A Document Intelligence nyilvános előzetes verziójú kiadásai korai hozzáférést biztosítanak az aktív fejlesztés alatt lévő funkciókhoz. A funkciók, a megközelítések és a folyamatok az általános rendelkezésre állás (GA) előtt változhatnak a felhasználói visszajelzések alapján.
A Document Intelligence ügyfélkódtárak nyilvános előzetes verziója alapértelmezés szerint a REST API 2024-07-31-preview verziója.
A nyilvános előzetes verzió 2024-07-31 előzetes verziója jelenleg csak a következő Azure-régiókban érhető el. Vegye figyelembe, hogy az AI Studio egyéni generatív (dokumentummező-kinyerési) modellje csak az USA északi középső régiójában érhető el:
USA keleti régiója
USA2 nyugati régiója
Nyugat-Európa
USA északi középső régiója
Ez a tartalom a következőre vonatkozik:v4.0 (előzetes verzió) | Korábbi verziók: v3.1 (GA)
Ez a tartalom a következőre vonatkozik:v3.1 (GA) | Legújabb verzió: v4.0 (előzetes verzió)
A Dokumentumintelligencia kifinomultabb és modulárisabb elemzési képességeket támogat. A bővítményfunkciókkal kibővítheti az eredményeket, hogy további, a dokumentumokból kinyert funkciókat is tartalmazzon. Egyes bővítményfunkciók többletköltséggel járnak. Ezek az opcionális funkciók a dokumentum kinyerésének forgatókönyvétől függően engedélyezhetők és letilthatók. A szolgáltatás engedélyezéséhez adja hozzá a társított szolgáltatásnevet a lekérdezési sztring features tulajdonsághoz. Egy kérelemben több bővítmény funkciót is engedélyezhet vesszővel tagolt funkciók listájának megadásával. A következő bővítményfunkciók érhetők el a későbbi és újabb kiadásokhoz 2023-07-31 (GA) .
Az összes modell nem minden bővítményfunkciót támogat. További információ: modelladatok kinyerése.
A bővítményfunkciók jelenleg nem támogatottak a Microsoft Office-fájltípusokhoz.
A Dokumentumintelligencia támogatja azokat az opcionális funkciókat, amelyek a dokumentum kinyerési forgatókönyvétől függően engedélyezhetők és letilthatók. A következő bővítményfunkciók érhetők el a későbbi és újabb kiadásokhoz 2023-10-31-preview:
A lekérdezésmezők implementációja a 2023-10-30 előzetes verziójú API-ban eltér a legutóbbi előzetes verziótól. Az új implementáció kevésbé költséges, és jól működik a strukturált dokumentumokkal.
✱ Bővítmény – A lekérdezésmezők ára eltér a többi bővítményfunkciótól. Részletekért tekintse meg a díjszabást .
Támogatott fájlformátumok
PDF
Képek: JPEG/JPG, PNG, BMP, TIFFHEIF
✱ A Microsoft Office-fájlok jelenleg nem támogatottak.
Nagy felbontású kinyerés
A nagy méretű dokumentumokból, például a mérnöki rajzokból származó kis szövegek felismerése kihívást jelent. A szöveg gyakran keveredik más grafikus elemekkel, és különböző betűtípusokkal, méretekkel és tájolásokkal rendelkezik. Ezenkívül a szöveg külön részekre bontható, vagy más szimbólumokhoz is csatlakoztatható. A Dokumentumintelligencia mostantól támogatja a tartalom kinyerését az ilyen típusú dokumentumokból a ocr.highResolution képességgel. A bővítmény funkció engedélyezésével jobb minőségű tartalomkinyerést kaphat az A1/A2/A3-dokumentumokból.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
A ocr.formula képesség kinyeri a gyűjteményben lévő összes azonosított képletet, például matematikai egyenletet, felső szintű objektumkéntcontent.formulas Belül contentaz észlelt képletek a következőképpen jelennek meg :formula:: . A gyűjtemény minden bejegyzése egy képletet jelöl, amely tartalmazza a képlettípust inline mint vagy display, és annak LaTeX-ábrázolása a value koordinátáival polygon együtt. Kezdetben a képletek az egyes lapok végén jelennek meg.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Betűtípustulajdonságok kinyerése
A ocr.font funkció a gyűjteményben kinyert szöveg összes betűtulajdonságát legfelső szintű objektumként contentnyeri ki.styles Minden stílusobjektum egyetlen betűtípustulajdonságot, a rá vonatkozó szöveget és annak megbízhatósági pontszámát adja meg. A meglévő stílustulajdonság további betűtípus-tulajdonságokkal bővül, például similarFontFamily a szöveg betűtípusa, fontStyle a dőlt és normál stílusok, a félkövér vagy normál stílusok fontWeight , color a szöveg színe és backgroundColor a szöveg határolókeretének színe.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
A ocr.barcode képesség kinyeri a gyűjteményben lévő összes azonosított vonalkódot legfelső szintű objektumkéntcontent.barcodes A rendszer az észlelt vonalkódokat a contentkövetkezőként :barcode:jeleníti meg: . A gyűjtemény minden bejegyzése egy vonalkódot jelöl, és tartalmazza a vonalkód típusát és kind a beágyazott vonalkód tartalmát value a koordinátáival polygon együtt. Kezdetben a vonalkódok az egyes oldalak végén jelennek meg. A confidence kód az 1-hez van beállítva.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
Ha hozzáadja a languages funkciót a analyzeResult kéréshez, az előrejelzi az észlelt elsődleges nyelvet az egyes szövegsorokhoz, valamint a languagesconfidence gyűjtemény alatt lévő analyzeResultnyelvhez.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
A kereshető PDF-funkcióval analóg PDF-fájlokat, például beolvasott PDF-fájlokat konvertálhat beágyazott szöveggel rendelkező PDF-fájllá. A beágyazott szöveg lehetővé teszi a részletes szövegkeresést a PDF kinyert tartalmában az észlelt szöveges entitások képfájlokra való felülírásával.
Fontos
A kereshető PDF-funkciót jelenleg csak a Read OCR-modell prebuilt-readtámogatja. A funkció használatakor adja meg a modelId következőt prebuilt-read, mivel más modelltípusok hibát adnak vissza ehhez az előzetes verzióhoz.
A kereshető PDF a 2024-07-31 előzetes verziójú prebuilt-read modell részét képezi, az általános PDF-használat használati költsége nélkül.
Kereshető PDF használata
A kereshető PDF használatához küldjön egy kérést POST a Analyze művelettel, és adja meg a kimeneti formátumot a következő módon pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Ha a Analyze művelet befejeződött, küldjön egy kérést GET a művelet eredményeinek lekérésére Analyze .
A sikeres befejezés után a PDF lekérhető és letölthető a következő formátumban application/pdf: . Ez a művelet lehetővé teszi a PDF beágyazott szöveges formájának közvetlen letöltését a Base64 kódolású JSON helyett.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Kulcs-érték párok
A korábbi API-verziókban az előre összeállított dokumentummodell kulcs-érték párokat nyert ki űrlapokból és dokumentumokból. A funkció előre összeállított elrendezéshez való hozzáadásával keyValuePairs az elrendezési modell ugyanazokat az eredményeket hozza létre.
A kulcs-érték párok a dokumentum azon meghatározott tartományai, amelyek azonosítják a címkét vagy kulcsot, valamint a hozzá tartozó választ vagy értéket. Strukturált formában ezek a párok lehetnek az adott mezőhöz megadott címke és érték. Strukturálatlan dokumentumokban a szerződés végrehajtásának dátuma lehet egy bekezdés szövege alapján. Az AI-modell betanítása az azonosítható kulcsok és értékek kinyerésére a dokumentumtípusok, formátumok és struktúrák széles választéka alapján történik.
A kulcsok külön is létezhetnek, ha a modell észleli, hogy egy kulcs létezik, nincs hozzárendelt érték, vagy ha nem kötelező mezőket dolgoz fel. Előfordulhat például, hogy egy középső név mező üresen hagyható egy űrlapon egyes példányokban. A kulcs-érték párok a dokumentumban található szövegtartományok. Azokban a dokumentumokban, ahol ugyanazt az értéket különböző módokon írják le, például ügyfél/felhasználó, a társított kulcs ügyfél vagy felhasználó (környezet alapján).
A lekérdezésmezők olyan bővítmények, amelyek kibővítik az előre összeállított modellből kinyert sémát, vagy meghatároznak egy adott kulcsnevet, ha a kulcs neve változó. A lekérdezésmezők használatához állítsa be a tulajdonságokat queryFields a tulajdonság mezőneveinek vesszővel tagolt listájára, és adja meg őket queryFields .
A Dokumentumintelligencia mostantól támogatja a lekérdezési mezők kinyeréseit. A lekérdezési mezők kinyerése során mezőket adhat hozzá az extrakciós folyamathoz egy lekérdezési kéréssel anélkül, hogy további betanításra van szükség.
Lekérdezésmezőket akkor használjon, ha ki kell terjesztenie egy előre összeállított vagy egyéni modell sémáját, vagy ki kell nyernie néhány mezőt az elrendezés kimenetével.
A lekérdezésmezők prémium szintű bővítmények. A legjobb eredmény érdekében adja meg a kinyerni kívánt mezőket teve- vagy Pascal-mezőnevek használatával a többszavas mezőnevekhez.
A lekérdezési mezők kérésenként legfeljebb 20 mezőt támogatnak. Ha a dokumentum a mező értékét tartalmazza, a rendszer visszaadja a mezőt és az értéket.
Ez a kiadás új implementációval rendelkezik a lekérdezésmezők funkcióhoz, amely alacsonyabb, mint a korábbi implementációé, és amelyet ellenőrizni kell.
Feljegyzés
A Document Intelligence Studio lekérdezésmező-kinyerése jelenleg az Layout és az Előre összeállított modellek 2024-02-29-preview2023-10-31-preview API-val érhető el, és a modellek (W2, 1098s és 1099s modellek) kivételével US tax újabb kiadásokban érhető el.
Lekérdezésmező kinyerése
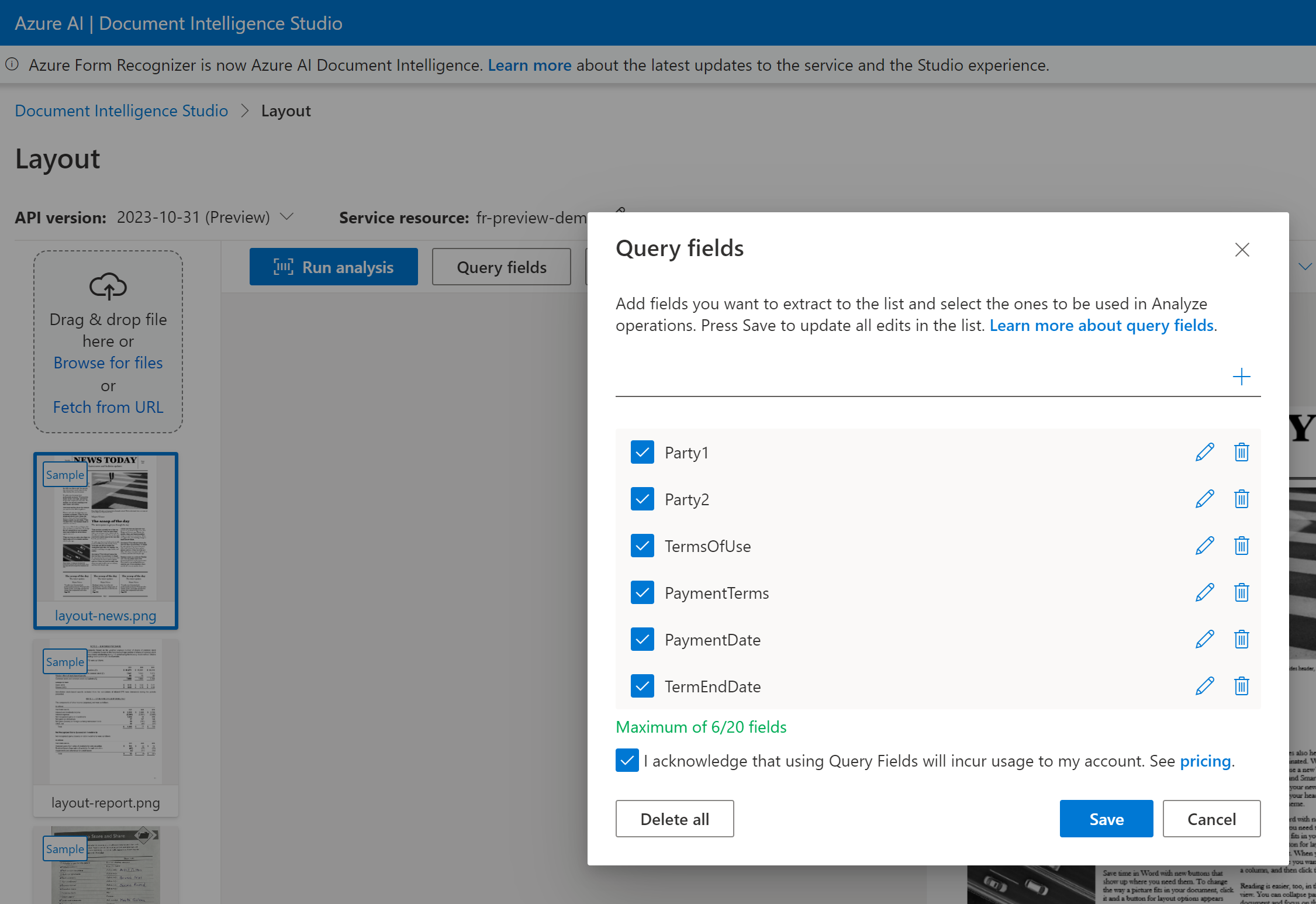
A lekérdezési mezők kinyeréséhez adja meg a kinyerni kívánt mezőket, és a Dokumentumintelligencia ennek megfelelően elemzi a dokumentumot. Példa:
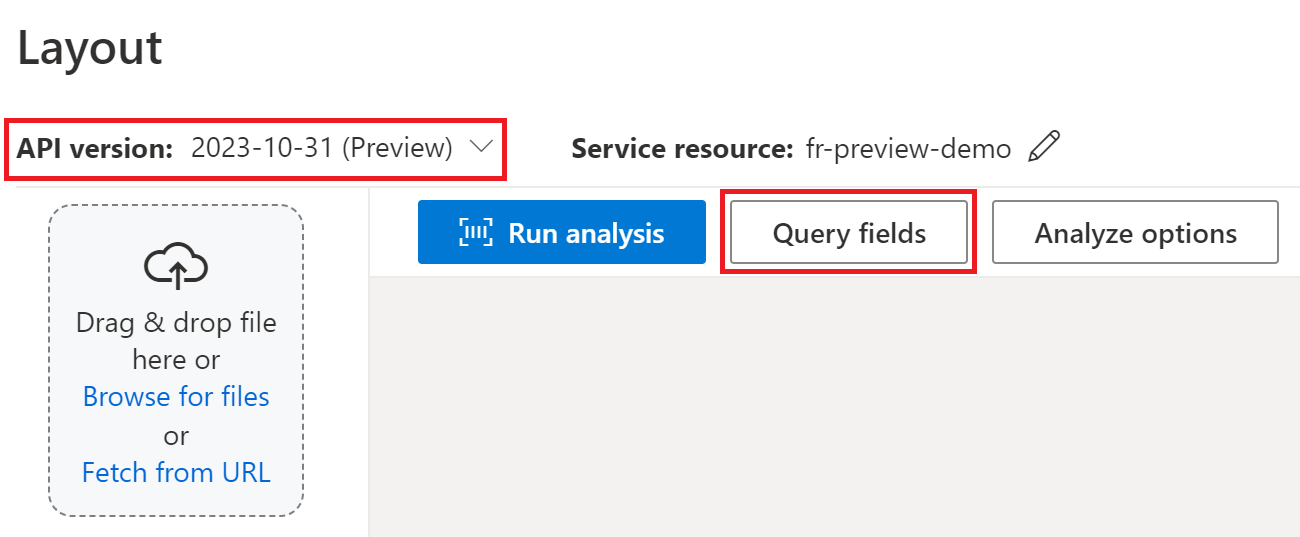
Ha a Document Intelligence Studióban dolgoz fel szerződést, használja a 2024-02-29-preview2023-10-31-preview következő verziókat:
A kérelem részeként átadhatja az olyan mezőfeliratok listáját, mint Party1a , Party2, TermsOfUsePaymentDatePaymentTermsés TermEndDate a analyze document kérelem részeként.
A Dokumentumintelligencia képes elemezni és kinyerni a mezőadatokat, és visszaadni az értékeket egy strukturált JSON-kimenetben.
A lekérdezési mezők mellett a válasz szövegeket, táblázatokat, kijelölési jeleket és egyéb releváns adatokat is tartalmaz.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")