Dokumentumintelligencia-olvasási modell
Fontos
- A Document Intelligence nyilvános előzetes verziójú kiadásai korai hozzáférést biztosítanak az aktív fejlesztés alatt lévő funkciókhoz.
- A funkciók, a megközelítések és a folyamatok az általános rendelkezésre állás (GA) előtt változhatnak a felhasználói visszajelzések alapján.
- A Document Intelligence ügyfélkódtárak nyilvános előzetes verziója alapértelmezés szerint a REST API 2024-02-29-preview verziója.
- A nyilvános előzetes verzió 2024-02-29 előzetes verziója jelenleg csak a következő Azure-régiókban érhető el:
- USA keleti régiója
- USA2 nyugati régiója
- Nyugat-Európa
Ez a tartalom a következőre vonatkozik::![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Ez a tartalom a következőre vonatkozik::![]() v3.1 (GA) | Legújabb verzió:
v3.1 (GA) | Legújabb verzió:![]() v4.0 (előzetes verzió) | Korábbi verziók:
v4.0 (előzetes verzió) | Korábbi verziók:![]() v3.0
v3.0
Ez a tartalom a következőre vonatkozik::![]() v3.0 (GA) | Legújabb verziók:
v3.0 (GA) | Legújabb verziók:![]() v4.0 (előzetes verzió)
v4.0 (előzetes verzió)![]() v3.1
v3.1
Feljegyzés
Ha szöveget szeretne kinyerni külső képekből, például címkékből, utcatáblákból és plakátokból, használja az Azure AI Image Analysis v4.0 Olvasás funkcióját, amely általános, nem dokumentumalapú képekhez van optimalizálva egy teljesítmény-továbbfejlesztett szinkron API-val, amely megkönnyíti az OCR beágyazását a felhasználói élmény forgatókönyveibe.
A Dokumentumintelligencia olvasási optikai karakterfelismerési (OCR) modell nagyobb felbontásban fut, mint az Azure AI Vision Read, és kinyomtatja és kézzel írt szöveget nyer ki PDF-dokumentumokból és beolvasott képekből. Emellett támogatja a Microsoft Word-, Excel-, PowerPoint- és HTML-dokumentumokból történő szövegkigyűjtést is. Észleli a bekezdéseket, szövegsorokat, szavakat, helyeket és nyelveket. Az olvasási modell a dokumentumintelligencia egyéb előre összeállított modelljeinek (például az Elrendezés, Az Általános dokumentum, a Számla, a Nyugta, az Identitás (ID) dokumentum, az Állapotbiztosítási kártya és a W2 alapjául szolgáló OCR-motor az egyéni modelleken kívül.
Mi az OCR a dokumentumokhoz?
A dokumentumok optikai karakterfelismerése (OCR) több fájlformátumban és globális nyelven nagy méretű, szövegigényes dokumentumokhoz van optimalizálva. Olyan funkciókat tartalmaz, mint a dokumentumképek nagyobb felbontású vizsgálata a kisebb és sűrűbb szövegek jobb kezelése érdekében; bekezdésészlelés; és kitölthető űrlapkezelés. Az OCR-képességek olyan speciális forgatókönyveket is tartalmaznak, mint az egykarakterek, valamint a számlákban, nyugtákban és egyéb előre összeállított forgatókönyvekben gyakran használt kulcsmezők pontos kinyerése.
Fejlesztési lehetőségek
A Document Intelligence v4.0 (2024-02-29-preview, 2023-10-31-preview) a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források | Modellazonosító |
|---|---|---|
| OCR-modell olvasása | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
előre összeállított olvasás |
A Document Intelligence v3.1 a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források | Modellazonosító |
|---|---|---|
| OCR-modell olvasása | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
előre összeállított olvasás |
A Document Intelligence 3.0-s verzió a következő eszközöket, alkalmazásokat és kódtárakat támogatja:
| Szolgáltatás | Források | Modellazonosító |
|---|---|---|
| OCR-modell olvasása | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
előre összeállított olvasás |
Bemeneti követelmények
A legjobb eredmény érdekében dokumentumonként egy tiszta fényképet vagy kiváló minőségű vizsgálatot biztosít.
Támogatott fájlformátumok:
Modell PDF Kép:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) és HTMLOlvasás ✔ ✔ ✔ Elrendezés ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Általános dokumentum ✔ ✔ Előre összeállított ✔ ✔ Egyéni kinyerés ✔ ✔ Egyéni besorolás ✔ ✔ ✔ (2024-02-29-preview) PDF és TIFF esetén legfeljebb 2000 oldal dolgozható fel (ingyenes szintű előfizetéssel csak az első két oldal dolgozható fel).
A dokumentumok elemzéséhez használt fájlméret 500 MB a fizetős (S0) és 4 MB az ingyenes (F0) szint esetén.
A képméreteknek 50 x 50 képpont és 10 000 képpont x 10 000 képpont között kell lenniük.
Ha a PDF-eket jelszó védi, akkor beküldés előtt el kell távolítania a védelmet.
A kinyerni kívánt szöveg minimális magassága 12 képpont egy 1024 x 768 képpontos képhez. Ez a dimenzió körülbelül
8150 pont/hüvelyk (DPI) pont szövegnek felel meg.Egyéni modell betanítása esetén a betanítási adatok oldalainak maximális száma az egyéni sablonmodell esetében 500, az egyéni neurális modell esetében pedig 50 000.
Egyéni extrakciós modell betanítása esetén a betanítási adatok teljes mérete sablonmodell esetén 50 MB, a neurális modell esetében pedig 1G-MB.
Egyéni besorolási modell betanítása esetén a betanítási adatok
1GBteljes mérete legfeljebb 10 000 oldal lehet.
Ismerkedés az olvasási modellel
Próbáljon meg szöveget kinyerni űrlapokból és dokumentumokból a Document Intelligence Studióval. A következő eszközökre van szüksége:
Azure-előfizetés – ingyenesen létrehozhat egyet.
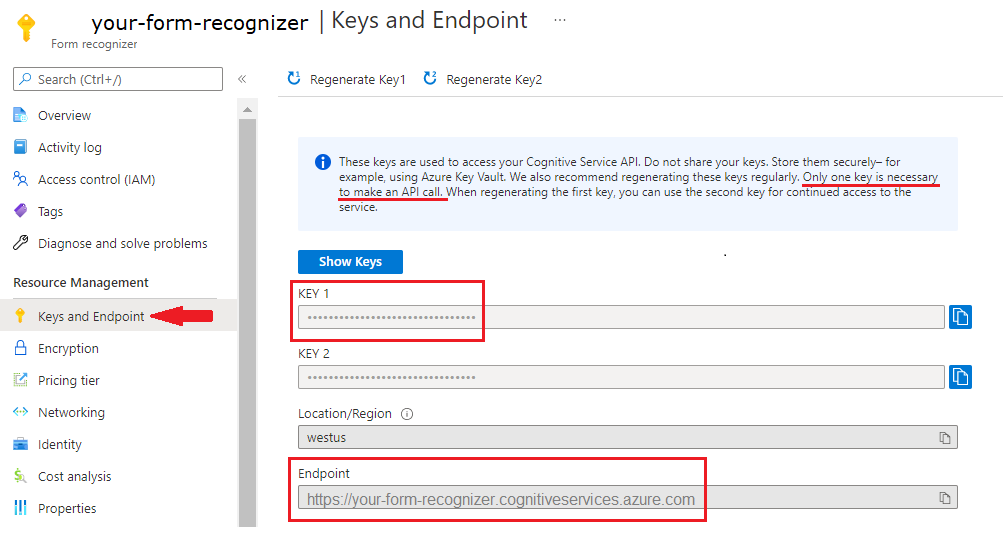
Dokumentumintelligencia-példány az Azure Portalon. A szolgáltatás kipróbálásához használhatja az ingyenes tarifacsomagot (
F0). Az erőforrás üzembe helyezése után válassza az Ugrás az erőforráshoz lehetőséget a kulcs és a végpont lekéréséhez.
Feljegyzés
A Document Intelligence Studio jelenleg nem támogatja a Microsoft Word, Excel, PowerPoint és HTML fájlformátumokat.
A Document Intelligence Studióval feldolgozott mintadokumentum
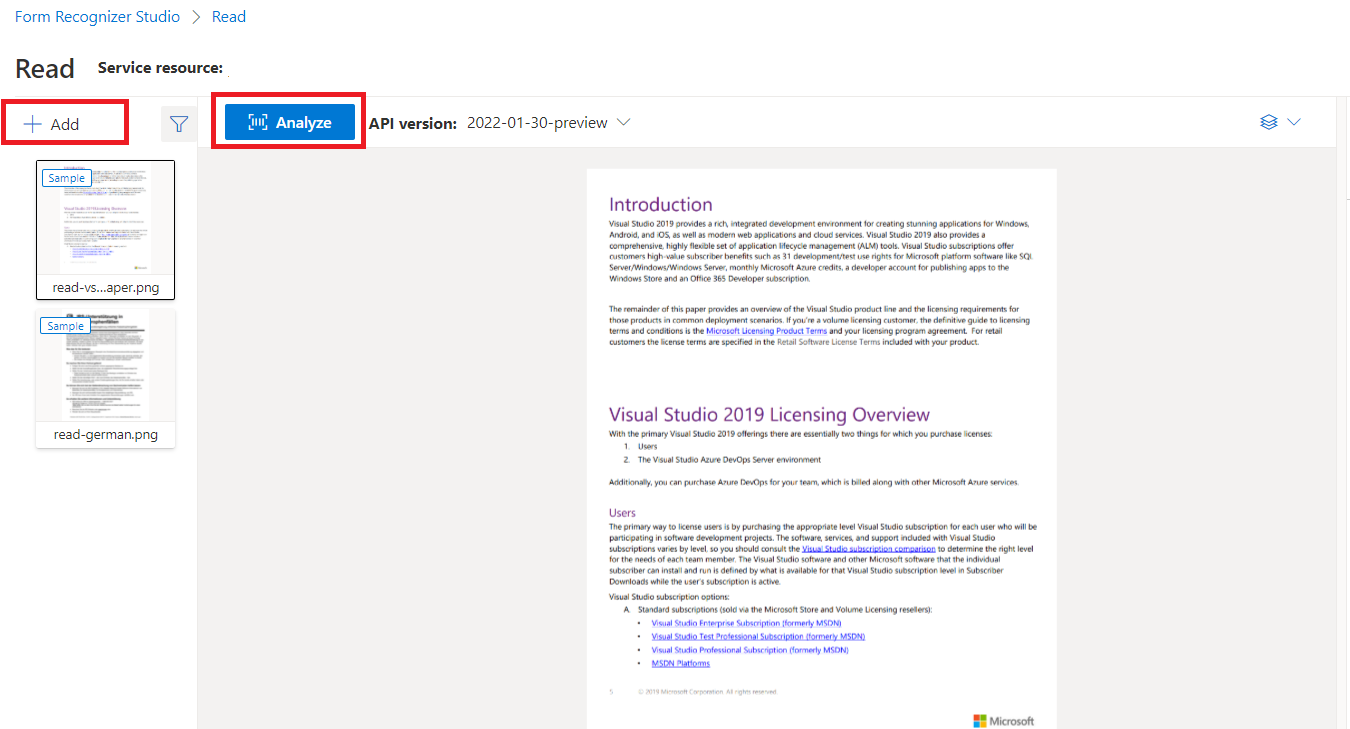
A Document Intelligence Studio kezdőlapján válassza az Olvasás lehetőséget.
Elemezheti a mintadokumentumot, vagy feltöltheti saját fájljait.
Válassza az Elemzés futtatása gombot, és szükség esetén konfigurálja az Elemzési beállításokat:

Támogatott nyelvek és területi beállítások
A támogatott nyelvek teljes listáját a Nyelvi támogatás – dokumentumelemzési modellek oldalon találja.
Adatkinyerés
Feljegyzés
A Microsoft Word- és HTML-fájlokat a 3.1-s és újabb verziók támogatják. A PDF-hez és a képekhez képest az alábbi funkciók nem támogatottak:
- Nincs szög, szélesség/magasság és egység az egyes oldalobjektumokkal.
- Minden észlelt objektum esetében nincs határoló sokszög vagy határoló régió.
- Az oldaltartomány (
pages) paraméterként nem támogatott. - Nincs
linesobjektum.
Oldalak
A lapgyűjtemény a dokumentum lapjainak listája. Minden oldal egymás után jelenik meg a dokumentumban, és tartalmazza a tájolási szöget, amely azt jelzi, hogy az oldal elforgatva van-e, valamint a szélességet és a magasságot (képpontban megadott méretek). A modell kimenetének oldalegységei az alábbi módon lesznek kiszámítva:
| Fájlformátum | Számított oldalegység | Összes oldal |
|---|---|---|
| Képek (JPEG/JPG, PNG, BMP, HEIF) | Minden kép = 1 oldalegység | Összes kép |
| A PDF minden oldala = 1 oldalegység | A PDF összes oldala | |
| TIFF | A TIFF minden képe = 1 oldal | Összes kép a TIFF-ben |
| Word (DOCX) | Legfeljebb 3000 karakter = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Legfeljebb 3000 karakter hosszúságú oldalak összesen |
| Excel (XLSX) | Minden munkalap = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Munkalapok összesen |
| PowerPoint (PPTX) | Minden dia = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Összes dia |
| HTML | Legfeljebb 3000 karakter = 1 oldalegység, beágyazott vagy csatolt képek nem támogatottak | Legfeljebb 3000 karakter hosszúságú oldalak összesen |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
Oldalak kijelölése szövegkinyeréshez
Nagyméretű, többoldalas PDF-dokumentumok esetén a pages lekérdezési paraméterrel konkrét oldalszámokat vagy oldaltartományokat jelölhet a szöveg kinyeréséhez.
Bekezdések
A Dokumentumintelligencia olvasási OCR-modellje a gyűjteményben lévő összes azonosított szövegblokkot legfelső szintű objektumként analyzeResultsnyeri ki.paragraphs A gyűjtemény minden bejegyzése egy szövegblokkot jelöl, és tartalmazza a kinyert szöveget éscontent a határoló polygon koordinátákat. Az span információk a dokumentum teljes szövegét tartalmazó legfelső szintű content tulajdonság szövegtöredékére mutatnak.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Szöveg, sorok és szavak
A Read OCR modell kinyeri a nyomtatási és a kézzel írt stílusszöveget.lineswords A modell a koordinátákat és confidence a kinyert szavakat adja polygon ki. A styles gyűjtemény tartalmaz minden kézzel írt stílust a vonalakhoz, ha észlelik, valamint a társított szövegre mutató spanokat. Ez a funkció a támogatott kézzel írt nyelvekre vonatkozik.
A Microsoft Word, Az Excel, a PowerPoint és a HTML esetében a Dokumentumintelligencia-olvasási modell 3.1-s és újabb verziói az összes beágyazott szöveget kinyerik. A szövegek szavakként és bekezdésekként vannak extratolva. A beágyazott képek nem támogatottak.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Kézzel írt stílus szövegsorokhoz
A válasz magában foglalja annak besorolását, hogy az egyes szövegsorok kézírásstílusúak-e vagy sem, valamint egy megbízhatósági pontszámot. További információ: kézzel írt nyelvi támogatás. Az alábbi példa egy JSON-kódrészletet mutat be.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Ha engedélyezte a betűtípus-/stílus hozzáadása funkciót, az objektum részeként is megkapja a styles betűtípus/stílus eredményét.
Következő lépések
Végezze el a dokumentumintelligencia gyorsútmutatóját:
Ismerkedjen meg a REST API-val: