पूर्वनिर्मित मॉडल का उपयोग करें
सुझाव
अधिक जानकारी के लिए टेक्स्ट और इमेज टैब देखें!
Azure दस्तावेज़ इंटेलिजेंस में पूर्वनिर्मित मॉडल आपको अपने स्वयं के मॉडलों को प्रशिक्षित किए बिना सामान्य प्रपत्र प्रकारों से डेटा निकालने में सक्षम बनाते हैं. Microsoft इन मॉडलों को बड़ी संख्या में नमूना दस्तावेज़ों पर प्रशिक्षित करता है, ताकि आप मानक दस्तावेज़ प्रकारों के लिए सटीक और विश्वसनीय परिणामों की अपेक्षा कर सकें.
दस्तावेज़ विश्लेषण मॉडल
डोमेन-विशिष्ट पूर्वनिर्मित मॉडल को देखने से पहले, दस्तावेज़ विश्लेषण मॉडल को समझना महत्वपूर्ण है जो उन्हें रेखांकित करते हैं।
मॉडल पढ़ें
रीड मॉडल दस्तावेजों और छवियों से मुद्रित और हस्तलिखित पाठ निकालता है। यह प्रत्येक टेक्स्ट लाइन की भाषा का पता लगाता है और वर्गीकृत करता है कि टेक्स्ट हस्तलिखित है या मुद्रित है। रीड मॉडल का उपयोग अन्य सभी दस्तावेज़ इंटेलिजेंस मॉडल में पाठ निष्कर्षण के लिए आधार के रूप में किया जाता है।
बहु-पृष्ठ PDF या TIFF फ़ाइलों के लिए, आप विश्लेषण के लिए पृष्ठ सीमा निर्दिष्ट करने के लिए अपने अनुरोध में पैरामीटर का pages उपयोग कर सकते हैं।
रीड मॉडल आदर्श है जब आप बिना किसी निश्चित या पूर्वानुमानित संरचना वाले दस्तावेज़ों से शब्द और पंक्तियाँ निकालना चाहते हैं।
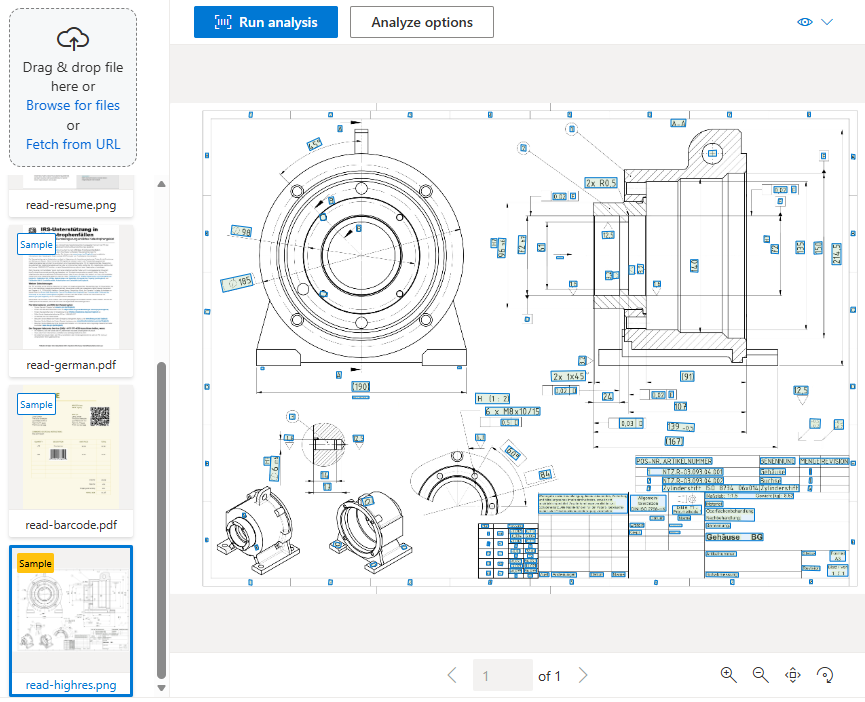
लेआउट मॉडल
लेआउट मॉडल चयन चिह्नों, तालिकाओं और दस्तावेज़ संरचना की जानकारी का पता लगाने के साथ रीड मॉडल के पाठ निष्कर्षण का विस्तार करता है। यह कुंजी-मूल्य जोड़े निकालने के लिए एक वैकल्पिक keyValuePairs सुविधा का भी समर्थन करता है।
जब आप किसी दस्तावेज़ को डिजिटाइज़ करते हैं, तो यह कोणीय हो सकता है, या तालिकाओं में मर्ज किए गए कक्षों या अपूर्ण पंक्तियों के साथ जटिल संरचनाएँ हो सकती हैं. लेआउट मॉडल इन कठिनाइयों को संभाल सकता है। प्रत्येक तालिका कक्ष को उसकी सामग्री, बाउंडिंग बॉक्स स्थिति और पंक्ति/स्तंभ अनुक्रमणिका के साथ निकाला जाता है।
चयन चिह्न (चेकबॉक्स और रेडियो बटन) उनके बाउंडिंग बॉक्स, आत्मविश्वास स्तर और क्या वे चयनित हैं, के साथ निकाले जाते हैं।
नोट
सामान्य दस्तावेज़ मॉडल दस्तावेज़ इंटेलिजेंस के पुराने संस्करणों में उपलब्ध था, लेकिन रिलीज़ में बहिष्कृत 2023-10-31-preview कर दिया गया था। कुंजी-मूल्य जोड़ी और इकाई निष्कर्षण के लिए इसकी कार्यक्षमता को लेआउट मॉडल और अन्य विशेषताओं में शामिल किया गया है।
विशिष्ट दस्तावेज़ प्रकारों के लिए पूर्वनिर्मित मॉडल
Azure दस्तावेज़ इंटेलिजेंस में विशिष्ट दस्तावेज़ प्रकारों पर प्रशिक्षित पूर्वनिर्मित मॉडल शामिल हैं। निम्न पूर्वनिर्मित मॉडल सामान्य व्यावसायिक दस्तावेज़ों से फ़ील्ड निकालने के लिए उपलब्ध कुछ उदाहरण हैं:
वित्तीय और कानूनी दस्तावेज
| नमूना | विवरण |
|---|---|
| इन्वायस | ग्राहक का नाम, विक्रेता विवरण, खरीद आदेश संख्या, चालान और नियत तिथियां, बिलिंग और शिपिंग पते, लाइन आइटम और योग निकालता है। |
| प्राप्ति | व्यापारी विवरण, लेन-देन की तारीख और समय, लाइन आइटम और योग निकालता है। एकल-पृष्ठ होटल रसीद प्रसंस्करण का समर्थन करता है। |
| बैंक स्टेटमेंट | खाता जानकारी, शुरुआत और समाप्ति शेष राशि, और लेनदेन विवरण निकालता है। |
| जाँच | आदाता राशि, तारीख और अन्य प्रासंगिक जानकारी निकालता है। |
| पे स्टब | मजदूरी, घंटे, कटौती, शुद्ध वेतन और अन्य सामान्य वेतन स्टब फ़ील्ड निकालता है। |
| क्रेडिट कार्ड | भुगतान कार्ड की जानकारी निकालता है. |
| इक़रारनामा करना | समझौते और पार्टी के विवरण निकालता है। |
अमेरिकी कर दस्तावेज़
| नमूना | विवरण |
|---|---|
| एकीकृत अमेरिकी कर | एक एकल मॉडल जो किसी भी समर्थित US कर प्रपत्र प्रकार से निकालता है। |
| डब्ल्यू-2 | कर योग्य मुआवजे का विवरण निकालता है। |
| 1098 और विविधताएं | बंधक ब्याज और संबंधित विवरण निकालता है। |
| 1099 और विविधताएं | विभिन्न स्रोतों से आय निकालता है। |
| 1040 और विविधताएं | व्यक्तिगत आयकर रिटर्न विवरण निकालता है। |
अमेरिकी बंधक दस्तावेज
| नमूना | विवरण |
|---|---|
| 1003 (यूआरएलए) | ऋण आवेदन विवरण निकालता है। |
| 1004 (उरार) | संपत्ति मूल्यांकन से जानकारी निकालता है। |
| 1005 | रोजगार की सत्यापन-जानकारी निकालता है। |
| 1008 | ऋण संचरण विवरण निकालता है। |
| समापन प्रकटीकरण | अंतिम समापन ऋण शर्तों को निकालता है। |
व्यक्तिगत पहचान दस्तावेज
| नमूना | विवरण |
|---|---|
| आईडी दस्तावेज़ | अमेरिकी ड्राइविंग लाइसेंस, यूरोपीय संघ आईडी और ड्राइवर के लाइसेंस, और अंतरराष्ट्रीय पासपोर्ट से विवरण निकालता है। इसमें नाम, जन्म तिथि, दस्तावेज़ संख्या और समर्थन या प्रतिबंध शामिल हैं। |
| स्वास्थ्य बीमा कार्ड | अमेरिकी स्वास्थ्य बीमा कार्ड से सामान्य फ़ील्ड निकालता है। |
| विवाह प्रमाण पत्र | प्रमाणित विवाह जानकारी निकालता है। |
महत्वपूर्ण
आईडी दस्तावेज़ मॉडल अधिकांश न्यायालयों में डेटा सुरक्षा कानूनों द्वारा कवर की गई व्यक्तिगत जानकारी निकालता है। सुनिश्चित करें कि आपके पास उनके डेटा को संग्रहीत करने के लिए व्यक्ति की अनुमति है और आप सभी लागू कानूनी आवश्यकताओं का अनुपालन करते हैं।
पूर्वनिर्मित मॉडल की विशेषताएं
पूर्वनिर्मित मॉडल दस्तावेज़ों से विभिन्न प्रकार के डेटा निकालने के लिए डिज़ाइन किए गए हैं। इन सुविधाओं में निम्न शामिल हैं:
- पाठ निष्कर्षण: सभी पूर्वनिर्मित मॉडल हस्तलिखित और मुद्रित पाठ से पंक्तियाँ और शब्द निकालते हैं।
- कुंजी-मान जोड़े: पाठ के स्पैन जो एक लेबल और उसकी प्रतिक्रिया की पहचान करते हैं। उदाहरण के लिए, वजन और 31 किलो।
- चयन चिह्न: चेकबॉक्स और रेडियो बटन, जिसमें यह भी शामिल है कि वे चुने गए हैं या नहीं।
- तालिकाएँ: कक्षों में डेटा, जिसमें स्तंभों और पंक्तियों की संख्या, स्तंभ और पंक्ति शीर्षक और मर्ज किए गए कक्ष शामिल हैं.
-
फ़ील्ड्स: एक विशिष्ट प्रपत्र प्रकार के लिए प्रशिक्षित मॉडल फ़ील्ड के एक निश्चित सेट की पहचान करते हैं। उदाहरण के लिए, चालान मॉडल निकालता है
CustomerNameऔर .InvoiceTotal
प्रीबिल्ट बनाम कस्टम मॉडल का उपयोग कब करें
पूर्वनिर्मित मॉडल सबसे आम दस्तावेज़ प्रकारों को कवर करते हैं। यदि आपके पास उद्योग-विशिष्ट या अद्वितीय प्रपत्र प्रकार है, तो आपको कस्टम मॉडल के साथ अधिक सटीक परिणाम मिल सकते हैं. हालाँकि, कस्टम मॉडल को प्रशिक्षित करने के लिए समय और नमूना डेटा की आवश्यकता होती है। कस्टम मॉडल विकास में निवेश करने से पहले हमेशा जांच लें कि आपके परिदृश्य के लिए एक पूर्वनिर्मित मॉडल मौजूद है या नहीं।