Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Az SQL Server-adatbázismotor egy példányából származó I/O logikai és fizikai olvasásokat tartalmaz. A logikai olvasás minden alkalommal megtörténik, amikor az adatbázismotor kér egy lapot a puffergyorsítótárból, más néven pufferkészletből. Ha a lap jelenleg nincs a puffergyorsítótárban, a fizikai olvasás először a lemezről a gyorsítótárba másolja a lapot.
Az adatbázismotor egy példánya által generált olvasási kérelmeket a relációs motor vezérli, és a tárolómotor optimalizálja. A relációs motor határozza meg a leghatékonyabb hozzáférési módszert (például táblavizsgálatot, indexvizsgálatot vagy kulcsos olvasást). A tárolómotor hozzáférési módszerei és pufferkezelő összetevői határozzák meg a végrehajtandó olvasások általános mintáját, és optimalizálják a hozzáférési módszer implementálásához szükséges olvasásokat. A köteget végrehajtó szál ütemezi az olvasásokat.
Read-ahead
Az adatbázismotor támogatja az előtöltésnek nevezett teljesítményoptimalizálási mechanizmust. Az előreolvasás előre jelzi a lekérdezés-végrehajtási terv teljesítéséhez szükséges adatokat és indexlapokat, és a lapokat a puffergyorsítótárba helyezi, mielőtt a lekérdezés felhasználja őket. Ez a folyamat lehetővé teszi a számítások és az I/O átfedését, kihasználva a processzor és a lemez előnyeit.
Az előreolvasási mechanizmus lehetővé teszi, hogy az adatbázismotor legfeljebb 64 összefüggő oldalt (512 KB) olvasson be egy fájlból. Az olvasás egyetlen scatter-gather olvasásként történik a puffertár megfelelő számú (valószínűleg nem összefüggő) pufferébe. Ha a tartomány bármelyik lapja már megtalálható a puffergyorsítótárban, az olvasás befejeztével a rendszer elveti az olvasás megfelelő lapját. Az oldaltartomány bármelyik végéről „levágható”, ha a megfelelő oldalak már megtalálhatók a gyorsítótárban.
Kétféle előolvasás létezik: az egyik adatoldalakhoz, a másik az indexlapokhoz.
Adatoldalak olvasása
Az adatbázismotor által az adatoldalak olvasására használt táblázatvizsgálatok hatékonyak. Az SQL Server-adatbázis indexfoglalási térképének (IAM) oldalai felsorolják a tábla vagy index által használt mértékeket. A tárolómotor beolvassa az IAM-et az olvasandó lemezcímek rendezett listájának létrehozásához. Ez lehetővé teszi, hogy a tárolómotor az I/OS-jét nagy szekvenciális olvasásokként optimalizálja, amelyeket egymás után hajtanak végre a lemezen elfoglalt helyük alapján. Az IAM-oldalakról további információt az objektumok által használt terület kezelése című témakörben talál.
Indexlapok olvasása
A tárolómotor az indexoldalakat kulcssorrendben olvassa be. Ez az ábra például egy olyan levéloldalkészlet egyszerűsített ábrázolását mutatja be, amely kulcskészletet és a levéloldalakat megfeleltető köztes indexcsomópontot tartalmaz. Az indexek lapjainak szerkezetéről további információt a fürtözött és nem fürtözött indexek témakörben talál.
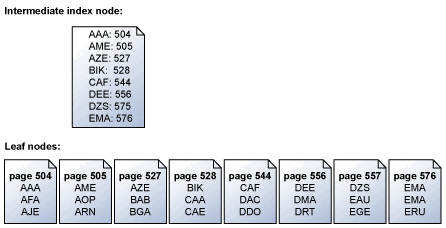
A tárolómotor a levélszint feletti köztes indexlap információit használja a kulcsokat tartalmazó lapok soros előreolvasásának programozására. Ha kérés érkezik minden kulcsra ABC-tól DEF-ig, a tárolómotor először beolvassa az indexoldalt a levéloldal felett. Azonban nem csak az 504. oldaltól az 556. oldalig (a megadott tartomány kulcsait tartalmazó utolsó lapig) olvassa be az egyes adatoldalokat egymás után. Ehelyett a tárolómotor megvizsgálja a köztes indexoldalt, és összeállítja azoknak a levéloldalaknak a listáját, amelyeket el kell olvasni. A tárolómotor ezután az összes olvasást kulcsrendbe rendezi. A tárolómotor azt is felismeri, hogy az 504/505 és az 527/528 oldal egybefüggő, és egyetlen pontolvasást hajt végre a szomszédos lapok egyetlen műveletben való lekéréséhez. Ha egy soros műveletben sok lapot kell lekérni, a tárolómotor egyszerre több olvasási blokkot ütemez. Ha az olvasások egy részhalmaza befejeződött, a tárolómotor az összes szükséges olvasás ütemezéséig egyenlő számú új olvasást ütemez.
A tárolómotor előre beírással gyorsítja az alaptáblák keresését a nemclustered indexekből. A nemclustered index levélsorai az egyes kulcsértékeket tartalmazó adatsorokra mutató mutatókat tartalmaznak. Ahogy a tárolómotor végigolvassa a nem klaszterezett index levéloldalait, elkezd aszinkron olvasásokat ütemezni azokhoz az adatsorokhoz, amelyek mutatóit már lekérte. Ez lehetővé teszi, hogy a tárolómotor lekérje az adatsorokat a mögöttes táblából, mielőtt befejezi a nemclustered index vizsgálatát. Az előletöltést attól függetlenül használják, hogy a tábla fürtözött indexet tartalmaz-e. Az SQL Server Enterprise kiadás több előkezelést használ, mint az SQL Server más kiadásai, így több oldal olvasható előre. Az előkezelés szintje egyetlen kiadásban sem konfigurálható. A nem clusterelt indexekről további információt a fürtözött és nem clusterelt indexek címmel talál.
Fejlett szkennelés
Az SQL Server Enterprise kiadásban a speciális vizsgálat funkció lehetővé teszi, hogy több feladat teljes táblázatvizsgálatokat osztjon meg. Ha egy Transact-SQL utasítás végrehajtási terve megköveteli egy tábla adatoldalainak vizsgálatát, és az adatbázismotor azt észleli, hogy a tábla már be van vizsgálva egy másik végrehajtási tervben, az adatbázismotor a második vizsgálathoz csatlakozik az elsőhöz, a második vizsgálat aktuális helyén. Az adatbázismotor egyenként olvassa be az egyes lapokat, és az egyes lapok sorait mindkét végrehajtási tervnek átadja. Ez addig folytatódik, amíg el nem éri a táblázat végét.
Ezen a ponton az első végrehajtási terv egy vizsgálat teljes eredményével rendelkezik. A második végrehajtási tervnek azonban le kell kérnie az olvasott adatoldalakat, mielőtt csatlakozott volna a folyamatban lévő vizsgálathoz. A második végrehajtási terv vizsgálata ezután visszafut a táblázat első adatoldalára, és az első vizsgálathoz csatlakozott helyre irányítja a keresést. Tetszőleges számú vizsgálat kombinálható így. Az adatbázismotor folyamatosan végighalad az adatoldalakon, amíg el nem végzi az összes vizsgálatot. Ezt a mechanizmust "körkörös vizsgálatnak" is nevezik, és bemutatja, hogy a SELECT utasításból visszaadott eredmények sorrendje miért nem garantálható ORDER BY záradék nélkül.
Tegyük fel például, hogy van egy 500 000 oldalas táblázata.
UserA végrehajt egy Transact-SQL utasítást, amely megköveteli a tábla vizsgálatát. Ha a vizsgálat 100 000 oldalt feldolgozott, UserB végrehajt egy másik Transact-SQL utasítást, amely ugyanazt a táblát vizsgálja. Az adatbázismotor 100 001 után ütemezi a lapok olvasási kéréseinek egy készletét, és mindkét lap sorait visszaküldi mindkét vizsgálatnak. Amikor a vizsgálat eléri a 200 000. oldalt, UserC végrehajt egy másik Transact-SQL utasítást, amely ugyanazt a táblát vizsgálja. A 200 001.001. oldaltól kezdve az adatbázismotor átadja a sorokat minden egyes oldalról, amely visszaolvassa mind a három vizsgálatra. Miután beolvassa az 500 000. sort, a UserA vizsgálat befejeződött, és a UserB és UserC vizsgálatok újraindulnak, és elkezdik olvasni a lapokat az 1. oldaltól kezdve. Amikor az Adatbázis-motor eljut a 100 000. oldalra, a UserB vizsgálata befejeződik. A szkennelés UserC ezután önállóan folytatódik, amíg el nem éri a 200 000. oldalt. Ezen a ponton az összes vizsgálat befejeződött.
Speciális szkennelés nélkül minden felhasználónak versenyeznie kellene a pufferterületért, ami lemezmeghajtó fej versengést okozna. Ezután az egyes felhasználók ugyanazt a lapot olvassák, ahelyett, hogy egyszer olvasnák és több felhasználó osztanák meg őket, lelassítva a teljesítményt és az erőforrásokat.