता है, जो Azure मशीन लर्निंग कार्यक्षेत्र से जुड़ा है।
एक बैच समापन बिंदु बनाएँ
बैच समापन बिंदु पर एक मॉडल को तैनात करने के लिए, आपको पहले बैच समापन बिंदु बनाना होगा।
बैच एंडपॉइंट बनाने के लिए, आप BatchEndpoint क्लास का उपयोग करेंगे। बैच समापन बिंदु नामों को Azure क्षेत्र के भीतर अद्वितीय होना चाहिए।
समापन बिंदु बनाने के लिए, निम्न आदेश का उपयोग करें:
# create a batch endpoint
endpoint = BatchEndpoint(
name="endpoint-example",
description="A batch endpoint",
)
ml_client.batch_endpoints.begin_create_or_update(endpoint)
नोक
Python SDK v2 के साथ बैच समापन बिंदु बनाने मेंकरने के लिए संदर्भ दस्तावेज़ का अन्वेषण करें।
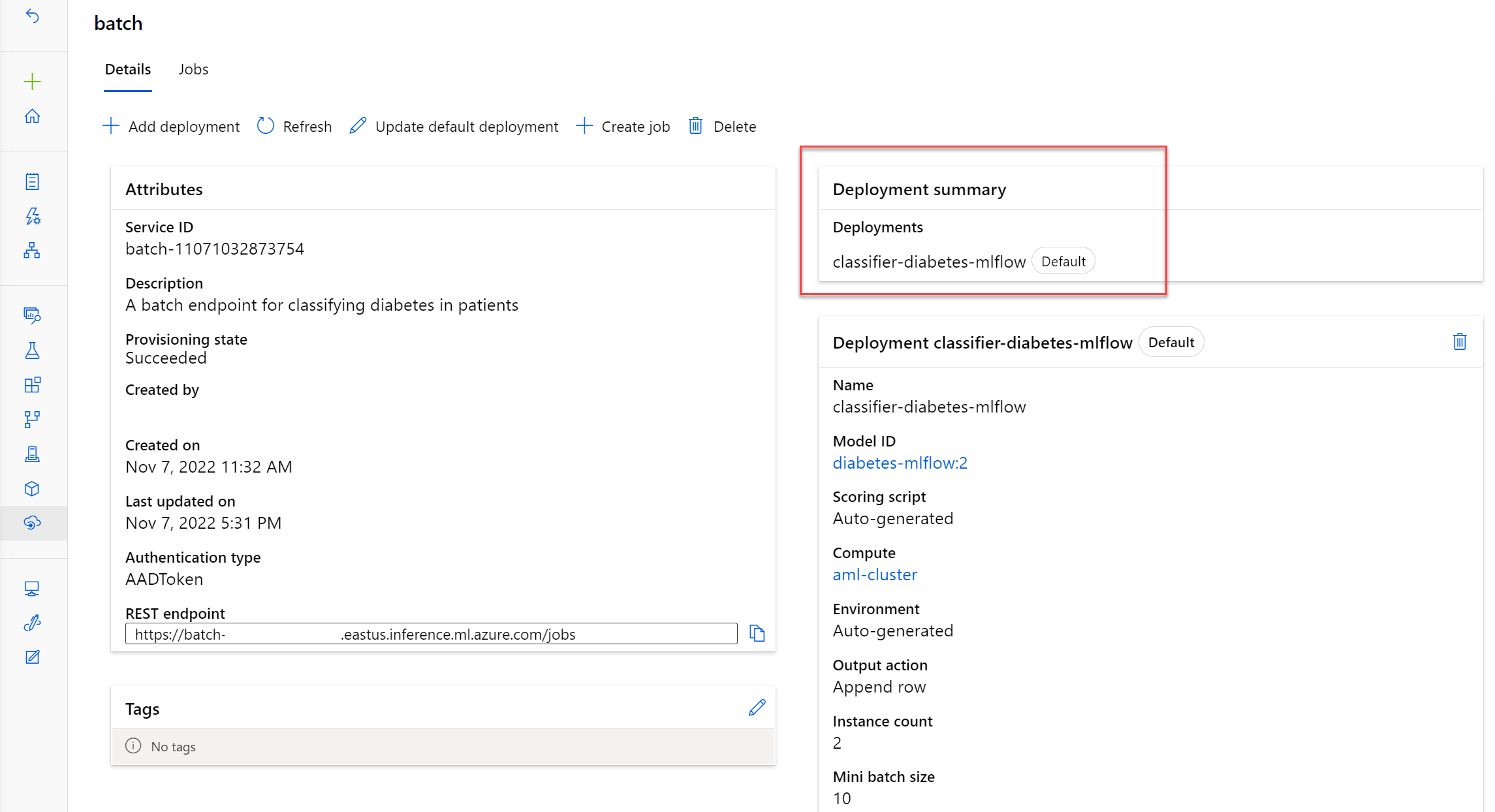
एक बैच समापन बिंदु के लिए एक मॉडल परिनियोजित करें
आप एक बैच समापन बिंदु पर कई मॉडल परिनियोजित कर सकते हैं। जब भी आप बैच समापन बिंदु को कॉल करते हैं, जो बैच स्कोरिंग कार्य को ट्रिगर करता है, तो डिफ़ॉल्ट परिनियोजन का उपयोग तब तक किया जाएगा जब तक कि अन्यथा निर्दिष्ट न हो।
बैच परिनियोजन के लिए कंप्यूट क्लस्टर का उपयोग करें
बैच परिनियोजन के लिए उपयोग करने के लिए आदर्श गणना Azure मशीन लर्निंग कंप्यूट क्लस्टर है। यदि आप चाहते हैं कि बैच स्कोरिंग कार्य समानांतर बैचों में नए डेटा को संसाधित करे, तो आपको एक से अधिक अधिकतम आवृत्तियों के साथ एक गणना क्लस्टर का प्रावधान करना होगा।
कंप्यूट क्लस्टर बनाने के लिए, आप AMLCompute क्लास का उपयोग कर सकते हैं।
from azure.ai.ml.entities import AmlCompute
cpu_cluster = AmlCompute(
name="aml-cluster",
type="amlcompute",
size="STANDARD_DS11_V2",
min_instances=0,
max_instances=4,
idle_time_before_scale_down=120,
tier="Dedicated",
)
cpu_cluster = ml_client.compute.begin_create_or_update(cpu_cluster)