वर्गीकरण क्या है?
बाइनरी वर्गीकरण दो श्रेणियों के साथ वर्गीकरण है। उदाहरण के लिए, हम रोगियों को गैर-मधुमेह या मधुमेह के रूप में लेबल कर सकते हैं।
वर्ग भविष्यवाणी 0 (असंभव) और 1 (निश्चित) के बीच मान के रूप में प्रत्येक संभावित वर्ग के लिए संभावना निर्धारित करके की जाती है। सभी वर्गों के लिए कुल संभावना हमेशा 1 होती है, क्योंकि रोगी निश्चित रूप से या तो मधुमेह या गैर-मधुमेह है। इसलिए, यदि किसी रोगी के मधुमेह होने की अनुमानित संभावना 0.3 है, तो 0.7 की इसी संभावना है कि रोगी गैर-मधुमेह है।
एक थ्रेशोल्ड मान, अक्सर 0.5, का उपयोग अनुमानित वर्ग को निर्धारित करने के लिए किया जाता है। यदि सकारात्मक वर्ग (इस मामले में, मधुमेह) में सीमा से अधिक अनुमानित संभावना है, तो मधुमेह के वर्गीकरण की भविष्यवाणी की जाती है।
एक वर्गीकरण मॉडल का प्रशिक्षण और मूल्यांकन
वर्गीकरण एक पर्यवेक्षित मशीन लर्निंग तकनीक का एक उदाहरण है, जिसका अर्थ है कि यह डेटा पर निर्भर करता है जिसमें ज्ञात सुविधा मान और ज्ञात लेबल मान शामिल हैं। इस उदाहरण में, सुविधा मान रोगियों के लिए नैदानिक माप हैं, और लेबल मान गैर-मधुमेह या मधुमेह का वर्गीकरण हैं। एक वर्गीकरण एल्गोरिथ्म का उपयोग डेटा के सबसेट को एक फ़ंक्शन में फिट करने के लिए किया जाता है जो फीचर मानों से प्रत्येक वर्ग लेबल की संभावना की गणना कर सकता है। शेष डेटा का उपयोग मॉडल का मूल्यांकन करने के लिए सुविधाओं से ज्ञात वर्ग लेबल से उत्पन्न भविष्यवाणियों की तुलना करके किया जाता है।
एक सरल उदाहरण
आइए प्रमुख सिद्धांतों को समझाने में मदद करने के लिए एक उदाहरण देखें। मान लीजिए कि हमारे पास निम्नलिखित रोगी डेटा है, जिसमें एक एकल विशेषता (रक्त शर्करा स्तर) और गैर-मधुमेह के लिए एक वर्ग लेबल 0, मधुमेह के लिए 1 शामिल है।
| Blood-Glucose | मधुमेह-संबंधी |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 115 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
हम वर्गीकरण मॉडल को प्रशिक्षित करने के लिए पहले आठ अवलोकनों का उपयोग करते हैं, और हम रक्त शर्करा सुविधा (x) और अनुमानित मधुमेह लेबल (y) की साजिश रचकर शुरू करते हैं।
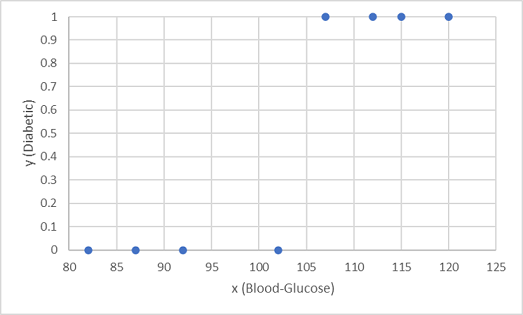
हमें जो चाहिए वह एक फ़ंक्शन है जो x के आधार पर y के लिए प्रायिकता मान की गणना करता है (दूसरे शब्दों में, हमें फ़ंक्शन की आवश्यकता है f(x) = y)। आप चार्ट से देख सकते हैं कि निम्न रक्त-शर्करा स्तर वाले रोगी सभी गैर-मधुमेह हैं, जबकि उच्च रक्त-शर्करा स्तर वाले रोगी मधुमेह हैं। ऐसा लगता है कि रक्त-शर्करा का स्तर जितना अधिक होगा, उतनी ही अधिक संभावना है कि एक रोगी मधुमेह है, जिसमें विभक्ति बिंदु 100 और 110 के बीच कहीं है। हमें एक फ़ंक्शन फिट करने की आवश्यकता है जो इन मानों के लिए y के लिए 0 और 1 के बीच मान की गणना करता है।
ऐसा ही एक फ़ंक्शन एक लॉजिस्टिक फ़ंक्शन है, जो एक सिग्मोइडल (एस-आकार) वक्र बनाता है।
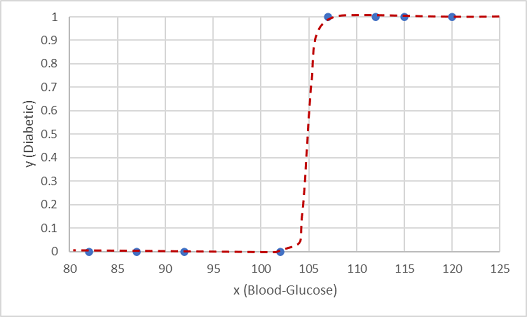
अब हम फ़ंक्शन का उपयोग संभाव्यता मान की गणना करने के लिए कर सकते हैं कि y सकारात्मक है, जिसका अर्थ है कि रोगी मधुमेह है, x के किसी भी मूल्य से फ़ंक्शन लाइन पर बिंदु ढूंढकर x. हम क्लास लेबल भविष्यवाणी के लिए कट-ऑफ पॉइंट के रूप में 0.5 का थ्रेशोल्ड मान सेट कर सकते हैं।
आइए इसे उन दो डेटा मानों के साथ परीक्षण करें जिन्हें हमने वापस रखा था।
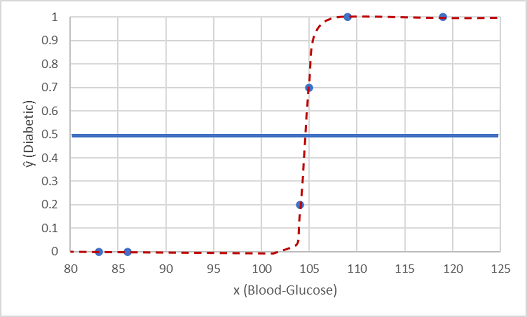
थ्रेशोल्ड लाइन के नीचे प्लॉट किए गए अंक 0 (गैर-मधुमेह) के अनुमानित वर्ग का उत्पादन करते हैं और रेखा के ऊपर के बिंदुओं को 1 (मधुमेह) के रूप में भविष्यवाणी की जाती है।
अब हम लेबल भविष्यवाणियों की तुलना कर सकते हैं (ŷ, या "y-hat"), मॉडल में समाहित लॉजिस्टिक फ़ंक्शन के आधार पर, वास्तविक वर्ग लेबल (y) )।
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |