दस्तावेज़ों से जानकारी निकालें
सुझाव
अधिक जानकारी के लिए टेक्स्ट और इमेज टैब देखें!
आज की व्यावसायिक प्रक्रियाएं बहुत अधिक दस्तावेजों में निहित डेटा पर निर्भर करती हैं जैसे प्रपत्र, रसीदें और चालान। मैन्युअल प्रसंस्करण देरी और त्रुटियाँ पेश कर सकता है, जिससे डेटा निष्कर्षण स्वचालन पहले से कहीं अधिक महत्वपूर्ण हो जाता है।
Azure सामग्री समझ कैसे काम करती है
Azure सामग्री समझ एक मॉडल-चालित निष्कर्षण वर्कफ़्लो का अनुसरण करती है जिसमें असंरचित सामग्री को अंतर्ग्रहण, विश्लेषण और संरचित डेटा के रूप में वापस लाया जाता है।
सामग्री निगलना: आप Azure सामग्री समझ को सबमिट करते हैं।
एआई-संचालित विश्लेषण: सेवा सामग्री का विश्लेषण करने के लिए ऑप्टिकल कैरेक्टर रिकॉग्निशन (ओसीआर), स्पीच रिकग्निशन, नेचुरल लैंग्वेज अंडरस्टैंडिंग और मल्टीमॉडल एआई मॉडल के संयोजन का उपयोग करती है।
संरचित आउटपुट: सेवा आपके मॉडल से मेल खाने वाले संरचित परिणाम (उदाहरण के लिए, JSON में) लौटाती है—जिससे डेटा को स्टोर करना, खोजना या डाउनस्ट्रीम सिस्टम में एकीकृत करना आसान हो जाता है।
Note
JSON (जावास्क्रिप्ट ऑब्जेक्ट नोटेशन) एक टेक्स्ट-आधारित डेटा प्रारूप है जिसका उपयोग सिस्टम के बीच संरचित डेटा को संग्रहीत और विनिमय करने के लिए किया जाता है। मनुष्यों के लिए पढ़ना और लिखना आसान है, और मशीनों के लिए पार्स करना और उत्पन्न करना आसान है।
स्कीमा को समझें
ओसीआर (ऑप्टिकल कैरेक्टर रिकॉग्निशन) एक कंप्यूटर को चित्रों से पाठ को 'पढ़ने' की अनुमति देता है, जैसे कि स्कैन किए गए दस्तावेज़, रसीदों की तस्वीरें, या मुद्रित पृष्ठों की छवियां, और उस पाठ को संपादन योग्य और खोजने योग्य डिजिटल पाठ में बदल दें। मूल ओसीआर मुद्रित पाठ को पहचानने में मदद करता है, पाठ निष्कर्षण पर ध्यान केंद्रित करता है , और शब्दों के बीच अर्थ, संदर्भ या संबंधों को नहीं समझता है।
Azure Content Understanding की दस्तावेज़ विश्लेषण क्षमताएं सरल OCR-आधारित पाठ निष्कर्षण से परे जाती हैं ताकि फ़ील्ड और उनके मूल्यों के स्कीमा-आधारित निष्कर्षण को शामिल किया जा सके। स्कीमा-संचालित दृष्टिकोण वह है जो Azure सामग्री समझ को बुनियादी OCR या ट्रांसक्रिप्शन सेवाओं से अलग करता है।
स्कीमा बताती है कि आप कौन सी जानकारी निकालना चाहते हैं और उस जानकारी को कैसे संरचित किया जाना चाहिए. जब आप किसी स्कीमा को परिभाषित करते हैं, तो आप निकालने के लिए फ़ील्ड्स निर्दिष्ट करते हैं. स्कीमा उन विशिष्ट फ़ील्ड्स या निकायों को सूचीबद्ध करती है जिनकी आप परवाह करते हैं.
उदाहरण के लिए, मान लें कि आप एक स्कीमा परिभाषित करते हैं जिसमें आमतौर पर इनवॉइस में पाए जाने वाले सामान्य फ़ील्ड शामिल होते हैं, जैसे:
- विक्रेता का नाम
- इनवॉइस नंबर
- चालान की तारीख
- ग्राहक का नाम
- कस्टम पता
- आइटम - ऑर्डर किए गए आइटम, जिनमें से प्रत्येक में शामिल हैं:
- आइटम विवरण
- इकाई मूल्य
- मात्रा का आदेश दिया
- लाइन आइटम कुल
- इनवॉइस उप-योग
- Tax
- शिपिंग चार्ज
- इनवॉइस कुल
अब मान लीजिए कि आपको निम्नलिखित चालान से यह जानकारी निकालने की आवश्यकता है:
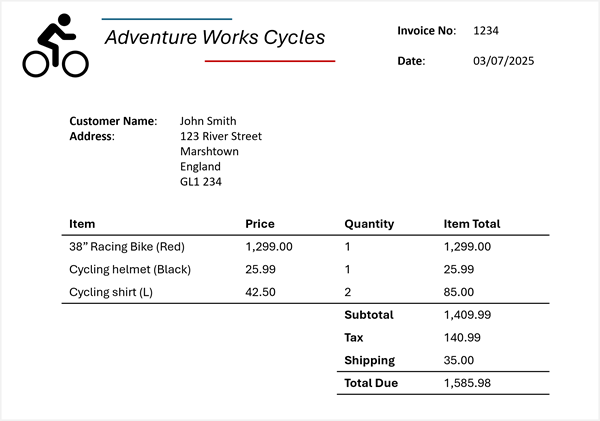
Azure सामग्री समझ आपके इनवॉइस पर इनवॉइस स्कीमा लागू कर सकती है और संबंधित फ़ील्ड की पहचान कर सकती है, भले ही उन पर अलग-अलग नामों से लेबल किया गया हो (या बिल्कुल भी लेबल नहीं किया गया हो). परिणामी विश्लेषण इस तरह एक परिणाम उत्पन्न करता है:

स्कीमा क्षेत्र संरचना को भी परिभाषित करता है। स्कीमा संरचित और नेस्टेड फ़ील्ड का समर्थन करते हैं, न कि केवल सपाट पाठ। उदाहरण के लिए:
-
Itemsएक संग्रह है - प्रत्येक आइटम में ,
descriptionunit price, ,quantityऔरline total
संरचित फ़ील्ड की पहचान करने से Azure Content Understanding को मूल्यों के बीच संबंधों को समझने की अनुमति मिलती है, कुछ ऐसा जो OCR अकेले नहीं कर सकता.
इनवॉइस उदाहरण में, प्रत्येक खोजे गए फ़ील्ड के लिए, आप नेस्टेड मान निकाल सकते हैं:
- विक्रेता का नाम: एडवेंचर वर्क्स साइकिल
- चालान संख्या: 1234
- चालान की तारीख: 03/07/2025
- ग्राहक का नाम: जॉन स्मिथ
- कस्टम पता: 123 रिवर स्ट्रीट, मार्शटाउन, इंग्लैंड, GL1 234
-
आइटम:
- आइटम 1:
- आइटम विवरण: 38 "रेसिंग बाइक (लाल)
- इकाई मूल्य: 1299.00
- मात्रा का आदेश: 1
- लाइन आइटम कुल: 1299.00
- आइटम 2:
- आइटम विवरण: सायक्लिंग हेलमेट (काला)
- इकाई मूल्य: 25.99
- मात्रा का आदेश: 1
- लाइन आइटम कुल: 25.99
- आइटम 3:
- आइटम विवरण: सायक्लिंग शर्ट (एल)
- इकाई मूल्य: 42.50
- मात्रा का आदेश दिया: 2
- लाइन आइटम कुल: 85.00
- आइटम 1:
- इनवॉइस उप-योग: 1409.99
- टैक्स: 140.99
- शिपिंग प्रभार: 35.00
- चालान कुल: 1585.98
Azure सामग्री समझ अपेक्षित अर्थ निकालती है, न कि केवल लेबल। स्कीमा शब्दार्थ रूप से लागू होते हैं, जिसका अर्थ है:
- लेबल भिन्न होने पर भी फ़ील्ड निकाला जा सकता है
- लेबल अनुपलब्ध होने पर भी फ़ील्ड निकाला जा सकता है
उदाहरण के लिए, इनवॉइस नंबर, इनवॉइस # या एक लेबल न किया गया नंबर सभी मैप InvoiceNumber कर सकते हैं यदि विश्लेषक यह निर्धारित करता है कि वे एक ही अवधारणा का प्रतिनिधित्व करते हैं।
विश्लेषकों को समझें
एक विश्लेषक Azure सामग्री समझ में एक इकाई है जो इनपुट लेता है, AI विश्लेषण लागू करता है, और संरचित परिणाम उत्पन्न करता है। विश्लेषक लगातार सभी आने वाली सामग्री पर एक ही निष्कर्षण तर्क लागू करते हैं। एक बार जब यह कॉन्फ़िगर हो जाता है, तो एक विश्लेषक यह सुनिश्चित करता है कि प्रत्येक विश्लेषण अनुरोध के लिए एक स्कीमा का लगातार पुन: उपयोग किया जाता है। विश्लेषक पूर्वानुमानित JSON परिणाम भी उत्पन्न करते हैं। संरचित परिणाम डाउनस्ट्रीम प्रसंस्करण (भंडारण, खोज, स्वचालन) को आसान बनाते हैं।
Azure सामग्री समझ सामान्य परिदृश्यों के लिए पूर्वनिर्मित विश्लेषक प्रदान करता है और आपकी आवश्यकताओं के अनुरूप कस्टम विश्लेषक का समर्थन करता है। उच्च स्तर पर:
- आप एक विश्लेषक चुनते हैं या बनाते हैं।
- विश्लेषक में क्षेत्रों और संरचना को परिभाषित करने वाली एक स्कीमा शामिल है।
- आप विश्लेषण के लिए सामग्री सबमिट करते हैं
- सेवा स्कीमा लागू करती है
- आपको स्कीमा से मेल खाने वाले संरचित JSON परिणाम प्राप्त होते हैं
फाउंड्री पोर्टल में Azure सामग्री समझ का उपयोग करना
Note
फाउंड्री पोर्टल में एक क्लासिक यूजर इंटरफेस (यूआई) और एक नया यूजर इंटरफेस है।
एक Microsoft फाउंड्री संसाधन बनाने के बाद, आप Azure सामग्री समझ का परीक्षण करने के लिए new फाउंड्री पोर्टल इंटरफ़ेस का उपयोग कर सकते हैं। फाउंड्री पोर्टल सामग्री उदाहरण प्रदान करता है और आपको विश्लेषण के लिए अपनी सामग्री अपलोड करने की अनुमति देता है।
आप स्रोत दस्तावेज़ का चयन करने और जानकारी के डिफ़ॉल्ट फ़ील्ड निकालने के लिए विज़ुअल इंटरफ़ेस का उपयोग कर सकते हैं। उदाहरण के लिए, जब आप किसी दस्तावेज़ की छवि पर Azure सामग्री समझ का प्रयास करते हैं, तो सेवा दस्तावेज़ पाठ और पाठ लेआउट जानकारी देता है.

Azure Content Understanding के विश्लेषक दस्तावेज़ों में पाठ मानों की पहचान करते हैं और उन्हें विशिष्ट फ़ील्ड में मैप करते हैं. उदाहरण के लिए, एक इनवॉइस दिया गया है, सेवा फ़ील्ड (जैसे विक्रेता का पता) और फ़ील्ड में डेटा (जैसे 123 456th स्ट्रीट) लौटाती है।

फाउंड्री पोर्टल में, आप प्रसंस्करण के JSON परिणाम भी देख सकते हैं।

Azure सामग्री समझ के साथ एक क्लाइंट एप्लिकेशन बनाना
आप सामग्री समझ एपीआई का उपयोग एक हल्का क्लाइंट एप्लिकेशन बनाने के लिए कर सकते हैं जो प्रोग्रामेटिक रूप से डेटा निकालता है।
Note
क्लाइंट एप्लिकेशन एक सॉफ्टवेयर प्रोग्राम है जो उपयोगकर्ता के डिवाइस पर चलता है और किसी अन्य सिस्टम, आमतौर पर एक सर्वर, नेटवर्क पर सेवाओं या डेटा का अनुरोध करता है। क्लाइंट एक एप्लिकेशन का हिस्सा है जिसके साथ उपयोगकर्ता इंटरैक्ट करते हैं, जबकि सर्वर पर्दे के पीछे भारी काम करता है। एप्लिकेशन किसी सेवा से डेटा या कार्यों का अनुरोध कर सकते हैं और एपीआई का उपयोग करके एक संरचित प्रतिक्रिया प्राप्त कर सकते हैं।
जब आप सामग्री को समझने वाले एपीआई का उपयोग करते हैं, तो आप एक पूर्वनिर्मित विश्लेषक चुन सकते हैं या एक कस्टम विश्लेषक बना सकते हैं। पूर्वनिर्मित विश्लेषकों में शामिल हैं: prebuilt-invoice, , prebuilt-imageSearch, prebuilt-audioSearchऔर prebuilt-videoSearch. जब आप विश्लेषण के लिए सामग्री विश्लेषक को सबमिट करते हैं, तो विश्लेषण अतुल्यकालिक होता है, जिसका अर्थ है कि जब यह तैयार हो जाता है तो आपको बाद में परिणाम मिलता है। क्योंकि विश्लेषण अतुल्यकालिक है, इसलिए आपको कार्य सफल होने तक Operation-Location URL (या) को analyzerResults की आवश्यकता है।
Azure सामग्री का उपयोग करना Python SDK को समझना
आइए URL से चालान का विश्लेषण करने के लिए पायथन SDK का उपयोग करने की प्रक्रिया पर एक नज़र डालें।
- Azure सामग्री को समझने वाले पायथन SDK स्थापित करें।
python -m pip install azure-ai-contentunderstanding
अपने फाउंड्री संसाधन समापन बिंदु और एपीआई कुंजी या माइक्रोसॉफ्ट एंट्रा आईडी की पहचान करें। आपका समापन बिंदु आम तौर पर इस तरह दिखता है:
https://<your-resource-name>.services.ai.azure.com/बनाएँ और क्लाइंट अनुप्रयोग कोड चलाएँ। पूर्वनिर्मित
analzyer_idविश्लेषक की आईडी है। आप यहां प्रीबिल्ट एनालाइज़र आईडी मानों की सूची पा सकते हैं।
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
परिणामी आउटपुट JSON है जो निकाले गए मार्कडाउन, फ़ील्ड, फ़ील्ड में डेटा और कॉन्फिडेंस स्कोर दिखाता है। उदाहरण के लिए:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
इसके बाद, ऑडियो और वीडियो से संरचित डेटा निकालने के लिए Azure सामग्री समझ विश्लेषकों का उपयोग करने का तरीका जानें।