Egyéni modellek: pontossági és megbízhatósági pontszámok
Ez a tartalom a következőre vonatkozik: ![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió) ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
Feljegyzés
- Az egyéni neurális modellek nem biztosítanak pontossági pontszámokat a betanítás során.
- A táblák, táblázatsorok és táblázatcellák megbízhatósági pontszámai a 2024-02-29-es előzetes verziójú API-verziótól kezdve érhetők el egyéni modellekhez.
Az egyéni sablonmodellek betanításakor becsült pontossági pontszámot hoznak létre. Az egyéni modell által elemzett dokumentumok a kinyert mezőkre vonatkozó megbízhatósági pontszámot állítanak elő. A megbízhatósági pontszám a valószínűséget jelzi a kinyert eredmény helyes észlelésének statisztikai bizonyossága mértékének mérésével. A becsült pontosság kiszámítása a betanítási adatok néhány különböző kombinációjának futtatásával történik a címkézett értékek előrejelzéséhez. Ebből a cikkből megtudhatja, hogyan értelmezheti a pontossági és megbízhatósági pontszámokat, valamint a pontszámok pontosságának és megbízhatósági eredményeinek javítása érdekében ajánlott eljárásokat.
Pontossági pontszámok
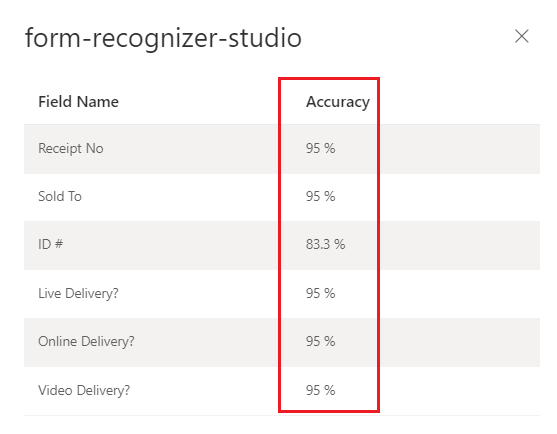
Egy (v3.0) vagy train (v2.1)-es egyéni modellművelet kimenete build tartalmazza a becsült pontossági pontszámot. Ez a pontszám azt jelzi, hogy a modell képes pontosan előrejelezni a címkézett értéket egy vizuálisan hasonló dokumentumban. A pontosságot 0% (alacsony) és 100% (magas) közötti százalékos értéktartományon belül mérik. A legjobb, ha 80%-os vagy magasabb pontszámot céloz meg. Érzékenyebb esetekben, például pénzügyi vagy orvosi nyilvántartások esetén 100%-os pontszámot ajánlunk. Emberi felülvizsgálatot is igényelhet.
Document Intelligence Studio
– Betanított egyéni modell (számla)
Megbízhatósági pontszámok
Feljegyzés
- A táblázat-, sor- és cellabizonyság-pontszámok mostantól a 2024-02-29-es verziójú API-verzió részét képezik.
- Az egyéni modellek táblázatcelláinak megbízhatósági pontszámai a 2024-02-29-es előzetes API-val kezdődően hozzáadva lesznek az API-hoz.
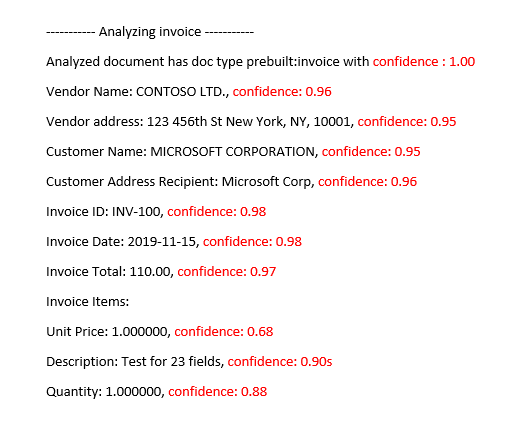
A dokumentumintelligencia-elemzés eredményei becsült megbízhatóságot adnak vissza az előrejelzett szavakhoz, kulcs-érték párokhoz, kijelölési jelekhez, régiókhoz és aláírásokhoz. Jelenleg nem minden dokumentummező ad vissza megbízhatósági pontszámot.
A mező megbízhatósága 0 és 1 közötti becsült valószínűséggel jelzi, hogy az előrejelzés helyes. A 0,95-ös megbízhatósági érték (95%) például azt jelzi, hogy az előrejelzés 20-ból 19-szer helyes. Olyan forgatókönyvek esetében, ahol a pontosság kritikus fontosságú, a megbízhatóság segítségével meghatározhatja, hogy automatikusan elfogadja-e az előrejelzést, vagy megjelöli-e azt emberi felülvizsgálatra.
Document Intelligence Studio
– Előre összeállított számlamodell elemzése
Megbízhatósági pontszámok javítása
Egy elemzési művelet után tekintse át a JSON-kimenetet. Vizsgálja meg a confidence csomópont alatti összes kulcs/érték eredmény értékeit pageResults . A csomópont megbízhatósági pontszámát readResults is meg kell vizsgálnia, amely megfelel a szövegolvasási műveletnek. Az olvasási eredmények megbízhatósága nem befolyásolja a kulcs-/érték kinyerési eredmények megbízhatóságát, ezért mindkettőt ellenőriznie kell. Íme néhány tipp:
Ha az
readResultsobjektum megbízhatósági pontszáma alacsony, javítsa a bemeneti dokumentumok minőségét.Ha az objektum megbízhatósági
pageResultspontszáma alacsony, győződjön meg arról, hogy az elemzett dokumentumok azonos típusúak.Fontolja meg az emberi felülvizsgálat beépítését a munkafolyamatokba.
Olyan űrlapokat használjon, amelyek különböző értékekkel rendelkeznek az egyes mezőkben.
Egyéni modellekhez használjon betanítási dokumentumok nagyobb készletét. A további dokumentumok címkézésével a modell nagyobb pontossággal ismeri fel a mezőket.
Egyéni modellek pontossági és megbízhatósági pontszámainak értelmezése
Az egyéni modell megbízhatósági pontszámának értelmezésekor figyelembe kell vennie a modellből visszaadott összes megbízhatósági pontszámot. Kezdjük az összes megbízhatósági pontszám listájával.
- Dokumentumtípus megbízhatósági pontszáma: A dokumentumtípus megbízhatósága azt jelzi, hogy az elemzett dokumentum hasonlít a betanítási adathalmaz dokumentumaihoz. Ha a dokumentumtípus megbízhatósága alacsony, az az elemzett dokumentum sablon- vagy szerkezeti eltéréseit jelzi. A dokumentumtípus megbízhatóságának javítása érdekében címkézzen fel egy dokumentumot az adott változattal, és adja hozzá a betanítási adatkészlethez. A modell újratanítása után jobban fel kell szerelni az adott változatosztály kezelésére.
- Mezőszintű megbízhatóság: Minden kinyert címkézett mezőhöz társított megbízhatósági pontszám tartozik. Ez a pontszám tükrözi a modell megbízhatóságát a kinyert érték pozíciójával kapcsolatban. A megbízhatósági pontszámok kiértékelése során meg kell vizsgálnia az alapul szolgáló kinyerési megbízhatóságot is, hogy átfogó megbízhatóságot hozzon létre a kinyert eredményhez. A mező típusától függően kiértékelheti a
OCRszöveg kinyerési vagy kijelölési jelek eredményeit, hogy összetett megbízhatósági pontszámot hozzon létre a mezőhöz. - A word megbízhatósági pontszáma A dokumentumban kinyert összes szóhoz társított megbízhatósági pontszám tartozik. A pontszám az átírás megbízhatóságát jelöli. Az oldalak tömbje szavakból álló tömböt tartalmaz, és minden szóhoz tartozik egy span és megbízhatósági pontszám. A kinyert egyéni mező értékei megegyeznek a kinyert szavak spanjaival.
- Kijelölési jelek megbízhatósági pontszáma: Az oldalak tömbje is tartalmaz kijelölési jeleket tartalmazó tömböt. Minden kijelölési jel rendelkezik egy megbízhatósági pontszámmal, amely a kijelölési jel megbízhatóságát és a kijelölési állapot észlelését jelöli. Ha egy címkézett mező kijelölőjellel rendelkezik, az egyéni mező kijelölése a kijelölési jel megbízhatóságával együtt az általános megbízhatósági pontosság pontos ábrázolása.
Az alábbi táblázat bemutatja, hogyan értelmezheti a pontossági és megbízhatósági pontszámokat az egyéni modell teljesítményének méréséhez.
| Pontosság | Megbízhatóság | Eredmény |
|---|---|---|
| Magas | Magas | • A modell jól működik a címkézett kulcsokkal és a dokumentumformátumokkal. • Kiegyensúlyozott betanítási adatkészlete van. |
| Magas | Alacsony | • Az elemzett dokumentum a betanítási adatkészlettől eltérően jelenik meg. • A modellnek legalább öt további címkézett dokumentummal kellene újratanulnia. • Ezek az eredmények a betanítási adathalmaz és az elemzett dokumentum formátumváltozását is jelezhetik. Fontolja meg egy új modell hozzáadását. |
| Alacsony | Magas | • Ez az eredmény nem valószínű. • Alacsony pontosságú pontszámok esetén adjon hozzá több címkézett adatot, vagy ossza fel a vizuálisan különálló dokumentumokat több modellbe. |
| Alacsony | Alacsony | • További címkézett adatok hozzáadása. • Vizuálisan eltérő dokumentumokat több modellre oszthat. |
Táblázat, sor és cella megbízhatósága
A táblázat, a sor és a cella megbízhatóságának API-val 2024-02-29-preview való hozzáadásával az alábbi gyakori kérdések segíthetnek a táblázat, a sor és a cella pontszámainak értelmezésében:
K: Lehetséges magas megbízhatósági pontszámot látni a cellák esetében, de a sor alacsony megbízhatósági pontszámát?
V: Igen. A tábla megbízhatóságának különböző szintjei (cella, sor és táblázat) az adott szinten lévő előrejelzés helyességének rögzítésére szolgálnak. A sorhoz tartozó, más lehetséges kihagyásokkal rendelkező, helyesen előrejelzett cellákban magas a cella megbízhatósága, de a sor megbízhatóságának alacsonynak kell lennie. Hasonlóképpen, egy táblázat megfelelő sora, amely más sorokkal kapcsolatos kihívásokat tartalmaz, magas sorbizalommal rendelkezik, míg a táblázat általános megbízhatósága alacsony lenne.
K: Mi a várt megbízhatósági pontszám a cellák egyesítésekor? Mivel az egyesítés a módosítandó oszlopok számát eredményezi, hogyan érintik a pontszámokat?
Válasz: A táblázat típusától függetlenül az egyesített cellák elvárása az, hogy alacsonyabb megbízhatósági értékekkel rendelkezzenek. Ezenkívül a hiányzó cellának (mivel egy szomszédos cellával egyesítették) alacsonyabb megbízhatóságú értékkel kell rendelkeznie NULL . Hogy ezek az értékek mennyivel alacsonyabbak lehetnek, az a betanítási adatkészlettől függ, az egyesített és a hiányzó, alacsonyabb pontszámmal rendelkező cellák általános trendjének is meg kell tartania.
K: Mi a megbízhatósági pontszám, ha egy érték nem kötelező? Ha hiányzik az érték, akkor egy értéket és magas megbízhatósági pontszámot tartalmazó cellára NULL kell számítania?
Válasz: Ha a betanítási adatkészlet a cellák opcionálisságára jellemző, segít a modellnek tudnia, hogy milyen gyakran jelenik meg egy érték a betanítási csoportban, és így mire számíthat a következtetés során. Ez a funkció akkor használatos, ha egy előrejelzés megbízhatóságát számítja ki, vagy egyáltalán nem készít előrejelzést (NULL). A betanítási csoportban többnyire üres értékek esetén nagy megbízhatóságú üres mezőre kell számítania.
K: Hogyan érintik a megbízhatósági pontszámokat, ha egy mező nem kötelező, és nincs jelen vagy hiányzik? Az a várakozás, hogy a megbízhatósági pontszám választ ad erre a kérdésre?
Válasz: Ha egy érték hiányzik egy sorból, a cellához érték és megbízhatóság van NULL hozzárendelve. A magas megbízhatósági pontszámnak itt azt kell jelentenie, hogy a modell előrejelzése (ha nincs érték) nagyobb valószínűséggel helyes. Ezzel szemben az alacsony pontszámnak nagyobb bizonytalanságot kell jeleznie a modelltől (és így a hiba lehetőségét, például a kihagyott értéket).
K: Milyen elvárásnak kell lennie a cella megbízhatósága és a sorok megbízhatósága szempontjából, ha többoldalas táblázatot nyer ki oldalakra osztott sorokkal?
Válasz: Várja meg, hogy a cella megbízhatósága magas legyen, a sorok megbízhatósága pedig potenciálisan alacsonyabb legyen, mint a felosztott sorok. A betanítási adatkészlet felosztott sorainak aránya befolyásolhatja a megbízhatósági pontszámot. Az osztott sorok általában eltérnek a táblázat többi soránál (így a modell kevésbé biztos abban, hogy helyes).
K: Az oldalközi táblák esetében, amelyek sorai tiszta módon végződnek és az oldalhatárokon kezdődnek, helyes azt feltételezni, hogy a megbízhatósági pontszámok minden oldalon konzisztensek?
V: Igen. Mivel a sorok alakja és tartalma hasonló, függetlenül attól, hogy hol találhatók a dokumentumban (vagy melyik oldalon), a megfelelő megbízhatósági pontszámoknak konzisztensnek kell lenniük.
K: Mi a legjobb módja az új megbízhatósági pontszámok kihasználásának?
Válasz: Tekintse meg a tábla megbízhatóságának minden szintjét egy felülről lefelé haladó megközelítéssel: először ellenőrizze a táblázat megbízhatóságát egészében, majd fúrjon le a sorszintre, és nézze meg az egyes sorokat, végül tekintse meg a cellaszintű megbízhatóságokat. A táblázat típusától függően van néhány megjegyzés:
Rögzített táblák esetén a cellaszintű megbízhatóság már elég sok információt rögzít a dolgok helyességéről. Ez azt jelenti, hogy egyszerűen megy át minden cellát, és vizsgálja meg a megbízhatósága lehet elég ahhoz, hogy meghatározza a minőséget az előrejelzés. A dinamikus táblák esetében a szintek egymásra épülnek, ezért a felülről lefelé haladó megközelítés fontosabb.
A modell nagy pontosságának biztosítása
A dokumentumok vizuális szerkezetének eltérései befolyásolják a modell pontosságát. A jelentett pontossági pontszámok következetlenek lehetnek, ha az elemzett dokumentumok mások, mint a betanításhoz használtak. Számoljon azzal, hogy az emberi szemmel hasonlónak tűnő dokumentumkészletek egy AI-modell számára egészen mások lehetnek. A következőkben a legnagyobb pontosságú betanítási modellek ajánlott eljárásait soroljuk fel. Ezeknek az irányelveknek megfelelően olyan modellt kell létrehozni, amely nagyobb pontosságot és megbízhatósági pontszámot ad az elemzés során, és csökkentenie kell az emberi felülvizsgálatra megjelölt dokumentumok számát.
Gondoskodjon róla, hogy egy dokumentum valamennyi változata szerepeljen a betanítási adathalmazban. A változatok közé tartoznak a különböző formátumok, például a digitális és a szkennelt PDF-fájlok.
Ha azt szeretné, hogy a modell mindkét PDF-dokumentumtípust elemezze, adjon hozzá legalább öt mintát minden típusból a betanítási adatkészlethez.
Különítse el a vizuálisan eltérő dokumentumtípusokat a különböző modellek betanításához.
- Általános szabályként, ha eltávolítja az összes felhasználó által megadott értéket, és a dokumentumok hasonlóak, további betanítási adatokat kell hozzáadnia a meglévő modellhez.
- Ha a dokumentumok eltérőek, bontsa mappákra a betanítási adatokat, és tanítsa be a modellt mindegyik változattal. Ezt követően egyetlen modellben egyesítheti a különböző változatokat.
Győződjön meg arról, hogy nincsenek felesleges címkék.
Győződjön meg arról, hogy az aláírás és a régió címkézése nem tartalmazza a környező szöveget.
Következő lépés
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: