Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Ez a cikk a másolási tevékenység teljesítményoptimalizálási funkcióit ismerteti, amelyeket Azure Data Factory és Synapse-folyamatokban használhat.
Teljesítményfunkciók konfigurálása felhasználói felülettel
Amikor kiválaszt egy Copy tevékenység a folyamatszerkesztő vásznán, és a vászon alatti tevékenységkonfigurációs területen a Beállítások fülre kattint, az összes teljesítményfunkció konfigurálásának lehetőségei alább láthatók.
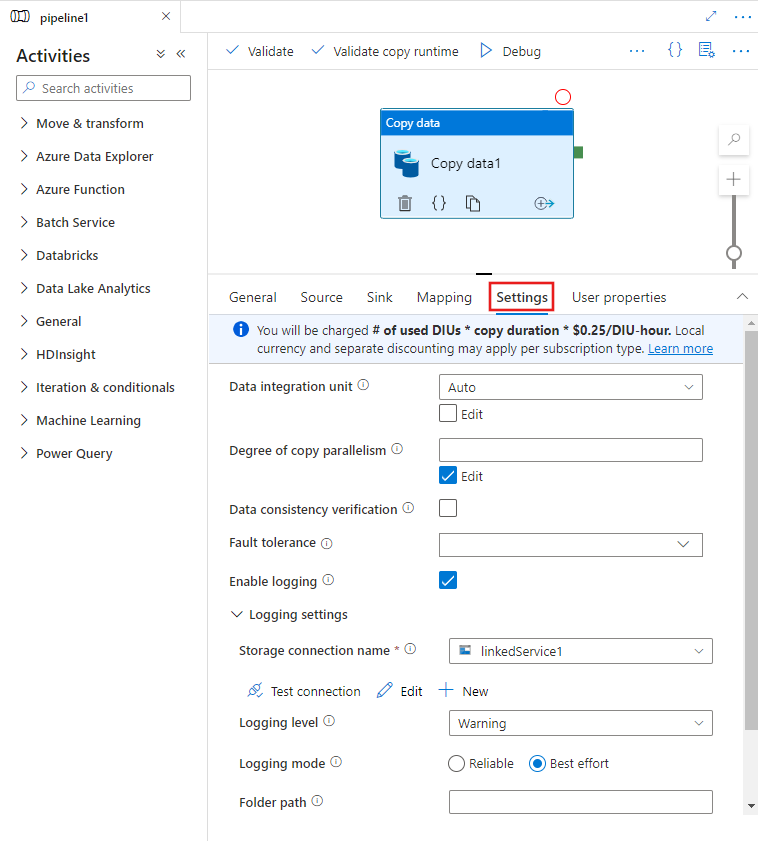
Adatintegrációs egységek
A adatintegráció egység olyan mérték, amely egyetlen egység teljesítményét (a processzor, a memória és a hálózati erőforrás-foglalás kombinációját) jelöli a szolgáltatáson belül. Az adatintegrációs egység csak Azure integrációs modulra vonatkozik, de nem önállóan üzemeltetett integrációs modulra.
A másolási tevékenységek futtatásának engedélyezése engedélyezett DIU-k száma 4 és 256 között van. Ha nincs megadva, vagy a felhasználói felületen az "Automatikus" lehetőséget választja, a szolgáltatás dinamikusan alkalmazza az optimális DIU-beállítást a forrás-fogadó pár és az adatminta alapján. Az alábbi táblázat a különböző másolási forgatókönyvek támogatott DIU-tartományait és alapértelmezett viselkedését sorolja fel:
| Másolási szcenárió | Támogatott DIU-tartomány | Szolgáltatás által meghatározott alapértelmezett DIU-k |
|---|---|---|
| Fájltárolók között |
-
Másolás egyetlen fájlból vagy egyetlen fájlba: 4 - Másolás több fájlból és fájlba: 4-256 a fájlok számától és méretétől függően Ha például egy 4 nagy fájlt tartalmazó mappából másol adatokat, és úgy dönt, hogy megőrzi a hierarchiát, a maximálisan érvényes DIU 16; ha úgy dönt, hogy egyesít egy fájlt, a maximális érvényes DIU 4. |
A fájlok számától és méretétől függően 4 és 32 között |
| Fájltárolóból nem fájltárolóba |
-
Másolás egyetlen fájlból: 4 - Másolás több fájlból: 4-256 a fájlok számától és méretétől függően Ha például egy 4 nagy fájlt tartalmazó mappából másol adatokat, a maximális effektív DIU 16. |
-
Másolás az Azure SQL Database-be vagy az Azure Cosmos DB-be: a fogadószinttől (DTU-k/feladat egységek) és a forrásfájl-mintától függően 4 és 16 között - Másolás az Azure Synapse Analytics-be PolyBase vagy COPY utasítással: 2 - Egyéb forgatókönyv: 4 |
| Nem fájl alapú tárolóból fájl alapú tárolóba |
-
Copy partícióbeállítás-kompatibilis adattárakból (beleértve a Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server és Teradata): 4–256, ha egy mappába ír, 4 pedig egyetlen fájlba. A forrásadat-partíciónkénti jegyzet legfeljebb 4 DIU-t használhat. - Egyéb forgatókönyvek: 4 |
-
Másolás REST-ből vagy HTTP-ből: 1 - Másolás az Amazon Redshiftből a UNLOAD használatával: 4 - Egyéb forgatókönyv: 4 |
| Nem fájl-tárolók között |
-
Copy partícióbeállítás-kompatibilis adattárakból (beleértve a Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server és Teradata): 4–256, ha egy mappába ír, 4 pedig egyetlen fájlba. A forrásadat-partíciónkénti jegyzet legfeljebb 4 DIU-t használhat. - Egyéb forgatókönyvek: 4 |
-
Másolás REST-ből vagy HTTP-ből: 1 - Egyéb forgatókönyv: 4 |
A másolási tevékenység figyelési nézetben vagy tevékenységkimenetben az egyes másolásokhoz használt DIU-k láthatók. További információ: Másolási tevékenység monitorozása. Az alapértelmezett érték felülbírálásához adja meg a tulajdonság értékét az dataIntegrationUnits alábbiak szerint. A másolási művelet által futtatáskor használt DIU-k tényleges száma az adatmintától függően egyenlő vagy kisebb, mint a konfigurált érték.
A felhasznált DIU-k száma * másolás időtartama * egységár/DIU-óra. Az aktuális árakat itt találja. A helyi pénznem és a külön diszkontálás előfizetés-típusonként alkalmazható.
Példa:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Saját üzemeltetésű integrációs modul skálázhatósága
Ha nagyobb átviteli sebességet szeretne elérni, függőlegesen méretezheti vagy vízszintesen méretezheti a saját üzemeltetésű integrációs modult:
- Ha a saját üzemeltetésű INTEGRÁCIÓS csomópont processzora és rendelkezésre álló memóriája nincs teljesen kihasználva, de az egyidejű feladatok végrehajtása eléri a korlátot, a csomóponton futtatható egyidejű feladatok számának növelésével skálázhatja fel a skálázást. Itt talál útmutatást.
- Ha viszont a processzor kihasználtsága magas az önálló IR csomóponton vagy kevés a rendelkezésre álló memória, hozzáadhat egy új csomópontot, hogy a terhelést több csomópontra ossza el. Itt talál útmutatást.
Vegye figyelembe, hogy a következő forgatókönyvekben egyetlen másolási tevékenység végrehajtása több saját üzemeltetésű önálló integrációs modul csomópontot is használhat:
- Adatok másolása fájlalapú tárolókból a fájlok számától és méretétől függően.
- Adatok másolása partíció-beállításokkal kompatibilis adattárból (beleértve a Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server és Teradata) az adatpartíciók számától függően.
Párhuzamos másolás
A párhuzamos másolás beállítható a parallelCopies tulajdonság segítségével a Copy tevékenység JSON-definíciójában, vagy a Degree of parallelism beállítással a Settings lapon a Copy tevékenység tulajdonságai között a felhasználói felületen, hogy jelezze azt a párhuzamosságot, amelyet a másolási tevékenység során alkalmazni kíván. Ezt a tulajdonságot a másolási tevékenységen belüli szálak maximális számaként tekintheti, amelyek párhuzamosan olvasnak a forrásból, vagy írnak a cél adattárakba.
A párhuzamos másolat ortogonálisan viszonyul az adatintegrációs egységekhez vagy a önállóan üzemeltetett IR csomópontokhoz. Az összes DIU-n vagy saját üzemeltetésű IR csomóponton meg van számolva.
Minden másolási tevékenység futtatásakor a szolgáltatás alapértelmezés szerint dinamikusan alkalmazza az optimális párhuzamos másolási beállítást a forrás-fogadó pár és az adatminta alapján.
Tipp.
A párhuzamos másolás alapértelmezett viselkedése általában a legjobb átviteli sebességet biztosítja, amelyet a szolgáltatás automatikusan határoz meg a forrás-fogadó pár, az adatminta és a DIU-k száma vagy a saját üzemeltetésű integrációs modul PROCESSZOR-/memória-/csomópontszáma alapján. A párhuzamos másolás optimalizálási lehetőségeiről a másolási tevékenység teljesítményének hibaelhárítása című részben olvashat.
Az alábbi táblázat a párhuzamos másolási viselkedést sorolja fel:
| Másolási szcenárió | Párhuzamos másolási viselkedés |
|---|---|
| Fájltárolók között |
parallelCopiesa fájl szintjén határozza meg a párhuzamosságot. Az egyes fájlokon belüli adattömbelés automatikusan és transzparensen történik. Úgy tervezték, hogy egy adott adattártípushoz a legmegfelelőbb adattömbméretet használja az adatok párhuzamos betöltéséhez. A futtatáskor használt párhuzamos másolási tevékenység tényleges száma nem több, mint a meglévő fájlok száma. Ha a másolási viselkedés a MergeFile fájl fogadóba kerül, a másolási tevékenység nem tudja kihasználni a fájlszintű párhuzamosságot. |
| Fájltárolóból nem fájltárolóba | - Az adatok Azure SQL Database-be vagy Azure Cosmos DB-be való másolásakor az alapértelmezett párhuzamos másolás a cél szinttől (DTU-k/kérelemegységek (RU-k) száma) is függ. - Ha adatokat másol Azure táblába, az alapértelmezett párhuzamos másolás 4. |
| Nem fájl alapú tárolóból fájl alapú tárolóba | - Ha partícióbeállítás-kompatibilis adattárból másol adatokat (beleértve a Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP tábla, SQL Server, Amazon RDS SQL Server és Teradata esetén az alapértelmezett párhuzamos másolás 4. A futtatáskor használt párhuzamos másolási tevékenység tényleges száma nem nagyobb, mint a meglévő adatpartíciók száma. Ha önállóan üzemeltetett Integration Runtime-ot használ, és Azure Blob/ADLS Gen2-be másol, vegye figyelembe, hogy az IR csomópontonkénti maximális hatékony párhuzamos másolás 4 vagy 5 lehet. – Más esetekben a párhuzamos másolás nem lép érvénybe. Még ha a párhuzamosság is meg van adva, a rendszer nem alkalmazza. |
| Nem fájl-tárolók között | - Az adatok Azure SQL Database-be vagy Azure Cosmos DB-be való másolásakor az alapértelmezett párhuzamos másolás a cél szinttől (DTU-k/kérelemegységek (RU-k) száma) is függ. - Ha partícióbeállítás-kompatibilis adattárból másol adatokat (beleértve a Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP tábla, SQL Server, Amazon RDS SQL Server és Teradata esetén az alapértelmezett párhuzamos másolás 4. - Ha adatokat másol Azure táblába, az alapértelmezett párhuzamos másolás 4. |
Az adattárakat üzemeltető gépek terhelésének szabályozásához vagy a másolási teljesítmény finomhangolásához felülbírálhatja az alapértelmezett értéket, és megadhatja a parallelCopies tulajdonság értékét. Az értéknek 1-nél nagyobb vagy egyenlő egész számnak kell lennie. Futásidőben a másolási tevékenység a legjobb teljesítmény érdekében a beállított értéknél kisebb vagy egyenlő értéket használ.
A tulajdonság értékének parallelCopies megadásakor vegye figyelembe a forrásra és a fogadó adattárakra vonatkozó terhelésnövekedést. Vegye figyelembe a saját üzemeltetésű integrációs futtatókörnyezet terhelésének növelését is, ha a másolási tevékenységet támogatja. Ez a terhelésnövekedés különösen akkor fordul elő, ha ugyanazon adattáron futó tevékenységek több tevékenységével vagy egyidejű futtatásával rendelkezik. Ha azt tapasztalja, hogy az adattár vagy a saját üzemeltetésű integrációs modul túlterhelt a terhelés miatt, csökkentse az értéket a parallelCopies terhelés csökkentése érdekében.
Példa:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Ütemezett másolat
Amikor adatokat másol egy forrásadattárból egy fogadó adattárba, dönthet úgy, hogy Azure Blob Storage-t vagy Azure Data Lake Storage Gen2 ideiglenes átmeneti tárolóként használja. Az előkészítés különösen hasznos a következő esetekben:
- Különböző adattárakból szeretne adatokat beemészteni az Azure Synapse Analyticsbe PolyBase-en keresztül, adatokat másolhat a Snowflake-ből vagy a Snowflake-be, és teljesítményorientáltan betöltheti az adatokat az Amazon Redshiftből/HDFS-ből. További részletek:
- A vállalati informatikai szabályzatok miatt nem szeretné megnyitni a tűzfalon más portokat a 80-as és a 443-as port kivételével. Ha például adatokat másol egy helyszíni adattárból egy Azure SQL Database vagy egy Azure Synapse Analytics, aktiválnia kell a kimenő TCP-kommunikációt az 1433-as porton a Windows tűzfal és a vállalati tűzfal esetében is. Ebben a forgatókönyvben a szakaszos másolás kihasználhatja a saját üzemeltetésű integrációs modul előnyeit, hogy először az adatokat http vagy HTTPS protokollon keresztül másolja egy átmeneti tárolóba a 443-as porton, majd betöltse az adatokat az előkészítésből az SQL Database-be vagy Azure Synapse Analytics. Ebben a folyamatban nem kell engedélyeznie a 1433-as portot.
- Előfordulhat, hogy egy lassú hálózati kapcsolaton keresztül egy hibrid adatáthelyezést (azaz egy helyszíni adattárból egy felhőbeli adattárba való másolást) kell végrehajtani. A teljesítmény javítása érdekében szakaszos másolással tömörítheti a helyszíni adatokat, így kevesebb időt vesz igénybe az adatok áthelyezése az átmeneti adattárba a felhőben. Ezután az átmeneti tárolóban lévő adatokat kibonthatja, mielőtt betöltené a céladattárat.
A szakaszos másolás működése
Az előkészítési funkció aktiválásakor a rendszer először a forrásadattárból az átmeneti tárolóba másolja az adatokat (hozza magával a saját Azure Blobot vagy Azure Data Lake Storage Gen2). Ezután az adatok át lesznek másolva az előkészítésből a fogadó adattárba. A másolási tevékenység automatikusan kezeli a kétfázisú folyamatot, és az átmeneti tárolóból is eltávolítja az ideiglenes adatokat az adatáthelyezés befejezése után.

Törlési engedélyt kell adnia az Azure Data Factory számára az ideiglenes tárolóban, hogy az ideiglenes adatok a másolási művelet futtatása után törölhetők legyenek.
Amikor egy átmeneti tárolóval aktiválja az adatáthelyezést, megadhatja, hogy szeretné-e tömöríteni az adatokat, mielőtt a forrásadattárból az átmeneti tárolóba áthelyezi őket. Az adatokat ezt követően kibontja, mielőtt egy köztes vagy átmeneti tárolóból a fogadó adattárba áthelyezi azokat.
Jelenleg nem másolhat adatokat két olyan adattár között, amelyek különböző saját üzemeltetésű IRS-ek segítségével csatlakoznak egymáshoz, sem szakaszos másolással, sem anélkül. Ilyen esetben két explicit módon láncolt másolási tevékenységet kell konfigurálni, hogy az adatokat a forrásból egy köztes tárolóba, majd onnan a célba másolja.
Konfiguráció
A másolási tevékenység enableStaging beállításának konfigurálásával megadhatja, hogy az adatok a tárolóban legyenek-e, mielőtt betöltené őket egy céladattárba. Ha engedélyezi az előkészítéstTRUE, adja meg az alábbi táblázatban felsorolt további tulajdonságokat.
| Tulajdonság | Leírás | Alapértelmezett érték | Kötelező |
|---|---|---|---|
| enableStaging | Adja meg, hogy ideiglenes átmeneti tárolón keresztül szeretne-e adatokat másolni. | Hamis | Nem |
| linkedServiceName (CsatlakoztatottSzolgáltatásNév) | Adja meg egy Azure Blob Storage vagy Azure Data Lake Storage Gen2 társított szolgáltatás nevét, amely a köztes átmeneti tárolóként használt Storage-példányra hivatkozik. | n/a | Igen, amikor az enableStaging értéke TRUE |
| elérési út | Adja meg a szakaszos adatokat tartalmazó elérési utat. Ha nem ad meg elérési utat, a szolgáltatás létrehoz egy tárolót az ideiglenes adatok tárolásához. | n/a | Nem (Igen, ha storageIntegration a Snowflake-összekötő van megadva) |
| enableCompression | Azt határozza meg, hogy az adatok tömörítve legyenek-e a célhelyre másolás előtt. Ez a beállítás csökkenti az átvitt adatok mennyiségét. | Hamis | Nem |
Megjegyzés
Ha szakaszos másolást használ, és engedélyezve van a tömörítés, a szolgáltatásfőnév vagy az MSI-hitelesítés nem támogatott a staging blob-hoz kapcsolódó szolgáltatásban.
Íme egy másolási tevékenység mintadefiníciója az előző táblázatban ismertetett tulajdonságokkal:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Ütemezett másolás számlázásának hatása
A díjat két lépés alapján számítjuk fel: a másolás időtartama és a másolás típusa.
- Amikor köztes tárolást használ egy felhőbeli másolás során, amely az adatok egyik felhőbeli adattárból egy másikba való másolását jelenti, az Azure integrációs futtatókörnyezet által támogatott mindkét lépésben a következő díjat számítják fel: [az 1. és 2. lépés másolási időtartamának összege] x [felhőalapú másolási egység ára].
- Ha az előkészítést egy hibrid másolás során használja, amely egy helyszíni adattárból egy felhőbeli adattárba másolja az adatokat, a saját üzemeltetésű integrációs modul által támogatott egyik fázisban a [hibrid másolás időtartama] x [hibrid másolási egység ára] + [felhőbeli másolás időtartama] x [felhőbeli másolási egység ára] díjat számítunk fel.
Kapcsolódó tartalom
Lásd a többi másolási tevékenységről szóló cikket: