A Azure Synapse Analytics dedikált SQL-készletének (korábbi nevén SQL DW) csalólapja
Ez a csalólap hasznos tippeket és ajánlott eljárásokat nyújt dedikált SQL-készlet (korábbi nevén SQL DW) megoldások létrehozásához.
Az alábbi ábra egy dedikált SQL-készlettel (korábban SQL DW) rendelkező adattárház tervezésének folyamatát mutatja be:
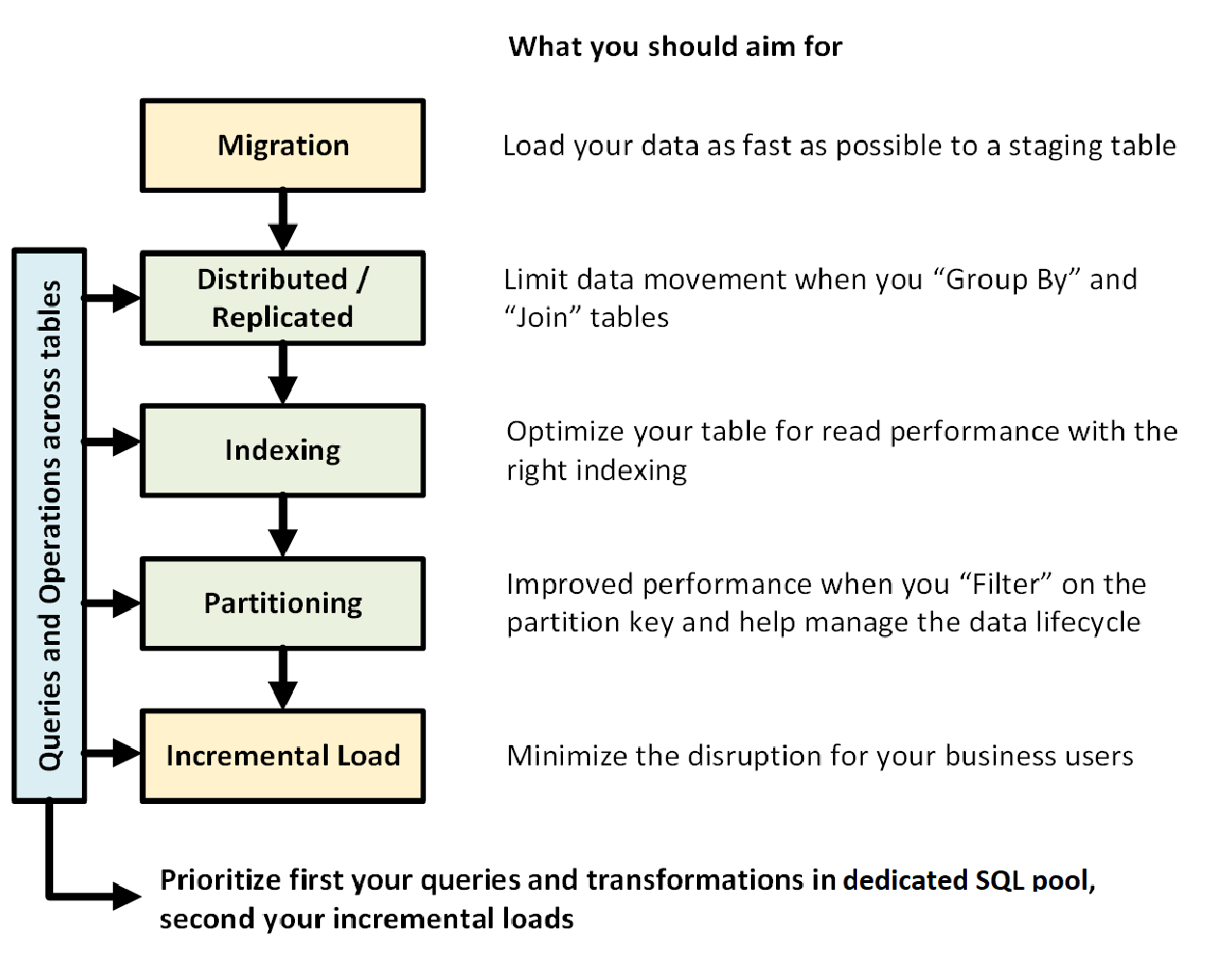
Táblák közötti lekérdezések és műveletek
Ha előre tudja, milyen elsődleges műveleteket és lekérdezéseket futtat majd az adattárházban, figyelembe veheti ezeket az adattárház architektúrájának kialakításakor. Ilyen lekérdezések és műveletek lehetnek többek között a következők:
- Egy vagy két ténytábla egyesítése dimenziótáblákkal, a kombinált tábla szűrése, majd az eredmények összefűzése egy data martba.
- Nagyobb vagy kisebb frissítések elvégzése a tényértékesítésekben.
- Csak adatok hozzáfűzése a táblákhoz.
A művelettípusok előzetes ismerete segít optimalizálni a táblák kialakítását.
Adatok migrálása
Először töltse be az adatokat Azure Data Lake Storage vagy Azure Blob Storage. Ezután a COPY utasítással betöltheti az adatokat az előkészítési táblákba. Használja a következő konfigurációt:
| Tervezés | Ajánlás |
|---|---|
| Disztribúció | Ciklikus időszeletelés |
| Indexelés | Halommemória |
| Particionálás | None |
| Erőforrásosztály | largerc vagy xlargerc |
Itt további információkat tudhat meg az adatok migrálásáról, az adatok betöltéséről és a kinyerési, betöltési és átalakítási (ELT) folyamatról.
Elosztott vagy replikált táblák
A tábla tulajdonságaitól függően a következő stratégiákat használja:
| Típus | Kiválóan alkalmas... | Ügyeljen a következő esetekben: |
|---|---|---|
| Replikált | * Kis méretű táblák csillagsémában, 2 GB-nál kevesebb tárterülettel tömörítés után (~5x tömörítés) | * Sok írási tranzakció van a táblában (például beszúrás, upsert, törlés, frissítés) * Gyakran módosítja Data Warehouse egységek (DWU) kiépítését * Csak 2-3 oszlopot használ, de a táblázat sok oszlopot tartalmaz * Replikált tábla indexelése |
| Ciklikus időszeletelés (alapértelmezett) | * Ideiglenes/átmeneti tábla * Nincs nyilvánvaló csatlakozási kulcs vagy jó jelölt oszlop |
* A teljesítmény az adatáthelyezési folyamat miatt lassú |
| Kivonat | * Ténytáblák * Nagyméretű dimenziótáblák |
* A terjesztési kulcs nem frissíthető |
Tippek:
- Kezdje ciklikus időszeleteléssel, de haladjon a kivonatoló terjesztési stratégia felé, hogy kihasználhassa a nagymértékben párhuzamos architektúrát.
- Ügyeljen arra, hogy a közös kivonatkulcsoknak ugyanaz legyen az adatformátuma.
- Ne terjesszen varchar formátumban.
- A gyakori csatlakozási műveletekkel rendelkező ténytáblákhoz közös kivonatkulccsal rendelkező dimenziótáblákhoz kivonatterjesztés használható.
- A sys.dm_pdw_nodes_db_partition_stats segítségével elemezheti az adatokban lévő eltéréseket.
- A sys.dm_pdw_request_steps használatával elemezheti a lekérdezések mögötti adatmozgásokat, figyelheti az időközvetítést és az elegyítési műveleteket. Ez az elosztási stratégia áttekintéséhez hasznos.
További tudnivalók a replikált táblákról és az elosztott táblákról.
A tábla indexelése
Az indexelés a táblák gyors olvasásához hasznos. Egyedi technológiákat alkalmazhat az igényei szerint:
| Típus | Kiválóan alkalmas... | Ügyeljen a következő esetekben: |
|---|---|---|
| Halommemória | * Átmeneti/ideiglenes tábla * Kis táblázatok kis keresésekkel |
* Minden keresés megvizsgálja a teljes táblázatot |
| Fürtözött index | * Akár 100 millió sorból * Nagy táblák (több mint 100 millió sor) csak 1-2 oszlop erősen használt |
* Replikált táblán használva * Összetett lekérdezések vannak, amelyek több csatlakozást és csoportosítási műveleteket foglalnak magukban * Frissítéseket készít az indexelt oszlopokon: memóriát igényel |
| Fürtözött oszlopcentrikus index (CCI) (alapértelmezett) | * Nagy táblák (több mint 100 millió sor) | * Replikált táblán használva * Jelentős frissítési műveleteket hajt végre a táblán * Túlparticionálja a táblát: a sorcsoportok nem terjednek át a különböző terjesztési csomópontokra és partíciókra |
Tippek:
- A fürtözött indexek mellett érdemes lehet nem fürtözött indexet is hozzáadni a szűréshez gyakran használt oszlopokhoz.
- Ügyeljen arra, hogyan kezeli a memóriát a CCI-vel rendelkező táblákban. Adatok betöltésekor az a cél, hogy a felhasználó (vagy a lekérdezés) nagyméretű erőforrásosztályt használhasson. Kerülje a vágást és sok kis tömörített sorcsoport létrehozását.
- A Gen2-n a teljesítmény maximalizálása érdekében a CCI-táblák gyorsítótárazása a számítási csomópontokon helyben történik.
- CCI esetén a sorcsoportok nem megfelelő tömörítése miatt gyenge lehet a teljesítmény. Ilyen esetben állítsa össze újra vagy rendezze át a CCI-t. Tömörített sorcsoportonként legalább 100 000 sorra van szükség. Az ideális a sorcsoportonként 1 millió sor.
- A növekményes terhelési gyakoriság és méret alapján érdemes lehet automatizálni az indexek átrendezésekor vagy újraépítésekor. A tavaszi nagytakarítás mindig hasznos.
- A sorcsoportokat stratégiai szempontok szerint vágja. Mekkorák a nyitott sorcsoportok? Mennyi adatot tervez betölteni a következő napokban?
További információk az indexekről.
Particionálás
Particionálhatja a táblát nagyméretű ténytábla esetén (1 milliárd sornál nagyobb). Az esetek 99 százalékában a partíciókulcsnak dátumon kell alapulnia.
ELT-t igénylő előkészítési táblák esetén hasznos lehet a particionálás. Ez megkönnyíti az adatok életciklus-felügyeletét. Ügyeljen arra, hogy ne legyen túlparticionálva a tény vagy az előkészítési tábla, különösen fürtözött oszlopcentrikus indexek esetén.
További információk a partíciókról.
Növekményes betöltés
Ha növekményesen fogja betölteni az adatokat, először győződjön meg arról, hogy nagyobb méretű erőforrásosztályokat foglalt le az adatok betöltéséhez. Ez különösen akkor fontos, ha fürtözött oszlopcentrikus indexekkel rendelkező táblákba tölt be. További részletekért tekintse meg az erőforrásosztályokat .
Javasoljuk, hogy a PolyBase és az ADF V2 használatával automatizálja az ELT-folyamatokat az adattárházba.
Az előzményadatok nagy mennyiségű frissítéséhez érdemes lehet CTAS-t használni a táblában tartani kívánt adatok megírásához az INSERT, UPDATE és DELETE helyett.
Statisztikák karbantartása
Fontos a statisztikák frissítése, mivel az adatokban jelentős változások történhetnek. Tekintse meg a frissítési statisztikákat annak megállapításához, hogy jelentős változások történtek-e. A frissített statisztikák optimalizálják a lekérdezési terveket. Ha úgy gondolja, hogy túl sokáig tart az összes statisztika karbantartása, körültekintőbben válassza ki, mely oszlopok rendelkezzenek statisztikákkal.
A frissítések gyakoriságát is megadhatja. Előfordulhat például, hogy csak a dátumoszlopokat szeretné frissíteni, amelyekbe napi rendszerességgel kerülnek új értékek. A legnagyobb előnnyel az jár, ha a csatlakozások részét képező, a WHERE záradékban használt és a GROUP BY elemben megtalálható oszlopok statisztikáit készíti el.
További információk a statisztikákról.
Erőforrásosztály
Az erőforráscsoportokkal memóriát foglalhat le a lekérdezések számára. Ha a lekérdezés vagy a betöltés sebességének növelése érdekében több memóriára van szüksége, magasabb erőforrásosztályokat kell lefoglalnia. A nagyobb erőforrásosztályok használata azonban hatással van a párhuzamos működésre. Ezt érdemes figyelembe venni, mielőtt az összes felhasználót nagyméretű erőforrásosztályba helyezné át.
Ha úgy látja, hogy a lekérdezések túl sokáig tartanak, ellenőrizze, hogy a felhasználók nem nagyméretű erőforrásosztályokban futnak-e. A nagyméretű erőforrás osztályok számos egyidejű helyet foglalnak le, ezért más lekérdezések várólistára helyezését okozhatják.
Végül a Dedikált SQL-készlet (korábban SQL DW) Gen2 használatával minden erőforrásosztály 2,5-szer több memóriát kap, mint az 1. generációs.
További információk az erőforrásosztályokról és a párhuzamos működésről.
Csökkentheti költségeit
A Azure Synapse egyik fő funkciója a számítási erőforrások kezelése. Ha nem használja, szüneteltetheti a dedikált SQL-készletet (korábbi nevén SQL DW), ami leállítja a számítási erőforrások számlázását. Az erőforrásokat a teljesítményigényeinek megfelelően skálázhatja. A szüneteltetést az Azure Portalon vagy a PowerShell-lel végezheti el. A skálázáshoz használja a Azure Portal, a PowerShellt, a T-SQL-t vagy egy REST API-t.
Az Azure Functions használatával mostantól bármikor használhatja az automatikus skálázást:

Teljesítményre optimalizálhatja az architektúrát
Küllős architektúra esetén az SQL Database és az Azure Analysis Services használatát javasoljuk. Ez a megoldás a munkaterhelések elkülönítését biztosítja a különböző felhasználói csoportok között, és az SQL Database és az Azure Analysis Services speciális biztonsági funkcióinak használatát teszi lehetővé. Emellett ezzel a módszerrel korlátlan párhuzamos működést biztosíthat a felhasználók számára.
További információ a dedikált SQL-készletet (korábbi nevén SQL DW) használó tipikus architektúrákról az Azure Synapse Analyticsben.
Helyezze üzembe egy kattintással a küllőket sql-adatbázisokban dedikált SQL-készletből (korábbi nevén SQL DW):