द्विआधारी वर्गीकरण
नोट
अधिक जानकारी के लिए टेक्स्ट और इमेज टैब देखें!
वर्गीकरण, प्रतिगमन की तरह, एक पर्यवेक्षित मशीन सीखने की तकनीक है; और इसलिए मॉडल के प्रशिक्षण, सत्यापन और मूल्यांकन की समान पुनरावृत्ति प्रक्रिया का पालन करता है। प्रतिगमन मॉडल जैसे संख्यात्मक मूल्यों की गणना करने के बजाय, वर्गीकरण मॉडल को प्रशिक्षित करने के लिए उपयोग किए जाने वाले एल्गोरिदम कक्षा असाइनमेंट के लिए संभाव्यता मूल्यों की गणना करते हैं और मॉडल प्रदर्शन का आकलन करने के लिए उपयोग किए जाने वाले मूल्यांकन मैट्रिक्स अनुमानित कक्षाओं की वास्तविक कक्षाओं की तुलना करते हैं।
बाइनरी वर्गीकरण एल्गोरिदम का उपयोग एक मॉडल को प्रशिक्षित करने के लिए किया जाता है जो एक वर्ग के लिए दो संभावित लेबलों में से एक की भविष्यवाणी करता है। अनिवार्य रूप से, सही या गलत की भविष्यवाणी करना। अधिकांश वास्तविक परिदृश्यों में, मॉडल को प्रशिक्षित और मान्य करने के लिए उपयोग किए जाने वाले डेटा अवलोकनों में कई फीचर (x) मान और एक y मान होता है जो या तो 1 या 0 होता है।
उदाहरण - बाइनरी वर्गीकरण
यह समझने के लिए कि बाइनरी वर्गीकरण कैसे काम करता है, आइए एक सरलीकृत उदाहरण देखें जो यह अनुमान लगाने के लिए एकल सुविधा (x) का उपयोग करता है कि लेबल y 1 या 0 है या नहीं। इस उदाहरण में, हम रोगी के रक्त शर्करा के स्तर का उपयोग यह अनुमान लगाने के लिए करेंगे कि रोगी को मधुमेह है या नहीं। यहां वह डेटा है जिसके साथ हम मॉडल को प्रशिक्षित करेंगे:

|

|
|---|---|
| रक्त ग्लूकोज (x) | मधुमेह-संबंधी? (वाई) |
| 67 | 12 |
| 103 | 1 |
| 114 | 1 |
| 72 | 12 |
| 116 | 1 |
| 65 | 12 |
एक द्विआधारी वर्गीकरण मॉडल का प्रशिक्षण
मॉडल को प्रशिक्षित करने के लिए, हम प्रशिक्षण डेटा को एक फ़ंक्शन में फिट करने के लिए एक एल्गोरिथ्म का उपयोग करेंगे जो क्लास लेबल के सच होने की संभावना की गणना करता है (दूसरे शब्दों में, रोगी को मधुमेह है)। प्रायिकता को 0.0 और 1.0 के बीच के मान के रूप में मापा जाता है, जैसे कि सभी संभावित वर्गों के लिए कुल संभावना 1.0 है। उदाहरण के लिए, यदि किसी रोगी को मधुमेह होने की संभावना 0.7 है, तो 0.3 की इसी संभावना है कि रोगी मधुमेह नहीं है।
ऐसे कई एल्गोरिदम हैं जिनका उपयोग बाइनरी वर्गीकरण के लिए किया जा सकता है, जैसे कि लॉजिस्टिक रिग्रेशन, जो 0.0 और 1.0 के बीच के मानों के साथ एक सिग्मॉइड (एस-आकार) फ़ंक्शन प्राप्त करता है, जैसे:
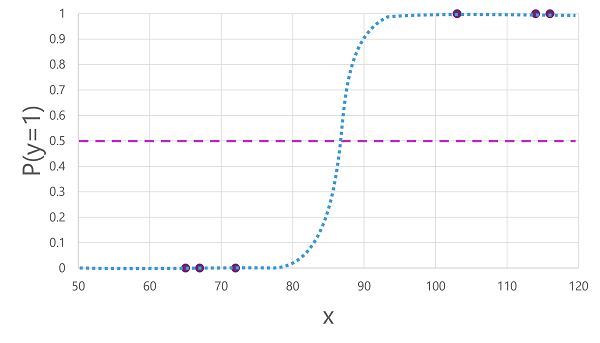
नोट
इसके नाम के बावजूद, मशीन लर्निंग में लॉजिस्टिक रिग्रेशन का उपयोग वर्गीकरण के लिए किया जाता है, प्रतिगमन के लिए नहीं। महत्वपूर्ण बिंदु इसके द्वारा उत्पादित फ़ंक्शन की लॉजिस्टिक प्रकृति है, जो निचले और ऊपरी मूल्य (बाइनरी वर्गीकरण के लिए उपयोग किए जाने पर 0.0 और 1.0) के बीच एस-आकार के वक्र का वर्णन करता है।
एल्गोरिथ्म द्वारा निर्मित फ़ंक्शन x के दिए गए मान के लिए y के सत्य (y = 1) होने की संभावना का वर्णन करता है। गणितीय रूप से, आप फ़ंक्शन को इस तरह व्यक्त कर सकते हैं:
एफ (एक्स) = पी (वाई = 1 | एक्स)
प्रशिक्षण डेटा में छह टिप्पणियों में से तीन के लिए, हम जानते हैं कि y निश्चित रूप से सत्य है, इसलिए उन टिप्पणियों की संभावना है कि y = 1 1.0 है और अन्य तीन के लिए, हम जानते हैं कि y निश्चित रूप से गलत है, इसलिए संभावना है कि y = 1 0.0 है। एस-आकार का वक्र संभाव्यता वितरण का वर्णन करता है ताकि रेखा पर x के मान को प्लॉट करना संबंधित संभावना की पहचान करे कि y1 है।
आरेख में उस सीमा को इंगित करने के लिए एक क्षैतिज रेखा भी शामिल है जिस पर इस फ़ंक्शन पर आधारित एक मॉडल सही (1) या गलत (0) की भविष्यवाणी करेगा। दहलीज y (P(y) = 0.5) के लिए मध्य-बिंदु पर स्थित है। इस बिंदु पर या उससे ऊपर के किसी भी मान के लिए, मॉडल सही (1) की भविष्यवाणी करेगा; जबकि इस बिंदु से नीचे के किसी भी मान के लिए यह गलत (0) की भविष्यवाणी करेगा। उदाहरण के लिए, 90 के रक्त शर्करा के स्तर वाले रोगी के लिए, फ़ंक्शन के परिणामस्वरूप 0.9 का संभाव्यता मान होगा। चूंकि 0.9 0.5 की सीमा से अधिक है, इसलिए मॉडल सच (1) की भविष्यवाणी करेगा - दूसरे शब्दों में, रोगी को मधुमेह होने की भविष्यवाणी की जाती है।
एक द्विआधारी वर्गीकरण मॉडल का मूल्यांकन
प्रतिगमन के साथ, बाइनरी वर्गीकरण मॉडल को प्रशिक्षित करते समय आप डेटा के एक यादृच्छिक सबसेट को वापस पकड़ते हैं जिसके साथ प्रशिक्षित मॉडल को मान्य करना है। आइए मान लें कि हमने अपने मधुमेह क्लासिफायरियर को मान्य करने के लिए निम्नलिखित डेटा वापस रखा है:
| रक्त ग्लूकोज (x) | मधुमेह-संबंधी? (वाई) |
|---|---|
| 66 | 12 |
| 107 | 1 |
| 112 | 1 |
| 71 | 12 |
| 87 | 1 |
| 89 | 1 |
लॉजिस्टिक फ़ंक्शन को लागू करने से हमने पहले x मानों को निम्न प्लॉट में परिणाम दिया था।
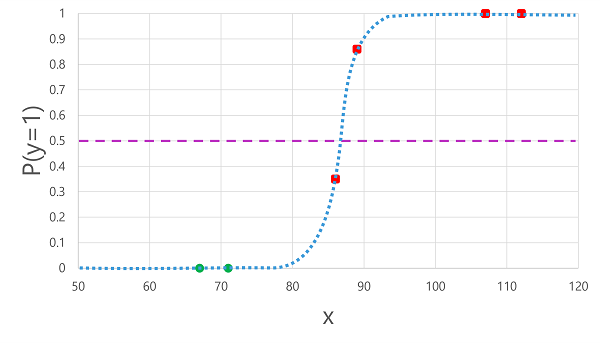
फ़ंक्शन द्वारा गणना की गई संभावना सीमा से ऊपर या नीचे है या नहीं, इसके आधार पर, मॉडल प्रत्येक अवलोकन के लिए 1 या 0 का अनुमानित लेबल उत्पन्न करता है। फिर हम अनुमानित वर्ग लेबल (ŷ) की तुलना वास्तविक वर्ग लेबल (y) से कर सकते हैं, जैसा कि यहां दिखाया गया है:
| रक्त ग्लूकोज (x) | वास्तविक मधुमेह निदान (वाई) | अनुमानित मधुमेह निदान (ŷ) |
|---|---|---|
| 66 | 12 | 12 |
| 107 | 1 | 1 |
| 112 | 1 | 1 |
| 71 | 12 | 12 |
| 87 | 1 | 12 |
| 89 | 1 | 1 |
बाइनरी वर्गीकरण मूल्यांकन मेट्रिक्स
बाइनरी वर्गीकरण मॉडल के लिए मूल्यांकन मेट्रिक्स की गणना करने में पहला कदम आमतौर पर प्रत्येक संभावित वर्ग लेबल के लिए सही और गलत भविष्यवाणियों की संख्या का मैट्रिक्स बनाना है:
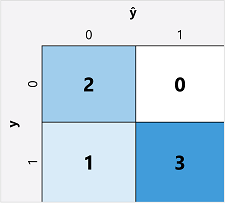
इस विज़ुअलाइज़ेशन को भ्रम मैट्रिक्स कहा जाता है, और यह भविष्यवाणी के योग दिखाता है जहां:
- ŷ=0 और y=0: सही नकारात्मक ( TN)
- ŷ=1 और y=0: गलत सकारात्मक ( FP)
- ŷ=0 और y=1: गलत नकारात्मक ( FN)
- ŷ=1 और y=1: सही सकारात्मक ( टीपी)
भ्रम मैट्रिक्स की व्यवस्था ऐसी है कि सही (सही) भविष्यवाणियों को ऊपर-बाएं से नीचे-दाएं एक विकर्ण रेखा में दिखाया गया है। अक्सर, रंग-तीव्रता का उपयोग प्रत्येक कोशिका में भविष्यवाणियों की संख्या को इंगित करने के लिए किया जाता है, इसलिए एक मॉडल पर एक त्वरित नज़र जो अच्छी तरह से भविष्यवाणी करती है, उसे एक गहरी छायांकित विकर्ण प्रवृत्ति को प्रकट करना चाहिए।
सटीकता
भ्रम मैट्रिक्स से आप जिस सबसे सरल मीट्रिक की गणना कर सकते हैं, वह सटीकता है - भविष्यवाणियों का अनुपात जो मॉडल को सही लगा। सटीकता की गणना इस प्रकार की जाती है:
(टीएन + टीपी) ÷ (टीएन + एफएन + एफपी + टीपी)
हमारे मधुमेह के उदाहरण के मामले में, गणना है:
(2+3) ÷ (2+1+0+3)
= 5 ÷ 6
= 0.83
इसलिए हमारे सत्यापन डेटा के लिए, मधुमेह वर्गीकरण मॉडल ने 83% समय सही भविष्यवाणियों का उत्पादन किया।
सटीकता शुरू में एक मॉडल का मूल्यांकन करने के लिए एक अच्छे मीट्रिक की तरह लग सकती है, लेकिन इस पर विचार करें। मान लीजिए कि 11% आबादी को मधुमेह है। आप एक मॉडल बना सकते हैं जो हमेशा 0 की भविष्यवाणी करता है, और यह 89%की सटीकता प्राप्त करेगा, भले ही यह उनकी विशेषताओं का मूल्यांकन करके रोगियों के बीच अंतर करने का कोई वास्तविक प्रयास नहीं करता है। हमें वास्तव में इस बात की गहरी समझ की आवश्यकता है कि मॉडल सकारात्मक मामलों के लिए 1 और नकारात्मक मामलों के लिए 0 की भविष्यवाणी करने में कैसा प्रदर्शन करता है।
याद करना
रिकॉल एक मीट्रिक है जो सकारात्मक मामलों के अनुपात को मापता है जिसे मॉडल ने सही ढंग से पहचाना है। दूसरे शब्दों में, मधुमेह वाले रोगियों की संख्या की तुलना में, मॉडल ने कितने मधुमेह होने की भविष्यवाणी की?
याद करने का सूत्र है:
टीपी ÷ (टीपी + एफएन)
हमारे मधुमेह उदाहरण के लिए:
3 ÷ (3+1)
= 3 ÷ 4
= 0.75
इसलिए हमारे मॉडल ने 75% रोगियों की सही पहचान की, जिन्हें मधुमेह है।
यथार्थता
प्रेसिजन याद करने के लिए एक समान मीट्रिक है, लेकिन अनुमानित सकारात्मक मामलों के अनुपात को मापता है जहां सही लेबल वास्तव में सकारात्मक है। दूसरे शब्दों में, मॉडल द्वारा भविष्यवाणी की गई रोगियों का अनुपात वास्तव में मधुमेह है ?
सटीकता के लिए सूत्र है:
टीपी ÷ (टीपी + एफपी)
हमारे मधुमेह उदाहरण के लिए:
3 ÷ (3+0)
= 3 ÷ 3
= 1.0
तो हमारे मॉडल द्वारा भविष्यवाणी की गई रोगियों में से 100% को मधुमेह है, वास्तव में मधुमेह है।
F1-स्कोर
F1-स्कोर एक समग्र मीट्रिक है जो याद और सटीकता को जोड़ती है। F1-स्कोर का सूत्र है:
(2 एक्स प्रेसिजन एक्स रिकॉल) ÷ (प्रेसिजन + रिकॉल)
हमारे मधुमेह उदाहरण के लिए:
(2 x 1.0 x 0.75) ÷ (1.0 + 0.75)
= 1.5 ÷ 1.75
= 0.86
वक्र के नीचे क्षेत्र (AUC)
रिकॉल का दूसरा नाम सही सकारात्मक दर (टीपीआर) है, और एक समकक्ष मीट्रिक है जिसे झूठी सकारात्मक दर (एफपीआर) कहा जाता है जिसकी गणना एफपी÷(एफपी+टीएन) के रूप में की जाती है। हम पहले से ही जानते हैं कि 0.5 की सीमा का उपयोग करते समय हमारे मॉडल के लिए टीपीआर 0.75 है, और हम 0÷2 = 0 के मूल्य की गणना करने के लिए एफपीआर के सूत्र का उपयोग कर सकते हैं।
बेशक, अगर हम उस सीमा को बदलना चाहते थे जिसके ऊपर मॉडल सच (1) की भविष्यवाणी करता है, तो यह सकारात्मक और नकारात्मक भविष्यवाणियों की संख्या को प्रभावित करेगा; और इसलिए टीपीआर और एफपीआर मेट्रिक्स बदलें। इन मेट्रिक्स का उपयोग अक्सर एक प्राप्त ऑपरेटर विशेषता (आरओसी) वक्र की साजिश रचकर एक मॉडल का मूल्यांकन करने के लिए किया जाता है जो टीपीआर और एफपीआर की तुलना 0.0 और 1.0 के बीच हर संभव थ्रेशोल्ड मान के लिए करता है:
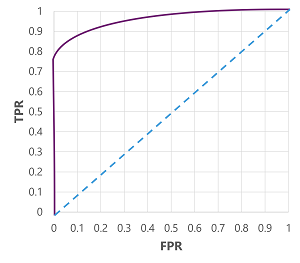
एक आदर्श मॉडल के लिए आरओसी वक्र सीधे टीपीआर अक्ष पर बाईं ओर और फिर शीर्ष पर एफपीआर अक्ष के पार जाएगा। चूंकि वक्र के लिए प्लॉट क्षेत्र 1x1 मापता है, इसलिए इस पूर्ण वक्र के नीचे का क्षेत्र 1.0 होगा (जिसका अर्थ है कि मॉडल 100% समय सही है)। इसके विपरीत, नीचे-बाएं से ऊपरी-दाएं तक एक विकर्ण रेखा उन परिणामों का प्रतिनिधित्व करती है जो एक बाइनरी लेबल का बेतरतीब ढंग से अनुमान लगाकर प्राप्त किए जाएंगे; 0.5 के वक्र के तहत एक क्षेत्र का उत्पादन। दूसरे शब्दों में, दो संभावित वर्ग लेबल दिए गए, आप यथोचित रूप से 50% समय का सही अनुमान लगाने की उम्मीद कर सकते हैं।
हमारे मधुमेह मॉडल के मामले में, ऊपर वक्र का उत्पादन किया जाता है, और वक्र (एयूसी) मीट्रिक के तहत क्षेत्र 0.875 है। चूंकि एयूसी 0.5 से अधिक है, इसलिए हम यह निष्कर्ष निकाल सकते हैं कि मॉडल यह अनुमान लगाने में बेहतर प्रदर्शन करता है कि किसी मरीज को बेतरतीब ढंग से अनुमान लगाने की तुलना में मधुमेह है या नहीं।