Dokumentumfeldolgozási modellek
Fontos
- A Document Intelligence nyilvános előzetes verziójú kiadásai korai hozzáférést biztosítanak az aktív fejlesztés alatt lévő funkciókhoz.
- A funkciók, a megközelítések és a folyamatok az általános rendelkezésre állás (GA) előtt változhatnak a felhasználói visszajelzések alapján.
- A Document Intelligence ügyfélkódtárak nyilvános előzetes verziója alapértelmezés szerint a REST API 2024-02-29-preview verziója.
- A nyilvános előzetes verzió 2024-02-29 előzetes verziója jelenleg csak a következő Azure-régiókban érhető el:
- USA keleti régiója
- USA2 nyugati régiója
- Nyugat-Európa
Ez a tartalom a következőre vonatkozik::![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Ez a tartalom a következőre vonatkozik::![]() v3.1 (GA) | Legújabb verzió:
v3.1 (GA) | Legújabb verzió:![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.0
v3.0![]() v2.1
v2.1
Ez a tartalom a következőre vonatkozik::![]() v3.0 (GA) | Legújabb verziók:
v3.0 (GA) | Legújabb verziók:![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió)![]() v3.1 | Korábbi verzió:
v3.1 | Korábbi verzió:![]() v2.1
v2.1
Ez a tartalom a következőre vonatkozik::![]() v2.1 | Legújabb verzió:
v2.1 | Legújabb verzió:![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió)
Az Azure AI Document Intelligence számos olyan modellt támogat, amelyek lehetővé teszik intelligens dokumentumfeldolgozás hozzáadását az alkalmazásokhoz és folyamatokhoz. Használhat előre összeállított tartományspecifikus modellt, vagy betaníthat egy egyéni modellt, amely az adott üzleti igényeknek és használati eseteknek megfelelően van kialakítva. A dokumentumintelligencia a REST API- vagy Python-, C#-, Java- és JavaScript-ügyfélkódtárakkal használható.
Modell áttekintése
Az alábbi táblázat az egyes jelenlegi és stabil API-khoz elérhető modelleket mutatja be:
| Modell típusa | Modell | • 2024-02-29-preview &listajel 2023-10-31-preview |
2023-07-31 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Dokumentumelemzési modellek | Olvasás | ✔️ | ✔️ | ✔️ | n.a. |
| Dokumentumelemzési modellek | Elrendezés | ✔️ | ✔️ | ✔️ | ✔️ |
| Dokumentumelemzési modellek | Általános dokumentum | áthelyezve az elrendezésbe** | ✔️ | ✔️ | n.a. |
| Előre összeállított modellek | Szerződés | ✔️ | ✔️ | n.a. | n.a. |
| Előre összeállított modellek | Egészségbiztosítási kártya | ✔️ | ✔️ | ✔️ | n.a. |
| Előre összeállított modellek | Személyazonosító okmányok | ✔️ | ✔️ | ✔️ | ✔️ |
| Előre összeállított modellek | Számla | ✔️ | ✔️ | ✔️ | ✔️ |
| Előre összeállított modellek | Beérkezési | ✔️ | ✔️ | ✔️ | ✔️ |
| Előre összeállított modellek | USA 1040 Adó* | ✔️ | ✔️ | n.a. | n.a. |
| Előre összeállított modellek | USA 1098 Adó* | ✔️ | n.a. | n.a. | n.a. |
| Előre összeállított modellek | USA 1099 Adó* | ✔️ | n.a. | n.a. | n.a. |
| Előre összeállított modellek | AMERIKAI W2 adó | ✔️ | ✔️ | ✔️ | n.a. |
| Előre összeállított modellek | US Mortgage 1003 URLA | ✔️ | n.a. | n.a. | n.a. |
| Előre összeállított modellek | US Mortgage 1008 Összegzés | ✔️ | n.a. | n.a. | n.a. |
| Előre összeállított modellek | USA-beli jelzáloghitelek záró közzététele | ✔️ | n.a. | n.a. | n.a. |
| Előre összeállított modellek | Házassági anyakönyvi kivonat | ✔️ | n.a. | n.a. | n.a. |
| Előre összeállított modellek | Hitelkártya | ✔️ | n.a. | n.a. | n.a. |
| Előre összeállított modellek | Névjegykártya | Elavult | ✔️ | ✔️ | ✔️ |
| Egyéni besorolási modell | Egyéni osztályozó | ✔️ | ✔️ | n.a. | n.a. |
| Egyéni extrakciós modell | Egyéni neurális | ✔️ | ✔️ | ✔️ | n.a. |
| Customextraction modell | Egyéni sablon | ✔️ | ✔️ | ✔️ | ✔️ |
| Egyéni extrakciós modell | Egyéni összeállítás | ✔️ | ✔️ | ✔️ | ✔️ |
| Minden modell | Bővítmények képességei | ✔️ | ✔️ | n.a. | n.a. |
* – Almodelleket tartalmaz. A támogatott változatok és altípusok modellspecifikus információi.
| Bővítmény képessége | Bővítmény/ingyenes | • 2024-02-29-preview &listajel [2023-10-31-preview](/rest/api/aiservices/operation-groups?view=rest-aiservices-2024-02-29-preview&preserve-view=true |
2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Betűtípustulajdonságok kinyerése | Összead | ✔️ | ✔️ | n.a. | n.a. |
| Képlet kinyerése | Összead | ✔️ | ✔️ | n.a. | n.a. |
| Nagy felbontású kinyerés | Összead | ✔️ | ✔️ | n.a. | n.a. |
| Vonalkód kinyerése | Ingyenes | ✔️ | ✔️ | n.a. | n.a. |
| Nyelvfelismerés | Ingyenes | ✔️ | ✔️ | n.a. | n.a. |
| Kulcsértékpárok | Ingyenes | ✔️ | n.a. | n.a. | n.a. |
| Lekérdezési mezők | Összead* | ✔️ | n.a. | n.a. | n.a. |
Modellelemzési funkciók
| Modellazonosító | Tartalom kinyerése | Lekérdezési mezők | Bekezdések | Bekezdésszerepkörök | Kijelölési jelek | Táblák | Kulcs-érték párok | Nyelvek | Vonalkódok | Dokumentumelemzés | Képletek* | Stílus betűtípusa* | Felsőbb* |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| előre összeállított olvasás | ✓ | O | O | O | O | O | |||||||
| előre összeállított elrendezés | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | ||
| előre összeállított dokumentum | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | |
| előre összeállított-businessCard | ✓ | ✓ | ✓ | ||||||||||
| előre összeállított szerződés | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| előre összeállított-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| előre összeállított számla | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | ||
| előre összeállított nyugta | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| előre összeállított-creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1099(változatok) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | ||||
| prebuilt-tax.us.1040(változatok) | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ – Engedélyezett
O – Nem kötelező
* – A prémium funkciók többletköltséggel járnak
Bővítmény* – A lekérdezésmezők ára eltér a többi bővítményfunkciótól. Részletekért tekintse meg a díjszabást .
| Modell | Leírás |
|---|---|
| Dokumentumelemzési modellek | |
| OcR olvasása | Nyomtatott és kézzel írt szöveg kinyerése szavakkal, helyekkel és észlelt nyelvekkel együtt. |
| Elrendezéselemzés | Szöveg- és dokumentumelrendezési elemek, például táblázatok, kijelölési jelek, címek, szakaszfejlécek és egyebek kinyerése. |
| Előre összeállított modellek | |
| Egészségbiztosítási kártya | Automatizálhatja az egészségügyi folyamatokat a biztosító, a tag, a vény, a csoportszám és más kulcsfontosságú információk amerikai egészségbiztosítási kártyákból való kinyerésével. |
| Usa-beli adódokumentum-modellek | Amerikai adózási űrlapok feldolgozása alkalmazotti, munkáltatói, bér- és egyéb információk kinyeréséhez. |
| US Mortgage-dokumentummodellek | Usa-beli jelzálog-űrlapok feldolgozása a hitelfelvevő hitel- és ingatlaninformációinak kinyeréséhez. |
| Szerződés | Bontsa ki a szerződést és a felek adatait. |
| Számla | Számlák automatizálása. |
| Beérkezési | Nyugtaadatok kinyerve a nyugtákból. |
| Identitásdokumentum (azonosító) | A személyazonossági (id) mezők kinyerve az egyesült államokbeli jogosítványokból és nemzetközi útlevelekből. |
| Névjegykártya | A névjegykártyák beolvasása a kulcsmezők és adatok alkalmazásba való kinyeréséhez. |
| Egyéni modellek | |
| Egyéni modell (áttekintés) | Adatokat nyerhet ki a vállalkozásához tartozó űrlapokból és dokumentumokból. Az egyéni modellek be vannak tanítva a különböző adatokhoz és használati esetekhez. |
| Egyéni extrakciós modellek | ● Az egyéni sablonmodellek elrendezési jeleket használnak az értékek dokumentumokból való kinyerésére, és alkalmasak mezők kinyerésére magas strukturált dokumentumokból, meghatározott vizualizációs sablonokkal. ● Az egyéni neurális modellek különböző dokumentumtípusokra vannak betanolva, hogy mezőket nyerjenek ki strukturált, félig strukturált és strukturálatlan dokumentumokból. |
| Egyéni besorolási modell | Az egyéni besorolási modell osztályozhatja a bemeneti fájl egyes lapjait, hogy azonosítsa a bemeneti fájlban lévő dokumentumokat, és több dokumentumot vagy egy dokumentum több példányát is azonosíthatja egy bemeneti fájlban. |
| Összeállított modellek | Több egyéni modell egyetlen modellbe kombinálásával automatizálhatja a különböző dokumentumtípusok feldolgozását egyetlen összeállított modellel. |
A Névjegykártya-modell kivételével az összes modell esetében a Dokumentumintelligencia mostantól támogatja a bővítményfunkciókat, hogy kifinomultabb elemzést lehessen lehetővé tenni. Ezek az opcionális képességek a dokumentum kinyerésének forgatókönyvétől függően engedélyezhetők és letilthatók. A (GA) és újabb 2023-07-31 API-verzióhoz hét bővítmény áll rendelkezésre:
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairs(2024-02-29-preview, 2023-10-31-preview)queryFields(2024-02-29-preview, 2023-10-31-preview)Not available with the US.Tax models
Modell adatai
Ez a szakasz az egyes modellektől elvárható kimenetet ismerteti. Vegye figyelembe, hogy a legtöbb modell kimenetét bővítheti bővítményfunkciókkal.
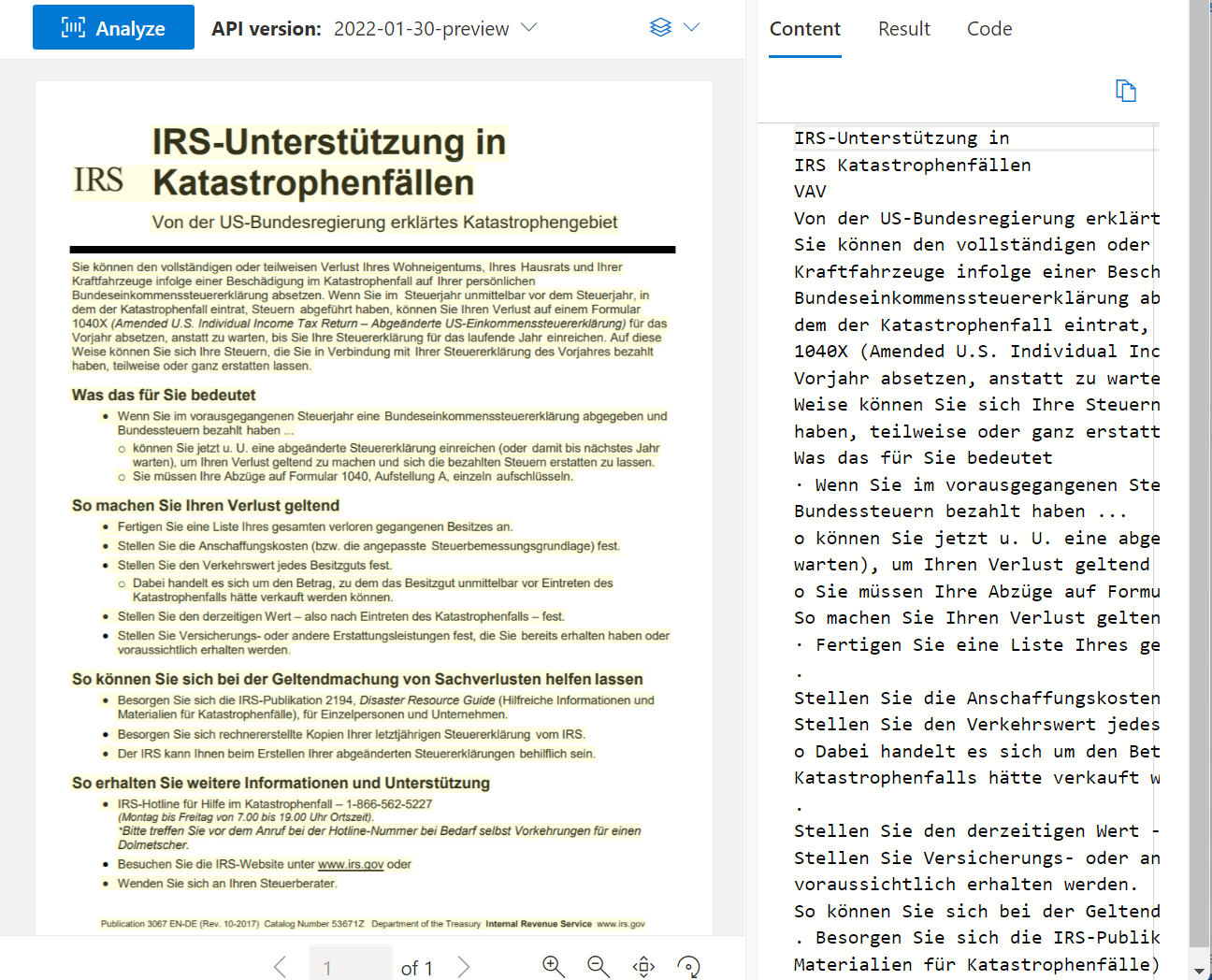
Read OCR

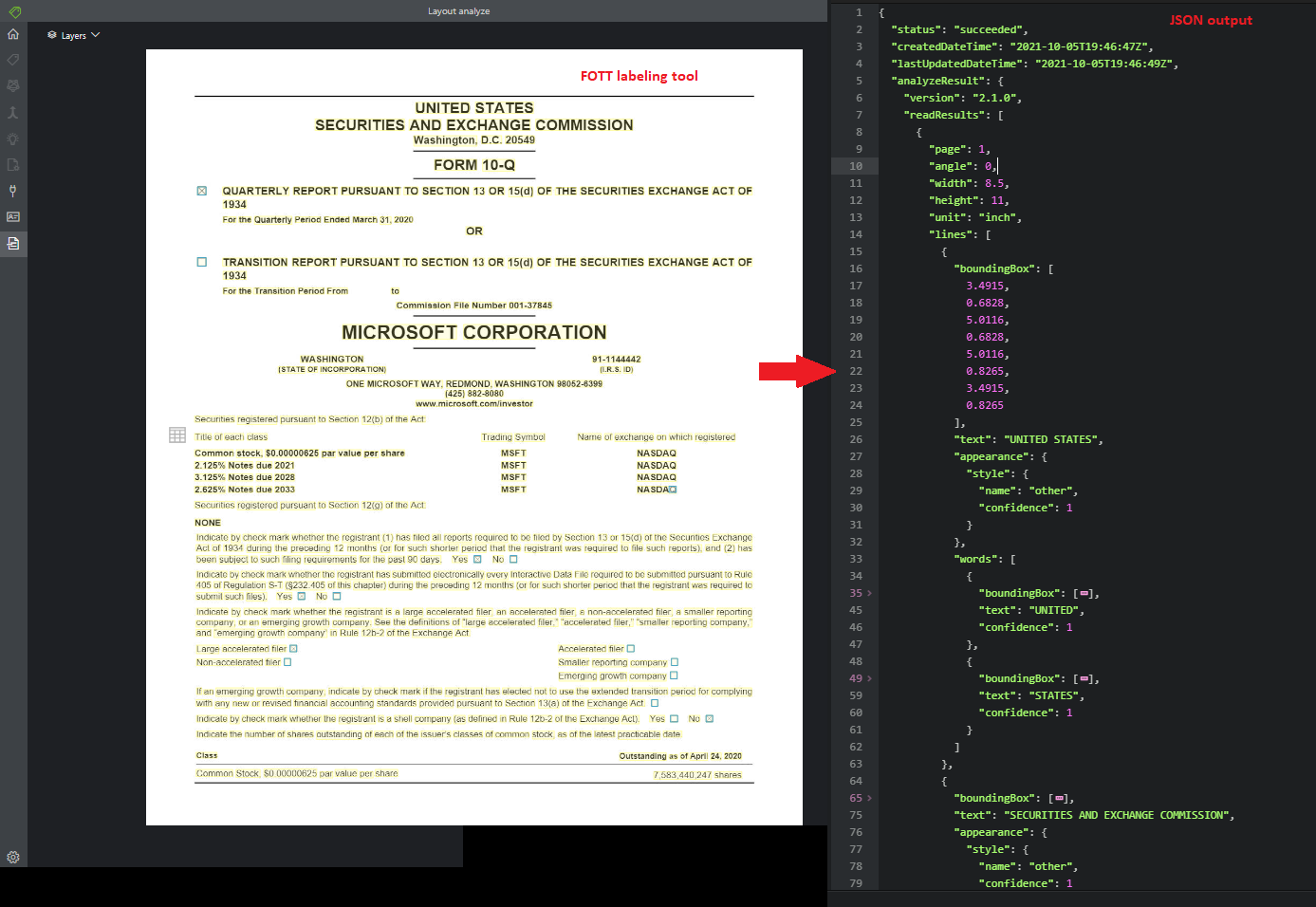
A Read API elemzi és kinyeri a vonalakat, szavakat, azok helyét, az észlelt nyelveket és a kézzel írt stílust, ha észleli őket.
A Document Intelligence Studio használatával feldolgozott mintadokumentum:
Elrendezéselemzés
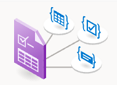
Az elrendezéselemzési modell elemzi és kinyeri a szöveget, a táblázatokat, a kijelölési jeleket és más szerkezeti elemeket, például a címeket, a szakaszfejléceket, az oldalfejléceket, az oldallábakat és egyebeket.
A Document Intelligence Studio használatával feldolgozott mintadokumentum:
Egészségbiztosítási kártya
![]()
Az egészségbiztosítási kártyamodell a hatékony optikai karakterfelismerési (OCR) képességeket a mélytanulási modellekkel kombinálva elemzi és kinyeri a legfontosabb információkat az EGYESÜLT Államok egészségbiztosítási kártyáiból.
A Document Intelligence Studio használatával feldolgozott USA-beli egészségbiztosítási kártyaminta:

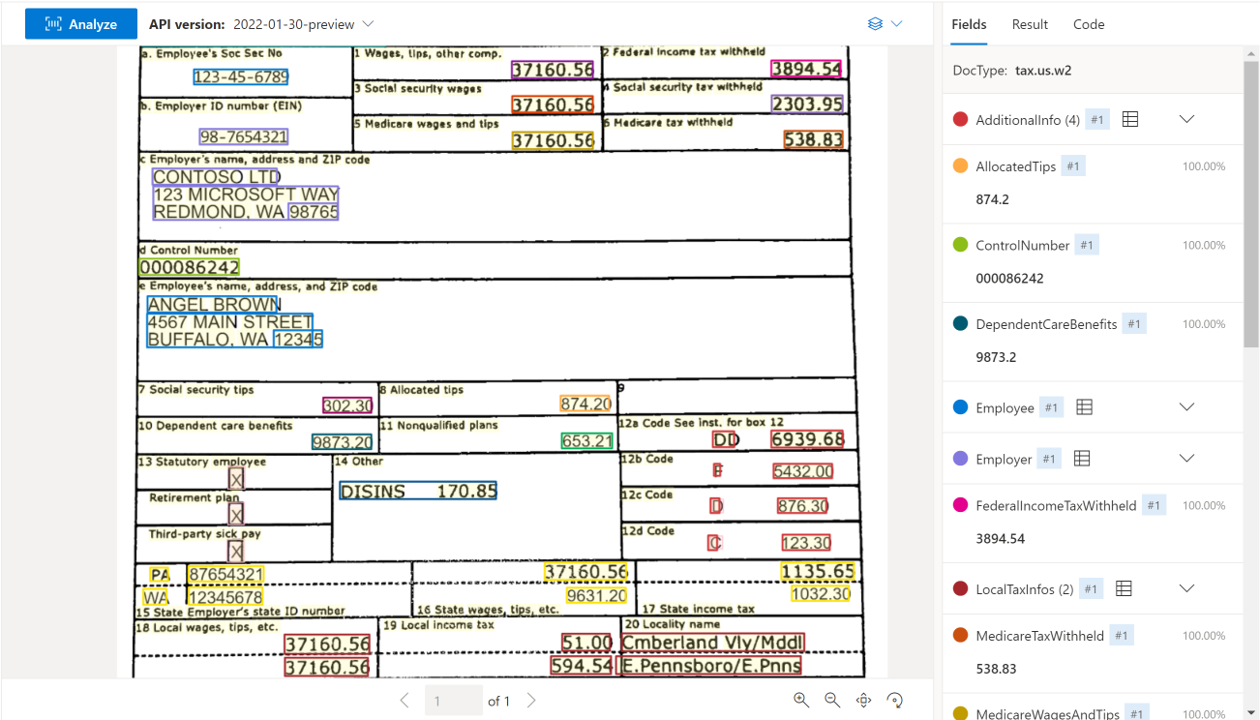
Amerikai adódokumentumok

Az egyesült államokbeli adódokumentum-modellek az adódokumentumok kiválasztott csoportjából elemzik és nyerik ki a kulcsmezőket és a sorelemeket. Az API támogatja az angol nyelvű amerikai adódokumentumok különböző formátumú és minőségű elemzését, beleértve a telefonon rögzített képeket, a beolvasott dokumentumokat és a digitális PDF-eket. Jelenleg a következő modellek támogatottak:
| Modell | Leírás | ModelID |
|---|---|---|
| AMERIKAI adó W-2 | Az adóköteles kompenzáció részleteinek kinyerése. | előre összeállított-tax.us.W-2 |
| Amerikai adó 1040 | A jelzálog-kamat részleteinek kinyerésében. | prebuilt-tax.us.1040(változatok) |
| Amerikai adó 1098 | A jelzálog-kamat részleteinek kinyerésében. | prebuilt-tax.us.1098(változatok) |
| Amerikai adó 1099 | A munkáltatótól eltérő forrásokból származó jövedelem kinyeréséből. | prebuilt-tax.us.1099(változatok) |
A Document Intelligence Studio használatával feldolgozott W-2-mintadokumentum:
USA-beli jelzáloghitel-dokumentumok

Az usa-beli jelzálogdokumentum-modellek elemzik és kinyerik a kulcsfontosságú mezőket, beleértve a hitelfelvevő, a hitel- és az ingatlaninformációkat a jelzálogdokumentumok egy kiválasztott csoportjából. Az API támogatja az angol nyelvű, különböző formátumú és minőségű, amerikai jelzáloghiteles dokumentumok elemzését, beleértve a telefonon rögzített képeket, a beolvasott dokumentumokat és a digitális PDF-eket. Jelenleg a következő modellek támogatottak:
| Modell | Leírás | ModelID |
|---|---|---|
| 1003 Végfelhasználói licencszerződés (EULA) | Hitel, hitelfelvevő, ingatlan adatainak kinyerés. | prebuilt-mortgage.us.1003 |
| 1008- összefoglaló dokumentum | Hitelfelvevő, eladó, ingatlan, jelzálog és jegyzés részleteinek kinyerése. | prebuilt-mortgage.us.1008 |
| Közzététel lezárása | A lezárás, a tranzakciós költségek és a hitel részleteinek kinyerésére. | prebuilt-mortgage.us.closingDisclosure |
| Házassági anyakönyvi kivonat | A közös kölcsön kérelmezőinek házassági adatainak kinyeréséről. | előre összeállított-házasságCertificate |
| AMERIKAI adó W-2 | Jövedelemigazolás adóköteles kompenzációs adatainak kinyerése. | előre összeállított-tax.us.W-2 |
Minta a Document Intelligence Studio használatával feldolgozott záró közzétételi dokumentumra:

Contract
![]()
A szerződési modell elemzi és kinyeri a főbb mezőket és sorelemeket a szerződéses szerződésekből, beleértve a feleket, a joghatóságokat, a szerződés azonosítóját és a címet. A modell jelenleg az angol nyelvű szerződéses dokumentumokat támogatja.
A Document Intelligence Studio használatával feldolgozott mintaszerződés:

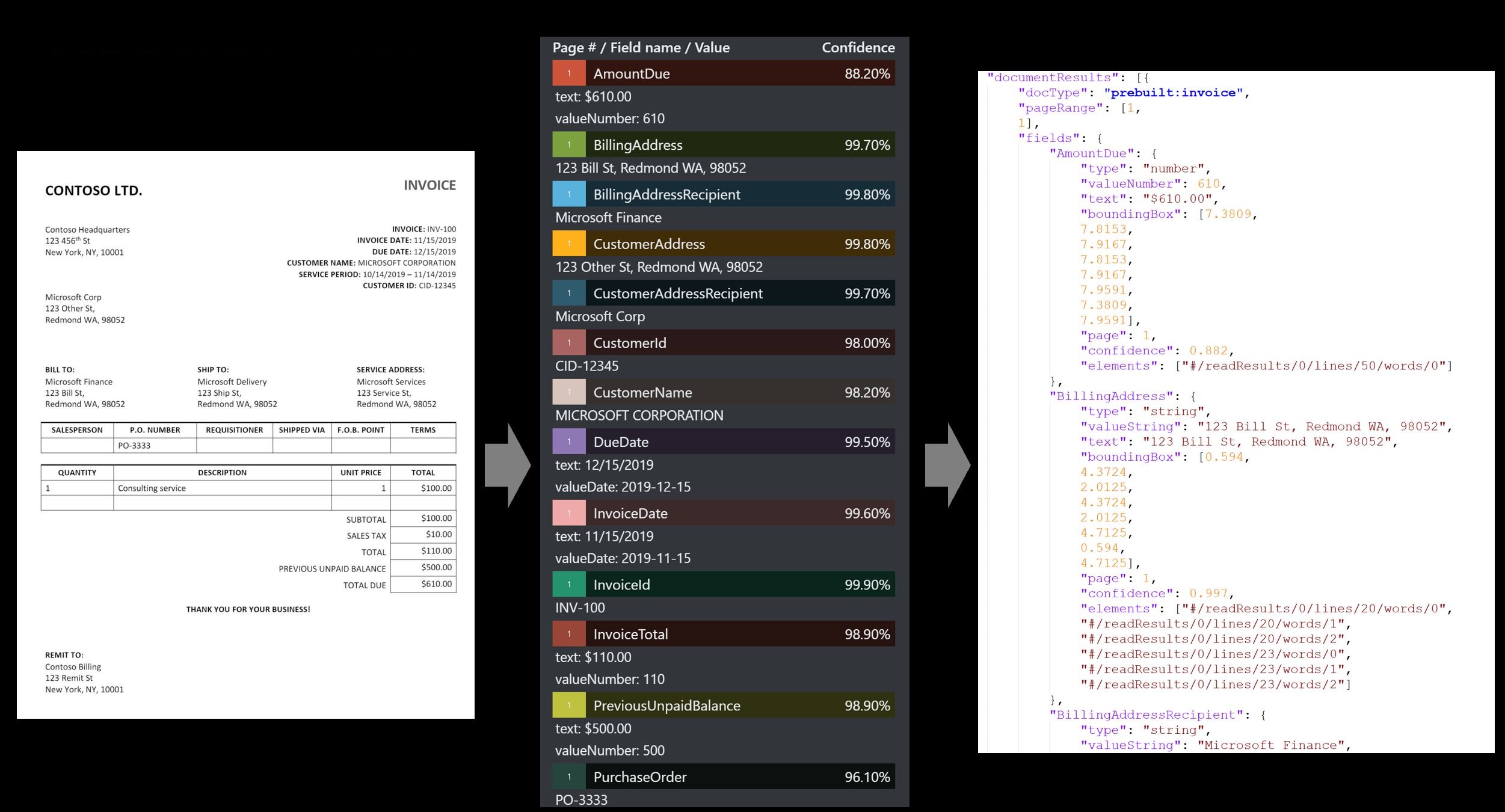
Számla

A számlamodell automatizálja a számlák feldolgozását az ügyfélnév, a számlázási cím, a határidő és az esedékes összeg, a sorelemek és egyéb kulcsadatok kinyeréséhez. A modell jelenleg az angol, spanyol, német, francia, olasz, portugál és holland számlákat támogatja.
A Document Intelligence Studio használatával feldolgozott számlaminta:

Nyugta
A nyugtamodell használatával a kereskedő nevét, dátumait, sortételeit, mennyiségét és összegét a nyomtatott és kézzel írt nyugtákból származó értékesítési nyugták vizsgálatára használhatja. A 3.0-s verzió az egyoldalas szállodai nyugtafeldolgozást is támogatja.
A Document Intelligence Studio használatával feldolgozott minta nyugta:

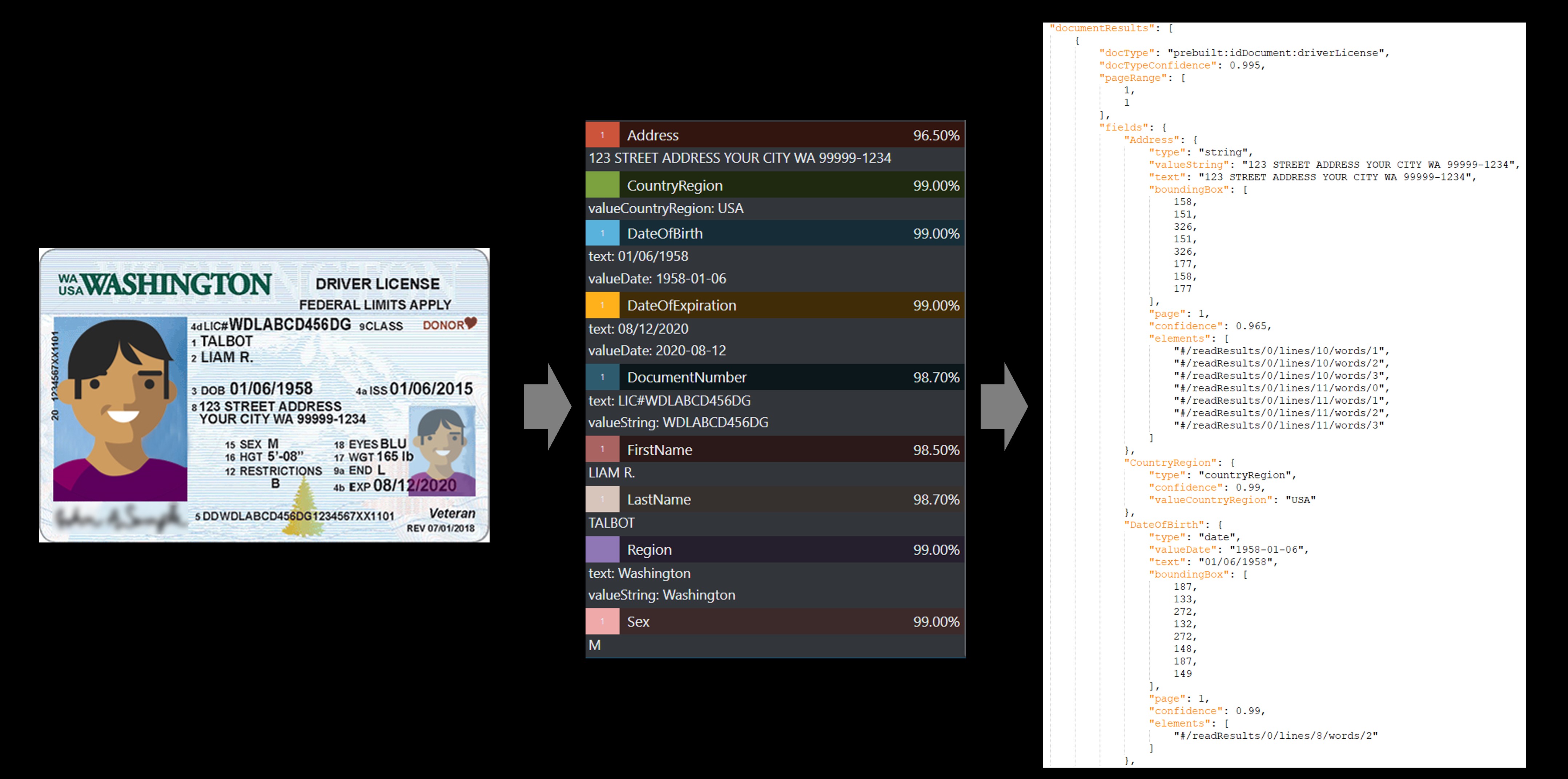
Identitásdokumentum (azonosító)

A kulcsmezők kinyeréséhez használja az identitásdokumentum (id) modellt az amerikai jogosítványok (mind az 50 állam és Columbia kerület) és az életrajzi lapok feldolgozásához nemzetközi útlevelekből (a vízum és egyéb úti okmányok kivételével).
Példa a Document Intelligence Studióval feldolgozott amerikai illesztőprogram-licencre:

Házassági anyakönyvi kivonat
![]()
A házassági anyakönyvi kivonat modelljével feldolgozhatja az amerikai házassági anyakönyvi kivonatokat, hogy kinyerje a legfontosabb mezőket, beleértve az egyéneket, a dátumot és a helyet.
A Document Intelligence Studio használatával feldolgozott amerikai házassági anyakönyvi kivonat minta:

Hitelkártya
![]()
A hitelkártya-modell használatával feldolgozhatja a hitel- és bankkártyákat a kulcsmezők kinyeréséhez.
A Document Intelligence Studio használatával feldolgozott hitelkártyaminta:

Egyéni modellek

Az egyéni modellek széles körben két típusba sorolhatók. Olyan egyéni besorolási modellek, amelyek támogatják a "dokumentumtípus" besorolását és az egyéni extrakciós modelleket, amelyek egy meghatározott sémát kinyerhetnek egy adott dokumentumtípusból.

Az egyéni dokumentummodellek a vállalatra jellemző űrlapokból és dokumentumokból elemzik és nyerik ki az adatokat. Betanítottuk őket, hogy felismerjék az űrlapmezőket a különálló tartalomban, és kulcs-érték párokat és táblaadatokat nyerjenek ki. Az első lépésekhez csak egy példa kell az űrlaptípusra.
A 3.0-s verziójú egyéni modell támogatja az aláírásészlelést az egyéni sablonban (űrlap) és a többoldalas táblázatokban mind a sablonban, mind a neurális modellekben.
Minta egyéni sablon a Document Intelligence Studióval feldolgozva:
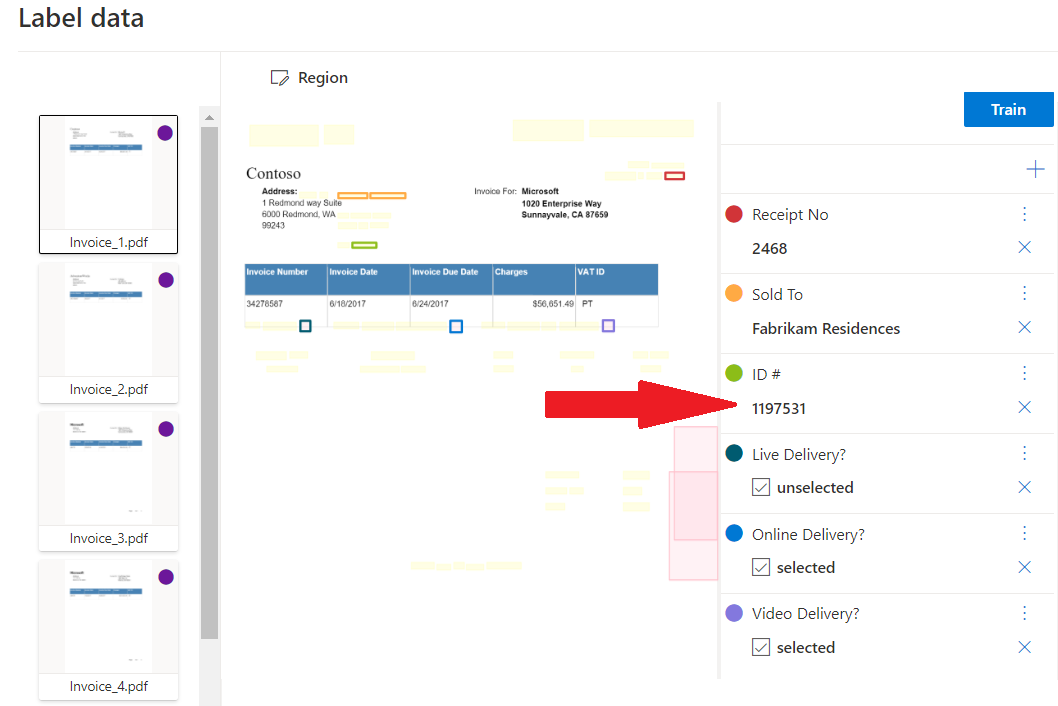
Egyéni kinyerés

Az egyéni extrakciós modell két típus , egyéni sablon vagy egyéni neurális modell egyike lehet. Egyéni kinyerési modell létrehozásához címkézzen fel egy dokumentum adathalmazát a kinyerni kívánt értékekkel, és tanítsa be a modellt a címkézett adathalmazra. Az első lépésekhez csak öt, azonos űrlap- vagy dokumentumtípusú példára van szüksége.
Minta egyéni kinyerés a Document Intelligence Studióval feldolgozva:

Egyéni osztályozó

Az egyéni besorolási modell lehetővé teszi a dokumentumtípus azonosítását a kinyerési modell meghívása előtt. A besorolási modell az API-tól 2023-07-31 (GA) kezdve érhető el. Az egyéni besorolási modellek betanításához osztályonként legalább két különböző osztályra és legalább öt mintára van szükség.
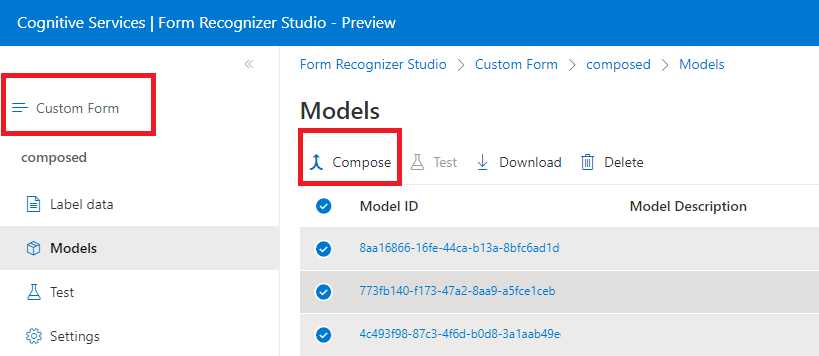
Összeállított modellek
A rendszer úgy hoz létre egy összeállított modellt, hogy egyéni modellek gyűjteményét veszi fel, és egyetlen, az űrlaptípusokból készült modellhez rendeli őket. Több egyéni modellt is hozzárendelhet egy egyetlen modellazonosítóval rendelkező, komponált modellhez. Egyetlen összeállított modellhez legfeljebb 200 betanított egyéni modellt rendelhet.
A Modell összeállítása párbeszédpanel ablaka a Document Intelligence Studióban:
Bemeneti követelmények
A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
Támogatott fájlformátumok:
Modell PDF Kép:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) és HTMLOlvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ (2024-02-29-preview) PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) és 4 MB az ingyenes (F0) szint esetén.
A képméreteknek 50 x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk (DPI) pont szövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete sablonmodell esetén 50 MB, a neurális modell esetében pedig 1G-MB.
Egyéni besorolási modell betanítása esetén a betanítási adatok
1GBteljes mérete legfeljebb 10 000 oldal lehet.
Feljegyzés
A Mintacímke eszköz nem támogatja a BMP fájlformátumot. Ez nem a Dokumentumintelligencia-szolgáltatás, hanem az eszköz korlátozása.
Verziómigrálás
A Document Intelligence v3.1 migrálási útmutatóját követve megtudhatja, hogyan használhatja a Document Intelligence 3.0-s verziót az alkalmazásokban
| Modell | Leírás |
|---|---|
| Dokumentumelemzés | |
| Elrendezés | Szöveg- és elrendezésinformációk kinyerve a dokumentumokból. |
| Előre elkészített | |
| Számla | Kulcsinformációk kinyerése angol és spanyol számlákból. |
| Beérkezési | Kulcsinformációk kinyerése az angol nyugtákból. |
| Személyazonosító okmányok | Kulcsinformációk kinyerése amerikai jogosítványokból és nemzetközi útlevelekből. |
| Névjegykártya | Kulcsinformációk kinyerése angol névjegykártyákból. |
| Szokás | |
| Szokás | Adatokat nyerhet ki a vállalkozásához tartozó űrlapokból és dokumentumokból. Az egyéni modellek be vannak tanítva a különböző adatokhoz és használati esetekhez. |
| Áll | Egyéni modellek gyűjteményének összeállítása és hozzárendelése egyetlen, az űrlaptípusokból készült modellhez. |
Elrendezés
Az Layout API szövegeket, táblázatokat és fejléceket, kijelölési jeleket és szerkezetadatokat elemez és nyer ki a dokumentumokból.
Mintadokumentum a Mintacímkézés eszközzel feldolgozva:
Számla
A számlamodell elemzi és kinyeri a kulcsadatokat az értékesítési számlákból. Az API különböző formátumban elemzi a számlákat, és kinyeri a legfontosabb információkat, például az ügyfél nevét, a számlázási címet, a határidőt és a fizetendő összeget.
Mintaszámlák feldolgozása a Mintacímkézés eszközzel:
Nyugta
- A nyugtamodell elemzi és kinyeri a kulcsadatokat a nyomtatott és kézzel írt értékesítési nyugtákból.
Minta visszaigazolása a Mintacímkézés eszközzel feldolgozva:
Személyazonosító okmányok
Az azonosító dokumentummodell elemzi és kinyeri a legfontosabb információkat a következő dokumentumokból:
Amerikai jogosítványok (mind az 50 állam és Columbia kerület)
Életrajzi oldalak nemzetközi útlevélből (a vízum és egyéb úti okmányok kivételével). Az API elemzi az identitásdokumentumokat és kinyeri azokat
A mintacímkézési eszközzel feldolgozott egyesült államokbeli illesztőprogram-licencminta:
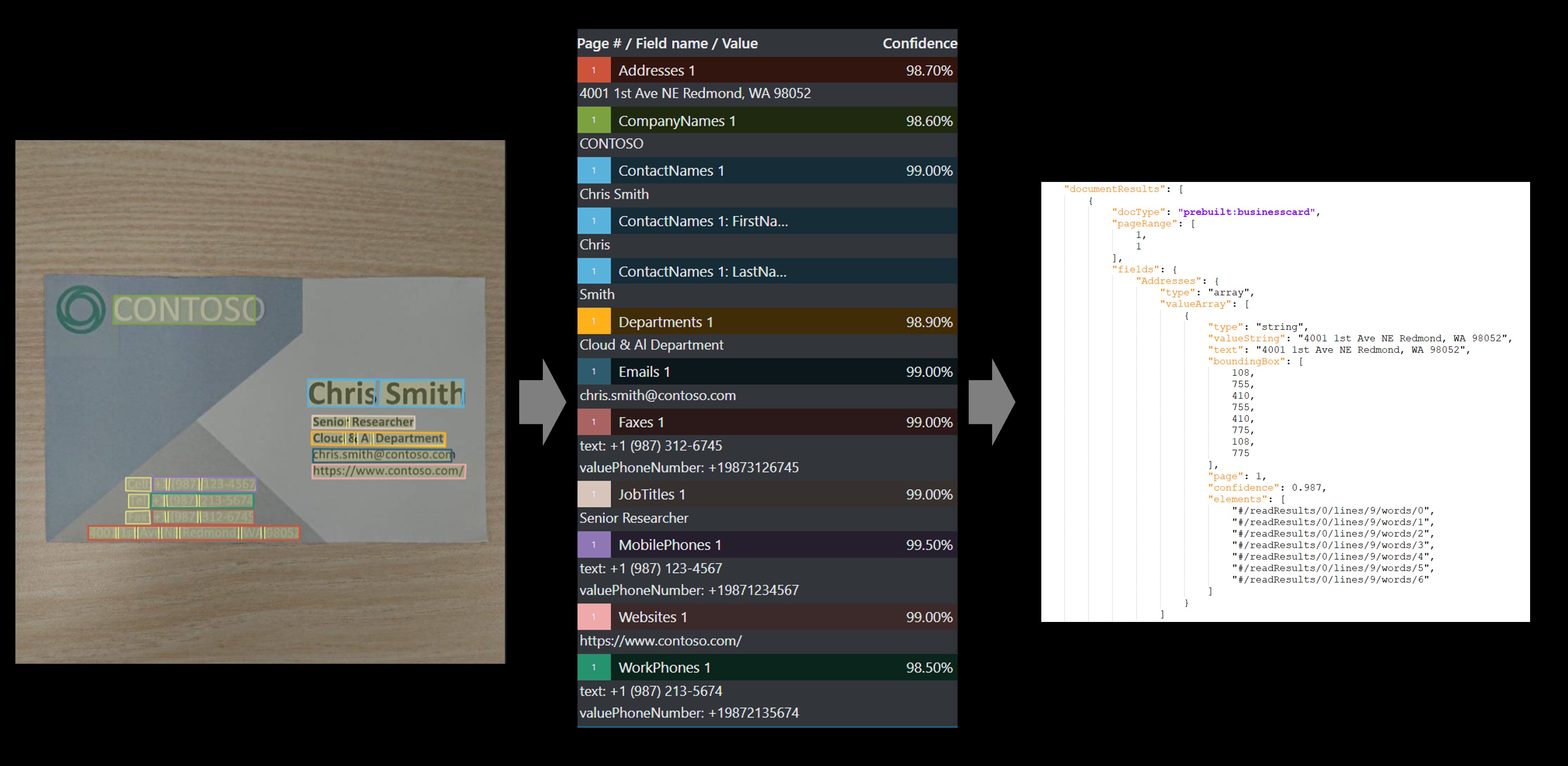
Névjegykártya
A névjegykártya-modell elemzi és kinyeri a névjegykártya-rendszerképek legfontosabb információit.
Minta névjegykártya a Mintacímkézés eszközzel:
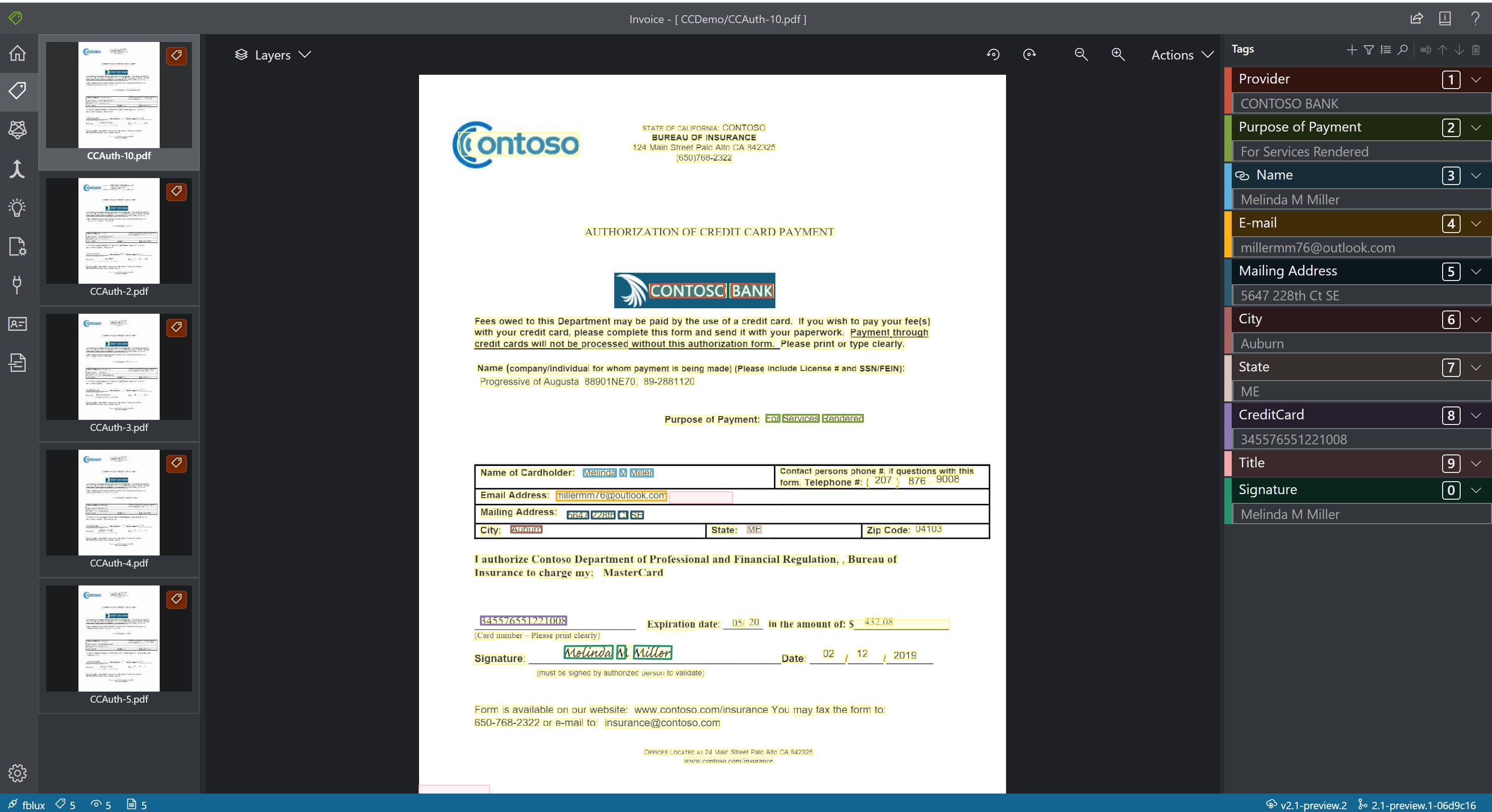
Egyéni
- Az egyéni modellek a vállalatra jellemző űrlapokból és dokumentumokból elemzik és nyerik ki az adatokat. Az API egy gépi tanulási program, amely betanított a különböző tartalmak űrlapmezőinek felismerésére, valamint kulcs-érték párok és táblaadatok kinyerésére. Az első lépésekhez csak öt, azonos típusú példára van szüksége, és az egyéni modell címkézett adatkészletekkel vagy anélkül is betanított.
Minta egyéni modellfeldolgozás a Mintacímkézés eszközzel:
Összeállított egyéni modell
A rendszer úgy hoz létre egy összeállított modellt, hogy egyéni modellek gyűjteményét veszi fel, és egyetlen, az űrlaptípusokból készült modellhez rendeli őket. Több egyéni modellt is hozzárendelhet egy egyetlen modellazonosítóval rendelkező, komponált modellhez. Akár 100 betanított egyéni modellt is hozzárendelhet egyetlen összeállított modellhez.
A Modell összeállítása párbeszédpanel ablaka a Mintacímkézés eszközzel:
Modelladatok kinyerése
| Modell | Szöveg kinyerése | Nyelvfelismerés | Kijelölési jelek | Táblák | Bekezdések | Bekezdésszerepkörök | Kulcs-érték párok | Mezők |
|---|---|---|---|---|---|---|---|---|
| Elrendezés | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Számla | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Beérkezési | ✓ | ✓ | ✓ | |||||
| Azonosító dokumentum | ✓ | ✓ | ✓ | |||||
| Névjegykártya | ✓ | ✓ | ✓ | |||||
| Egyéni űrlap | ✓ | ✓ | ✓ | ✓ | ✓ |
Bemeneti követelmények
A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
Támogatott fájlformátumok:
Modell PDF Kép:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) és HTMLOlvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ (2024-02-29-preview) PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) és 4 MB az ingyenes (F0) szint esetén.
A képméreteknek 50 x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk (DPI) pont szövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete sablonmodell esetén 50 MB, a neurális modell esetében pedig 1G-MB.
Egyéni besorolási modell betanítása esetén a betanítási adatok
1GBteljes mérete legfeljebb 10 000 oldal lehet.
Feljegyzés
A Mintacímke eszköz nem támogatja a BMP fájlformátumot. Ez nem a Dokumentumintelligencia-szolgáltatás, hanem az eszköz korlátozása.
Verziómigrálás
A Document Intelligence v3.1 migrálási útmutatóját követve megtudhatja, hogyan használhatja a Document Intelligence 3.0-s verziót az alkalmazásokban
Következő lépések
Próbálja meg feldolgozni saját űrlapjait és dokumentumait a Document Intelligence Studióval.
Végezze el a Dokumentumintelligencia rövid útmutatóját , és kezdje el létrehozni egy dokumentumfeldolgozó alkalmazást a választott fejlesztési nyelven.
Próbálja meg feldolgozni saját űrlapjait és dokumentumait a Dokumentumintelligencia mintacímkéző eszközzel.
Végezze el a Dokumentumintelligencia rövid útmutatóját , és kezdje el létrehozni egy dokumentumfeldolgozó alkalmazást a választott fejlesztési nyelven.