Document processing models
Important
- Document Intelligence public preview releases provide early access to features that are in active development. Features, approaches, and processes may change, prior to General Availability (GA), based on user feedback.
- The public preview version of Document Intelligence client libraries default to REST API version 2024-07-31-preview.
- Public preview version 2024-07-31-preview is currently only available in the following Azure regions. Note that the custom generative (document field extraction) model in AI Studio is only available in North Central US region:
- East US
- West US2
- West Europe
- North Central US
This content applies to: ![]() v4.0 (preview) | Previous versions:
v4.0 (preview) | Previous versions: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
This content applies to: ![]() v3.1 (GA) | Latest version:
v3.1 (GA) | Latest version: ![]() v4.0 (preview) | Previous versions:
v4.0 (preview) | Previous versions: ![]() v3.0
v3.0 ![]() v2.1
v2.1
This content applies to: ![]() v3.0 (GA) | Latest versions:
v3.0 (GA) | Latest versions: ![]() v4.0 (preview)
v4.0 (preview) ![]() v3.1 | Previous version:
v3.1 | Previous version: ![]() v2.1
v2.1
This content applies to: ![]() v2.1 | Latest version:
v2.1 | Latest version: ![]() v4.0 (preview)
v4.0 (preview)
Azure AI Document Intelligence supports a wide variety of models that enable you to add intelligent document processing to your apps and flows. You can use a prebuilt domain-specific model or train a custom model tailored to your specific business need and use cases. Document Intelligence can be used with the REST API or Python, C#, Java, and JavaScript client libraries.
Note
- Document processing projects that involve financial data, protected health data, personal data, or highly sensitive data require careful attention.
- Be sure to comply with all national/regional and industry-specific requirements.
Model overview
The following table shows the available models for each current preview and stable API:
| Model Type | Model | • 2024-02-29-preview • 2023-10-31-preview |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Document analysis models | Read | ✔️ | ✔️ | ✔️ | n/a |
| Document analysis models | Layout | ✔️ | ✔️ | ✔️ | ✔️ |
| Document analysis models | General document | moved to layout** | ✔️ | ✔️ | n/a |
| Prebuilt models | Bank Check | ✔️ | n/a | n/a | n/a |
| Prebuilt models | Bank Statement | ✔️ | n/a | n/a | n/a |
| Prebuilt models | Paystub | ✔️ | n/a | n/a | n/a |
| Prebuilt models | Contract | ✔️ | ✔️ | n/a | n/a |
| Prebuilt models | Health insurance card | ✔️ | ✔️ | ✔️ | n/a |
| Prebuilt models | ID document | ✔️ | ✔️ | ✔️ | ✔️ |
| Prebuilt models | Invoice | ✔️ | ✔️ | ✔️ | ✔️ |
| Prebuilt models | Receipt | ✔️ | ✔️ | ✔️ | ✔️ |
| Prebuilt models | US Unified Tax* | ✔️ | n/a | n/a | n/a |
| Prebuilt models | US 1040 Tax* | ✔️ | ✔️ | n/a | n/a |
| Prebuilt models | US 1098 Tax* | ✔️ | n/a | n/a | n/a |
| Prebuilt models | US 1099 Tax* | ✔️ | n/a | n/a | n/a |
| Prebuilt models | US W2 Tax | ✔️ | ✔️ | ✔️ | n/a |
| Prebuilt models | US Mortgage 1003 URLA | ✔️ | n/a | n/a | n/a |
| Prebuilt models | US Mortgage 1004 URAR | ✔️ | n/a | n/a | n/a |
| Prebuilt models | US Mortgage 1005 | ✔️ | n/a | n/a | n/a |
| Prebuilt models | US Mortgage 1008 Summary | ✔️ | n/a | n/a | n/a |
| Prebuilt models | US Mortgage closing disclosure | ✔️ | n/a | n/a | n/a |
| Prebuilt models | Marriage certificate | ✔️ | n/a | n/a | n/a |
| Prebuilt models | Credit card | ✔️ | n/a | n/a | n/a |
| Prebuilt models | Business card | deprecated | ✔️ | ✔️ | ✔️ |
| Custom classification model | Custom classifier | ✔️ | ✔️ | n/a | n/a |
| Custom Generative Model | Custom Generative Model | ✔️ | n/a | n/a | n/a |
| Custom extraction model | Custom neural | ✔️ | ✔️ | ✔️ | n/a |
| Customextraction model | Custom template | ✔️ | ✔️ | ✔️ | ✔️ |
| Custom extraction model | Custom composed | ✔️ | ✔️ | ✔️ | ✔️ |
| All models | Add-on capabilities | ✔️ | ✔️ | n/a | n/a |
* - Contains submodels. See the model specific information for supported variations and subtypes.
Latency
Latency is the amount of time it takes for an API server to handle and process an incoming request and deliver the outgoing response to the client. The time to analyze a document depends on the size (for example, number of pages) and associated content on each page. Document Intelligence is a multitenant service where latency for similar documents is comparable but not always identical. Occasional variability in latency and performance is inherent in any microservice-based, stateless, asynchronous service that processes images and large documents at scale. Although we're continuously scaling up the hardware and capacity and scaling capabilities, you might still have latency issues at runtime.
| Add-on Capability | Add-On/Free | • 2024-02-29-preview &bullet [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-v4.0%20(2024-07-31-preview)&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Font property extraction | Add-On | ✔️ | ✔️ | n/a | n/a |
| Formula extraction | Add-On | ✔️ | ✔️ | n/a | n/a |
| High resolution extraction | Add-On | ✔️ | ✔️ | n/a | n/a |
| Barcode extraction | Free | ✔️ | ✔️ | n/a | n/a |
| Language detection | Free | ✔️ | ✔️ | n/a | n/a |
| Key value pairs | Free | ✔️ | n/a | n/a | n/a |
| Query fields | Add-On* | ✔️ | n/a | n/a | n/a |
| Searchable pdf | Add-On* | ✔️ | n/a | n/a | n/a |
Model analysis features
| Model ID | Content Extraction | Query fields | Paragraphs | Paragraph Roles | Selection Marks | Tables | Key-Value Pairs | Languages | Barcodes | Document Analysis | Formulas* | Style Font* | High Resolution* | Searchable PDF |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| prebuilt-read | ✓ | ✓ | O | O | O | O | O | ✓ | ||||||
| prebuilt-layout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |||
| prebuilt-document | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| prebuilt-businessCard | ✓ | ✓ | ✓ | |||||||||||
| prebuilt-contract | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | ✓ | O | O | ||||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-invoice | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
| prebuilt-receipt | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-check.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-payStub.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-bankStatement | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1004 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1005 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099(variations) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1040(variations) | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - Enabled
O - Optional
* - Premium features incur extra costs
Add-On* - Query fields are priced differently than the other add-on features. See pricing for details.
Bounding box and polygon coordinates
A bounding box (polygon in v3.0 and later versions) is an abstract rectangle that surrounds text elements in a document used as a reference point for object detection.
The bounding box specifies position by using an x and y coordinate plane presented in an array of four numerical pairs. Each pair represents a corner of the box in the following order: upper left, upper right, lower right, lower left.
Image coordinates are presented in pixels. For a PDF, coordinates are presented in inches.
For all models, except Business card model, Document Intelligence now supports add-on capabilities to allow for more sophisticated analysis. These optional capabilities can be enabled and disabled depending on the scenario of the document extraction. There are seven add-on capabilities available for the 2023-07-31 (GA) and later API version:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax modelssearchablePDF(2024-07-31-preview)Only available for Read Model
Language support
The deep-learning-based universal models in Document Intelligence support many languages that can extract multilingual text from your images and documents, including text lines with mixed languages. Language support varies by Document Intelligence service functionality. For a complete list, see the following articles:
- Language support: document analysis models
- Language support: prebuilt models
- Language support: custom models
Regional availability
Document Intelligence is generally available in many of the 60+ Azure global infrastructure regions.
For more information, see our Azure geographies page to help choose the region that's best for you and your customers.
Model details
This section describes the output you can expect from each model. You can extend the output of most models with add-on features.
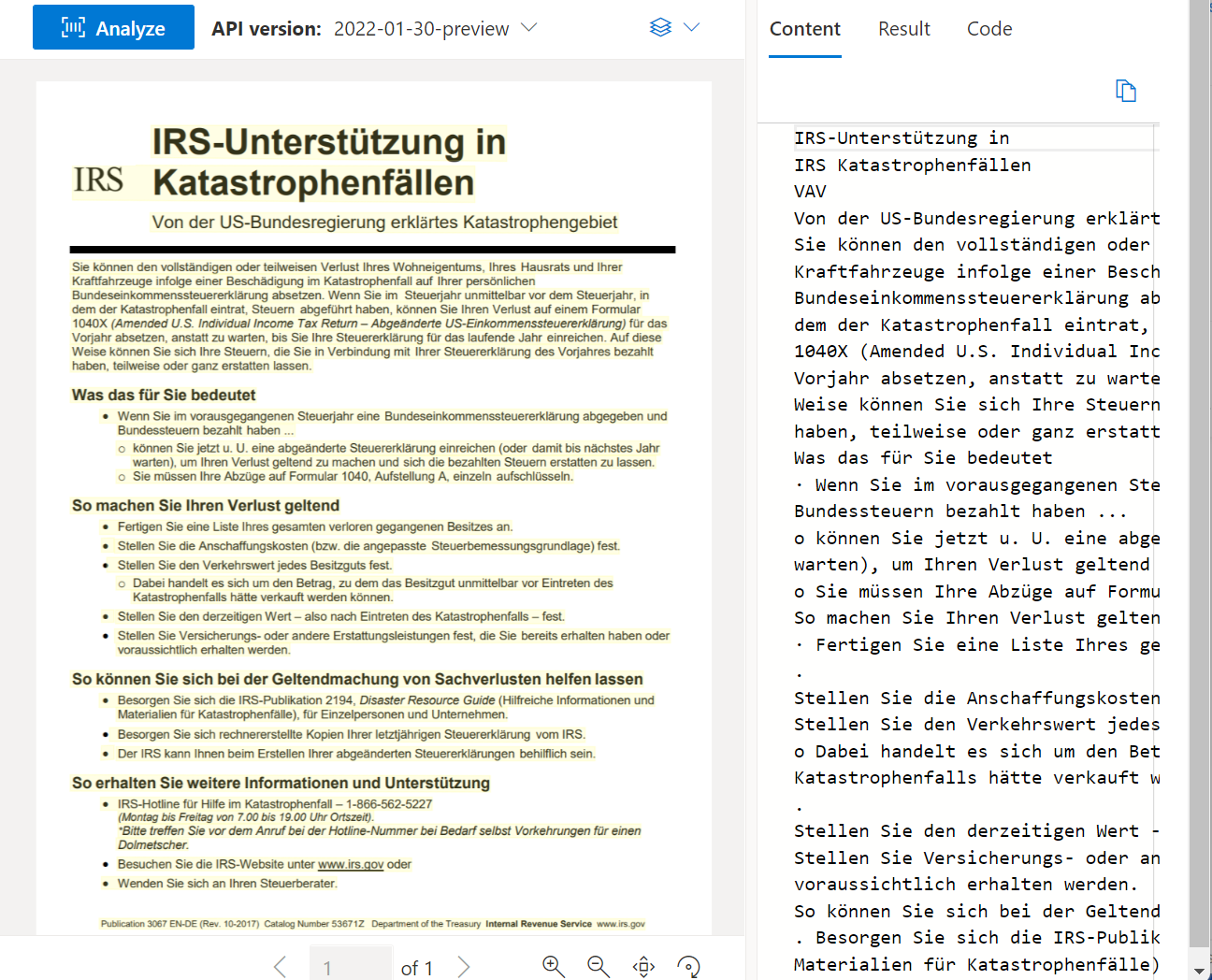
Read OCR

The Read API analyzes and extracts lines, words, their locations, detected languages, and handwritten style if detected.
Sample document processed using the Document Intelligence Studio:
Layout analysis

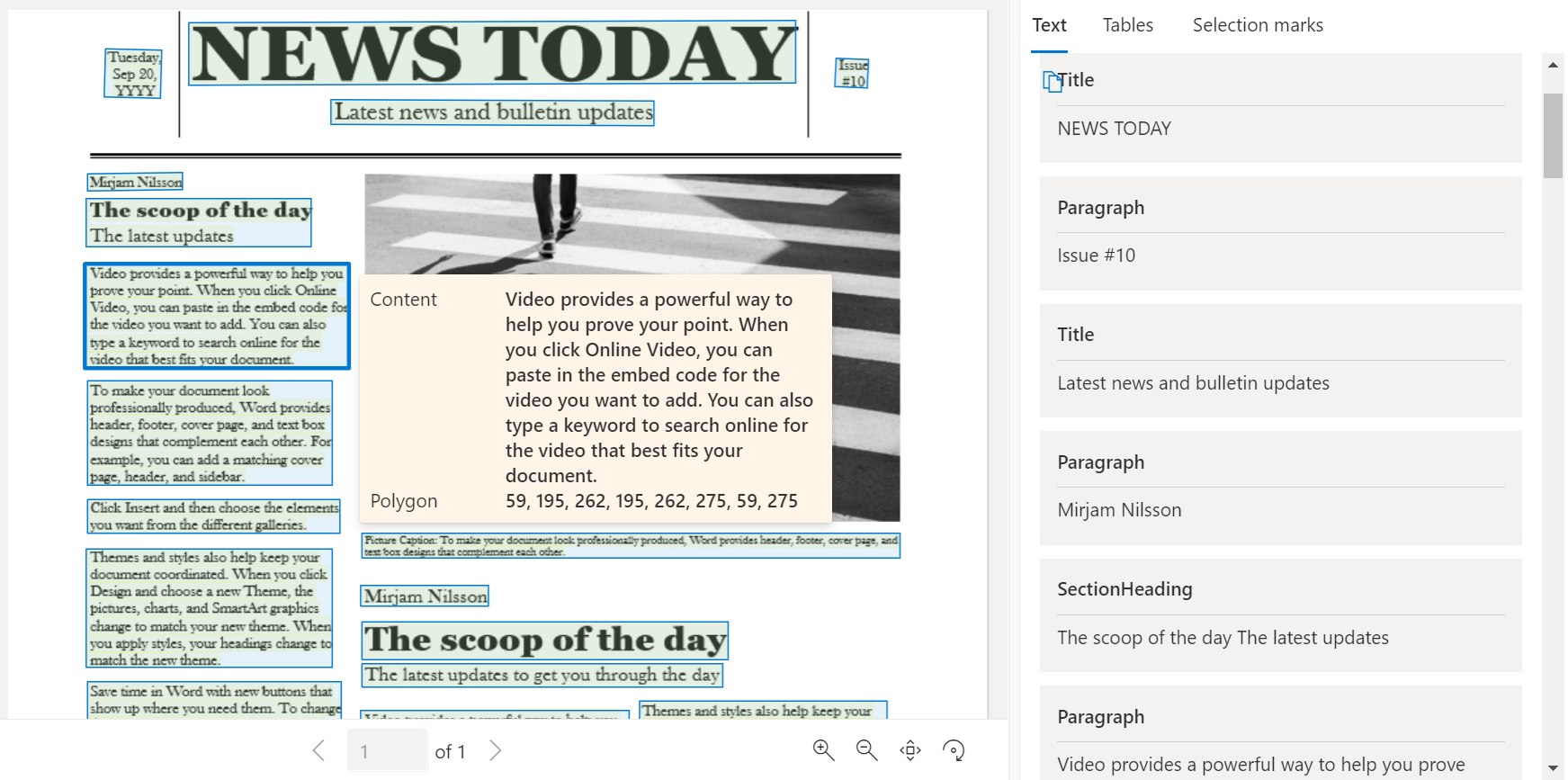
The Layout analysis model analyzes and extracts text, tables, selection marks, and other structure elements like titles, section headings, page headers, page footers, and more.
Sample document processed using the Document Intelligence Studio:
Health insurance card
![]()
The health insurance card model combines powerful Optical Character Recognition (OCR) capabilities with deep learning models to analyze and extract key information from US health insurance cards.
Sample US health insurance card processed using Document Intelligence Studio:

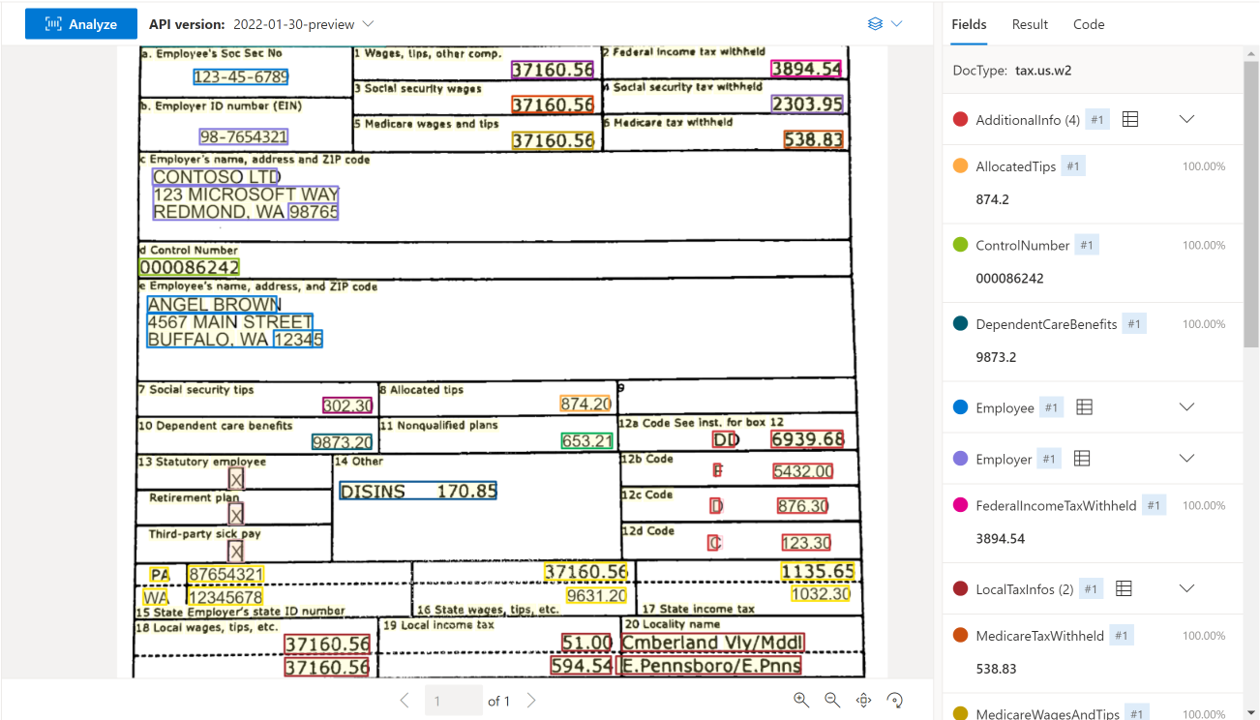
US tax documents
The US tax document models analyze and extract key fields and line items from a select group of tax documents. The API supports the analysis of English-language US tax documents of various formats and quality including phone-captured images, scanned documents, and digital PDFs. The following models are currently supported:
| Model | Description | ModelID |
|---|---|---|
| US Tax W-2 | Extract taxable compensation details. | prebuilt-tax.us.w2 |
| US Tax 1040 | Extract mortgage interest details. | prebuilt-tax.us.1040(variations) |
| US Tax 1098 | Extract mortgage interest details. | prebuilt-tax.us.1098(variations) |
| US Tax 1099 | Extract income received from sources other than employer. | prebuilt-tax.us.1099(variations) |
Sample W-2 document processed using Document Intelligence Studio:
US mortgage documents

The US mortgage document models analyze and extract key fields including borrower, loan, and property information from a select group of mortgage documents. The API supports the analysis of English-language US mortgage documents of various formats and quality including phone-captured images, scanned documents, and digital PDFs. The following models are currently supported:
| Model | Description | ModelID |
|---|---|---|
| 1003 End-User License Agreement (EULA) | Extract loan, borrower, property details. | prebuilt-mortgage.us.1003 |
| 1008 Summary document | Extract borrower, seller, property, mortgage, and underwriting details. | prebuilt-mortgage.us.1008 |
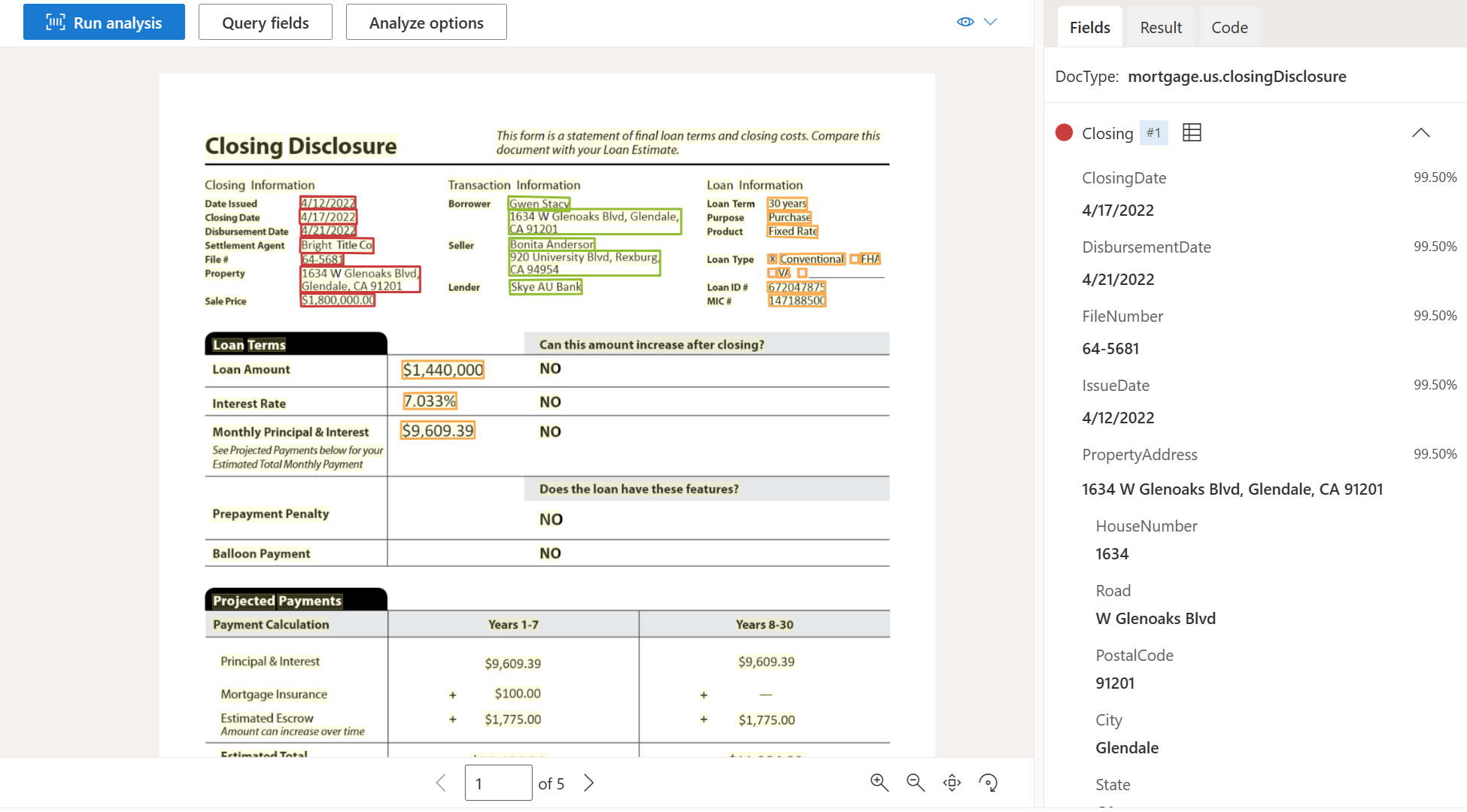
| Closing disclosure | Extract closing, transaction costs, and loan details. | prebuilt-mortgage.us.closingDisclosure |
| Marriage certificate | Extract marriage information details for joint loan applicants. | prebuilt-marriageCertificate |
| US Tax W-2 | Extract taxable compensation details for income verification. | prebuilt-tax.us.w2 |
Sample Closing disclosure document processed using Document Intelligence Studio:
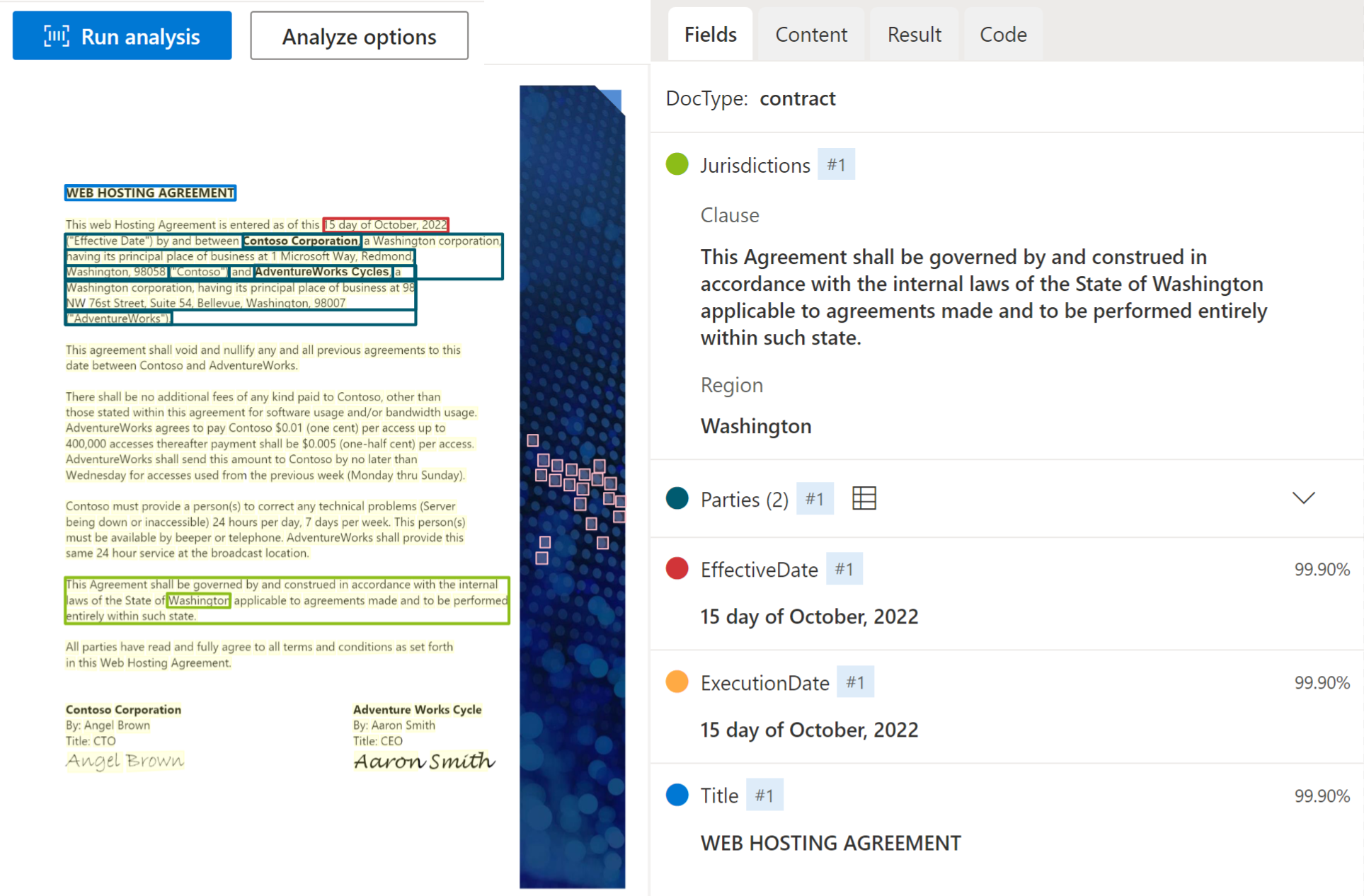
Contract
![]()
The contract model analyzes and extracts key fields and line items from contractual agreements including parties, jurisdictions, contract ID, and title. The model currently supports English-language contract documents.
Sample contract processed using Document Intelligence Studio:
Invoice
The invoice model automates processing of invoices to extracts customer name, billing address, due date, and amount due, line items, and other key data. Currently, the model supports English, Spanish, German, French, Italian, Portuguese, and Dutch invoices.
Sample invoice processed using Document Intelligence Studio:

Receipt
Use the receipt model to scan sales receipts for merchant name, dates, line items, quantities, and totals from printed and handwritten receipts. The version v3.0 also supports single-page hotel receipt processing.
Sample receipt processed using Document Intelligence Studio:

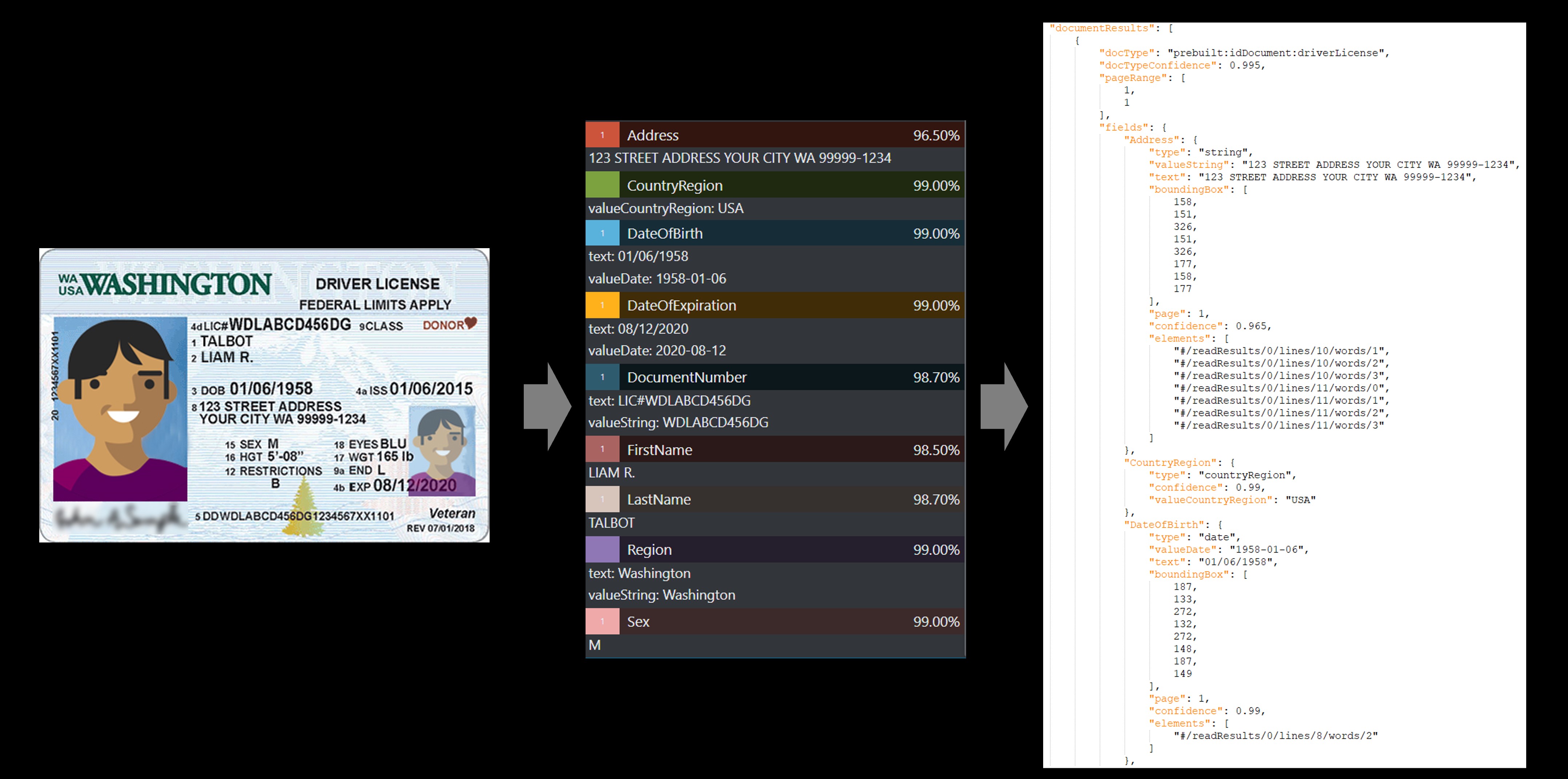
Identity document (ID)

Use the Identity document (ID) model to process U.S. Driver's Licenses (all 50 states and District of Columbia) and biographical pages from international passports (excluding visa and other travel documents) to extract key fields.
Sample U.S. Driver's License processed using Document Intelligence Studio:

Marriage certificate
![]()
Use the marriage certificate model to process U.S. marriage certificates to extract key fields including the individuals, date, and location.
Sample U.S. marriage certificate processed using Document Intelligence Studio:

Credit card
![]()
Use the credit card model to process credit and debit cards to extract key fields.
Sample credit card processed using Document Intelligence Studio:

Custom models

Custom models can be broadly classified into two types. Custom classification models that support classification of a "document type" and custom extraction models that can extract a defined schema from a specific document type.
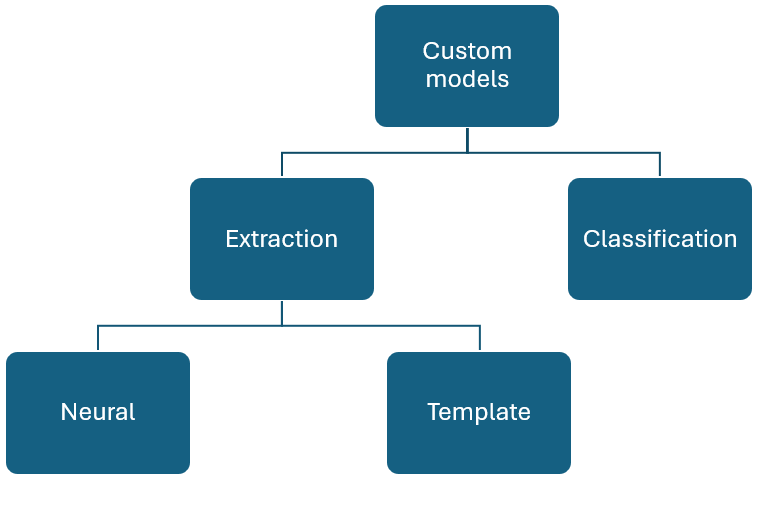
Custom document models analyze and extract data from forms and documents specific to your business. They recognize form fields within your distinct content and extract key-value pairs and table data. You only need one example of the form type to get started.
Version v3.0 and later custom models support signature detection in custom template (form) and cross-page tables in both template and neural models. Signature detection looks for the presence of a signature, not the identity of the person who signs the document. If the model returns unsigned for signature detection, the model didn't find a signature in the defined field.
Sample custom template processed using Document Intelligence Studio:
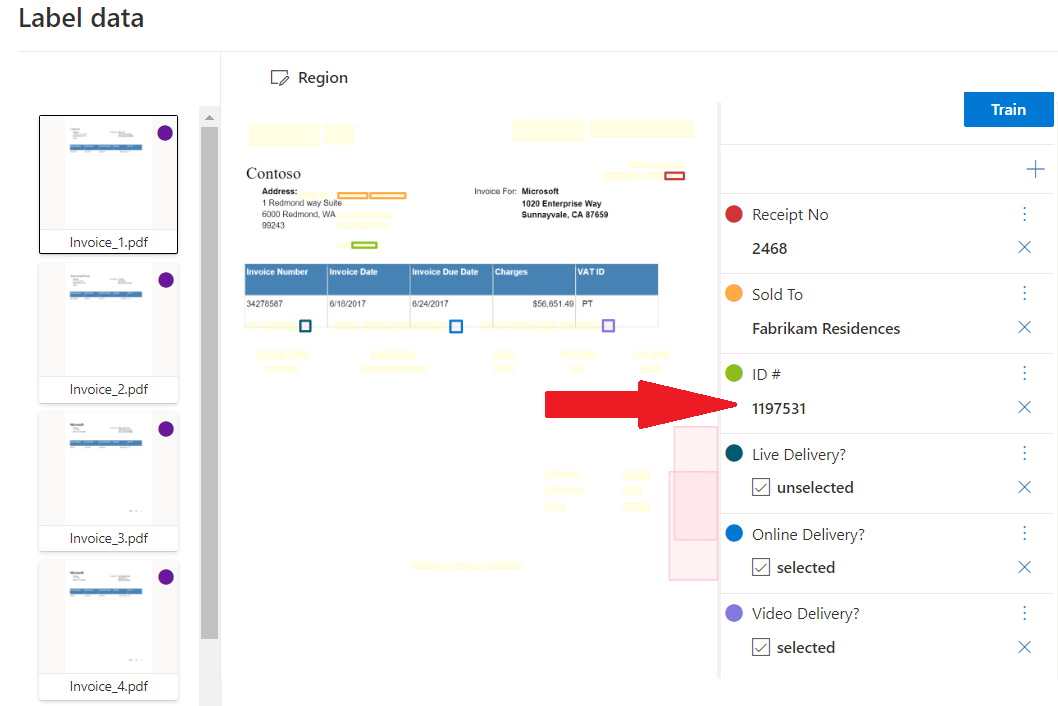
Custom extraction

Custom extraction model can be one of two types, custom template or custom neural. To create a custom extraction model, label a dataset of documents with the values you want extracted and train the model on the labeled dataset. You only need five examples of the same form or document type to get started.
Sample custom extraction processed using Document Intelligence Studio:

Custom classifier

The custom classification model enables you to identify the document type before invoking the extraction model. The classification model is available starting with the 2023-07-31 (GA) API. Training a custom classification model requires at least two distinct classes and a minimum of five samples per class.
Composed models
A composed model is created by taking a collection of custom models and assigning them to a single model built from your form types. You can assign multiple custom models to a composed model called with a single model ID. You can assign up to 200 trained custom models to a single composed model.
Composed model dialog window in Document Intelligence Studio:
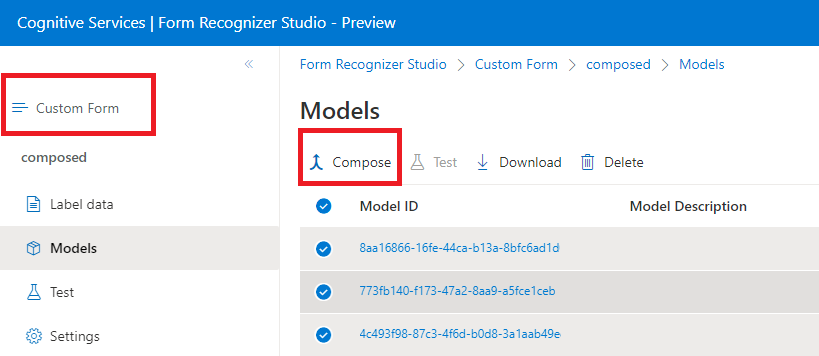
Input requirements
Supported file formats:
Model PDF Image: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLRead ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) General Document ✔ ✔ Prebuilt ✔ ✔ Custom extraction ✔ ✔ Custom classification ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) For best results, provide one clear photo or high-quality scan per document.
For PDF and TIFF, up to 2,000 pages can be processed (with a free tier subscription, only the first two pages are processed).
The file size for analyzing documents is 500 MB for paid (S0) tier and
4MB for free (F0) tier.Image dimensions must be between 50 pixels x 50 pixels and 10,000 pixels x 10,000 pixels.
If your PDFs are password-locked, you must remove the lock before submission.
The minimum height of the text to be extracted is 12 pixels for a 1024 x 768 pixel image. This dimension corresponds to about
8point text at 150 dots per inch (DPI).For custom model training, the maximum number of pages for training data is 500 for the custom template model and 50,000 for the custom neural model.
For custom extraction model training, the total size of training data is 50 MB for template model and
1GB for the neural model.For custom classification model training, the total size of training data is
1GB with a maximum of 10,000 pages. For 2024-07-31-preview and later, the total size of training data is2GB with a maximum of 10,000 pages.
Note
The Sample Labeling tool does not support the BMP file format. This is a limitation of the tool not the Document Intelligence Service.
Version migration
Learn how to use Document Intelligence v3.0 in your applications by following our Document Intelligence v3.1 migration guide
| Model | Description |
|---|---|
| Document analysis | |
| Layout | Extract text and layout information from documents. |
| Prebuilt | |
| Invoice | Extract key information from English and Spanish invoices. |
| Receipt | Extract key information from English receipts. |
| ID document | Extract key information from US driver licenses and international passports. |
| Business card | Extract key information from English business cards. |
| Custom | |
| Custom | Extract data from forms and documents specific to your business. Custom models are trained for your distinct data and use cases. |
| Composed | Compose a collection of custom models and assign them to a single model built from your form types. |
Layout
The Layout API analyzes and extracts text, tables and headers, selection marks, and structure information from documents.
Sample document processed using the Sample Labeling tool:
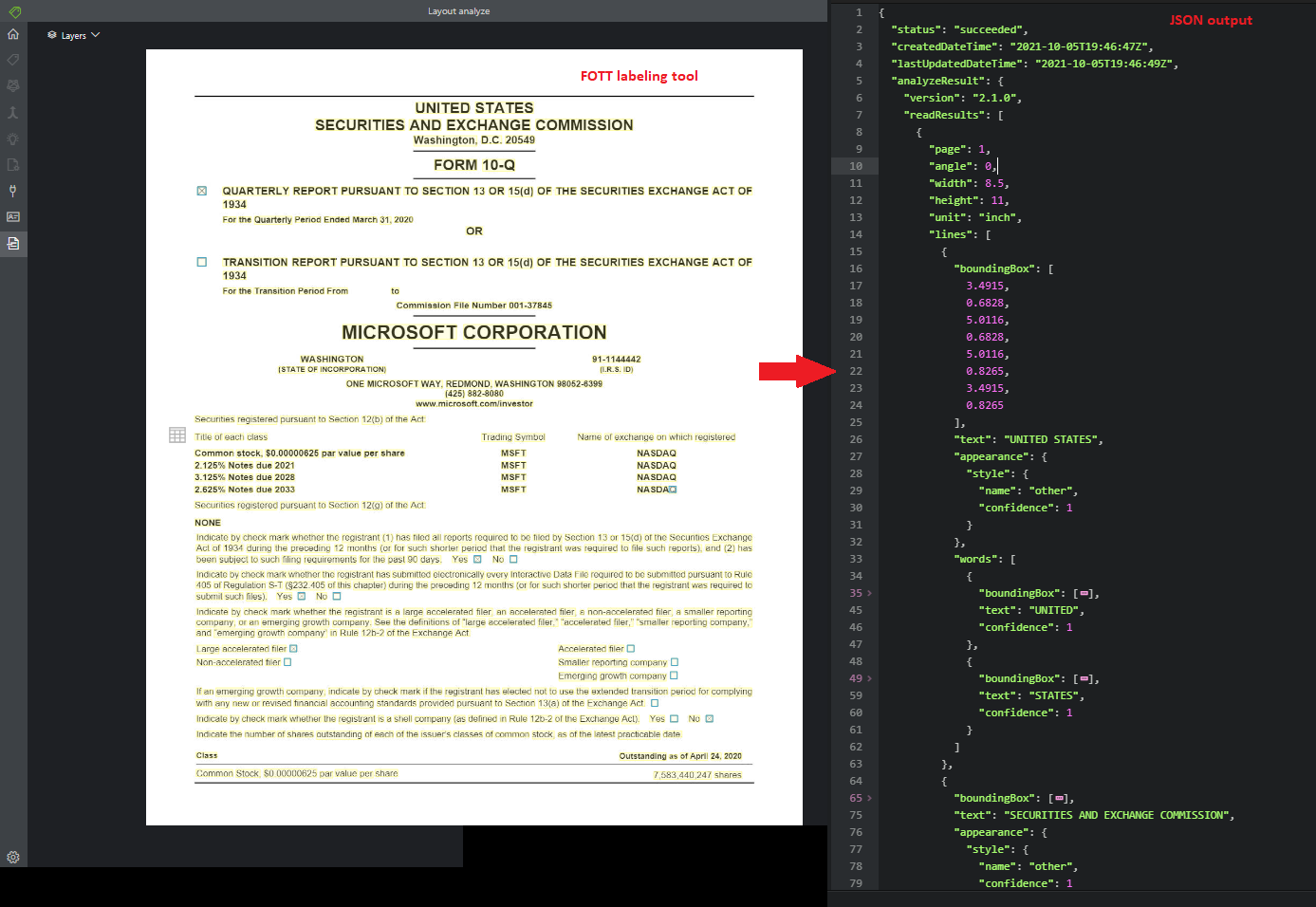
Invoice
The invoice model analyzes and extracts key information from sales invoices. The API analyzes invoices in various formats and extracts key information such as customer name, billing address, due date, and amount due.
Sample invoice processed using the Sample Labeling tool:

Receipt
- The receipt model analyzes and extracts key information from printed and handwritten sales receipts.
Sample receipt processed using Sample Labeling tool:
ID document
The ID document model analyzes and extracts key information from the following documents:
U.S. Driver's Licenses (all 50 states and District of Columbia)
Biographical pages from international passports (excluding visa and other travel documents). The API analyzes identity documents and extracts
Sample U.S. Driver's License processed using the Sample Labeling tool:
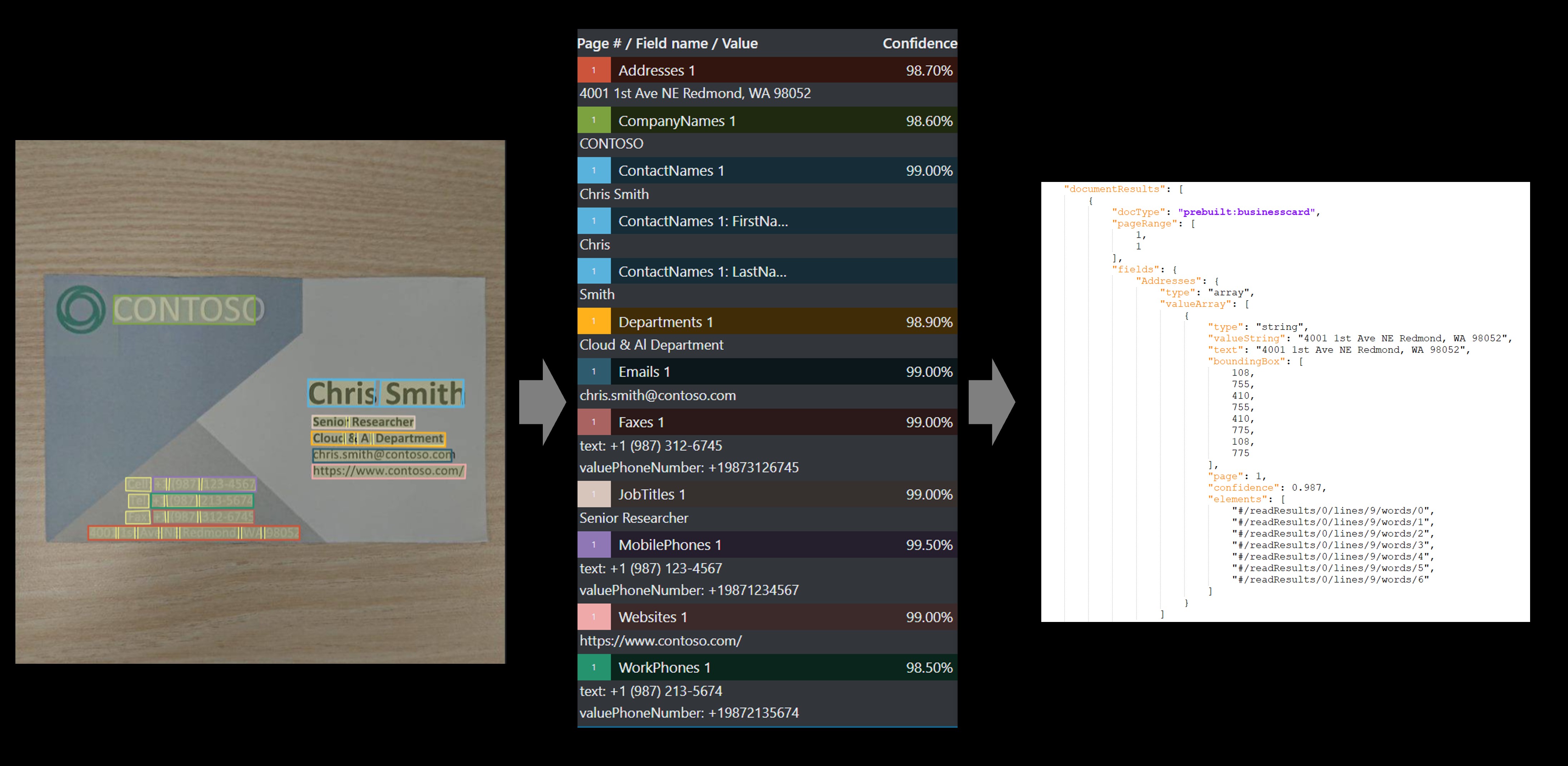
Business card
The business card model analyzes and extracts key information from business card images.
Sample business card processed using the Sample Labeling tool:
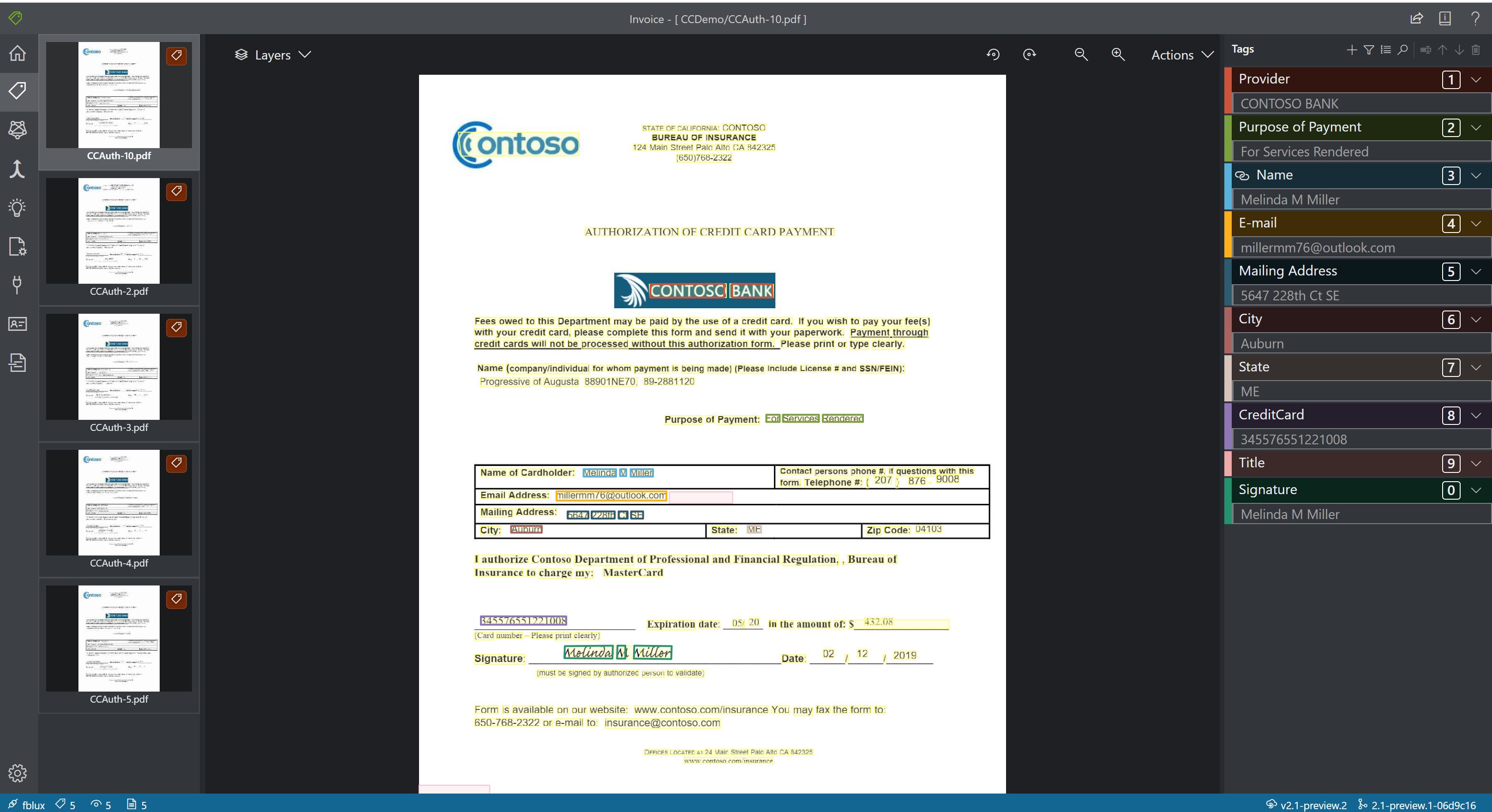
Custom
- Custom models analyze and extract data from forms and documents specific to your business. The API is a machine-learning program trained to recognize form fields within your distinct content and extract key-value pairs and table data. You only need five examples of the same form type to get started and your custom model can be trained with or without labeled datasets.
Sample custom model processing using the Sample Labeling tool:
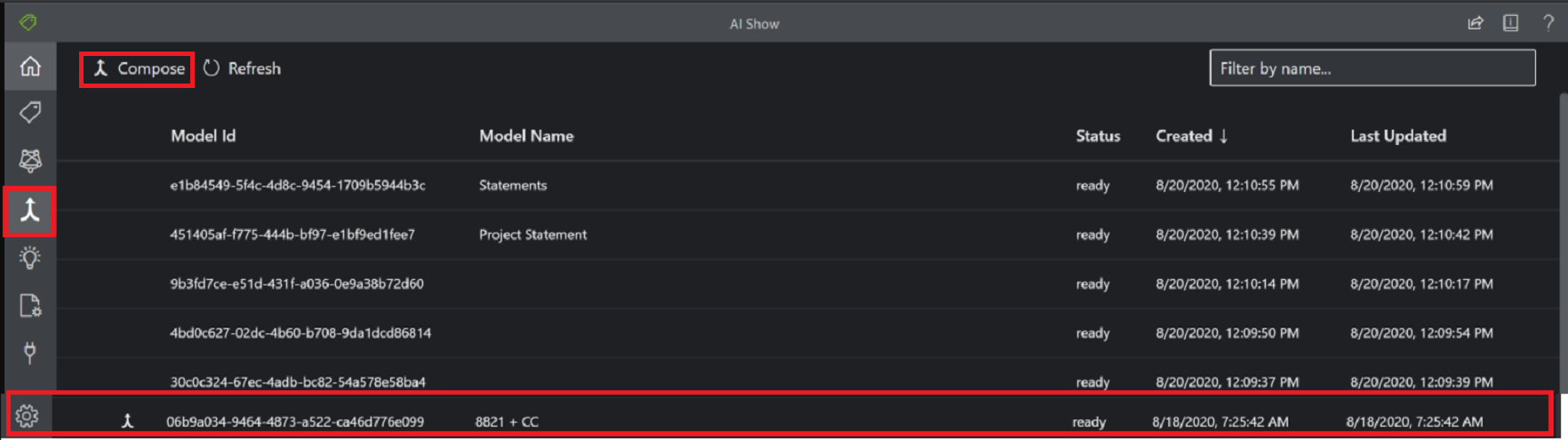
Composed custom model
A composed model is created by taking a collection of custom models and assigning them to a single model built from your form types. You can assign multiple custom models to a composed model called with a single model ID. You can assign up to 100 trained custom models to a single composed model.
Composed model dialog window using the Sample Labeling tool:
Model data extraction
| Model | Text extraction | Language detection | Selection Marks | Tables | Paragraphs | Paragraph roles | Key-Value pairs | Fields |
|---|---|---|---|---|---|---|---|---|
| Layout | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Invoice | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Receipt | ✓ | ✓ | ✓ | |||||
| ID Document | ✓ | ✓ | ✓ | |||||
| Business Card | ✓ | ✓ | ✓ | |||||
| Custom Form | ✓ | ✓ | ✓ | ✓ | ✓ |
Input requirements
Supported file formats:
Model PDF Image: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLRead ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) General Document ✔ ✔ Prebuilt ✔ ✔ Custom extraction ✔ ✔ Custom classification ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) For best results, provide one clear photo or high-quality scan per document.
For PDF and TIFF, up to 2,000 pages can be processed (with a free tier subscription, only the first two pages are processed).
The file size for analyzing documents is 500 MB for paid (S0) tier and
4MB for free (F0) tier.Image dimensions must be between 50 pixels x 50 pixels and 10,000 pixels x 10,000 pixels.
If your PDFs are password-locked, you must remove the lock before submission.
The minimum height of the text to be extracted is 12 pixels for a 1024 x 768 pixel image. This dimension corresponds to about
8point text at 150 dots per inch (DPI).For custom model training, the maximum number of pages for training data is 500 for the custom template model and 50,000 for the custom neural model.
For custom extraction model training, the total size of training data is 50 MB for template model and
1GB for the neural model.For custom classification model training, the total size of training data is
1GB with a maximum of 10,000 pages. For 2024-07-31-preview and later, the total size of training data is2GB with a maximum of 10,000 pages.
Note
The Sample Labeling tool does not support the BMP file format. This is a limitation of the tool not the Document Intelligence Service.
Version migration
You can learn how to use Document Intelligence v3.0 in your applications by following our Document Intelligence v3.1 migration guide
Next steps
Try processing your own forms and documents with the Document Intelligence Studio.
Complete a Document Intelligence quickstart and get started creating a document processing app in the development language of your choice.
Try processing your own forms and documents with the Document Intelligence Sample Labeling tool.
Complete a Document Intelligence quickstart and get started creating a document processing app in the development language of your choice.