Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Tip
Microsoft Fabric Data Warehouse egy nagyvállalati szintű relációs raktár egy Data Lake-alaprendszeren, jövőre kész architektúrával, beépített AI-vel és új funkciókkal. Ha még nem ismerkedik adattárházzal, kezdje a Fabric Data Warehouse. A meglévő dedikált SQL-készlet számítási feladatai frissíthetők Fabric az adatelemzés, a valós idejű elemzés és a jelentéskészítés új képességeinek eléréséhez.
Ez az oktatóanyag az Azure Machine Learning Designer használatával készít egy prediktív gépi tanulási modellt. A modell az Azure Synapse-ban tárolt adatokon alapul. Az oktatóanyag forgatókönyve annak előrejelzése, hogy az ügyfél valószínűleg vásárol-e kerékpárt, vagy nem így az Adventure Works, a kerékpárbolt, célzott marketingkampányt hozhat létre.
Előfeltételek
Az oktatóanyag teljesítéséhez a következőkre lesz szüksége:
- az AdventureWorksDW-mintaadatokkal előre betöltött SQL-készlet. Az SQL-készlet kiépítéséhez tekintse meg az SQL-készlet létrehozását és a mintaadatok betöltését. Ha már rendelkezik adattárházzal, de nem rendelkezik mintaadatokkal, manuálisan is betöltheti a mintaadatokat.
- Egy Azure Machine Learning-munkaterület. Ezt az oktatóanyagot követve hozzon létre egy újat.
Az adatok lekérése
A használt adatok az AdventureWorksDW dbo.vTargetMail nézetében vannak. A Datastore ebben az oktatóanyagban való használatához a program először exportálja az adatokat az Azure Data Lake Storage-fiókba, mivel az Azure Synapse jelenleg nem támogatja az adathalmazokat. Az Azure Data Factory az adatraktárból az Azure Data Lake Storage-ba történő adatexportálására használható a másolási tevékenység használatával. Importáláshoz használja a következő lekérdezést:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Miután az adatok elérhetővé válnak az Azure Data Lake Storage-ban, az Azure Machine Learning adattárai az Azure Storage-szolgáltatásokhoz való csatlakozásra szolgálnak. Az alábbi lépéseket követve hozzon létre egy adattárat és egy megfelelő adatkészletet:
Indítsa el az Azure Machine Learning Studiót az Azure Portalon, vagy jelentkezzen be az Azure Machine Learning Studióban.
Kattintson a Bal oldali panelEn lévő Adattárak elemre a Kezelés szakaszban, majd kattintson az Új adattár elemre.
Adja meg az adattár nevét, válassza ki az "Azure Blob Storage" típust, adja meg a helyet és a hitelesítő adatokat. Ezt követően kattintson a Create (Létrehozás) gombra.
Ezután kattintson az Adathalmazok elemre a bal oldali panelEn az Eszközök szakaszban. Válassza az Adathalmaz létrehozása lehetőséget a Adattárolóból.
Adja meg az adathalmaz nevét, és válassza ki a táblázatos típust. Ezután a Tovább gombra kattintva továbbléphet.
Az Adattár kiválasztása vagy létrehozása szakaszban válassza a Korábban létrehozott adattár lehetőséget. Válassza ki a korábban létrehozott adattárat. Kattintson a Tovább gombra, és adja meg az elérési utat és a fájlbeállításokat. Ügyeljen arra, hogy oszlopfejlécet adjon meg, ha a fájlok tartalmaznak egyet.
Végül kattintson a Létrehozás gombra az adathalmaz létrehozásához.
Tervezői kísérlet konfigurálása
Következő lépésként kövesse az alábbi lépéseket a tervezők konfigurálásának érdekében:
Kattintson a Tervező fülre a Szerző szakasz bal oldali ablaktábláján.
Új folyamat létrehozásához válassza az könnyen használható előre összeállított összetevőket .
A jobb oldali beállítások panelen adja meg a folyamatlánc nevét.
Emellett válasszon ki a teljes kísérlethez egy cél számítási fürtöt a korábban kiépített fürtök közül a Beállítások gomb segítségével. Zárja be a Beállítások panelt.
Adatok importálása
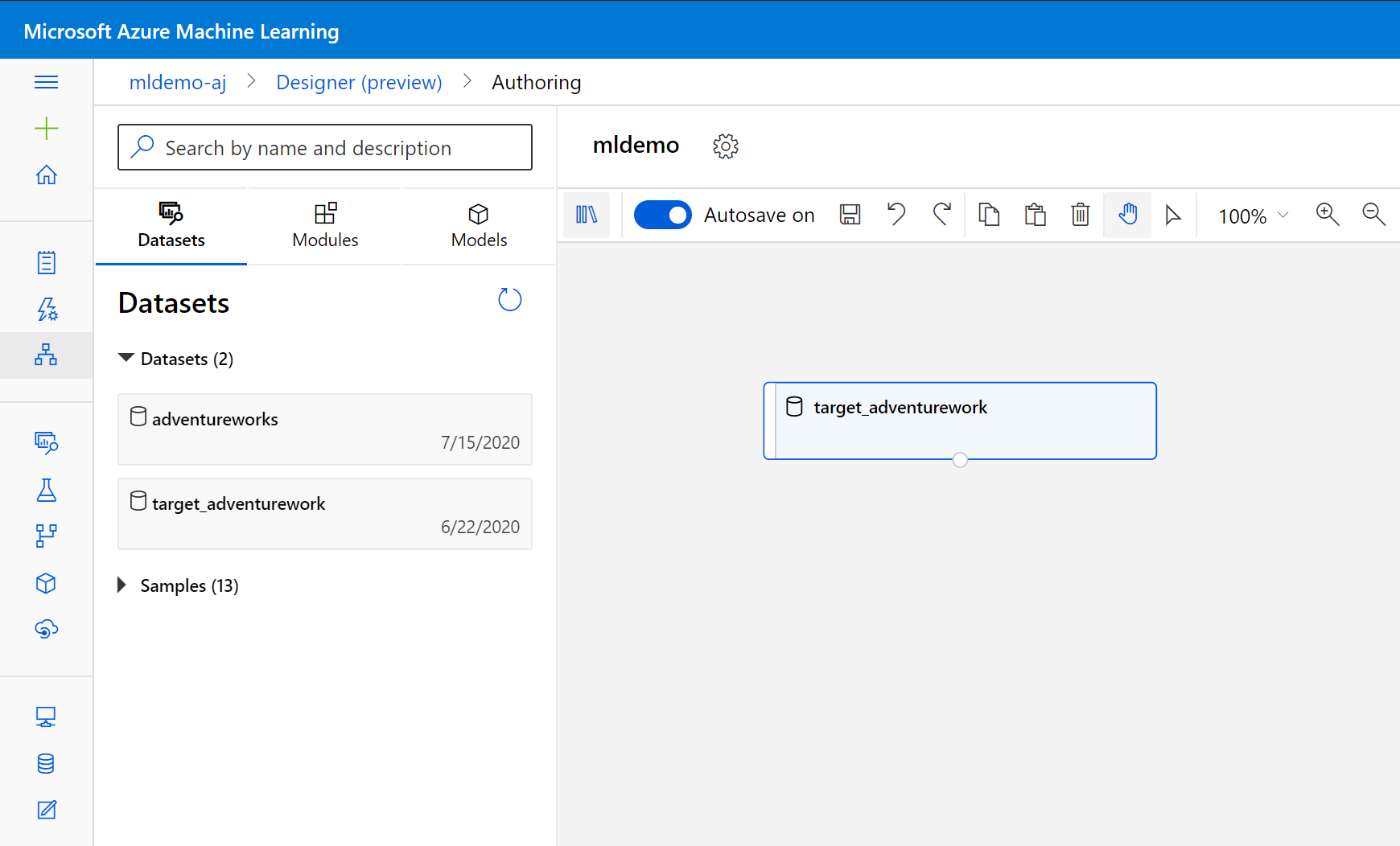
A keresőmező alatti bal oldali panelen válassza ki az Adathalmazok részösszeget.
Húzza a korábban létrehozott adathalmazt a vászonra.
Az adatok megtisztítása
Az adatok tisztításához távolítsa el azokat az oszlopokat, amelyek nem relevánsak a modell számára. Kövesse az alábbi lépéseket:
Válassza ki az Összetevők altáblát a bal oldali panelen.
Húzza a vászonra az Oszlopok kiválasztása az adathalmazban komponenst az < csoportból. Csatlakoztassa ezt az összetevőt az Adathalmaz összetevőhöz.
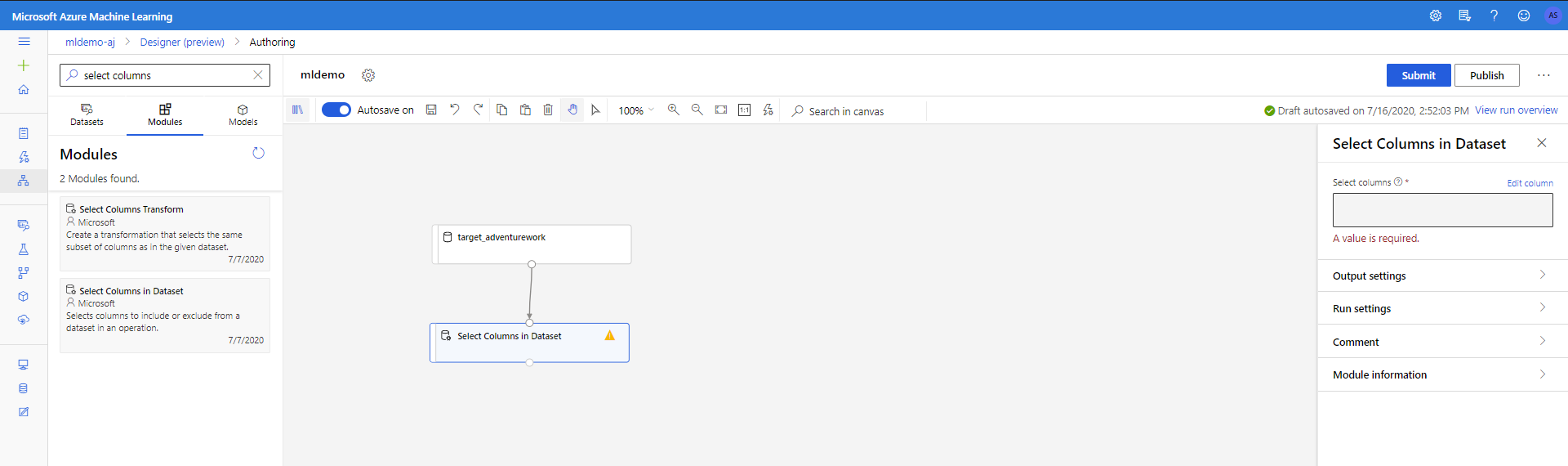
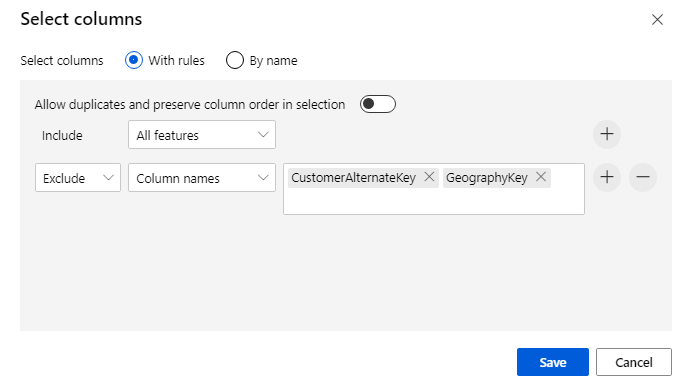
Kattintson az összetevőre a Tulajdonságok panel megnyitásához. Kattintson a Szerkesztés oszlopra annak megadásához, hogy mely oszlopokat szeretné elvetni.
Két oszlop kizárása: CustomerAlternateKey és GeographyKey. Kattintson a Mentés

A modell létrehozása
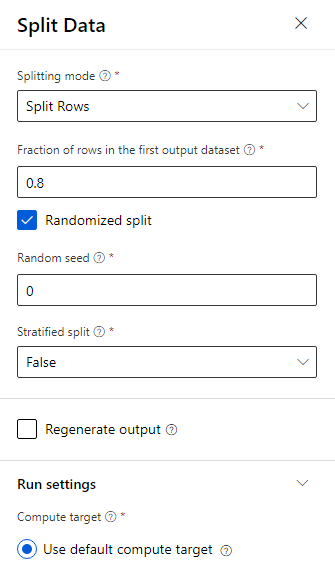
Az adatok felosztása 80–20: 80% a gépi tanulási modellek betanításához, 20%a pedig a modell teszteléséhez. Ebben a bináris besorolási problémában "kétosztályos" algoritmusokat használunk.
Húzza a Megosztott Adat összetevőt a vászonba.
A tulajdonságok panelen adja meg a 0,8 értéket az első kimeneti adathalmaz sorainak törtrészéhez.
Húzza a kétosztályos emelt szintű döntési fa összetevőt a vászonra.
Húzza a Modell Betanítása komponenst a vászonra. Adja meg a bemeneteket úgy, hogy csatlakoztatja azokat a Kétosztályos Kiemelt Döntési Fa (ML-algoritmus) és a Adatok Felosztása (az algoritmus betanításához szükséges adatok) összetevőkhöz.
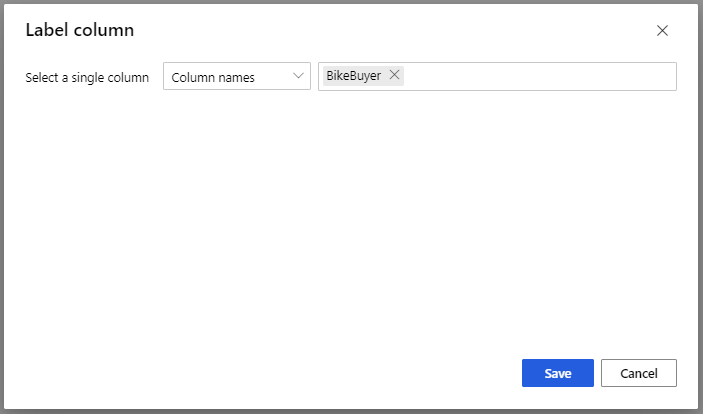
A Train Model modell esetén a Tulajdonságok panel Címke oszlopában válassza az Oszlop szerkesztése lehetőséget. Jelölje ki a \BikeBuyer\ oszlopot előrejelzendő oszlopként, és válassza a \Mentés\ lehetőséget.
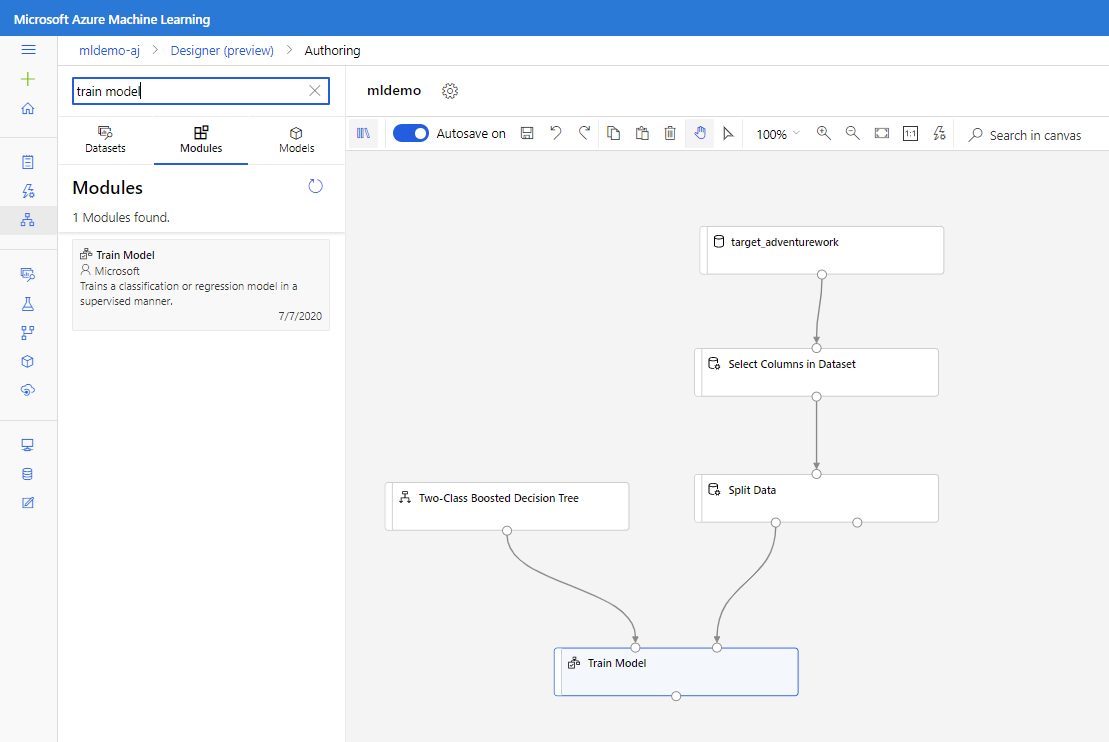
A modell pontozása
Most tesztelje, hogyan működik a modell a tesztadatokon. Két különböző algoritmust hasonlítunk össze, hogy kiderüljön, melyik teljesít jobban. Kövesse az alábbi lépéseket:
Húzza a Score Model komponenst a vászonra, és csatlakoztassa a Train Model és Split Data komponensekhez.
Húzza a kétosztályos Bayes Averaged Perceptront a kísérleti vászonra. Összehasonlíthatja, hogy ez az algoritmus hogyan teljesít a kétosztályos emelt szintű döntési fával összehasonlítva.
Másolja és illessze be a Modell betanítása és Modell pontozása összetevőt a vászonra.
Húzza a Modell kiértékelése összetevőt a vászonra a két algoritmus összehasonlításához.
Kattintson a Küldés gombra a folyamatfuttatás beállításához.
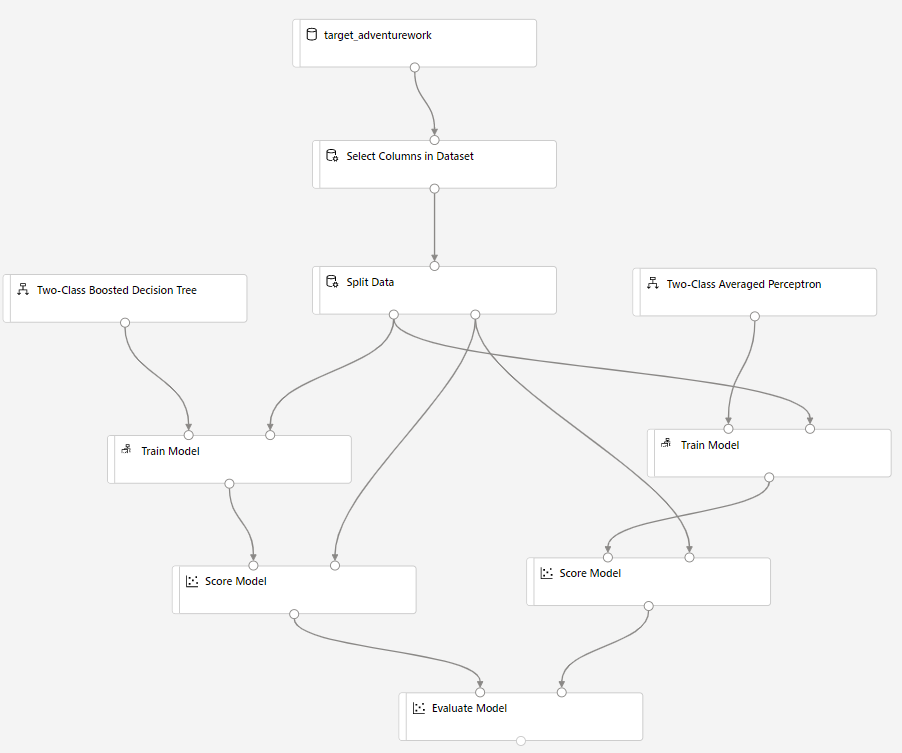
Miután a futtatás befejeződött, kattintson a jobb gombbal a Modell kiértékelése összetevőre, és kattintson a Kiértékelési eredmények megjelenítése parancsra.
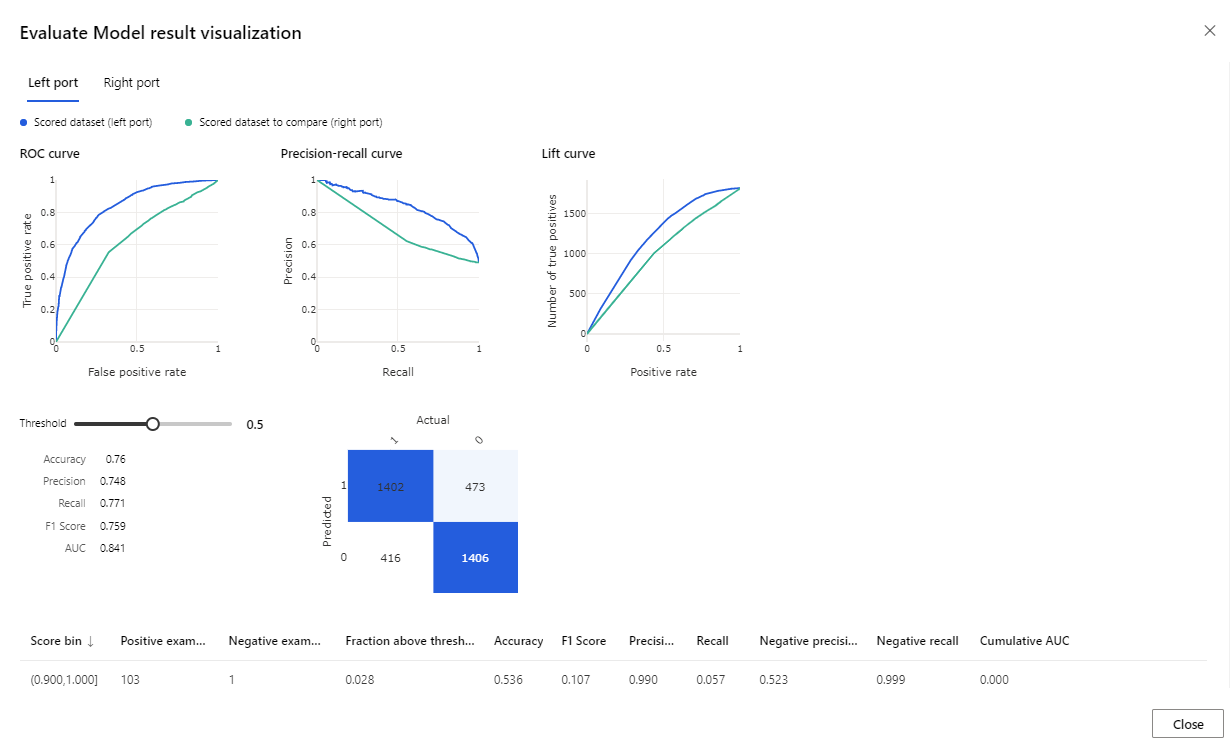

A megadott metrikák a ROC-görbe, a pontosságvisszahívási diagram és az emelési görbe. Ezeket a metrikákat megvizsgálva láthatja, hogy az első modell jobban teljesített, mint a második. Az első modell előrejelzésének megtekintéséhez kattintson a jobb gombbal a Score Model összetevőre, és kattintson a Pontozott adatkészlet megjelenítése elemre az előrejelzett eredmények megtekintéséhez.
A tesztadatkészlethez további két oszlop lesz hozzáadva.
- Pontozott valószínűség: annak valószínűsége, hogy az ügyfél kerékpárvásárló.
- Értékelt címkék: a modell által végzett osztályozás – kerékpárvásárló (1) vagy nem (0). A címkézés valószínűségi küszöbértéke 50 százalékra van beállítva és módosítható.
Hasonlítsa össze a BikeBuyer oszlopot (tényleges) az értékelt címkékkel (előrejelzés), a modell teljesítményének értékeléséhez. Ezután ezzel a modellel előrejelzéseket készíthet az új ügyfelek számára. Ezt a modellt közzéteheti webszolgáltatásként, vagy visszaírhatja az eredményeket az Azure Synapse-ba.
Következő lépések
Az Azure Machine Learningről az Azure Machine Learning bemutatása című témakörben olvashat bővebben.
Itt megismerheti az adattárházban található beépített pontozást.