Keresési szolgáltatás kapacitásának becslése és kezelése
Az Azure AI Searchben a kapacitás a számítási feladatra skálázható replikákon és partíciókon alapul. A replikák a keresőmotor másolatai. A partíciók tárolási egységek. Minden új keresési szolgáltatás mindegyikével kezdődik, de egymástól függetlenül adhat hozzá vagy távolíthat el replikákat és partíciókat az ingadozó számítási feladatok kezeléséhez. A kapacitás hozzáadása növeli a keresési szolgáltatás futtatásának költségeit.
A replikák és partíciók fizikai jellemzői, például a feldolgozási sebesség és a lemez I/O-jának fizikai jellemzői szolgáltatási szint szerint változnak. Egy standard keresési szolgáltatásban a replikák és partíciók gyorsabbak és nagyobbak, mint az alapszintű szolgáltatásoké.
A kapacitás módosítása nem azonnali. A partíciók üzembe helyezése vagy leszerelése akár egy órát is igénybe vehet, különösen a nagy mennyiségű adatot tartalmazó szolgáltatások esetében.
Keresési szolgáltatás skálázása során az alábbi eszközök és megközelítések közül választhat:
Fogalmak: keresési egységek, replikák, partíciók, szegmensek
A kapacitás olyan keresési egységekbenvan kifejezve, amelyek partíciók és replikák kombinációjában foglalhatók le, a rugalmas konfigurációk támogatása érdekében egy mögöttes horizontális skálázási mechanizmus használatával:
| Koncepció | Definíció |
|---|---|
| Keresési egység | A teljes rendelkezésre álló kapacitás egyetlen növekménye (36 egység). Ez az Azure AI-Search szolgáltatás számlázási egysége is. A szolgáltatás futtatásához legalább egy egység szükséges. |
| Replika | A keresési szolgáltatás példányai, amelyeket elsősorban a lekérdezési műveletek terheléselosztására használnak. Minden replika egy index egy példányát tárolja. Ha három replikát foglal le, három példányban érhető el egy index a lekérdezési kérelmek kiszolgálásához. |
| Partíció | Fizikai tárolás és I/O olvasási/írási műveletekhez (például index újraépítésekor vagy frissítésekor). Minden partícióhoz tartozik egy szelet a teljes indexből. Ha három partíciót foglal le, az index harmadokra van osztva. |
| Szilánk | Egy index adattömbje. Az Azure AI Search az egyes indexeket szegmensekre osztja, hogy felgyorsítsa a partíciók hozzáadását (a szegmensek új keresési egységekbe való áthelyezésével). |
Az alábbi ábra a replikák, partíciók, szegmensek és keresési egységek közötti kapcsolatot mutatja be. Egy példát mutat be arra, hogy egy adott index hogyan van átfogva egy szolgáltatás négy keresési egységén két replikával és két partícióval. A négy keresési egység mindegyike az index szegmenseinek csak a felét tárolja. A bal oldali oszlop keresési egységei a szegmensek első felét tárolják, amely az első partíciót tartalmazza, míg a jobb oldali oszlopban lévők a szegmensek második felét tárolják, amely a második partíciót tartalmazza. Mivel két replika létezik, minden indexszilánk két példánya van. A felső sor keresési egységei egy példányt tárolnak, amely az első replikát tartalmazza, míg az alsó sorban lévők egy másik példányt tárolnak, amely a második replikát tartalmazza.
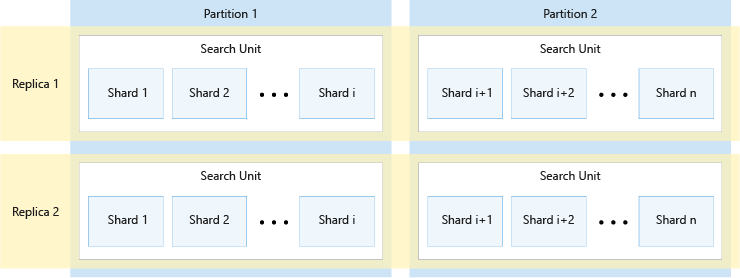
A fenti diagram csak egy példa. A partíciók és replikák számos kombinációja lehetséges, legfeljebb 36 keresési egységig.
Az Azure AI Searchben a szegmenskezelés implementálási részlet és nem konfigurálható, de az indexek horizontális felosztásának ismerete segít megérteni a rangsorolási és automatikus kiegészítési viselkedések esetenkénti rendellenességeit:
Rangsorolási anomáliák: A keresési pontszámokat először a szegmens szintjén számítjuk ki, majd összesítjük egyetlen eredményhalmazba. A szegmenstartalom jellemzőitől függően előfordulhat, hogy az egyik szegmens egyezései magasabbak, mint a másiké. Ha a keresési eredményekben az intuitív rangsorolást észleli, az valószínűleg a horizontális skálázás hatásainak köszönhető, különösen akkor, ha az indexek kicsik. Ezeket a rangsorolási anomáliákat elkerülheti, ha úgy dönt, hogy globálisan számítja ki a pontszámokat a teljes indexben, de ez teljesítménybeli büntetést von maga után.
Automatikus kiegészítési anomáliák: Automatikus kiegészítési lekérdezések, amelyekben a részben megadott kifejezés első néhány karakterében egyezések jönnek létre, fogadjon el egy homályos paramétert, amely megbocsátja a helyesírás kis eltéréseit. Az automatikus kiegészítés esetében a homályos egyezés az aktuális szegmensen belüli kifejezésekre van korlátozva. Ha például egy szegmens tartalmazza a "Microsoft"-t, és a "mikro" kifejezés részleges kifejezése be van írva, a keresőmotor a "Microsoft" kifejezéssel fog egyezni az adott szegmensben, de az index fennmaradó részeit tartalmazó többi szegmensben nem.
Becslési célok
A kapacitástervezésnek tartalmaznia kell az objektumkorlátokat (például a szolgáltatásban engedélyezett indexek maximális számát) és a tárterületkorlátokat. A szolgáltatási szint határozza meg az objektumok és a tárterület korlátait. Amelyik korlátot előbb eléri a rendszer, az a tényleges korlát.
Az indexek és egyéb objektumok számát általában üzleti és mérnöki követelmények határozzák meg. Előfordulhat például, hogy ugyanannak az indexnek több verziója is van az aktív fejlesztéshez, teszteléshez és éles környezethez.
A tárolási igényeket a létrehozni kívánt indexek mérete határozza meg. Nincsenek olyan szilárd heurisztika vagy általánosságok, amelyek segítenek a becslésekben. Az index méretének meghatározásának egyetlen módja a buildelés. Mérete az importált adatokon, szövegelemzésen és indexkonfiguráción alapul, például hogy engedélyezi-e a javaslattevőket, a szűrést és a rendezést.
A teljes szöveges kereséshez az elsődleges adatstruktúra egy fordított indexszerkezet , amely a forrásadatoktól eltérő jellemzőkkel rendelkezik. Az invertált indexek esetében a méretet és az összetettségeket a tartalom határozza meg, nem feltétlenül a benne tárolt adatok mennyisége. A nagy redundanciával rendelkező nagy adatforrások kisebb indexet eredményezhetnek, mint egy nagy mértékben változó tartalmat tartalmazó kisebb adathalmaz. Ezért ritkán lehet az index méretét az eredeti adathalmaz mérete alapján következtetni.
Az index attribútumai, például a szűrők engedélyezése és a rendezés befolyásolják a tárolási követelményeket. A javaslattevők használata tárolási következményekkel is jár. További információ: Attribútumok és indexméret.
Feljegyzés
Annak ellenére, hogy az indexek és a tárolás jövőbeli igényeinek becslése találgatásnak tűnhet, érdemes megtenni. Ha egy réteg kapacitása túl alacsonynak bizonyul, ki kell építenie egy új szolgáltatást egy magasabb szinten, majd újra kell betöltenie az indexeket. A szolgáltatás nem frissíthető helyben az egyik szintről a másikra.
Becslés az ingyenes szinttel
A kapacitás becslésének egyik módszere az ingyenes szinttel való kezdés. Ne feledje, hogy az ingyenes szolgáltatás legfeljebb három indexet, 50 MB tárterületet és 2 perc indexelési időt kínál. Ezekkel a korlátozásokkal nehéz megbecsülni egy előre jelzett indexméretet, de ezek a lépések:
Készítsen elő egy kis, reprezentatív adatkészletet.
Hozzon létre egy indexet, és töltse be az adatokat. Ha az adathalmaz egy indexelők által támogatott Azure-adatforrásban üzemeltethető, a portál Adatimportálás varázslója segítségével is létrehozhatja és betöltheti az indexet. Ellenkező esetben REST API-k használatával létrehozhatja az indexet, és leküldheti az adatokat. A leküldéses modell megköveteli, hogy az adatok JSON-dokumentumok formájában legyenek, ahol a dokumentum mezői az index mezőinek felelnek meg.
Gyűjtsön adatokat az indexről, például a méretről. A funkciók és attribútumok hatással vannak a tárolásra. A javaslattevők hozzáadása (keresési módú lekérdezések) például növelik a tárolási követelményeket.
Ugyanezzel az adatkészlettel megpróbálhat létrehozni egy index több verzióját, különböző attribútumokkal az egyes mezőkön, hogy lássa, hogyan változnak a tárolási követelmények. További információ: "Tárolási következmények" az alapszintű index létrehozása című témakörben.
Egy hozzávetőleges becsléssel megduplázhatja ezt az összeget két indexhez (fejlesztéshez és éles környezethez), majd ennek megfelelően választhatja ki a szintet.
Becslés számlázható szinttel
A dedikált erőforrások nagyobb mintavételi és feldolgozási időt képesek biztosítani az index mennyiségének, méretének és lekérdezési mennyiségének reálisabb becsléséhez a fejlesztés során. Egyes ügyfelek közvetlenül a számlázható szinttel ugranak be, majd újra kiértékelik a fejlesztési projekt érettségével.
Tekintse át az egyes szintek szolgáltatási korlátait annak megállapításához, hogy az alacsonyabb szintek támogatják-e a szükséges indexek számát. Az alapszintű, az S1 és az S2 szinten az indexkorlátok 15, 50 és 200. A Tárolóoptimalizált szint 10 indexes korláttal rendelkezik, mivel úgy van kialakítva, hogy alacsony számú nagyon nagy indexet támogatjon.
Szolgáltatás létrehozása számlázható szinten:
- Ha nem biztos az előre jelzett terhelésben, kezdjen alacsonyan, alapszintű vagy S1 szinten.
- Ha a tesztelés nagy léptékű indexelést és lekérdezési terhelést is tartalmaz, kezdjen magasra, S2-nél vagy akár S3-nál is.
- Ha nagy mennyiségű adatot indexel, és a lekérdezési terhelés viszonylag alacsony, az L1 vagy L2 tárolóra optimalizált tárolással kell kezdenie, mint egy belső üzleti alkalmazás esetén.
Hozzon létre egy kezdeti indexet annak meghatározásához, hogy a forrásadatok hogyan fordítják le az indexet. Csak így becsülhet meg indexméretet.
Monitorozza a tárterületet, a szolgáltatási korlátokat, a lekérdezési kötetet és a késést a portálon. A portál megjeleníti a másodpercenkénti lekérdezéseket, a szabályozott lekérdezéseket és a keresési késést. Ezek az értékek segítenek eldönteni, hogy a megfelelő szintet választotta-e.
Replikák hozzáadása magas rendelkezésre álláshoz vagy a lassú lekérdezési teljesítmény csökkentése érdekében.
Nincs irányelv arra vonatkozóan, hogy hány replikára van szükség a lekérdezési terhelések kezeléséhez. A lekérdezés teljesítménye a lekérdezés összetettségétől és a versengő számítási feladatoktól függ. Bár a replikák hozzáadása egyértelműen jobb teljesítményt eredményez, az eredmény nem szigorúan lineáris: a három replika hozzáadása nem garantálja a háromszoros átviteli sebességet. A QPS megoldáshoz való becsléséhez a teljesítményelemzése és a lekérdezések monitorozása című témakörben talál útmutatást.
Feljegyzés
A tárolási követelmények felfújhatók, ha olyan adatokat is tartalmaz, amelyeket soha nem keresnek. Ideális esetben a dokumentumok csak a keresési élményhez szükséges adatokat tartalmazzák. A bináris adatok nem kereshetők, és külön kell tárolni őket (esetleg egy Azure-táblában vagy blobtárolóban). Ezután hozzá kell adni egy mezőt az indexhez, hogy a külső adatokra mutató URL-hivatkozást tároljon. Az egyes keresési dokumentumok maximális mérete 16 MB (vagy kevesebb, ha egy kérelemben több dokumentumot tölt fel tömegesen). További információkért tekintse meg az Azure AI Search szolgáltatáskorlátait.
Lekérdezési kötetekkel kapcsolatos szempontok
A másodpercenkénti lekérdezések (QPS) fontos metrikák a teljesítmény finomhangolása során, de a kapacitástervezés szempontjából csak akkor válik megfontolandóvá, ha az elején magas lekérdezési mennyiségre számít.
A standard szintek biztosíthatják a replikák és partíciók egyensúlyát. Növelheti a lekérdezési fordulatot, ha replikákat ad hozzá a terheléselosztáshoz, vagy partíciókat ad hozzá a párhuzamos feldolgozáshoz. Ezután a szolgáltatás kiépítése után hangolhatja a teljesítményt.
Ha a kezdettől magas, tartós lekérdezési kötetekre számít, érdemes megfontolni a magasabb standard szinteket, amelyeket erősebb hardverek támogatnak. Ezután offline állapotba helyezhet partíciókat és replikákat, vagy akár alacsonyabb szintű szolgáltatásra is válthat, ha ezek a lekérdezési kötetek nem fordulnak elő. A lekérdezések átviteli sebességének kiszámításáról további információt a lekérdezések figyelése című témakörben talál.
A tárterületoptimalizált szintek nagy adatterhelésekhez hasznosak, így a lekérdezési késési követelmények kevésbé fontos, átfogóbb indextárolást támogatnak. Továbbra is további replikákat kell használnia a terheléselosztáshoz, és további partíciókat a párhuzamos feldolgozáshoz. Ezután a szolgáltatás kiépítése után hangolhatja a teljesítményt.
Szolgáltatási szintű szerződések
Az ingyenes szint és az előzetes verziójú funkciókra nem vonatkoznak szolgáltatásiszint-szerződések (SLA-k). Az összes számlázható szint esetében az SLA-k akkor lépnek érvénybe, amikor elegendő redundanciát épít ki a szolgáltatáshoz. Két vagy több replikával kell rendelkeznie a lekérdezési (olvasási) SLA-khoz. Három vagy több replikával kell rendelkeznie a lekérdezési és indexelési (olvasási-írási) SLA-khoz. A partíciók száma nem befolyásolja az SLA-kat.
Tippek kapacitástervezéshez
Lehetővé teszi a metrikák számára, hogy lekérdezések köré építkezhessenek, és adatokat gyűjthessenek a használati minták köré (munkaidőn belüli lekérdezések, csúcsidőn kívüli indexelés). Ezekkel az adatokkal tájékoztathatja a szolgáltatáskiépítési döntéseket. Bár ez nem praktikus óránként vagy naponta, dinamikusan módosíthatja a partíciókat és az erőforrásokat a lekérdezési kötetek tervezett változásainak megfelelően. A nem tervezett, de tartós változásokat is el tudja fogadni, ha a szintek elég hosszúak ahhoz, hogy cselekvést indokoljanak.
Ne feledje, hogy a kiépítés egyetlen hátránya, hogy előfordulhat, hogy le kell bontani egy szolgáltatást, ha a tényleges követelmények nagyobbak, mint az előrejelzések. A szolgáltatáskimaradás elkerülése érdekében egy új szolgáltatást magasabb szinten hozna létre, és egymás mellett futtatná, amíg az összes alkalmazás és kérés meg nem célozza az új végpontot.
Mikor kell kapacitást hozzáadni?
Kezdetben a szolgáltatás egy minimális erőforrásszintet foglal le, amely egy partícióból és egy replikából áll. A választott szint határozza meg a partíció méretét és sebességét, és minden réteg különböző forgatókönyvekhez illeszkedő jellemzők köré van optimalizálva. Ha magasabb szintű szintet választ, előfordulhat , hogy kevesebb partícióra van szüksége, mint ha az S1-et használja. Az önkiszolgáló teszteléssel megválaszolandó kérdések egyike, hogy egy nagyobb és drágább partíció jobb teljesítményt nyújt-e, mint egy alacsonyabb szinten kiépített szolgáltatás két olcsóbb partíciója.
Egyetlen szolgáltatásnak elegendő erőforrással kell rendelkeznie az összes számítási feladat (indexelés és lekérdezés) kezeléséhez. Egyik számítási feladat sem fut a háttérben. Ütemezheti az indexelést olyan időszakokra, amikor a lekérdezési kérések természetesen ritkábban fordulnak elő, de a szolgáltatás máskülönben nem rangsorolja az egyik feladatot a másikhoz. Emellett bizonyos mértékű redundancia kisimítja a lekérdezési teljesítményt a szolgáltatások vagy csomópontok belső frissítésekor.
Néhány irányelv a kapacitás hozzáadásának meghatározásához:
- A szolgáltatásiszint-szerződés magas rendelkezésre állási feltételeinek teljesítése
- A HTTP 503-hibák gyakorisága növekszik
- Nagy lekérdezési kötetek várhatók
Általános szabály, hogy a keresési alkalmazásoknak általában több replikára van szükségük, mint a partíciókra, különösen akkor, ha a szolgáltatásműveletek elfogultak a lekérdezési számítási feladatok felé. Minden replika az index egy-egy példánya, amely lehetővé teszi a szolgáltatás számára a kérelmek több példány közötti terheléselosztását. Az indexek terheléselosztását és replikálását az Azure AI Search felügyeli, és bármikor módosíthatja a szolgáltatáshoz lefoglalt replikák számát. Egy Standard keresési szolgáltatásban legfeljebb 12 replikát, egy alapszintű keresési szolgáltatásban pedig 3 replikát foglalhat le. A replikafoglalás az Azure Portalról vagy a programozott lehetőségek egyikéből végezhető el.
A közel valós idejű adatfrissítést igénylő keresési alkalmazásoknak a replikákhoz képest arányosan több partícióra lesz szükségük. A partíciók hozzáadása több számítási erőforrás olvasási/írási műveleteit is elosztja. Emellett több lemezterületet biztosít további indexek és dokumentumok tárolásához.
Végül a nagyobb indexek lekérdezése tovább tart. Így előfordulhat, hogy a partíciók növekményes növekedéséhez kisebb, de arányos replikákra van szükség. A lekérdezések és a lekérdezéskötet összetettsége azt határozza meg, hogy a lekérdezések végrehajtása milyen gyorsan fordul meg.
Feljegyzés
További replikák vagy partíciók hozzáadása növeli a szolgáltatás futtatásának költségeit, és enyhe eltéréseket okozhat az eredmények sorrendjében. Ellenőrizze a díjkalkulátort , hogy megértse a további csomópontok hozzáadásának számlázási következményeit. Az alábbi diagram segíthet kereszthivatkozást adni az adott konfigurációhoz szükséges keresési egységek számának. További információ arról, hogy a további replikák hogyan befolyásolják a lekérdezések feldolgozását, tekintse meg az eredmények sorrendjét.
Replikák és partíciók hozzáadása vagy csökkentése
Jelentkezzen be az Azure Portalra , és válassza ki a keresési szolgáltatást.
A Gépház alatt nyissa meg a Skálázás lapot a replikák és partíciók módosításához.
Az alábbi képernyőképen egy egyszerű szabvány látható, amely egyetlen replikával és partícióval van kiépítve. Az alsó képlet azt jelzi, hogy hány keresési egység van használatban (1). Ha az egységár 100 dollár (nem valós ár), a szolgáltatás futtatásának havi költsége átlagosan 100 dollár lenne.
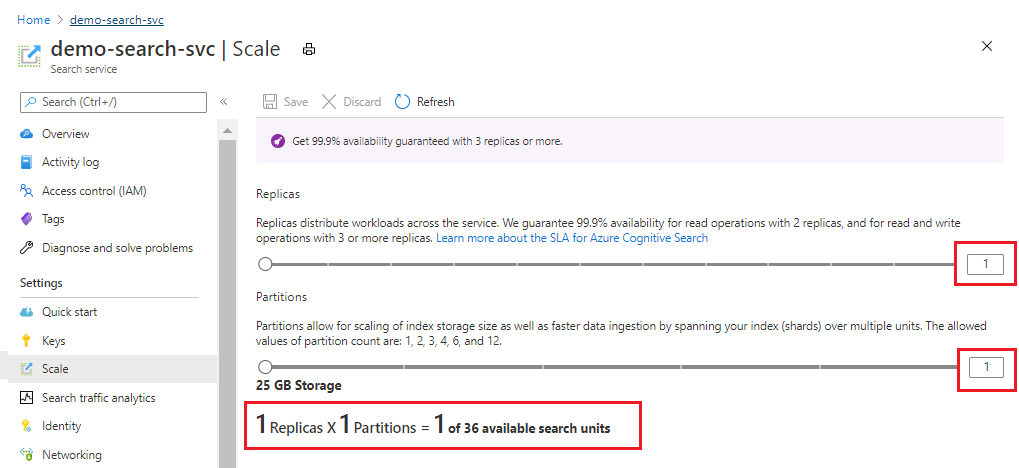
A csúszkával növelheti vagy csökkentheti a partíciók számát. Válassza a Mentés lehetőséget.
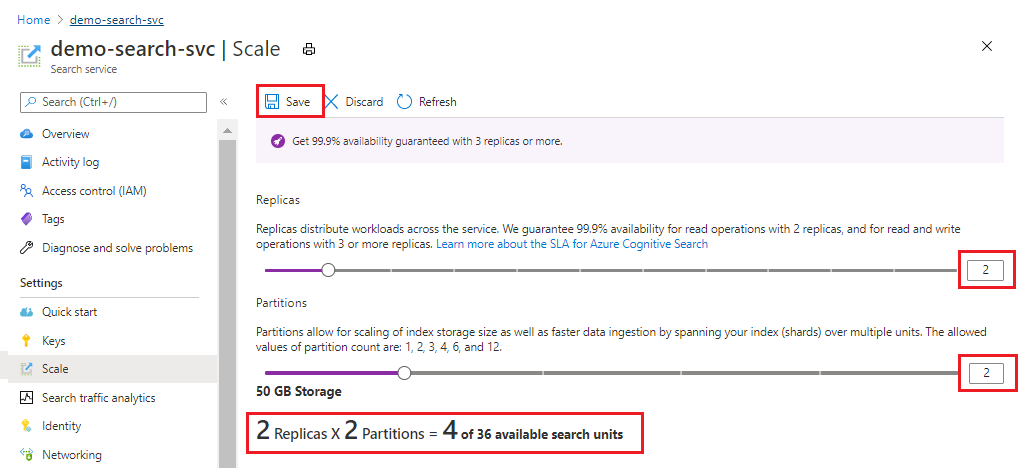
Ez a példa egy második replikát és partíciót ad hozzá. Figyelje meg a keresési egységek számát; ez most négy, mert a számlázási képlet replikák és partíciók szorzata (2 x 2). A kapacitás megduplázása több mint duplája a szolgáltatás futtatásának költségeinek. Ha a keresési egység költsége 100 usd volt, az új havi számla most 400 dollár lesz.
Az egyes szintek egységenkénti aktuális költségeiért látogasson el a Díjszabás oldalra.
A mentés után ellenőrizheti az értesítéseket, hogy a művelet sikeres volt-e.
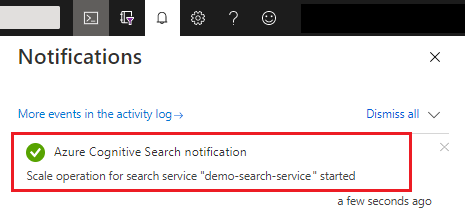
A kapacitás módosítása akár 15 perctől akár több óráig is eltarthat. A folyamat elindítása után nem szakíthatja meg a műveletet, és nincs valós idejű monitorozás a replika- és partíciókorrekciókhoz. Az alábbi üzenet azonban látható marad, amíg a módosítások folyamatban vannak.

Feljegyzés
A szolgáltatás kiépítése után nem frissíthető magasabb szintre. Létre kell hoznia egy keresési szolgáltatást az új szinten, és újra kell betöltenie az indexeket. A szolgáltatáskiépítéssel kapcsolatos segítségért tekintse meg az Azure AI-Search szolgáltatás létrehozása a portálon című témakört.
A méretezési kérelmek kezelése
Méretezési kérelem beérkezésekor a keresési szolgáltatás:
- Ellenőrzi, hogy a kérelem érvényes-e.
- Megkezdi az adatok és a rendszerinformációk biztonsági mentését.
- Ellenőrzi, hogy a szolgáltatás már kiépítési állapotban van-e (jelenleg replikákat vagy partíciókat ad hozzá vagy szüntet meg).
- Megkezdi a kiépítést.
A szolgáltatás skálázása a szolgáltatás méretétől és a kérés hatókörétől függően akár 15 percet vagy akár egy órát is igénybe vehet. A biztonsági mentés az adatok mennyiségétől, valamint a partíciók és replikák számától függően több percet is igénybe vehet.
A fenti lépések nem teljesen egymást követő lépések. A rendszer például akkor kezdi el a kiépítést, amikor biztonságosan megteheti, ami lehet, hogy a biztonsági mentés leáll.
Skálázási hibák
A "Szolgáltatásfrissítési műveletek jelenleg nem engedélyezettek, mert egy korábbi kérést dolgozunk fel" hibaüzenetet az okozza, hogy megismétli a le- vagy felskálázásra vonatkozó kérést, ha a szolgáltatás már feldolgoz egy korábbi kérést.
A hiba megoldásához ellenőrizze a szolgáltatás állapotát a kiépítési állapot ellenőrzéséhez:
- A szolgáltatás állapotának lekéréséhez használja a Felügyeleti REST API-t, az Azure PowerShellt vagy az Azure CLI-t .
- Hívja meg a Get Service -t (REST) vagy azzal egyenértékűt a PowerShellhez vagy a parancssori felülethez.
- Ellenőrizze a "provisioningState" válaszát : "kiépítés"
Ha az állapot "Kiépítés", várja meg, amíg a kérés befejeződik. Az állapotnak "Sikeres" vagy "Sikertelen" értéknek kell lennie egy másik kérés megkísérlése előtt. Nincs állapot a biztonsági mentéshez. A biztonsági mentés egy belső művelet, és nem valószínű, hogy tényező lenne a skálázási gyakorlatok megszakításában.
Ha úgy tűnik, hogy a keresési szolgáltatás kiépítési állapotban elakadt, keressen használhatatlan árva indexeket, nulla lekérdezési kötettel és indexfrissítés nélkül. A használhatatlan indexek blokkolhatják a szolgáltatási kapacitás változásait. Különösen olyan indexeket keressen, amelyek CMK-titkosítással vannak eltitkolva, és amelyek kulcsai már nem érvényesek. Törölje az indexet, vagy állítsa vissza a kulcsokat az index online állapotba helyezéséhez és a méretezési művelet letiltásához.
Partíció- és replikakombinációk
A 2024. április 3. előtt létrehozott keresési szolgáltatások esetében: Az alapszintű szolgáltatás pontosan egy partícióval és legfeljebb három replikával rendelkezhet, legfeljebb három termékváltozatra. Az egyetlen állítható erőforrás a replikák.
A 2024. április 3. után létrehozott keresési szolgáltatások támogatott régiókban: Az alapszintű szolgáltatás legfeljebb három partícióval és három replikával rendelkezhet. A maximális SU-korlát kilenc, amely támogatja a partíciók és replikák teljes kiegészítését.
Bármely számlázható szinten elérhető keresési szolgáltatásokhoz a létrehozás dátumától függetlenül legalább két replikára van szükség a lekérdezések magas rendelkezésre állásához.
Az összes standard és tárolási optimalizált keresési szolgáltatás feltételezheti a replikák és partíciók alábbi kombinációit, az ezen szintekre engedélyezett 36 SU-korlátra is figyelemmel.
| 1 partíció | 2 partíció | 3 partíció | 4 partíció | 6 partíció | 12 partíció | |
|---|---|---|---|---|---|---|
| 1 replika | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 replika | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 replika | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 replika | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | n/a |
| 5 replika | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | n/a |
| 6 replika | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | n/a |
| 12 replika | 12 SU | 24 SU | 36 SU | N.A. | N.A. | N.A. |
A termékváltozatokat, a díjszabást és a kapacitást részletesen ismertetjük az Azure webhelyén. További információ: Díjszabás részletei.
Feljegyzés
A replikák és partíciók száma egyenletesen 12-re oszlik (pontosabban 1, 2, 3, 4, 6, 12). Az Azure AI Search előre osztja el az egyes indexeket 12 szegmensre, így egyenlő részekben osztható el az összes partíción. Ha például a szolgáltatás három partícióval rendelkezik, és létrehoz egy indexet, minden partíció az index négy szegmensét fogja tartalmazni. Hogy az Azure AI Search hogyan szilánkokat oszt meg egy indexben, az implementáció részletei, a későbbi kiadásokban változhat. Bár a szám ma 12, nem várható, hogy ez a szám mindig 12 lesz a jövőben.