Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Az adatfolyamok Azure Data Factory folyamatokban és Azure Synapse Analytics folyamatokban is elérhetők. Ez a cikk az adatfolyamok leképezésére vonatkozik. Ha még nem ismerkedik az átalakításokkal, tekintse meg az Adatok átalakítása leképezési adatfolyamokkal című bevezető cikket.
Tipp
A 2. generációs adatfolyam egyenértékű átalakításával (oszlopok kiválasztása) kapcsolatban tekintse meg az Adatfolyam Gen2 útmutatóját az adatfolyam-felhasználók leképezéséhez.
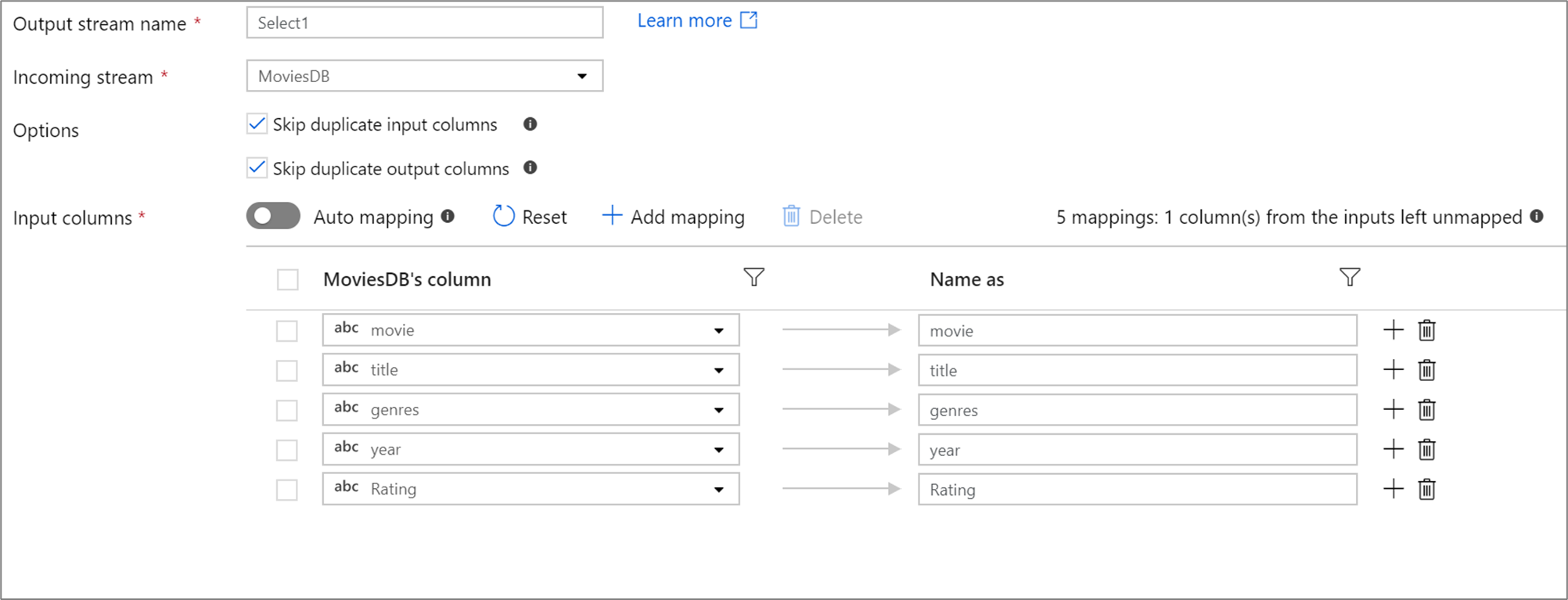
A kijelölés átalakításával átnevezheti, elvetheti vagy átrendezheti az oszlopokat. Ez az átalakítás nem módosítja a soradatokat, hanem azt választja ki, hogy mely oszlopokat propagálja a rendszer az alsóbb rétegben.
A kiválasztási átalakítások során a felhasználók rögzített leképezéseket adhatnak meg, szabályalapú leképezést végezhetnek mintákkal, vagy engedélyezhetik az automatikus leképezést. A rögzített és a szabályalapú leképezések is használhatók ugyanazon a kiválasztási átalakításon belül. Ha egy oszlop nem egyezik a megadott leképezések egyikével, a rendszer elveti.
Rögzített leképezés
Ha a vetítésben kevesebb mint 50 oszlop van definiálva, az összes definiált oszlop alapértelmezés szerint rögzített leképezéssel rendelkezik. A rögzített leképezés egy definiált, bejövő oszlopot vesz fel, és pontos nevet képez le.
Megjegyzés
Rögzített leképezéssel nem képezhet le vagy nevezhet át sodródott oszlopokat
Hierarchikus oszlopok leképezése
A rögzített leképezések a hierarchikus oszlopok almappáinak felső szintű oszlophoz való leképezéséhez használhatók. Ha definiált hierarchiával rendelkezik, az oszlop legördülő listájával jelöljön ki egy aloszlopot. A kiválasztási átalakítás egy új oszlopot hoz létre az alhalmaz értékével és adattípusával.
Szabályalapú leképezés
Ha egyszerre több oszlopot szeretne leképezni, vagy át szeretne haladni az elsodródott oszlopokon, szabályalapú leképezéssel oszlopminták használatával határozhatja meg a leképezéseket. Egyezés a name, type, stream, és position az oszlopok alapján. A rögzített és szabályalapú leképezések bármilyen kombinációjával rendelkezhet. Alapértelmezés szerint az 50 oszlopnál nagyobb vetítések alapértelmezés szerint szabályalapú leképezésre kerülnek, amelyek minden oszlopon megegyeznek, és a bemeneti nevet adja ki.
Szabályalapú leképezés hozzáadásához kattintson a Leképezés hozzáadása elemre, és válassza a Szabályalapú megfeleltetés lehetőséget.

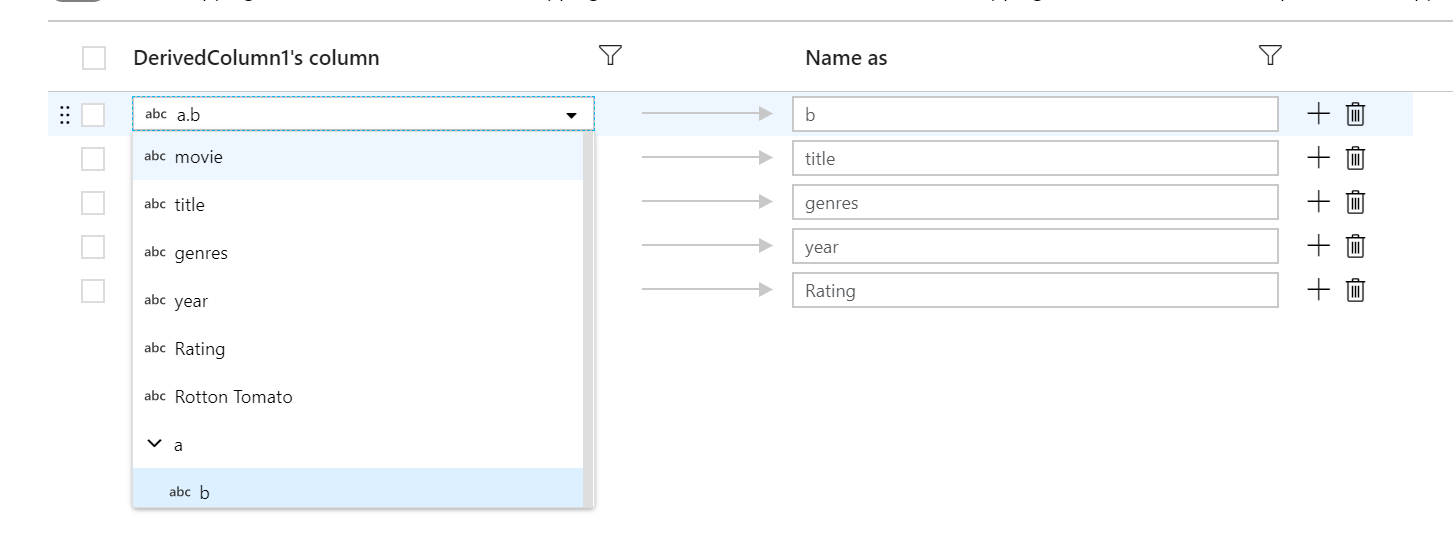
Minden szabályalapú megfeleltetéshez két bemenet szükséges: az a feltétel, amely alapján egyezni kell, és hogy mit nevezze el az egyes megfeleltetett oszlopoknak. Mindkét érték bevitele a kifejezésszerkesztőn keresztül van megadva. A bal oldali kifejezésmezőbe írja be a logikai egyezés feltételét. A jobb oldali kifejezésmezőben adja meg, hogy a megfeleltetett oszlop mire lesz megfeleltetve.

Szintaxissal $$ hivatkozhat egy egyeztetett oszlop bemeneti nevére. Például ha a fenti képet vesszük alapul, tegyük fel, hogy egy felhasználó szeretné az összes olyan sztringoszlopot megtalálni, amelynek a neve rövidebb, mint hat karakter. Ha egy bejövő oszlop neve el lett nevezve test, a kifejezés $$ + '_short' átnevezi az oszlopot test_short. Ha ez az egyetlen leképezés, a rendszer minden olyan oszlopot elvet a kimeneti adatokból, amelyek nem felelnek meg a feltételnek.
A minták egyeznek a sodródott és a definiált oszlopokkal is. Ha látni szeretné, hogy mely definiált oszlopokat képezi le egy szabály, kattintson a szabály melletti szemüveg ikonra. Ellenőrizze a kimenetet az adatelőnézet használatával.
Regex-leképezés
Ha a lefelé mutató sáv ikonra kattint, megadhatja a regex-leképezési feltételt. A regex-leképezési feltétel megegyezik az összes olyan oszlopnévvel, amely megfelel a megadott regex feltételnek. Ez standard szabályalapú leképezésekkel kombinálva használható.

A fenti példa egyezik a regex mintával (r) vagy bármely oszlopnévvel, amely tartalmaz egy kis 'r'-t. A normál szabályalapú leképezéshez hasonlóan az összes egyező oszlopot a jobb oldali feltételt a $$ szintaxissal módosítják.
Ha az oszlopnév több regex egyezést tartalmaz, meghatározott egyezésekre hivatkozhat a $n használatával, ahol 'n' az egyezés számát jelöli. A $2 például egy oszlopnév második egyezésére utal.
Szabályalapú hierarchiák
Ha a definiált kivetítés hierarchiával rendelkezik, szabályalapú leképezéssel megfeleltetheti a hierarchiák almappáit. Adjon meg egy megfelelő feltételt és azt az összetett oszlopot, amelynek almappáit le szeretné képezni. A rendszer minden egyező oszlopot a jobb oldalon megadott "Name as" szabály szerint ad ki.
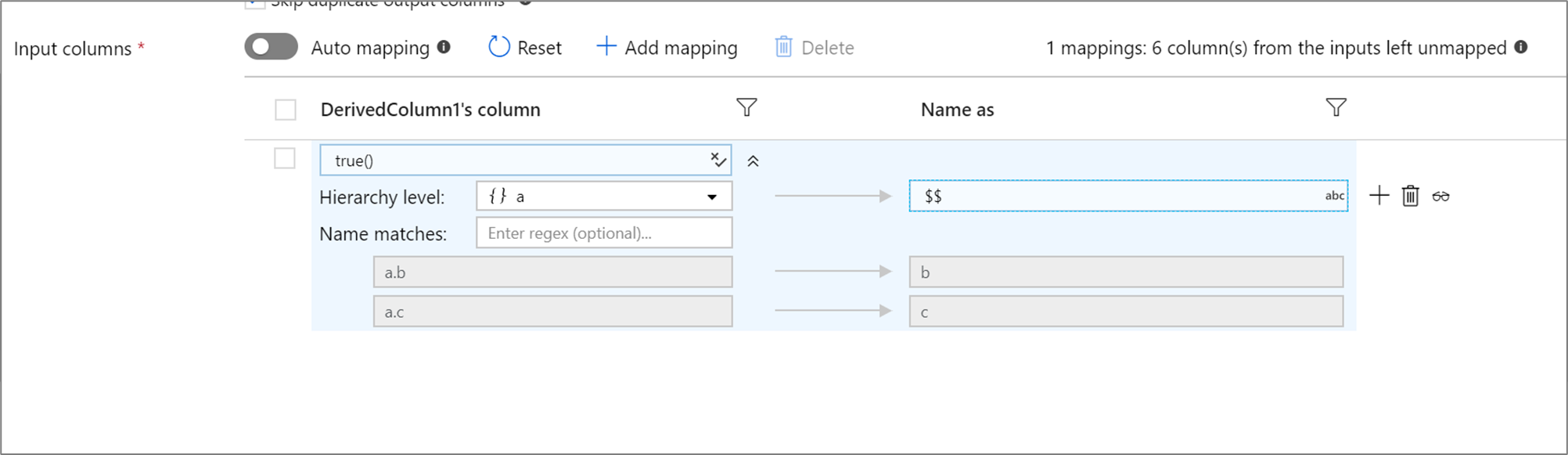
A fenti példa az összetett oszlop aösszes almappáján megegyezik.
a két alsóoszlopot tartalmaz: b és c. A kimeneti séma két oszlopot b fog tartalmazni, és c mivel a "Név mint" feltétel az $$.
Paraméterezés
Az oszlopneveket szabályalapú leképezéssel paraméterezheti. Használja a kulcsszót name a bejövő oszlopnevek paraméterrel való egyeztetéséhez. Ha például rendelkezik adatfolyam-paraméterrelmycolumn, létrehozhat egy olyan szabályt, amely megegyezik minden olyan oszlopnévvel, amely egyenlő.mycolumn A egyeztetett oszlopot átnevezheti egy kemény kóddal rendelkező sztringre, például "üzleti kulcsra", és explicit módon hivatkozhat rá. Ebben a példában az illeszkedési feltétel name == $mycolumn, a névfeltétel pedig "üzleti kulcs".
Automatikus leképezés
Kijelölési átalakítás hozzáadásakor az automatikus leképezési csúszka váltásával engedélyezhető az automatikus leképezés. Az automatikus leképezéssel a kiválasztási átalakítás az összes bejövő oszlopot leképezi, az ismétlődések kivételével, ugyanazzal a névvel, mint a bemenetük. Ez magában foglalja az elsodródott oszlopokat, ami azt jelenti, hogy a kimeneti adatok olyan oszlopokat tartalmazhatnak, amelyek nincsenek definiálva a sémában. A sodródott oszlopokról további információt a sémaeltolódás című témakörben talál.
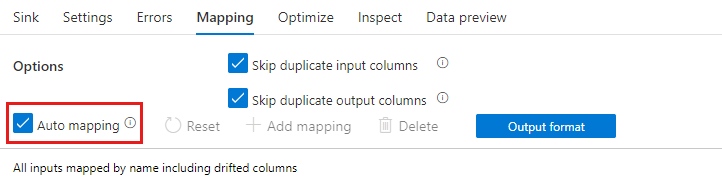
Ha az automatikus leképezés be van kapcsolva, a kijelölési átalakítás tiszteletben tartja az ismétlődő beállítások kihagyását, és új aliast ad a meglévő oszlopokhoz. Az aliasolás akkor hasznos, ha több illesztést vagy keresést végez ugyanazon a streamen és öncsatlakozási forgatókönyvekben.
Duplikált oszlopok
Alapértelmezés szerint a kiválasztási átalakítás duplikált oszlopokat vet ki a bemeneti és kimeneti vetületben is. Az ismétlődő bemeneti oszlopok gyakran illesztési és keresési átalakításokból származnak, ahol az oszlopnevek duplikálva vannak az illesztés mindkét oldalán. Ismétlődő kimeneti oszlopok akkor fordulhatnak elő, ha két különböző bemeneti oszlopot képez le ugyanarra a névre. A jelölőnégyzet bejelölésével kiválaszthatja, hogy az ismétlődő oszlopokat elveti vagy megtartja.
Oszlopok sorrendje
A leképezések sorrendje határozza meg a kimeneti oszlopok sorrendjét. Ha egy bemeneti oszlopot többször is leképeznek, csak az első megfeleltetés lesz betartva. Az ismétlődő oszlopok elvetése esetén az első egyezés megmarad.
Adatfolyamszkript
Szintaxis
<incomingStream>
select(mapColumn(
each(<hierarchicalColumn>, match(<matchCondition>), <nameCondition> = $$), ## hierarchical rule-based matching
<fixedColumn>, ## fixed mapping, no rename
<renamedFixedColumn> = <fixedColumn>, ## fixed mapping, rename
each(match(<matchCondition>), <nameCondition> = $$), ## rule-based mapping
each(patternMatch(<regexMatching>), <nameCondition> = $$) ## regex mapping
),
skipDuplicateMapInputs: { true | false },
skipDuplicateMapOutputs: { true | false }) ~> <selectTransformationName>
Example
Az alábbiakban egy select mapping és annak adatfolyam-szkriptje látható:
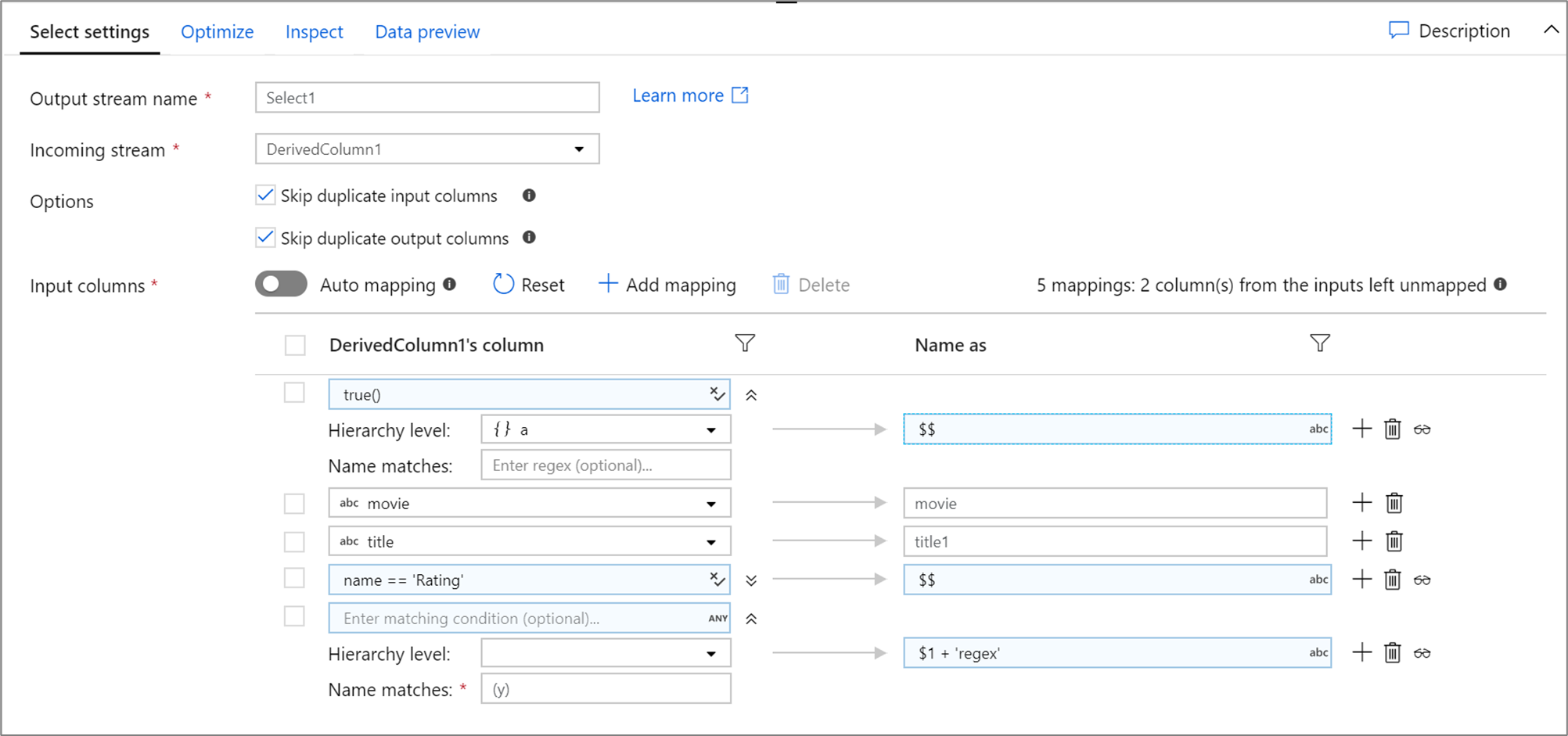
DerivedColumn1 select(mapColumn(
each(a, match(true())),
movie,
title1 = title,
each(match(name == 'Rating')),
each(patternMatch(`(y)`),
$1 + 'regex' = $$)
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> Select1
Kapcsolódó tartalom
- Miután a Kiválasztás funkcióval átnevezte, átrendezte és aliasokat adott az oszlopoknak, a Süllyesztési átalakítással adattárba helyezheti az adatokat.