HB-sorozatú virtuális gépek méretei
A következőkre vonatkozik: ✔️ Linux rendszerű virtuális gépek ✔️ Windows rendszerű virtuális gépek Rugalmas méretezési ✔️ csoportok ✔️ Egységes méretezési csoportok
Számos teljesítménytesztet futtattunk HB-sorozatú méreteken. Az alábbiakban a teljesítménytesztelés néhány eredményét mutatjuk be.
| Workload | HB |
|---|---|
| STREAM triád | 260 GB/s (CCX-enként 32-33 GB/s) |
| Nagy teljesítményű Linpack (HPL) | 1000 GigaFLOPS (Rpeak), 860 GigaFLOPS (Rmax) |
| RDMA-késés és sávszélesség | 1,27 mikroszekundum, 99,1 Gb/s |
| FIO a helyi NVMe SSD-n | 1,7 GB/s olvasás, 1,0 GB/s írás |
| IOR on 4 * Azure Premium SSD (P30 Managed Disks, RAID0)** | 725 MB/s olvasás, 780 MB/írás |
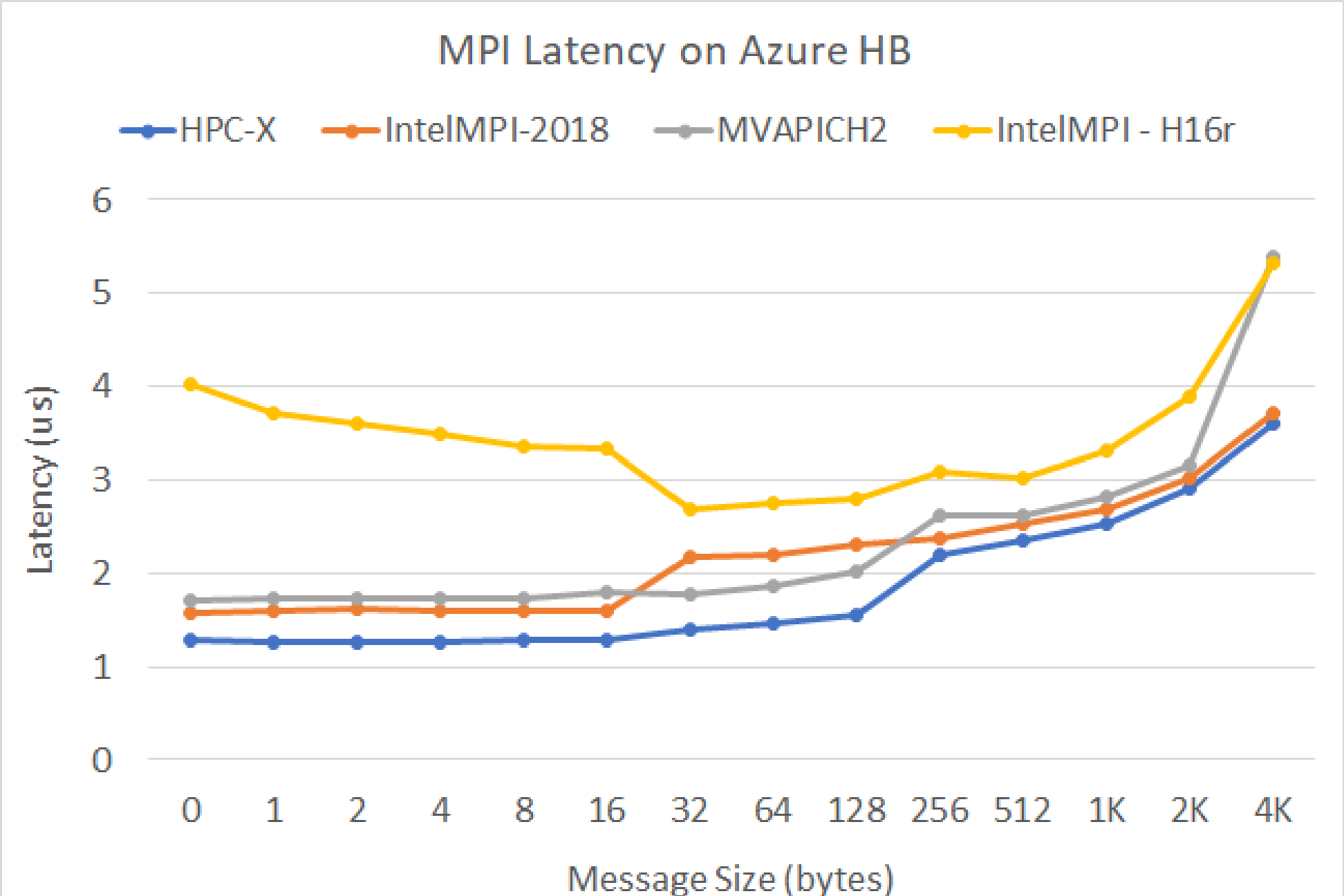
MPI-késés
Fut az OSU microbenchmark csomag MPI-késési tesztje. A mintaszkriptek a GitHubon találhatók
./bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./osu_latency
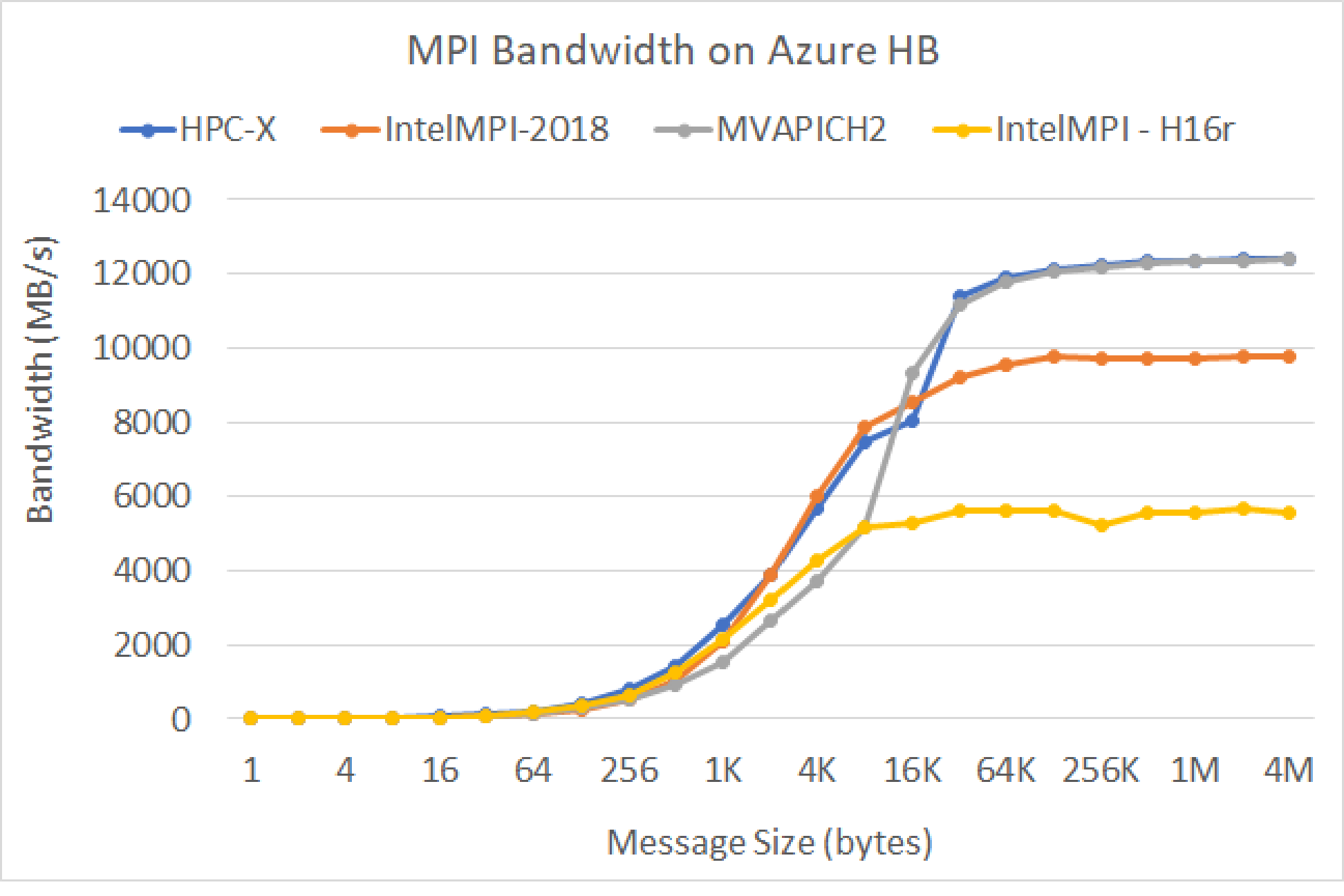
MPI-sávszélesség
Fut az OSU microbenchmark csomag MPI-sávszélesség-tesztje. A mintaszkriptek a GitHubon találhatók
./mvapich2-2.3.install/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=[INSERT CORE #] ./mvapich2-2.3/osu_benchmarks/mpi/pt2pt/osu_bw
Mellanox Perftest
A Mellanox Perftest csomag számos InfiniBand-teszttel rendelkezik, például késéssel (ib_send_lat) és sávszélességtel (ib_send_bw). Alább látható egy példaparancs.
numactl --physcpubind=[INSERT CORE #] ib_send_lat -a
További lépések
- Az Azure Compute Tech Community blogjaiban tájékozódhat a legújabb bejelentésekről, a HPC számítási feladatokra vonatkozó példáiról és teljesítményeredményeiről.
- A HPC számítási feladatok futtatásának magasabb szintű architekturális nézetét az Azure-beli nagy teljesítményű számítástechnika (HPC) című témakörben tekintheti meg.