Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Az adatfolyamok Azure Data Factory folyamatokban és Azure Synapse Analytics folyamatokban is elérhetők. Ez a cikk az adatfolyamok leképezésére vonatkozik. Ha még nem ismerkedik az átalakításokkal, tekintse meg az Adatok átalakítása leképezési adatfolyamokkal című bevezető cikket.
Tipp.
Az Adatfolyam Gen2-ben az ezzel egyenértékű átalakítást (egyéni oszlopot) a Dataflow Gen2 útmutatójában találja az adatfolyam-felhasználók leképezéséhez.
A származtatott oszlopátalakítás használatával új oszlopokat hozhat létre az adatfolyamban, vagy módosíthatja a meglévő mezőket.
Oszlopok létrehozása és frissítése
Származtatott oszlop létrehozásakor létrehozhat egy új oszlopot, vagy frissíthet egy meglévőt. Az Oszlop szövegmezőbe írja be a létrehozott oszlopot. A séma egy meglévő oszlopának felülbírálásához használhatja az oszlop legördülő menüt. A származtatott oszlop kifejezésének létrehozásához válassza ki az Enter kifejezés szövegmezőjét. Elkezdheti gépelni a kifejezést, vagy megnyithatja a kifejezésszerkesztőt a logika létrehozásához.
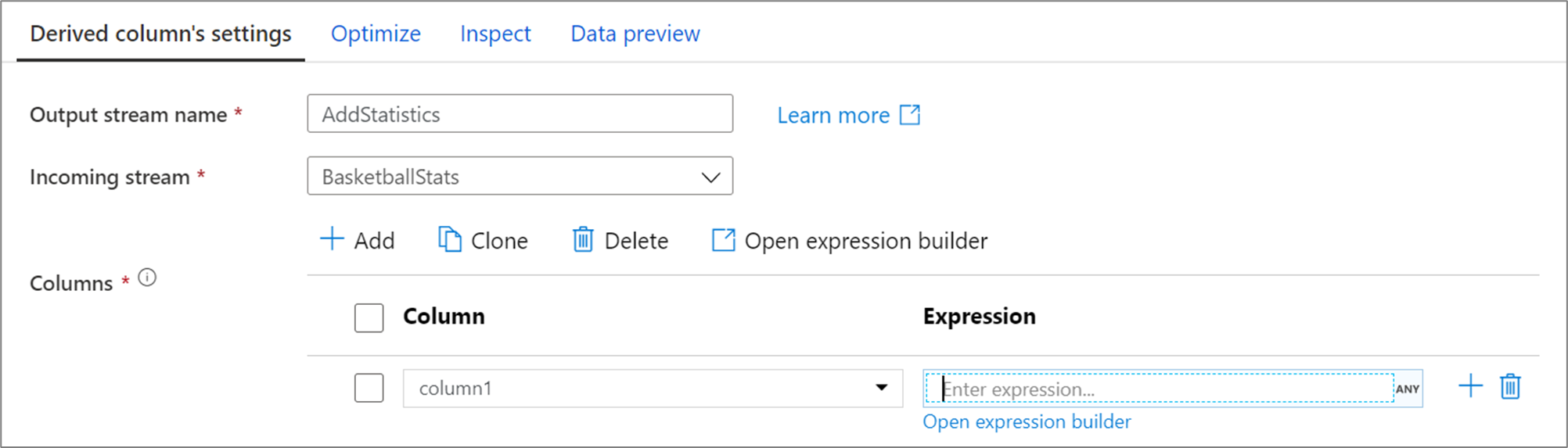
Ha több származtatott oszlopot szeretne hozzáadni, válassza a Hozzáadás elemet az oszloplista fölött, vagy a meglévő származtatott oszlop melletti plusz ikont. Válassza az Oszlop hozzáadása vagy az Oszlopminta hozzáadása lehetőséget.
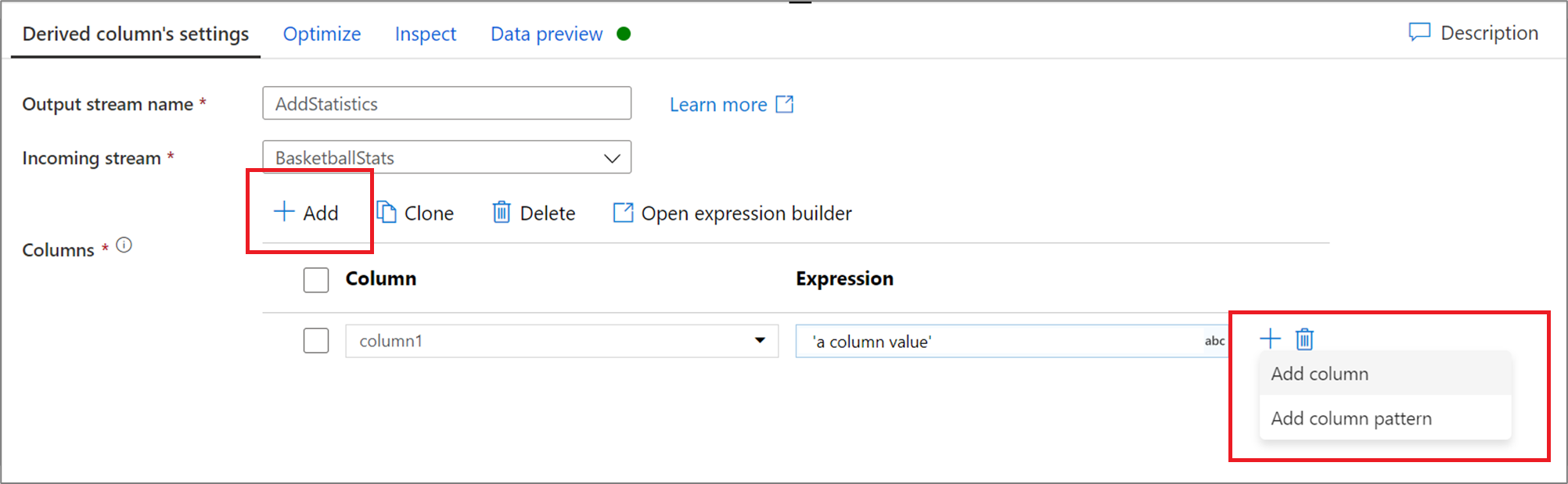
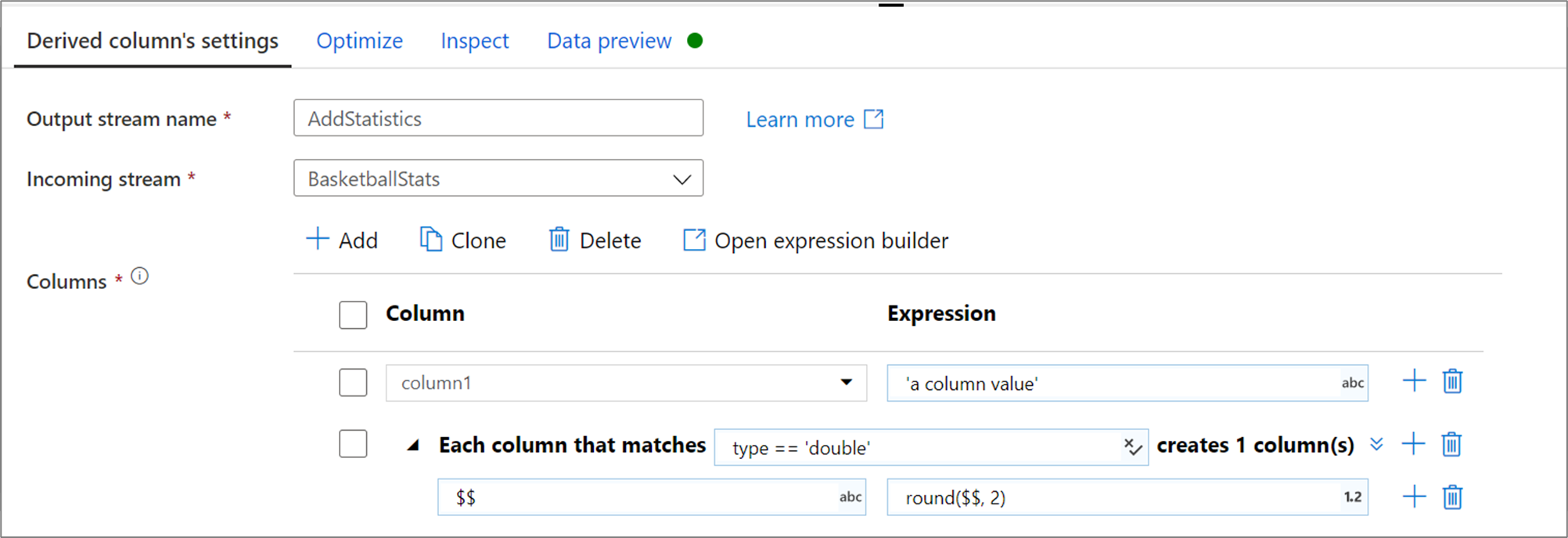
Oszlopminták
Olyan esetekben, amikor a séma nincs explicit módon definiálva, vagy ha tömegesen szeretne frissíteni egy oszlopkészletet, oszlopmintákat kell létrehoznia. Az oszlopminták lehetővé teszik az oszlopok egyeztetését az oszlop metaadatain alapuló szabályok használatával, és származtatott oszlopokat hozhat létre az egyes egyező oszlopokhoz. További információkért megtudhatja , hogyan hozhat létre oszlopmintákat a származtatott oszlopátalakításban.
Sémák létrehozása a kifejezésszerkesztővel
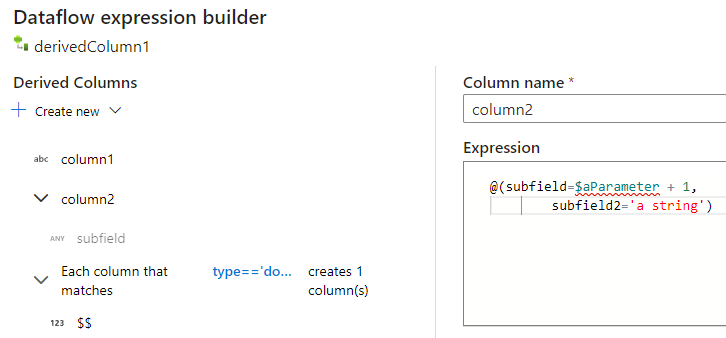
Az adatfolyam-leképezési kifejezésszerkesztő használatakor a származtatott oszlopokat a Származtatott oszlopok szakaszban hozhatja létre, szerkesztheti és kezelheti. Az átalakítás során létrehozott vagy módosított összes oszlop megjelenik a listában. Az oszlop nevének kiválasztásával interaktívan kiválaszthatja, hogy melyik oszlopot vagy mintát szerkeszti. Másik oszlop hozzáadásához válassza az Új létrehozása lehetőséget, és adja meg, hogy egyetlen oszlopot vagy mintát szeretne-e hozzáadni.
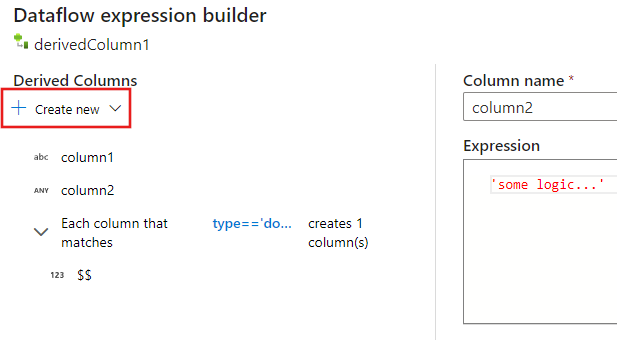
Összetett oszlopok használatakor aloszlopokat hozhat létre. Ehhez válassza a plusz ikont bármelyik oszlop mellett, és válassza a Subcolumn hozzáadása lehetőséget. Az adatfolyam összetett típusainak kezelésével kapcsolatos további információkért lásd : JSON-kezelés a leképezési adatfolyamban.
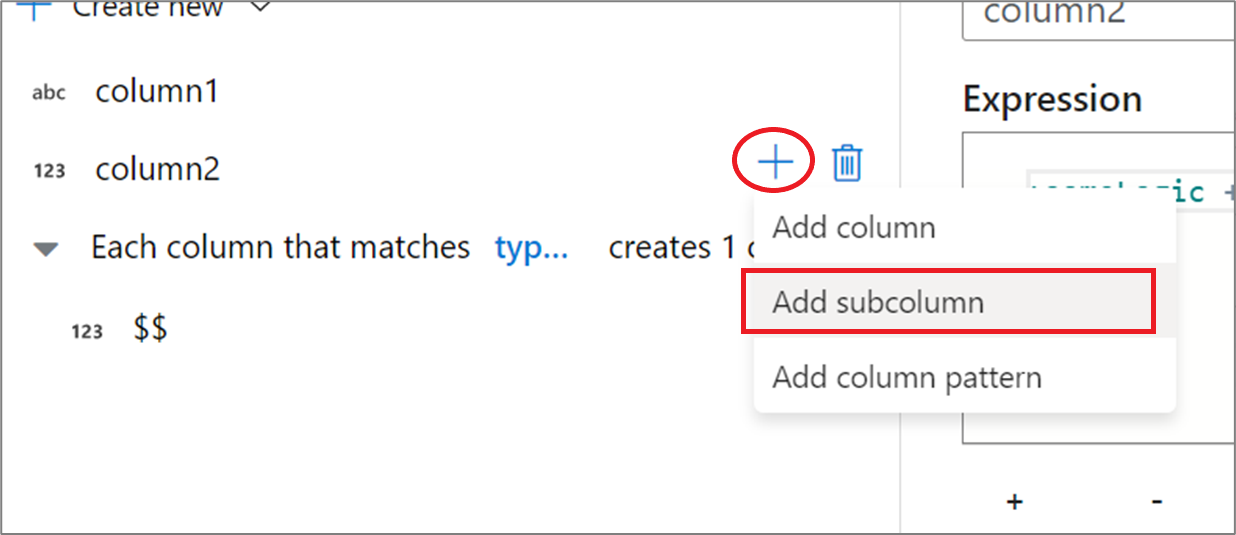
Az adatfolyam összetett típusainak kezelésével kapcsolatos további információkért lásd : JSON-kezelés a leképezési adatfolyamban.
Adatfolyamszkript
Szintaxis
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Példa
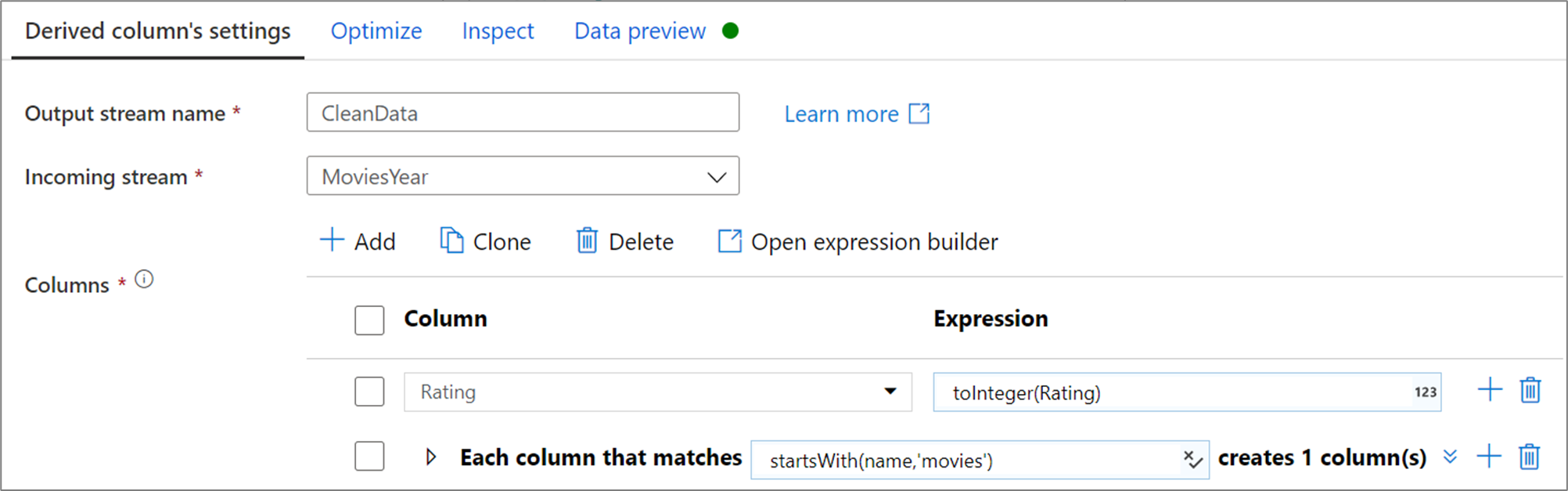
Az alábbi példa egy származtatott oszlop CleanData , amely egy bejövő streamet MoviesYear használ, és két származtatott oszlopot hoz létre. Az első származtatott oszlopban az Rating oszlop értékét a Rating értékére cseréli, amely egész szám típusú lesz. A második származtatott oszlop egy olyan minta, amely megfelel azoknak az oszlopoknak, amelyeknek a neve "filmek" néven kezdődik. Minden egyeztetett oszlophoz létrehoz egy olyan oszlopot movie , amely megegyezik a "movie_" előtaggal rendelkező egyező oszlop értékével.
A felhasználói felületen ez az átalakítás az alábbi képhez hasonlóan néz ki:
Az átalakítás adatfolyam-szkriptje az alábbi kódrészletben található:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
Kapcsolódó tartalom
- További információ a Mapping Adatfolyam kifejezési nyelvéről.