Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik: Azure Logic Apps (Felhasználás + Standard)
Előfordulhat, hogy a tartalmat tokenekké kell alakítania, amelyek szavak vagy karakterdarabok, vagy egy nagy dokumentumot kisebb darabokra kell osztania, mielőtt a tartalmat konkrét műveletekkel használhatja. A Azure AI Keresés vagy Azure OpenAI műveletek például jogkivonatos bemenetre számítanak, és csak korlátozott számú jogkivonatot képesek kezelni.
Ezekben a forgatókönyvekben használja a dokumentum és az adattömb szövegének elemzése a logikai alkalmazás munkafolyamatában nevű adatműveletiműveleteket. Ezek a műveletek a tartalmat, például PDF-dokumentumot, CSV-fájlt, Excel fájlt stb. jogkivonatos sztringkimenetté alakítják, majd a jogkivonatok száma alapján darabra osztják a sztringet. Ezután hivatkozhat ezekre a kimenetekre a munkafolyamat későbbi műveleteivel.
Tipp
További információért tegye fel Azure Copilot ezeket a kérdéseket:
- Mi az a token az MI-ben?
- Mi az a tokenizált bemenet?
- Mi az a tokenizált sztringkimenet?
- Mi az elemzés az AI-ben?
- Mi az a darabolás az AI-ben?
A Azure Copilot kereséséhez a Azure portálon eszköztáron válassza a Copilot lehetőséget.
Ez az útmutató bemutatja, hogyan adhat hozzá és állíthat be műveleteket a dokumentumok elemzéséhez és a szövegrészek munkafolyamatban való formázásához.
Ismert problémák és korlátozások
A Használat munkafolyamatokban a Dokumentumelemzés művelet csak a következő Azure régiókban érhető el:
- Ausztrália keleti régiója
- Dél-Brazília
- Kelet-Ázsia
- USA keleti régiója
- USA 2. keleti régiója
- Észak-Európa
- USA déli középső régiója
- Délkelet-Ázsia
- Közép-Svédország
- USA 2. nyugati régiója
- USA 3. nyugati régiója
- Egyesült Királyság déli régiója
Ezek a régiók adatforrás-kapcsolatokat, dokumentumkövetést, dokumentumtömböket, Azure OpenAI-beágyazási modellek támogatását, valamint beépített indexelési támogatást biztosítanak az adatok lekéréséhez. További információért lásd: Az indexelés automatizálása az AI-keresésben az Azure Logic Apps munkafolyamatok segítségével.
A dokumentum elemzés és szövegrészlet műveletek jelenleg nem támogatják a gazdagépfájlokat, például a nagygépes és középkategóriás bináris fájlokat, mint amilyenek a Virtual Storage Access Method (VSAM) fájlok. Ha azonban standard munkafolyamatokkal dolgozik, használhatja az IBM Gazdagépfájl beépített műveletet, amelynek neve Gazdagépfájl tartalmának elemzése.
Előfeltételek
Egy Azure fiók és előfizetés. Ha nem rendelkezik Azure-előfizetéssel, hozzárendelhet egy ingyenes Azure-fiókot.
Egy használatalapú vagy standard logikai alkalmazás munkafolyamata egy létező eseményindítóval, mivel a dokumentum elemzése és a szöveg darabolása műveletek csak műveletekként érhetők el. Győződjön meg arról, hogy az elemezni vagy adattömbbe beolvasni kívánt tartalmat lekérő művelet megelőzi ezeket az adatműveleteket.
Dokumentum elemzése
A Dokumentum elemzése művelet tartalmat, például PDF-dokumentumot, CSV-fájlt, Excel-fájlt stb. tokenizált sztringgé alakít. Ebben a példában tegyük fel, hogy a munkafolyamat a HTTP-kérés fogadásakor elnevezett Kérelem eseményindítóval kezdődik. Ez az eseményindító egy másik összetevőtől, például egy Azure függvénytől, egy másik logikai alkalmazás munkafolyamatától stb. küldött HTTP-kérésre vár. A HTTP-kérés tartalmazza egy új feltöltött dokumentum URL-címét, amely elérhető a munkafolyamat lekéréséhez és elemzéséhez. A HTTP-műveletek azonnal követik az eseményindítót, és HTTP-kérést küldenek a dokumentum URL-címére, és a dokumentum tartalmával együtt visszatérnek a tárhelyéről.
Ha más tartalomforrásokat, például Azure Blob Storage, SharePoint, OneDrive, fájlrendszert, FTP-t stb. használ, ellenőrizheti, hogy elérhetők-e triggerek ezekhez a forrásokhoz. Azt is ellenőrizheti, hogy elérhetők-e műveletek a források tartalmának lekéréséhez. További információ: Beépített műveletek és felügyelt összekötők.
A Azure portálon nyissa meg a logikai alkalmazás erőforrását és munkafolyamatát a tervezőben.
A meglévő eseményindító és műveletek alatt kövesse az alábbi általános lépéseket a dokumentum elemzése nevű adatműveleti művelet munkafolyamathoz való hozzáadásához.
A tervezőn válassza a Dokumentum elemzése műveletet.
A műveletinformációs ablaktábla megnyitása után a Paraméterek lap Dokumentumtartalom tulajdonságában adja meg az elemezni kívánt tartalmat az alábbi lépések végrehajtásával:
Jelölje be a Dokumentumtartalom mezőben.
Megjelennek a dinamikus tartalomlista (villám ikon) és a kifejezésszerkesztő (függvényikon) beállításai.
Az előző művelet kimenetének kiválasztásához válassza ki a dinamikus tartalomlistát.
Ha egy előző művelet kimenetét módosító kifejezést szeretne létrehozni, jelölje ki a kifejezésszerkesztőt.
Ez a példa a dinamikus tartalomlista villámikonjának kiválasztásával folytatódik.
A dinamikus tartalomlista megnyitása után válassza ki a kívánt kimenetet egy előző műveletből.
Ebben a példában a dokumentumelemzési művelet a HTTP-művelet Törzs kimenetére hivatkozik.
A Törzskimenet ekkor megjelenik a Dokumentumtartalom mezőben:
A dokumentumelemzési művelet alatt adja hozzá a tokenizált sztringkimenettel használni kívánt műveleteket, például az adattömb szövegét, amelyet az útmutató később ismertet.
Dokumentum elemzése – Hivatkozás
Paraméterek
| Név | Érték | Adattípus | Leírás | Korlát |
|---|---|---|---|---|
| Dokumentum tartalma | < feldolgozandó tartalom> | Bármely | Az elemezni kívánt tartalom. | Egyik sem |
Kimenetek
| Név | Adattípus | Leírás |
|---|---|---|
| A találat szövegének elemzése | Sztringtömb | Sztringek tömbje. |
| Elemezett eredmény | Objektum | Egy objektum, amely a teljes elemezt szöveget tartalmazza. |
Adattömb szövege
Az Adattömb szöveges művelet kisebb részekre osztja a tartalmat, hogy a későbbi műveletek könnyebben használhatók legyenek az aktuális munkafolyamatban. A következő lépések a Parse a document szakasz példájára épülnek, és felosztják a tokenek sztring kimenetét az Azure AI műveletekhez, amelyek tokenizált, kisebb méretű tartalom egységeket várnak.
Megjegyzés
Az adatrészletezést használó előző műveletek nem befolyásolják a részletező szöveg műveletét, és a részletező szövegművelet sem befolyásolja a részletezést használó későbbi műveleteket.
A Azure portálon nyissa meg a logikai alkalmazás erőforrását és munkafolyamatát a tervezőben.
A dokumentum elemzése művelet keretében kövesse az alábbi általános lépéseket az Adatkezelési művelet, neve Szövegegység, hozzáadásához.
A tervezőn válassza a Chunk szöveg tevékenységet.
Miután megnyílik a műveletinformációs ablaktábla, a Paraméterek lapon, az Adattömb-stratégia tulajdonságnál válassza a TokenSize elemet az adattömbelési módszerként, ha még nincs kijelölve.
Stratégia Leírás TokenSize A megadott tartalom felosztása a tokenek száma alapján. A stratégia kiválasztása után válassza ki a Szöveg mezőben a tartalmat az adattömbökre bontás specifikálásához.
Megjelennek a dinamikus tartalomlista (villám ikon) és a kifejezésszerkesztő (függvényikon) beállításai.
Az előző művelet kimenetének kiválasztásához válassza ki a dinamikus tartalomlistát.
Ha egy előző művelet kimenetét módosító kifejezést szeretne létrehozni, jelölje ki a kifejezésszerkesztőt.
Ez a példa a dinamikus tartalomlista villámikonjának kiválasztásával folytatódik.
A dinamikus tartalomlista megnyitása után válassza ki a kívánt kimenetet egy előző műveletből.
Ebben a példában az Adattömb szövegművelet a dokumentumelemzési műveletből származó elemzési eredmény szövegkimenetére hivatkozik.
A Szöveg mezőben most az Elemzés eredményművelet kimenete látható:
A kiválasztott stratégia és forgatókönyv alapján végezze el az Adattömb szövegművelet beállítását. További információ: Adattömbszöveg – Hivatkozás.
Most, ha más olyan műveleteket ad hozzá, amelyek jogkivonatos bemenetet várnak és használnak, például a Azure AI-műveleteket, a bemeneti tartalom a könnyebb használat érdekében lesz formázva.
Adattömb szövege – Hivatkozás
Paraméterek
| Név | Érték | Adattípus | Leírás | Korlátok |
|---|---|---|---|---|
| Darabolási Stratégia | TokenSize | Sztring típusú felsorolás | Ossza fel a tartalmat a tokenek száma alapján. Alapértelmezett: TokenSize |
Nem alkalmazható |
| Szöveg | < content-to-chunk> | Bármely | Az adattömbbe beszedendő tartalom. | Lásd: Korlátok és konfigurációs referencia-útmutató |
| EncodingModel | < kódolási módszer> | Sztring típusú felsorolás | A használni kívánt kódolási modell: - Alapértelmezett: cl100k_base (gpt4, gpt-3.5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) További információ: OpenAI – Modellek áttekintése. |
Nem alkalmazható |
| TokenSize | < max-tokens-per-chunk> | Egész szám | A tokenek maximális száma tartalmi egységenként. Alapértelmezett: Nincs |
Minimum: 1 Maximum: 8000 |
| PageOverlapLength | < egymást átfedő karakterek száma> | Egész szám | Az előző adattömb végéből a következő adattömbbe belefoglalandó karakterek száma. Ezzel a beállítással elkerülheti a fontos információk elvesztését, ha a tartalmat adattömbökre osztja, és megőrzi a folytonosságot és a kontextust az adattömbök között. Alapértelmezett: 0 – Nincsenek átfedésben lévő karakterek. |
Minimum: 0 |
Tipp
További információért tegye fel Azure Copilot ezeket a kérdéseket:
- Mi a PageOverlapLength az adattömbben?
- Mi a kódolás az Azure MI-ben?
A Azure Copilot kereséséhez a Azure portálon eszköztáron válassza a Copilot lehetőséget.
Kimenetek
| Név | Adattípus | Leírás |
|---|---|---|
| Darabolt eredmény szöveges elemei | Sztringtömb | Sztringek tömbje. |
| Darabolt eredmény szövegeleme | Sztring | Egyetlen karakterlánc a tömbben. |
| Darabolt eredmény | Objektum | Egy objektum, amely a teljes darabolt szöveget tartalmazza. |
Példa munkafolyamat
Az alábbi példa más műveleteket is tartalmaz, amelyek teljes munkafolyamat-mintát hoznak létre az adatok bármely forrásból való betöltéséhez:
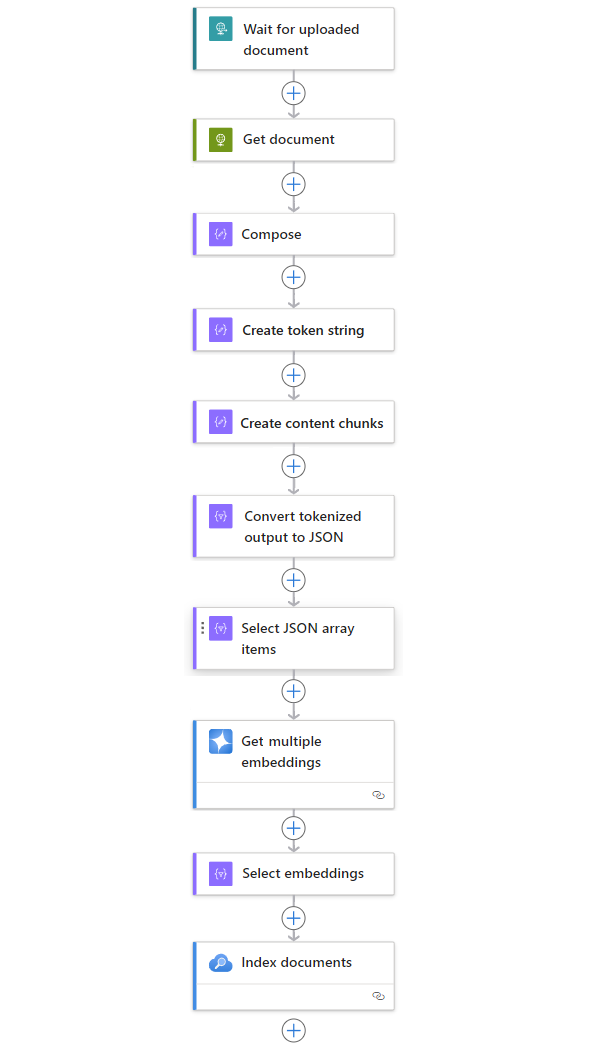
| Lépés | Feladat | Mögöttes művelet | Leírás |
|---|---|---|---|
| 1 | Várjon vagy keressen új tartalmat. | HTTP-kérés fogadása | Egy eseményindító, amely vagy lekérdezi vagy megvárja az új adatok érkezését, akár ütemezett ismétlődés alapján, akár adott eseményekre reagálva. Ilyen esemény lehet egy új fájl, amely egy adott tárolórendszerbe van feltöltve, például Azure Blob Storage, SharePoint, OneDrive, fájlrendszer, FTP stb. Ebben a példában a Kérelem eseményindító művelet egy másik végpontról küldött HTTP- vagy HTTPS-kérésre vár. A kérelem tartalmazza egy új feltöltött dokumentum URL-címét. |
| 2 | A tartalom lekérése. | HTTP | EGY HTTP-művelet , amely lekéri a feltöltött dokumentumot a fájl URL-címével az eseményindító kimenetéből. |
| 3 | Dokumentumadatok írása. | Összeállítás | Adatműveleti művelet, amely összefűzi a különböző elemeket. Ez a példa összefűzi a dokumentum kulcs-érték adatait. |
| 4 | Token-sztring létrehozása. | Dokumentum elemzése | A Adatműveletek művelet, amely a Compose művelet kimenetéből tokenizált sztringet hoz létre. |
| 5 | Tartalomtömbök létrehozása. | Adattömb szövege | Adatműveleti művelet, amely a jogkivonat-sztringet darabokra osztja a tartalomtömbönkénti jogkivonatok száma alapján. |
| 6 | Konvertálja a tokenizált és darabolt szöveget JSON formátumba. | JSON elemzése | Adatműveleti művelet, amely az adattömb kimenetét JSON-tömbté alakítja. |
| 7 | Válassza ki a JSON-tömbelemeket. | Kiválasztás | Adatműveleti művelet, amely több elemet választ ki a JSON-tömbből. |
| 8 | Hozza létre a beágyazásokat. | Több beágyazások lekérése | Egy Azure OpenAI művelet, amely beágyazást hoz létre az egyes JSON-tömbelemekhez. |
| 9 | Válassza ki a beágyazásokat és egyéb információkat. | Kiválasztás | Adatműveleti művelet, amely a beágyazásokat és más dokumentumadatokat választja ki. |
| 10 | Indexelje az adatokat. | Dokumentumok indexelése | Egy Azure AI Keresés művelet, amely az egyes kijelölt beágyazások alapján indexeli az adatokat. |