Gyorsítótárazási útmutató
A gyorsítótárazás egy gyakran alkalmazott módszer, amelynek célja egy rendszer teljesítményének és méretezhetőségének javítása. Úgy gyorsítótárazza az adatokat, hogy ideiglenesen átmásolja a gyakran használt adatokat az alkalmazás közelében található gyors tárolóba. Ha ez a gyors adattároló közelebb van az alkalmazáshoz, mint az eredeti forrás, akkor a gyorsabb adatkiszolgálás révén a gyorsítótárazással lényegesen javítható az ügyfélalkalmazások válaszideje.
A gyorsítótárazás akkor a leghatékonyabb, ha egy ügyfélpéldány ismételten beolvassa ugyanazokat az adatokat, különösen akkor, ha az alábbi feltételek az eredeti adattárra vonatkoznak:
- Viszonylag statikus marad.
- A gyorsítótár sebességéhez képest lassú.
- Magas szintű versengésnek van kitéve.
- Messze van, amikor a hálózati késés lassú hozzáférést okozhat.
Gyorsítótárazás elosztott alkalmazásokban
Az elosztott alkalmazások általában az alábbi stratégiák valamelyikét vagy mindkettőt implementálják az adatok gyorsítótárazásakor:
- Privát gyorsítótárat használnak, ahol az adatok helyben vannak tárolva azon a számítógépen, amelyen egy alkalmazás vagy szolgáltatás egy példánya fut.
- Megosztott gyorsítótárat használnak, amely közös forrásként szolgál, amelyet több folyamat és gép is elérhet.
Mindkét esetben a gyorsítótárazás elvégezhető ügyféloldalon és kiszolgálóoldalon is. Az ügyféloldali gyorsítótárazást az a folyamat végzi, amely a rendszer felhasználói felületét biztosítja, például webböngészőt vagy asztali alkalmazást. A kiszolgálóoldali gyorsítótárazást a távolról futó üzleti szolgáltatásokat biztosító folyamat végzi.
Privát gyorsítótárazás
A gyorsítótár legalapvetőbb típusa egy memóriabeli tároló. Egyetlen folyamat címterében van tárolva, és közvetlenül az abban a folyamatban futó kód fér hozzá. Ez a gyorsítótártípus gyorsan elérhető. Emellett hatékony eszköz lehet a statikus adatok szerény mennyiségének tárolására is. A gyorsítótár méretét általában a folyamatot üzemeltető gépen rendelkezésre álló memória korlátozza.
Ha a memóriában fizikailag lehetségesnél több információt kell gyorsítótáraznia, a gyorsítótárazott adatokat a helyi fájlrendszerbe is írhatja. Ez a folyamat lassabban fog hozzáférni, mint a memóriában tárolt adatokhoz, de még mindig gyorsabbnak és megbízhatóbbnak kell lennie, mint a hálózaton keresztüli adatok lekérése.
Ha több olyan alkalmazáspéldánya van, amely egyidejűleg használja ezt a modellt, minden alkalmazáspéldány saját független gyorsítótárral rendelkezik, amely az adatok saját másolatát tartalmazza.
A gyorsítótárat az eredeti adatok pillanatképének tekinti a múlt egy bizonyos pontján. Ha ezek az adatok nem statikusak, akkor valószínű, hogy a különböző alkalmazáspéldányok az adatok különböző verzióit használják a gyorsítótáraikban. Ezért az ilyen példányok által végrehajtott lekérdezések eltérő eredményeket adhatnak vissza az 1. ábrán látható módon.
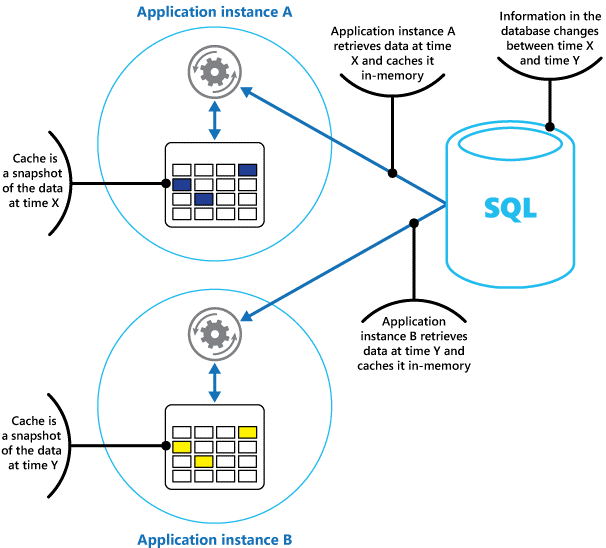
1. ábra: Memóriabeli gyorsítótár használata egy alkalmazás különböző példányaiban.
Megosztott gyorsítótárazás
Megosztott gyorsítótár használata esetén enyhítheti azokat az aggodalmakat, amelyek szerint az adatok az egyes gyorsítótárakban eltérhetnek, ami memóriabeli gyorsítótárazással is előfordulhat. A megosztott gyorsítótárazás biztosítja, hogy a különböző alkalmazáspéldányok ugyanazt a nézetet lássák a gyorsítótárazott adatokról. A gyorsítótárat egy külön helyen találja, amely általában egy külön szolgáltatás részeként van üzemeltetve, a 2. ábrán látható módon.
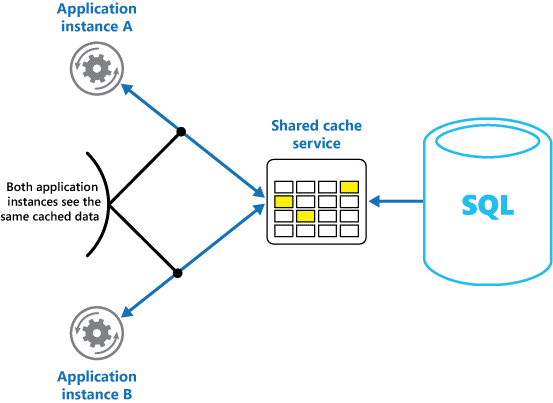
2. ábra: Megosztott gyorsítótár használata.
A megosztott gyorsítótárazási módszer egyik fontos előnye a méretezhetőség, amelyet biztosít. Számos megosztott gyorsítótár-szolgáltatás egy kiszolgálófürt használatával valósul meg, és szoftverrel osztja el az adatokat a fürtben transzparens módon. Az alkalmazáspéldányok egyszerűen küldenek egy kérést a gyorsítótár-szolgáltatásnak. A mögöttes infrastruktúra határozza meg a gyorsítótárazott adatok helyét a fürtben. A gyorsítótárat egyszerűen skálázhatja további kiszolgálók hozzáadásával.
A megosztott gyorsítótárazási módszernek két fő hátránya van:
- A gyorsítótár lassabban érhető el, mert már nincs helyileg tárolva az egyes alkalmazáspéldányok számára.
- A különálló gyorsítótár-szolgáltatás implementálásának követelménye összetettebbé teheti a megoldást.
A gyorsítótárazás használatának szempontjai
A következő szakaszok részletesebben ismertetik a gyorsítótár tervezésének és használatának szempontjait.
Döntse el, mikor gyorsítótárazza az adatokat
A gyorsítótárazás jelentősen javíthatja a teljesítményt, a méretezhetőséget és a rendelkezésre állást. Minél több adata van, és minél több felhasználónak kell hozzáférnie ezekhez az adatokhoz, annál nagyobb lesz a gyorsítótárazás előnyei. A gyorsítótárazás csökkenti az eredeti adattárban nagy mennyiségű egyidejű kérés kezeléséhez kapcsolódó késést és versengést.
Előfordulhat például, hogy egy adatbázis csak korlátozott számú egyidejű kapcsolatot támogat. A megosztott gyorsítótárból származó adatok lekérése azonban a mögöttes adatbázis helyett lehetővé teszi, hogy az ügyfélalkalmazások akkor is hozzáférhessenek ezekhez az adatokhoz, ha az elérhető kapcsolatok száma jelenleg kimerült. Emellett ha az adatbázis elérhetetlenné válik, előfordulhat, hogy az ügyfélalkalmazások a gyorsítótárban tárolt adatok használatával folytathatják a munkát.
Fontolja meg a gyakran olvasott, de ritkán módosított adatok gyorsítótárazását (például az írási műveleteknél nagyobb arányú olvasási műveleteket tartalmazó adatokat). Azonban nem javasoljuk, hogy a gyorsítótárat használja a kritikus információk mérvadó tárolójaként. Ehelyett győződjön meg arról, hogy minden olyan módosítást, amelyet az alkalmazás nem engedhet meg magának, mindig egy állandó adattárba menti. Ha a gyorsítótár nem érhető el, az alkalmazás továbbra is használhatja az adattárat, és nem veszít fontos információkat.
Az adatok hatékony gyorsítótárazási módjának meghatározása
A gyorsítótár hatékony használatának kulcsa a gyorsítótárazáshoz legmegfelelőbb adatok meghatározásában és a gyorsítótárazás megfelelő időben történő gyorsítótáraztatásában rejlik. Az adatok igény szerint hozzáadhatók a gyorsítótárhoz az alkalmazás első lekérésekor. Az alkalmazásnak csak egyszer kell lekérnie az adatokat az adattárból, és hogy a későbbi hozzáférés a gyorsítótár használatával kielégíthető.
Másik lehetőségként a gyorsítótárat előre részben vagy teljesen feltöltheti adatokkal, jellemzően az alkalmazás indításakor (ez az úgynevezett magvetési módszer). Előfordulhat azonban, hogy nem tanácsos magvetést implementálni egy nagy gyorsítótár esetében, mert ez a megközelítés hirtelen, nagy terhelést okozhat az eredeti adattárra, amikor az alkalmazás elindul.
A használati minták elemzése gyakran segíthet eldönteni, hogy teljes mértékben vagy részben előre feltölti-e a gyorsítótárat, és kiválasztja a gyorsítótárazandó adatokat. A gyorsítótárat például a statikus felhasználói profil adataival helyezheti el az alkalmazás rendszeresen (talán minden nap) használó ügyfelek számára, de azokat az ügyfeleket nem, akik hetente csak egyszer használják az alkalmazást.
A gyorsítótárazás általában jól működik az olyan adatokkal, amelyek nem módosíthatók vagy ritkán változnak. Ilyenek például a referenciaadatok, például az e-kereskedelmi alkalmazások termék- és díjszabási információi, vagy a megosztott statikus erőforrások, amelyek létrehozása költséges. Az adatok egy része vagy mindegyike betölthető a gyorsítótárba az alkalmazás indításakor az erőforrások iránti kereslet minimalizálása és a teljesítmény javítása érdekében. Érdemes lehet olyan háttérfolyamatot is használnia, amely rendszeres időközönként frissíti a gyorsítótár hivatkozási adatait, hogy biztosan up-to-date legyen. Vagy a háttérfolyamat frissítheti a gyorsítótárat, amikor a referenciaadatok megváltoznak.
A gyorsítótárazás kevésbé hasznos a dinamikus adatok esetében, bár van néhány kivétel ebben a megfontolásban (további információt a jelen cikk későbbi, rendkívül dinamikus adatok gyorsítótárazása című szakaszában talál). Amikor az eredeti adatok rendszeresen változnak, a gyorsítótárazott adatok gyorsan elavulttá válnak, vagy a gyorsítótár és az eredeti adattár szinkronizálásának többletterhelése csökkenti a gyorsítótárazás hatékonyságát.
A gyorsítótárnak nem kell tartalmaznia egy entitás teljes adatait. Ha például egy adatelem többértékű objektumot jelöl, például egy banki ügyfelet névvel, címmel és számlaegyenleggel, ezek némelyike statikus marad, például a név és a cím. Más elemek, például a számlaegyenleg dinamikusabbak lehetnek. Ilyen esetekben hasznos lehet az adatok statikus részeinek gyorsítótárazása, és szükség esetén csak a fennmaradó információk lekérése (vagy kiszámítása).
Javasoljuk, hogy végezzen teljesítménytesztelést és használatelemzést annak megállapításához, hogy a gyorsítótár előre feltöltődése vagy igény szerinti betöltése, vagy mindkettő kombinációja megfelelő-e. A döntésnek az adatok változékonyságán és használati mintáján kell alapulnia. A gyorsítótár-kihasználtság és a teljesítményelemzés fontos azokban az alkalmazásokban, amelyek nagy terhelést tapasztalnak, és nagy mértékben méretezhetőnek kell lenniük. Nagy mértékben skálázható forgatókönyvekben például a gyorsítótárat is ki lehet szórni, hogy a csúcsidőkben csökkentse az adattár terhelését.
A gyorsítótárazással elkerülheti a számítások ismétlését az alkalmazás futása közben. Ha egy művelet átalakítja az adatokat, vagy bonyolult számítást végez, mentheti a művelet eredményeit a gyorsítótárban. Ha később ugyanez a számítás szükséges, az alkalmazás egyszerűen lekérheti az eredményeket a gyorsítótárból.
Az alkalmazások módosíthatják a gyorsítótárban tárolt adatokat. Javasoljuk azonban, hogy a gyorsítótárat átmeneti adattárként képzelje el, amely bármikor eltűnhet. Ne csak a gyorsítótárban tárolja az értékes adatokat; győződjön meg arról, hogy az eredeti adattárban is megőrzi az adatokat. Ez azt jelenti, hogy ha a gyorsítótár elérhetetlenné válik, minimálisra csökkenti az adatok elvesztésének esélyét.
Rendkívül dinamikus adatok gyorsítótárazva
Ha gyorsan változó információkat tárol egy állandó adattárban, az többletterhelést okozhat a rendszeren. Vegyük például azt az eszközt, amely folyamatosan jelenti az állapotot vagy más méréseket. Ha egy alkalmazás úgy dönt, hogy nem gyorsítótárazza ezeket az adatokat azon az alapon, hogy a gyorsítótárazott információk szinte mindig elavultak lesznek, ugyanez a szempont igaz lehet az adatok adattárból való tárolásakor és lekérésekor. Az adatok mentése és beolvasása során előfordulhat, hogy módosult.
Ilyen helyzetben fontolja meg a dinamikus információk gyorsítótárban való tárolásának előnyeit az állandó adattár helyett. Ha az adatok nem kritikusak, és nem igényel naplózást, akkor nem számít, hogy az alkalmi módosítás elveszik-e.
Az adatok lejáratának kezelése gyorsítótárban
A legtöbb esetben a gyorsítótárban tárolt adatok az eredeti adattárban tárolt adatok másolatai. Az eredeti adattár adatai a gyorsítótárazás után változhatnak, ami miatt a gyorsítótárazott adatok elavulttá válhatnak. Számos gyorsítótárazási rendszer lehetővé teszi, hogy a gyorsítótárat úgy konfigurálja, hogy lejárjanak az adatok, és csökkentse azt az időtartamot, amelyre az adatok elavultak lehetnek.
Amikor a gyorsítótárazott adatok lejárnak, a rendszer eltávolítja azokat a gyorsítótárból, és az alkalmazásnak le kell kérnie az adatokat az eredeti adattárból (az újonnan beolvasott adatokat visszateheti a gyorsítótárba). A gyorsítótár konfigurálásakor beállíthatja az alapértelmezett lejárati szabályzatot. Számos gyorsítótár-szolgáltatásban megadhatja az egyes objektumok lejárati idejét is, amikor programozott módon tárolja őket a gyorsítótárban. Egyes gyorsítótárak lehetővé teszik a lejárati időtartam abszolút értékként való megadását, vagy olyan csúsztatási értékként, amely miatt az elem el lesz távolítva a gyorsítótárból, ha az nem érhető el a megadott időn belül. Ez a beállítás felülírja a gyorsítótár-szintű lejárati szabályzatokat, de csak a megadott objektumok esetében.
Megjegyzés:
Vegye figyelembe a gyorsítótár és a benne található objektumok lejárati idejét. Ha túl rövidre teszi, az objektumok túl gyorsan lejárnak, és csökkenti a gyorsítótár használatának előnyeit. Ha túl hosszúra teszi az időszakot, azzal kockáztatja, hogy az adatok elavulttá válnak.
Az is előfordulhat, hogy a gyorsítótár megtelik, ha az adatok hosszú ideig rezidensek maradnak. Ebben az esetben az új elemek gyorsítótárhoz való hozzáadására irányuló kérések egyes elemek kényszerített eltávolítását okozhatják egy kiürítési folyamat során. A gyorsítótárszolgáltatások általában a legkevésbé használt (LRU) alapon távolítják el az adatokat, de általában felülbírálhatja ezt a házirendet, és megakadályozhatja az elemek kizárását. Ha azonban ezt a megközelítést alkalmazza, azzal a kockázattal jár, hogy túllépi a gyorsítótárban elérhető memóriát. Egy olyan alkalmazás, amely egy elemet próbál hozzáadni a gyorsítótárhoz, kivétellel meghiúsul.
Egyes gyorsítótárazási implementációk további kiürítési szabályzatokat biztosíthatnak. A kilakoltatási szabályzatok több típusa is létezik. Ezek a következők:
- A legutóbb használt szabályzat (abban a reményben, hogy az adatokra nem lesz szükség újra).
- Elsőként kifelé irányuló szabályzat (a legrégebbi adatokat a rendszer először kiüríti).
- Egy aktivált eseményen alapuló explicit eltávolítási szabályzat (például a módosított adatok).
Adatok érvénytelenítése ügyféloldali gyorsítótárban
Az ügyféloldali gyorsítótárban tárolt adatok általában azon a szolgáltatáson kívül esőnek minősülnek, amely az adatokat az ügyfél számára biztosítja. A szolgáltatás nem kényszerítheti közvetlenül az ügyfelet arra, hogy adatokat adjon hozzá vagy távolítson el az ügyféloldali gyorsítótárból.
Ez azt jelenti, hogy előfordulhat, hogy egy rosszul konfigurált gyorsítótárat használó ügyfél továbbra is elavult információkat használ. Ha például a gyorsítótár lejárati szabályzatai nincsenek megfelelően implementálva, előfordulhat, hogy az ügyfél elavult információkat használ, amelyek helyileg gyorsítótárazva vannak, amikor az eredeti adatforrás adatai megváltoztak.
Ha http-kapcsolaton keresztül adatokat kiszolgáló webalkalmazást hoz létre, implicit módon kényszerítheti a webügyfeleket (például böngészőt vagy webproxyt) a legfrissebb információk lekérésére. Ezt akkor teheti meg, ha egy erőforrást az erőforrás URI-jának módosítása frissít. A webes ügyfelek általában egy erőforrás URI-ját használják kulcsként az ügyféloldali gyorsítótárban, így ha az URI megváltozik, a webes ügyfél figyelmen kívül hagyja az erőforrás korábban gyorsítótárazott verzióit, és ehelyett lekéri az új verziót.
Egyidejűség kezelése gyorsítótárban
A gyorsítótárakat gyakran úgy tervezték, hogy egy alkalmazás több példánya is megossza. Minden alkalmazáspéldány képes az adatok olvasására és módosítására a gyorsítótárban. Következésképpen a megosztott adattárak esetében felmerülő egyidejűségi problémák a gyorsítótárra is érvényesek. Ha egy alkalmazásnak módosítania kell a gyorsítótárban tárolt adatokat, előfordulhat, hogy gondoskodnia kell arról, hogy az alkalmazás egyik példánya által végrehajtott frissítések ne felülírják a másik példány módosításait.
Az adatok jellegétől és az ütközések valószínűségétől függően az egyidejűség két megközelítése közül választhat:
- Optimista. Közvetlenül az adatok frissítése előtt az alkalmazás ellenőrzi, hogy a gyorsítótárban lévő adatok módosultak-e a lekérés óta. Ha az adatok továbbra is ugyanazok, a módosítás végezhető el. Ellenkező esetben az alkalmazásnak el kell döntenie, hogy frissíti-e. (A döntés alapjául szolgáló üzleti logika alkalmazásspecifikus lesz.) Ez a megközelítés olyan helyzetekre alkalmas, amikor a frissítések ritkán fordulnak elő, vagy ha nem valószínű, hogy ütközések történnek.
- Pesszimista. Amikor lekéri az adatokat, az alkalmazás zárolja azokat a gyorsítótárban, hogy megakadályozza egy másik példány módosítását. Ez a folyamat biztosítja, hogy ütközések ne következhessenek be, de blokkolhatják azokat a példányokat is, amelyeknek ugyanazokat az adatokat kell feldolgozniuk. A pesszimista egyidejűség befolyásolhatja a megoldás méretezhetőségét, és csak rövid élettartamú műveletekhez ajánlott. Ez a megközelítés akkor lehet megfelelő, ha az ütközések nagyobb valószínűséggel történnek, különösen akkor, ha egy alkalmazás több elemet frissít a gyorsítótárban, és gondoskodnia kell arról, hogy ezek a módosítások következetesen legyenek alkalmazva.
Magas rendelkezésre állás és méretezhetőség megvalósítása, valamint a teljesítmény javítása
Kerülje a gyorsítótár használatát az adatok elsődleges adattáraként; ez annak az eredeti adattárnak a szerepe, amelyből a gyorsítótár fel van töltve. Az adatok megőrzésének biztosításáért az eredeti adattár felel.
Ügyeljen arra, hogy ne vezessen be kritikus függőségeket a megosztott gyorsítótár-szolgáltatás rendelkezésre állásától a megoldásokban. Egy alkalmazásnak továbbra is működnie kell, ha a megosztott gyorsítótárat biztosító szolgáltatás nem érhető el. Az alkalmazásnak nem szabad válaszolnia vagy sikertelennek lennie, amíg a gyorsítótár-szolgáltatás folytatására vár.
Ezért az alkalmazásnak készen kell állnia a gyorsítótár szolgáltatás rendelkezésre állásának észlelésére, és vissza kell esnie az eredeti adattárba, ha a gyorsítótár nem érhető el. A Circuit-Breaker minta hasznos a forgatókönyv kezeléséhez. A gyorsítótárat biztosító szolgáltatás helyreállítható, és amint elérhetővé válik, a gyorsítótár újra feltölthető, amint az adatok beolvasva lesznek az eredeti adattárból egy olyan stratégiát követve, mint a gyorsítótár-feltöltési minta.
A rendszer méretezhetőségét azonban befolyásolhatja, ha az alkalmazás visszaesik az eredeti adattárba, amikor a gyorsítótár átmenetileg nem érhető el. Miközben az adattár helyreállítása folyamatban van, az eredeti adattárat eláraszthatja az adatkérések, ami időtúllépéseket és sikertelen kapcsolatokat eredményez.
Fontolja meg egy helyi, privát gyorsítótár implementálását egy alkalmazás minden példányában, valamint azt a megosztott gyorsítótárat, amelyhez az összes alkalmazáspéldány hozzáfér. Amikor az alkalmazás lekér egy elemet, először a helyi gyorsítótárban, majd a megosztott gyorsítótárban, végül pedig az eredeti adattárban ellenőrizheti. A helyi gyorsítótár feltölthető a megosztott gyorsítótárban lévő adatokkal, vagy az adatbázisban, ha a megosztott gyorsítótár nem érhető el.
Ez a megközelítés gondos konfigurálást igényel, hogy a helyi gyorsítótár ne legyen túl elavult a megosztott gyorsítótár tekintetében. A helyi gyorsítótár azonban pufferként működik, ha a megosztott gyorsítótár nem érhető el. A 3. ábrán ez a struktúra látható.

3. ábra: Helyi privát gyorsítótár használata megosztott gyorsítótárral.
A viszonylag hosszú élettartamú adatokat tartalmazó nagy gyorsítótárak támogatásához egyes gyorsítótár-szolgáltatások magas rendelkezésre állási lehetőséget biztosítanak, amely automatikus feladatátvételt valósít meg, ha a gyorsítótár elérhetetlenné válik. Ez a módszer általában az elsődleges gyorsítótár-kiszolgálón tárolt gyorsítótárazott adatok másodlagos gyorsítótár-kiszolgálóra való replikálását, valamint a másodlagos kiszolgálóra való váltást foglalja magában, ha az elsődleges kiszolgáló meghibásodik, vagy megszakad a kapcsolat.
A több célhelyre való írás késésének csökkentése érdekében előfordulhat, hogy a másodlagos kiszolgálóra történő replikáció aszinkron módon történik, amikor az adatok az elsődleges kiszolgálón lévő gyorsítótárba kerülnek. Ez a megközelítés azt a lehetőséget eredményezi, hogy a gyorsítótárban tárolt adatok némelyike elveszhet, ha hiba történik, de az adatok arányának kicsinek kell lennie a gyorsítótár teljes méretéhez képest.
Ha egy megosztott gyorsítótár nagy, hasznos lehet a gyorsítótárazott adatok csomópontok közötti particionálása a versengés esélyének csökkentése és a méretezhetőség javítása érdekében. Számos megosztott gyorsítótár támogatja a csomópontok dinamikus hozzáadását (és eltávolítását) és az adatok partíciók közötti újraegyensúlyozását. Ez a megközelítés magában foglalhatja a fürtözést, amelyben a csomópontok gyűjteménye zökkenőmentes, egyetlen gyorsítótárként jelenik meg az ügyfélalkalmazások számára. Belsőleg azonban az adatok egy előre definiált terjesztési stratégia alapján oszlanak el a csomópontok között, amely egyenletesen egyensúlyozza a terhelést. További információ a lehetséges particionálási stratégiákról: Adatparticionálási útmutató.
A fürtözés a gyorsítótár rendelkezésre állását is növelheti. Ha egy csomópont meghibásodik, a gyorsítótár fennmaradó része továbbra is elérhető. A fürtözést gyakran használják a replikációval és a feladatátvétellel együtt. Minden csomópont replikálható, és a replika gyorsan online állapotba helyezhető, ha a csomópont meghibásodik.
Sok olvasási és írási művelet valószínűleg egyetlen adatértéket vagy objektumot foglal magában. Időnként azonban szükség lehet nagy mennyiségű adat gyors tárolására vagy lekérésére. A gyorsítótár üzembe helyezéséhez például több száz vagy több ezer elem írható a gyorsítótárba. Előfordulhat, hogy egy alkalmazásnak ugyanannak a kérésnek a részeként nagy számú kapcsolódó elemet is le kell kérnie a gyorsítótárból.
Számos nagy méretű gyorsítótár kötegműveleteket biztosít ezekhez a célokhoz. Ez lehetővé teszi, hogy egy ügyfélalkalmazás nagy mennyiségű elemet csomagoljon egyetlen kérelembe, és csökkentse a nagy számú kis kérelem végrehajtásával járó többletterhelést.
Gyorsítótárazás és végleges konzisztencia
A gyorsítótár-feltöltési minta működéséhez a gyorsítótárat feltöltő alkalmazás példányának hozzáféréssel kell rendelkeznie az adatok legújabb és konzisztens verziójához. A végleges konzisztenciát megvalósító rendszerekben (például replikált adattárakban) ez nem feltétlenül így van.
Az alkalmazás egy példánya módosíthatja az adatelemet, és érvénytelenítheti az elem gyorsítótárazott verzióját. Az alkalmazás egy másik példánya megpróbálhatja beolvasni ezt az elemet egy gyorsítótárból, ami gyorsítótár-kihagyást okoz, ezért beolvassa az adatokat az adattárból, és hozzáadja a gyorsítótárhoz. Ha azonban az adattár nem lett teljesen szinkronizálva a többi replikával, az alkalmazáspéldány felolvassa és feltölti a gyorsítótárat a régi értékkel.
Az adatkonzisztencia kezelésével kapcsolatos további információkért tekintse meg az Adatkonzisztencia-alapozót.
Gyorsítótárazott adatok védelme
A használt gyorsítótár-szolgáltatástól függetlenül fontolja meg, hogyan védheti meg a gyorsítótárban tárolt adatokat a jogosulatlan hozzáféréstől. Két fő probléma merül fel:
- A gyorsítótárban lévő adatok bizalmassága.
- A gyorsítótár és a gyorsítótárat használó alkalmazás közötti adatvédelmet.
A gyorsítótárban lévő adatok védelme érdekében a gyorsítótár szolgáltatás olyan hitelesítési mechanizmust implementálhat, amely megköveteli, hogy az alkalmazások a következőket adják meg:
- Mely identitások férhetnek hozzá a gyorsítótárban lévő adatokhoz.
- Mely műveletek (olvasási és írási műveletek) végrehajtására jogosultak ezek az identitások.
Az adatok olvasásával és írásával kapcsolatos többletterhelés csökkentése érdekében, miután egy identitás írási vagy olvasási hozzáférést kapott a gyorsítótárhoz, az identitás bármilyen adatot használhat a gyorsítótárban.
Ha korlátoznia kell a gyorsítótárazott adatok részhalmazaihoz való hozzáférést, tegye az alábbiak egyikét:
- Ossza fel a gyorsítótárat partíciókra (különböző gyorsítótár-kiszolgálók használatával), és csak a használni kívánt partíciók identitásaihoz adjon hozzáférést.
- Az egyes alhalmazokban lévő adatokat különböző kulcsokkal titkosíthatja, és csak azoknak az identitásoknak adja meg a titkosítási kulcsokat, amelyeknek hozzáféréssel kell rendelkezniük az egyes részhalmazokhoz. Előfordulhat, hogy egy ügyfélalkalmazás továbbra is le tudja kérni a gyorsítótárban lévő összes adatot, de csak azokat az adatokat tudja visszafejteni, amelyekhez a kulcsok vannak.
Meg kell védenie az adatokat is, amikor azok a gyorsítótárban és azon kívül áramlik. Ehhez az ügyfélalkalmazások által a gyorsítótárhoz való csatlakozáshoz használt hálózati infrastruktúra által biztosított biztonsági funkcióktól függ. Ha a gyorsítótárat az ügyfélalkalmazásokat üzemeltető szervezeten belül egy helyszíni kiszolgálóval implementálják, akkor előfordulhat, hogy a hálózat elkülönítése nem igényel további lépéseket. Ha a gyorsítótár távolról található, és TCP- vagy HTTP-kapcsolatot igényel egy nyilvános hálózaton keresztül (például az interneten), fontolja meg az SSL implementálását.
A gyorsítótárazás Azure-beli implementálásának szempontjai
Az Azure Cache for Redis a nyílt forráskódú Redis Cache implementációja, amely szolgáltatásként fut egy Azure-adatközpontban. Olyan gyorsítótárazási szolgáltatást biztosít, amely bármely Azure-alkalmazásból elérhető, függetlenül attól, hogy az alkalmazás felhőszolgáltatásként, webhelyként vagy Azure-beli virtuális gépen belül van-e implementálva. A gyorsítótárakat olyan ügyfélalkalmazások oszthatják meg, amelyek rendelkeznek a megfelelő hozzáférési kulccsal.
Az Azure Cache for Redis egy nagy teljesítményű gyorsítótárazási megoldás, amely rendelkezésre állást, méretezhetőséget és biztonságot biztosít. Általában szolgáltatásként fut egy vagy több dedikált gépen. Minél több információt próbál tárolni a memóriában a gyors hozzáférés biztosítása érdekében. Ez az architektúra alacsony késést és magas átviteli sebességet biztosít, mivel csökkenti a lassú I/O-műveletek végrehajtásának szükségességét.
Az Azure Cache for Redis számos, az ügyfélalkalmazások által használt API-val kompatibilis. Ha már rendelkezik olyan alkalmazásokkal, amelyek már a helyszínen futó Azure Cache for Redist használják, az Azure Cache for Redis gyors áttelepítési útvonalat biztosít a felhőbeli gyorsítótárazáshoz.
A Redis funkciói
A Redis több, mint egyszerű gyorsítótár-kiszolgáló. Egy elosztott memórián belüli adatbázist biztosít egy átfogó parancskészlettel, amely számos gyakori forgatókönyvet támogat. Ezeket a dokumentum későbbi, a Redis-gyorsítótárazással foglalkozó szakaszában ismertetjük. Ez a szakasz összefoglalja a Redis néhány fő funkcióját.
Redis mint memóriabeli adatbázis
A Redis támogatja az olvasási és írási műveleteket is. A Redisben az írások védhetők a rendszerhibáktól, ha rendszeres időközönként egy helyi pillanatképfájlban vagy egy csak hozzáfűző naplófájlban tárolják őket. Ez a helyzet nem sok gyorsítótárban fordul elő, amelyet átmeneti adattáraknak kell tekinteni.
Minden írás aszinkron, és nem blokkolja az ügyfeleket az adatok olvasásában és írásában. Amikor a Redis elindul, beolvassa az adatokat a pillanatképből vagy a naplófájlból, és a memóriában lévő gyorsítótár létrehozásához használja. További információ: Redis-adatmegőrzés a Redis webhelyén.
Megjegyzés:
A Redis nem garantálja, hogy az összes írás mentése katasztrofális hiba esetén történik, de legrosszabb esetben néhány másodpercnyi adat elveszhet. Ne feledje, hogy a gyorsítótár nem mérvadó adatforrásként működik, és a gyorsítótárat használó alkalmazások feladata annak biztosítása, hogy a kritikus fontosságú adatok mentése sikeres legyen egy megfelelő adattárba. További információ: Gyorsítótár-feltöltési minta.
Redis-adattípusok
A Redis egy kulcs-érték tároló, ahol az értékek egyszerű típusokat vagy összetett adatstruktúrákat, például kivonatokat, listákat és készleteket tartalmazhatnak. Támogatja az ilyen adattípusokon végzett atomi műveleteket. A kulcsok állandóak vagy korlátozott élettartammal címkézhetők, ekkor a rendszer automatikusan eltávolítja a kulcsot és annak megfelelő értékét a gyorsítótárból. A Redis-kulcsokkal és -értékekkel kapcsolatos további információkért tekintse meg a Redis-adattípusok és absztrakciók ismertetését ismertető oldalt a Redis webhelyén.
Redis replikáció és fürtözés
A Redis támogatja az elsődleges/alárendelt replikációt a rendelkezésre állás és az átviteli sebesség fenntartása érdekében. Az elsődleges Redis-csomópontra történő írási műveleteket a rendszer egy vagy több alárendelt csomópontra replikálja. Az olvasási műveleteket az elsődleges vagy bármely alárendelt tudja kiszolgálni.
Ha rendelkezik hálózati partícióval, az alárendeltek továbbra is kiszolgálhatják az adatokat, majd transzparensen újraszinkronizálhatják az elsődlegest a kapcsolat újbóli létrehozásakor. További részletekért látogasson el a Redis webhely replikációs oldalára.
A Redis fürtözést is biztosít, amely lehetővé teszi az adatok transzparens particionálását szegmensekre a kiszolgálók között, és eloszthatja a terhelést. Ez a funkció javítja a méretezhetőséget, mivel új Redis-kiszolgálók vehetők fel, és a gyorsítótár méretének növekedésével újraparticionálásra kerülnek az adatok.
Emellett a fürt minden kiszolgálója replikálható elsődleges/alárendelt replikációval. Ez biztosítja a fürt minden csomópontjának rendelkezésre állását. A fürtözéssel és a horizontális skálázással kapcsolatos további információkért látogasson el a Redis-fürt oktatóanyagának oldalára a Redis webhelyén.
A Redis memóriahasználata
A Redis-gyorsítótár véges méretű, amely a gazdagépen elérhető erőforrásoktól függ. A Redis-kiszolgáló konfigurálásakor megadhatja a maximálisan használható memóriamennyiséget. A Redis-gyorsítótárban lévő kulcsokat úgy is konfigurálhatja, hogy lejárati ideje legyen, majd a rendszer automatikusan eltávolítja azt a gyorsítótárból. Ez a funkció segíthet megakadályozni, hogy a memóriabeli gyorsítótár régi vagy elavult adatokkal töltsön fel.
A memória kitöltésekor a Redis számos szabályzat követésével automatikusan kiürítheti a kulcsokat és azok értékeit. Az alapértelmezett érték az LRU (a legutóbb használt), de más házirendeket is választhat, például a kulcsok véletlenszerű kiürítését vagy a kiürítés teljes kikapcsolását (ebben az esetben az elemek gyorsítótárhoz való hozzáadása sikertelen, ha megtelt). A Redis LRU-gyorsítótárként való használata lapon további információk találhatók.
Redis-tranzakciók és kötegek
A Redis lehetővé teszi az ügyfélalkalmazás számára, hogy atomi tranzakcióként küldjön be olyan műveleteket, amelyek adatokat olvasnak és írnak a gyorsítótárban. A tranzakció összes parancsa garantáltan szekvenciálisan fut, és a többi egyidejű ügyfél által kiadott parancsok nem lesznek egymásba fonva.
Ezek azonban nem valódi tranzakciók, mivel egy relációs adatbázis végrehajtaná őket. A tranzakciófeldolgozás két szakaszból áll – az első a parancsok várólistára helyezése, a második pedig a parancsok futtatása. A parancssor-kezelési szakaszban a tranzakciót alkotó parancsokat az ügyfél küldi el. Ha valamilyen hiba történik ezen a ponton (például szintaxishiba vagy a paraméterek helytelen száma), akkor a Redis nem hajlandó feldolgozni a teljes tranzakciót, és elveti azt.
A futtatási fázisban a Redis sorrendben hajtja végre az egyes várólistára helyezett parancsokat. Ha egy parancs ebben a fázisban meghiúsul, a Redis a következő várólistás paranccsal folytatja, és nem állítja vissza a már futtatott parancsok hatásait. Ez az egyszerűsített tranzakciós forma segít fenntartani a teljesítményt, és elkerülni a versengés által okozott teljesítményproblémákat.
A Redis az optimista zárolás egy formáját valósítja meg a konzisztencia fenntartása érdekében. A tranzakciókról és a Redis-zárolásról a Redis webhelyén található Tranzakciók oldalon talál részletes információkat.
A Redis támogatja a kérések nem tranzakciós kötegelését is. A Redis protokoll, amellyel az ügyfelek parancsokat küldenek egy Redis-kiszolgálónak, lehetővé teszi, hogy az ügyfél ugyanazon kérés részeként több műveletet küldjön. Ez segíthet a csomagtöredezettség csökkentésében a hálózaton. A köteg feldolgozásakor a rendszer minden parancsot végrehajt. Ha a parancsok bármelyike hibás, a rendszer elutasítja őket (ami nem tranzakcióval történik), de a többi parancs végrehajtása megtörténik. A kötegben lévő parancsok feldolgozásának sorrendjére sincs garancia.
Redis-biztonság
A Redis kizárólag az adatok gyors elérésére összpontosít, és úgy van kialakítva, hogy megbízható környezetben fusson, amely csak megbízható ügyfelek számára érhető el. A Redis a jelszóhitelesítésen alapuló korlátozott biztonsági modellt támogatja. (A hitelesítés teljesen eltávolítható, bár ezt nem javasoljuk.)
Minden hitelesített ügyfél ugyanazt a globális jelszót használja, és hozzáféréssel rendelkezik ugyanahhoz az erőforráshoz. Ha átfogóbb bejelentkezési biztonságra van szüksége, saját biztonsági réteget kell implementálnia a Redis-kiszolgáló előtt, és minden ügyfélkérésnek át kell haladnia ezen a további rétegen. A Redisnek nem szabad közvetlenül kitéve lennie a nem megbízható vagy nem hitelesített ügyfeleknek.
A parancsokhoz való hozzáférést letilthatja vagy átnevezheti (és csak a kiemelt ügyfeleknek adhat meg új neveket).
A Redis nem támogatja közvetlenül az adattitkosítás egyik formáját sem, ezért az ügyfélalkalmazások minden kódolást végre kell hajtaniuk. Emellett a Redis nem biztosít semmilyen közlekedési biztonságot. Ha a hálózaton áthaladó adatok védelmére van szüksége, javasoljuk, hogy implementáljon egy SSL-proxyt.
További információkért látogasson el a Redis biztonsági oldalára a Redis webhelyén.
Megjegyzés:
Az Azure Cache for Redis saját biztonsági réteget biztosít, amelyen keresztül az ügyfelek csatlakoznak. A mögöttes Redis-kiszolgálók nincsenek kitéve a nyilvános hálózatnak.
Azure Redis Cache
Az Azure Cache for Redis hozzáférést biztosít az Azure-adatközpontban üzemeltetett Redis-kiszolgálókhoz. Ez egy olyan homlokzat, amely hozzáférést és biztonságot biztosít. A gyorsítótárat az Azure Portalon helyezheti üzembe.
A portál számos előre definiált konfigurációt biztosít. Ezek a dedikált szolgáltatásként futó 53 GB-os gyorsítótártól és a 99,9%-es szolgáltatásiszint-szerződéssel (SLA) rendelkező fő-/alárendelt replikációt támogató, dedikált szolgáltatásként futó gyorsítótártól a megosztott hardveren futó replikáció nélküli 250 MB-os gyorsítótárig (rendelkezésre állási garancia nélkül) terjednek.
Az Azure Portal használatával konfigurálhatja a gyorsítótár kiürítési szabályzatát is, és a felhasználók a megadott szerepkörökhöz való hozzáadásával szabályozhatja a gyorsítótárhoz való hozzáférést. Ezek a szerepkörök, amelyek meghatározzák a tagok által végrehajtható műveleteket, tartalmazzák a tulajdonost, a közreműködőt és az olvasót. Például a tulajdonosi szerepkör tagjai teljes mértékben szabályozhatják a gyorsítótárat (beleértve a biztonságot) és annak tartalmát, a közreműködői szerepkör tagjai olvashatnak és írhatnak információkat a gyorsítótárban, az Olvasó szerepkör tagjai pedig csak a gyorsítótárból tudják lekérni az adatokat.
A legtöbb felügyeleti feladat az Azure Portalon keresztül történik. Emiatt a Redis standard verziójában elérhető számos felügyeleti parancs nem érhető el, beleértve a konfiguráció programozott módosításának lehetőségét, a Redis-kiszolgáló leállítását, a további alárendeltek konfigurálását vagy az adatok kényszerített lemezre mentését.
Az Azure Portal kényelmes grafikus kijelzőt tartalmaz, amely lehetővé teszi a gyorsítótár teljesítményének monitorozását. Megtekintheti például a létesített kapcsolatok számát, a végrehajtott kérések számát, az olvasások és írások mennyiségét, valamint a gyorsítótár-találatok és a gyorsítótárhibák számát. Ezen információk segítségével meghatározhatja a gyorsítótár hatékonyságát, és szükség esetén átválthat egy másik konfigurációra, vagy módosíthatja a kiürítési szabályzatot.
Emellett riasztásokat is létrehozhat, amelyek e-maileket küldenek a rendszergazdáknak, ha egy vagy több kritikus metrika a várt tartományon kívül esik. Előfordulhat például, hogy riasztást szeretne küldeni a rendszergazdának, ha a gyorsítótár-kihagyások száma meghaladja a megadott értéket az elmúlt órában, mert ez azt jelenti, hogy a gyorsítótár túl kicsi, vagy az adatok túl gyorsan kiüríthetők.
A gyorsítótár processzor-, memória- és hálózati használatát is figyelheti.
Az Azure Cache for Redis létrehozását és konfigurálását bemutató további információkért és példákért látogasson el az Azure Cache for Redis lapjára az Azure-blogon.
Munkamenet állapotának és HTML-kimenetének gyorsítótárazása
Ha azure-webszerepkörök használatával futtatott ASP.NET webalkalmazásokat hoz létre, mentheti a munkamenet állapotadatait és HTML-kimenetét egy Azure Cache for Redisben. Az Azure Cache for Redis munkamenet-állapotszolgáltatója lehetővé teszi a munkamenet-adatok megosztását egy ASP.NET-webalkalmazás különböző példányai között, és nagyon hasznos olyan webfarm-helyzetekben, amikor az ügyfél-kiszolgáló affinitása nem érhető el, és a munkamenet-adatok gyorsítótárazása a memóriában nem lenne megfelelő.
A munkamenet-állapotszolgáltató használata az Azure Cache for Redis szolgáltatással számos előnnyel jár, többek között az alábbiakat:
- A munkamenet-állapot megosztása számos ASP.NET webalkalmazással.
- Jobb méretezhetőséget biztosít.
- Több olvasó és egyetlen író számára támogatja az ugyanazon munkamenetállapot-adatokhoz való szabályozott, egyidejű hozzáférést.
- A tömörítéssel memóriát takaríthat meg, és javíthatja a hálózati teljesítményt.
További információ: ASP.NET munkamenet-állapotszolgáltató az Azure Cache for Redishez.
Megjegyzés:
Ne használja az Azure Cache for Redis munkamenet-állapotszolgáltatóját olyan ASP.NET alkalmazásokkal, amelyek az Azure-környezeten kívül futnak. A gyorsítótár Azure-on kívüli elérésének késése kiküszöbölheti az adatok gyorsítótárazásának teljesítménybeli előnyeit.
Hasonlóképpen, az Azure Cache for Redis kimeneti gyorsítótár-szolgáltatója lehetővé teszi a ASP.NET webalkalmazás által létrehozott HTTP-válaszok mentését. Ha a kimeneti gyorsítótár-szolgáltatót az Azure Cache for Redis használatával használja, javíthatja az összetett HTML-kimenetet megjelenítő alkalmazások válaszidejének növelését. A hasonló válaszokat generáló alkalmazáspéldányok a gyorsítótárban lévő megosztott kimeneti töredékeket használhatják ahelyett, hogy ezt a HTML-kimenetet többször generálják. További információ: ASP.NET Kimeneti gyorsítótár-szolgáltató az Azure Cache for Redishez.
Egyéni Redis-gyorsítótár létrehozása
Az Azure Cache for Redis az alapul szolgáló Redis-kiszolgálók homlokzataként működik. Ha olyan speciális konfigurációra van szüksége, amelyet nem fed le az Azure Redis cache (például egy 53 GB-nál nagyobb gyorsítótár), saját Redis-kiszolgálókat hozhat létre és üzemeltethet az Azure Virtual Machines használatával.
Ez egy potenciálisan összetett folyamat, mert előfordulhat, hogy több virtuális gépet kell létrehoznia, hogy elsődleges és alárendelt csomópontként működjön, ha replikációt szeretne megvalósítani. Továbbá, ha fürtöt szeretne létrehozni, akkor több elsődleges és alárendelt kiszolgálóra van szüksége. A minimális fürtözött replikációs topológia, amely magas szintű rendelkezésre állást és méretezhetőséget biztosít, legalább hat virtuális gépet tartalmaz, amelyek három pár elsődleges/alárendelt kiszolgálóként lesznek rendszerezve (a fürtöknek legalább három elsődleges csomópontot kell tartalmazniuk).
A késés minimalizálása érdekében minden elsődleges/alárendelt párnak közel kell lennie egymáshoz. Az egyes párok azonban különböző régiókban található Azure-adatközpontokban is futhatnak, ha a leggyakrabban használt alkalmazások közelében szeretné megtalálni a gyorsítótárazott adatokat. Egy Azure-beli virtuális gépként futó Redis-csomópont létrehozására és konfigurálására példa: A Redis futtatása CentOS Linux rendszerű virtuális gépen az Azure-ban.
Megjegyzés:
Ha így valósítja meg a saját Redis-gyorsítótárát, a szolgáltatás figyeléséért, kezeléséért és védelméért felel.
Redis-gyorsítótár particionálása
A gyorsítótár particionálásához több számítógépre kell felosztani a gyorsítótárat. Ez a struktúra számos előnnyel jár az egyetlen gyorsítótár-kiszolgálóval szemben, többek között az alábbiakat:
- Olyan gyorsítótár létrehozása, amely sokkal nagyobb, mint egyetlen kiszolgálón tárolható.
- Adatok elosztása kiszolgálók között, a rendelkezésre állás javítása. Ha egy kiszolgáló meghibásodik vagy elérhetetlenné válik, az általa tárolt adatok nem érhetők el, de a többi kiszolgálón lévő adatok továbbra is elérhetők. A gyorsítótárak esetében ez nem kulcsfontosságú, mert a gyorsítótárazott adatok csak az adatbázisban tárolt adatok átmeneti másolatai. A elérhetetlenné váló kiszolgálók gyorsítótárazott adatai ehelyett egy másik kiszolgálón gyorsítótárazhatók.
- A terhelés szétosztása a kiszolgálók között, ezáltal javítva a teljesítményt és a méretezhetőséget.
- Az adatok földrajzi helye a hozzá hozzáférő felhasználókhoz közel, ezáltal csökkentve a késést.
Gyorsítótár esetén a particionálás leggyakoribb formája a horizontális skálázás. Ebben a stratégiában minden partíció (vagy szegmens) saját jogon egy Redis-gyorsítótár. Az adatok egy adott partícióra skálázási logikával kerülnek továbbításra, amely az adatok elosztásához többféle megközelítést is használhat. A horizontális skálázási minta további információt nyújt a horizontális skálázás implementálásáról.
A particionálás Redis-gyorsítótárban való implementálásához az alábbi módszerek egyikét használhatja:
- Kiszolgálóoldali lekérdezés-útválasztás. Ebben a technikában az ügyfélalkalmazás kérést küld a gyorsítótárat alkotó Redis-kiszolgálók bármelyikének (valószínűleg a legközelebbi kiszolgálónak). Minden Redis-kiszolgáló olyan metaadatokat tárol, amelyek leírják az általa tárolt partíciót, és információkat is tartalmaznak arról, hogy mely partíciók találhatók más kiszolgálókon. A Redis-kiszolgáló megvizsgálja az ügyfélkérést. Ha helyben megoldható, végrehajtja a kért műveletet. Ellenkező esetben a kérést a megfelelő kiszolgálóra továbbítja. Ezt a modellt a Redis-fürtözés valósítja meg, és részletesebben a Redis-fürt oktatóanyagának oldalán, a Redis webhelyén ismertetjük. A Redis-fürtözés transzparens az ügyfélalkalmazások számára, és további Redis-kiszolgálók is hozzáadhatók a fürthöz (és az újraparticionált adatokhoz) anélkül, hogy újrakonfigurálnia kellene az ügyfeleket.
- Ügyféloldali particionálás. Ebben a modellben az ügyfélalkalmazás olyan logikát tartalmaz (esetleg kódtár formájában), amely a kéréseket a megfelelő Redis-kiszolgálóra irányítja. Ez a módszer az Azure Cache for Redis használatával használható. Hozzon létre több Azure Cache for Redis-t (egyet minden adatpartícióhoz), és implementálja az ügyféloldali logikát, amely a kéréseket a megfelelő gyorsítótárba irányítja. Ha a particionálási séma megváltozik (ha például további Azure Cache for Redis jön létre), előfordulhat, hogy újra kell konfigurálni az ügyfélalkalmazásokat.
- Proxy által támogatott particionálás. Ebben a sémában az ügyfélalkalmazások kéréseket küldenek egy közvetítő proxyszolgáltatásnak, amely megérti az adatok particionálásának módját, majd átirányítja a kérést a megfelelő Redis-kiszolgálóra. Ez a megközelítés az Azure Cache for Redishez is használható; a proxyszolgáltatás Azure-felhőszolgáltatásként implementálható. Ez a megközelítés további összetettséget igényel a szolgáltatás implementálásához, és a kérések végrehajtása hosszabb időt vehet igénybe, mint az ügyféloldali particionálás használata.
A Particionálás lap: az adatok több Redis-példány közötti felosztása a Redis webhelyén további információt nyújt a particionálás Redis használatával történő implementálásáról.
Redis Cache-ügyfélalkalmazások implementálása
A Redis számos programozási nyelven írt ügyfélalkalmazásokat támogat. Ha a .NET-keretrendszer használatával készít új alkalmazásokat, javasoljuk, hogy használja a StackExchange.Redis ügyfélkódtárat. Ez a kódtár egy .NET-keretrendszer objektummodellt biztosít, amely kivonatolja a Redis-kiszolgálóhoz való csatlakozás, a parancsok küldése és a válaszok fogadása részleteit. NuGet-csomagként elérhető a Visual Studióban. Ugyanezzel a kódtárral csatlakozhat egy Azure Cache for Redishez, vagy egy virtuális gépen üzemeltetett egyéni Redis-gyorsítótárhoz.
Redis-kiszolgálóhoz való csatlakozáshoz használja az osztály statikus Connect metódusát ConnectionMultiplexer . A metódus által létrehozott kapcsolat az ügyfélalkalmazás teljes élettartama alatt használható, és ugyanazt a kapcsolatot több egyidejű szál is használhatja. Ne csatlakoztassa újra és válassza le a kapcsolatot minden alkalommal, amikor Redis-műveletet hajt végre, mert ez csökkentheti a teljesítményt.
Megadhatja a kapcsolati paramétereket, például a Redis-gazdagép címét és a jelszót. Ha az Azure Cache for Redist használja, a jelszó az Azure Cache for Redishez az Azure Portal használatával létrehozott elsődleges vagy másodlagos kulcs.
Miután csatlakozott a Redis-kiszolgálóhoz, beszerezhet egy leírót a Redis Database-ben, amely gyorsítótárként működik. Ehhez a Redis-kapcsolat biztosítja a GetDatabase metódust. Ezután lekérheti az elemeket a gyorsítótárból, és adatokat tárolhat a gyorsítótárban az és StringGet a StringSet metódusok használatával. Ezek a metódusok egy kulcsot várnak paraméterként, és visszaadják az elemet a gyorsítótárban, amely egyező értékkel rendelkezik (StringGet), vagy hozzáadja az elemet a gyorsítótárhoz ezzel a kulccsal (StringSet).
A Redis-kiszolgáló helyétől függően számos művelet késéssel járhat, miközben a rendszer egy kérést továbbít a kiszolgálónak, és választ ad vissza az ügyfélnek. A StackExchange kódtár számos olyan metódus aszinkron verzióit biztosítja, amelyeket az ügyfélalkalmazások válaszkészsége érdekében tesz elérhetővé. Ezek a metódusok támogatják a feladatalapú aszinkron mintát a .NET-keretrendszerben .
Az alábbi kódrészlet egy nevű metódust RetrieveItemmutat be. A redis és a StackExchange kódtár alapján szemlélteti a gyorsítótár-feltöltési minta implementációját. A metódus egy sztringkulcs-értéket használ, és megkísérli lekérni a megfelelő elemet a Redis cache-ből a StringGetAsync metódus meghívásával (aszinkron verzió StringGet).
Ha az elem nem található, a rendszer a metódus használatával GetItemFromDataSourceAsync kéri le a mögöttes adatforrásból (amely egy helyi módszer, és nem része a StackExchange-kódtárnak). Ezt követően a rendszer hozzáadja a gyorsítótárhoz a StringSetAsync metódus használatával, hogy legközelebb gyorsabban lekérhesse.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
A StringGet metódusok és StringSet a metódusok nem korlátozódnak a sztringértékek beolvasására vagy tárolására. Bármely olyan elemet átvehetnek, amely bájttömbként szerializálva van. Ha mentenie kell egy .NET-objektumot, szerializálhatja bájtstreamként, és a StringSet metódussal írhatja a gyorsítótárba.
Hasonlóképpen, a metódussal StringGet beolvashat egy objektumot a gyorsítótárból, és .NET-objektumként deszerializálhatja azt. Az alábbi kód az IDatabase-interfész bővítménymetódusait mutatja be (a GetDatabase Redis-kapcsolat metódusa egy IDatabase objektumot ad vissza), valamint néhány mintakódot, amely ezeket a metódusokat használja egy BlogPost objektum olvasására és a gyorsítótárba való írására:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Az alábbi kód egy olyan metódust RetrieveBlogPost mutat be, amely ezen bővítménymetódusokkal olvas és ír egy szerializálható BlogPost objektumot a gyorsítótárba a gyorsítótár-feltöltési mintát követve:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
A Redis támogatja a parancscsövezést, ha egy ügyfélalkalmazás több aszinkron kérést küld. A Redis a parancsok fogadása és megválaszolása helyett ugyanazt a kapcsolatot használva multiplexelheti a kéréseket.
Ez a megközelítés segít csökkenteni a késést a hálózat hatékonyabb használatával. Az alábbi kódrészlet egy példát mutat be, amely egyszerre két ügyfél adatait kéri le. A kód két kérést küld el, majd más feldolgozást hajt végre (nem jelenik meg), mielőtt az eredmények fogadására vár. A Wait gyorsítótár-objektum metódusa hasonló a .NET-keretrendszer Task.Wait metódusához:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Az Azure Cache for Redist használó ügyfélalkalmazások írásáról további információt az Azure Cache for Redis dokumentációjában talál. További információ a StackExchange.Redis webhelyen is elérhető.
Az ugyanazon a webhelyen található folyamatokat és multiplexereket tartalmazó lap további információt nyújt az aszinkron műveletekről és a Redis és a StackExchange kódtár használatával végzett pipeliningről.
A Redis gyorsítótárazásának használata
A Redis legegyszerűbb használata gyorsítótárazási problémák esetén kulcs-érték párok, ahol az érték egy tetszőleges hosszúságú, tetszőleges hosszúságú karakterlánc, amely bármilyen bináris adatot tartalmazhat. (Ez lényegében egy bájtból álló tömb, amely sztringként kezelhető). Ezt a forgatókönyvet a jelen cikk korábbi, Redis Cache-ügyfélalkalmazások implementálása című szakasza szemléltette.
Vegye figyelembe, hogy a kulcsok nem értelmezett adatokat is tartalmaznak, így bármilyen bináris információt használhat kulcsként. Minél hosszabb a kulcs, annál több helyet fog tárolni, és minél tovább tart a keresési műveletek végrehajtása. A használhatóság és a könnyű karbantartás érdekében gondosan tervezzen meg kulcsteret, és használjon értelmes (de nem részletes) kulcsokat.
Használjon például strukturált kulcsokat, például "customer:100" a 100-as azonosítójú ügyfél kulcsának megjelenítéséhez, nem pedig egyszerűen "100". Ez a séma lehetővé teszi a különböző adattípusokat tároló értékek egyszerű megkülönböztetésére. Használhatja például a "orders:100" kulcsot is a 100 azonosítójú rendelés kulcsának megjelenítéséhez.
Az egydimenziós bináris sztringeken kívül a Redis kulcs-érték párok értékei strukturáltabb információkat is tartalmazhatnak, beleértve a listákat, a készleteket (rendezetlen és nem rendezett) és a kivonatokat. A Redis egy átfogó parancskészletet biztosít, amely képes kezelni ezeket a típusokat, és ezen parancsok közül sok elérhető a .NET-keretrendszer alkalmazásai számára egy ügyfélkódtáron keresztül, például a StackExchange-en keresztül. A Redis-adatok típusainak és absztrakcióinak bemutatása a Redis webhelyén részletesebb áttekintést nyújt ezekről a típusokról és a manipulálásukra használható parancsokról.
Ez a szakasz az ilyen adattípusok és parancsok gyakori használati eseteit foglalja össze.
Atomi és kötegműveletek végrehajtása
A Redis a sztringértékeken végzett atomi get-and-set műveletek sorozatát támogatja. Ezek a műveletek eltávolítják azokat a lehetséges versenyveszélyeket, amelyek külön GET és SET parancsok használatakor fordulhatnak elő. Az elérhető műveletek a következők:
INCR,INCRBY,DECRésDECRBY, amelyek atomi növekményes és decrement műveleteket hajtanak végre egész számadatok értékein. A StackExchange kódtár túlterhelt verziókat ésIDatabase.StringIncrementAsyncmetódusokat biztosít ezeknek aIDatabase.StringDecrementAsyncműveleteknek a végrehajtásához, és visszaadja a gyorsítótárban tárolt eredményül kapott értéket. A következő kódrészlet az alábbi módszerek használatát mutatja be:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, amely lekéri a kulcshoz társított értéket, és új értékre módosítja. A StackExchange kódtár a metóduson keresztül teszi elérhetővé ezt aIDatabase.StringGetSetAsyncműveletet. Az alábbi kódrészlet erre a módszerre mutat példát. Ez a kód az előző példában szereplő "data:counter" kulcshoz társított aktuális értéket adja vissza. Ezután visszaállítja a kulcs értékét nullára, mind ugyanannak a műveletnek a részeként:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETésMSET, amely egyetlen műveletként visszaadhat vagy módosíthat sztringértékeket. AIDatabase.StringGetAsyncmetódusok túlterheltekIDatabase.StringSetAsyncennek a funkciónak a támogatásához, ahogyan az alábbi példában látható:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Több műveletet is kombinálhat egyetlen Redis-tranzakcióval a jelen cikk korábbi, Redis-tranzakciók és kötegek szakaszában leírtak szerint. A StackExchange kódtár a felületen keresztül támogatja a ITransaction tranzakciókat.
A metódussal ITransaction objektumot IDatabase.CreateTransaction hozhat létre. Az objektum által biztosított metódusokkal parancsokat hívhat meg a ITransaction tranzakcióhoz.
Az ITransaction interfész hozzáférést biztosít az interfész által IDatabase elért metódusokhoz hasonló metódusokhoz, kivéve, hogy az összes metódus aszinkron. Ez azt jelenti, hogy csak a ITransaction.Execute metódus meghívásakor lesznek végrehajtva. A metódus által ITransaction.Execute visszaadott érték azt jelzi, hogy a tranzakció sikeresen létrejött -e (igaz), vagy meghiúsult -e (hamis).
Az alábbi kódrészlet egy példát mutat be, amely két számlálót növekményesen és dekrementel ugyanazon tranzakció részeként:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Ne feledje, hogy a Redis-tranzakciók eltérnek a relációs adatbázisok tranzakcióitól. A Execute metódus egyszerűen várólistára állítja a futtatni kívánt tranzakciót alkotó összes parancsot, és ha valamelyik hibás, akkor a tranzakció leáll. Ha az összes parancsot sikeresen várólistára állítottuk, minden parancs aszinkron módon fut.
Ha valamelyik parancs meghiúsul, a többiek továbbra is feldolgozva maradnak. Ha ellenőriznie kell, hogy egy parancs sikeresen befejeződött-e, le kell kérnie a parancs eredményeit a megfelelő feladat Eredmény tulajdonságával, ahogyan az a fenti példában látható. Az Eredmény tulajdonság olvasása letiltja a hívó szálat, amíg a feladat be nem fejeződik.
További információ: Tranzakciók a Redisben.
Kötegelt műveletek végrehajtásakor használhatja a IBatch StackExchange kódtár felületét. Ez az interfész hozzáférést biztosít a felület által IDatabase elért metódusokhoz hasonló metódusokhoz, kivéve, hogy az összes metódus aszinkron.
A metódussal IBatch létrehoz egy IDatabase.CreateBatch objektumot, majd a metódussal futtatja a IBatch.Execute köteget, ahogyan az az alábbi példában látható. Ez a kód egyszerűen beállít egy sztringértéket, növeli és decrementeli az előző példában használt számlálókat, és megjeleníti az eredményeket:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Fontos tisztában lenni azzal, hogy a tranzakcióval ellentétben, ha egy köteg parancsa hibásan formázott, akkor a többi parancs továbbra is futhat. A IBatch.Execute metódus nem ad vissza semmilyen sikerre vagy hibára utaló jelet.
Tűzoltás és gyorsítótár-műveletek elfelejtése
A Redis parancsjelölőkkel támogatja a tűz- és felejtési műveleteket. Ebben az esetben az ügyfél egyszerűen elindít egy műveletet, de nem érdekli az eredmény, és nem várja meg a parancs befejezését. Az alábbi példa bemutatja, hogyan hajthatja végre az INCR parancsot tűz- és felejtési műveletként:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Automatikusan lejáró kulcsok megadása
Amikor egy elemet egy Redis-gyorsítótárban tárol, megadhat egy időtúllépést, amely után az elem automatikusan törlődik a gyorsítótárból. A parancs használatával TTL azt is lekérdezheti, hogy mennyi idő áll a kulcs lejárata előtt. Ez a parancs elérhető a StackExchange-alkalmazások számára a IDatabase.KeyTimeToLive metódus használatával.
Az alábbi kódrészlet bemutatja, hogyan állíthat be 20 másodperces lejárati időt egy kulcson, és hogyan kérdezheti le a kulcs hátralévő élettartamát:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
A lejárati időt egy adott dátumra és időre is beállíthatja a EXPIRE paranccsal, amely metódusként KeyExpireAsync a StackExchange könyvtárban érhető el:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Jótanács
Manuálisan eltávolíthat egy elemet a gyorsítótárból a DEL paranccsal, amely metódusként IDatabase.KeyDeleteAsync a StackExchange könyvtáron keresztül érhető el.
Címkék használata a gyorsítótárazott elemek közötti korrelációhoz
A Redis-készlet több olyan elemből álló gyűjtemény, amely egyetlen kulccsal rendelkezik. Egy készletet a SADD paranccsal hozhat létre. A készlet elemeit az SMEMBERS paranccsal kérdezheti le. A StackExchange kódtár implementálja a SADD parancsot a IDatabase.SetAddAsync metódussal, az SMEMBERS parancsot pedig a IDatabase.SetMembersAsync metódussal.
A meglévő készleteket az SDIFF (különbség beállítása), az SINTER (metszéspont beállítása) és a SUNION (egyesítés beállítása) parancsokkal is kombinálhatja. A StackExchange kódtár egyesíti ezeket a műveleteket a IDatabase.SetCombineAsync metódusban. A metódus első paramétere határozza meg a végrehajtandó műveletet.
Az alábbi kódrészletek bemutatják, hogy a készletek hogyan lehetnek hasznosak a kapcsolódó elemek gyűjteményeinek gyors tárolásához és lekéréséhez. Ez a kód a BlogPost jelen cikk korábbi részében, a Redis Cache-ügyfélalkalmazások implementálásában leírt típust használja.
Az BlogPost objektumok négy mezőt tartalmaznak– egy azonosítót, egy címet, egy rangsorolási pontszámot és egy címkegyűjteményt. Az alábbi első kódrészlet az objektumok C#-listájának BlogPost feltöltéséhez használt mintaadatokat jeleníti meg:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Az egyes BlogPost objektumok címkéi készletként tárolhatók egy Redis-gyorsítótárban, és minden egyes halmazt társíthat a BlogPostrendszer azonosítójával. Ez lehetővé teszi, hogy az alkalmazás gyorsan megtalálja az adott blogbejegyzéshez tartozó összes címkét. Ha az ellenkező irányba szeretne keresni, és megkeresni egy adott címkét tartalmazó összes blogbejegyzést, létrehozhat egy másik készletet, amely a kulcsban lévő címkeazonosítóra hivatkozó blogbejegyzéseket tartalmazza:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Ezek a struktúrák lehetővé teszik, hogy sok gyakori lekérdezést nagyon hatékonyan hajthasson végre. Megtalálhatja és megjelenítheti például az 1. blogbejegyzés összes címkéjét:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Az 1. blogbejegyzésben és a 2. blogbejegyzésben gyakran használt címkéket egy metszéspont-művelet végrehajtásával találja meg, az alábbiak szerint:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
És megtalálja az összes blogbejegyzést, amely egy adott címkét tartalmaz:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Legutóbb elért elemek keresése
Számos alkalmazás esetében gyakori feladat a legutóbb elért elemek megkeresése. Előfordulhat például, hogy egy blogwebhely információkat szeretne megjeleníteni a legutóbb olvasott blogbejegyzésekről.
Ezt a funkciót redis-listával valósíthatja meg. A Redis-listák több olyan elemet tartalmaznak, amelyek ugyanazt a kulcsot tartalmazzák. A lista kétvégű üzenetsorként működik. Az elemeket az LPUSH (bal oldali leküldés) és az RPUSH (jobb leküldés) parancsokkal a lista bármelyik végébe leküldheti. Az LPOP és az RPOP parancsokkal a lista bármelyik végéből lekérheti az elemeket. Az LRANGE és az RRANGE parancsokkal is visszaadhat elemeket.
Az alábbi kódrészletek bemutatják, hogyan hajthatja végre ezeket a műveleteket a StackExchange kódtár használatával. Ez a kód az BlogPost előző példákban szereplő típust használja. Mivel egy felhasználó elolvas egy blogbejegyzést, a IDatabase.ListLeftPushAsync metódus a blogbejegyzés címét egy listára küldi, amely a Redis cache "blog:recent_posts" kulcsához van társítva.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Ahogy több blogbejegyzést olvasnak, a címek ugyanarra a listára kerülnek. A listát az a sorrend rendezi, amelyben a címeket hozzáadták. A legutóbb olvasott blogbejegyzések a lista bal vége felé vannak. (Ha ugyanazt a blogbejegyzést többször olvassák, akkor több bejegyzés is szerepel a listában.)
A metódus használatával IDatabase.ListRange megjelenítheti a legutóbbi olvasási bejegyzések címét. Ez a metódus a listát, a kezdőpontot és a végpontot tartalmazó kulcsot használja. Az alábbi kód lekéri a lista bal felső részén található 10 blogbejegyzés (0 és 9 közötti elemek) címét:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Vegye figyelembe, hogy a ListRangeAsync metódus nem távolít el elemeket a listából. Ehhez használhatja a metódusokat és IDatabase.ListLeftPopAsync a IDatabase.ListRightPopAsync metódusokat.
Ha meg szeretné akadályozni, hogy a lista határozatlan ideig növekedjen, a lista levágásával rendszeresen kivághatja az elemeket. Az alábbi kódrészlet bemutatja, hogyan távolíthatja el az öt bal szélső elemet a listából:
await cache.ListTrimAsync(redisKey, 0, 5);
Ranglista megvalósítása
Alapértelmezés szerint a készlet elemei nincsenek meghatározott sorrendben tárolva. Rendezett készletet a ZADD paranccsal (a IDatabase.SortedSetAdd StackExchange könyvtárban található metódussal) hozhat létre. Az elemek rendezése egy pontszámnak nevezett numerikus érték használatával történik, amely paraméterként van megadva a parancshoz.
Az alábbi kódrészlet hozzáadja egy blogbejegyzés címét egy rendezett listához. Ebben a példában minden blogbejegyzés rendelkezik egy pontszámmezővel is, amely tartalmazza a blogbejegyzés rangsorolását.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
A blogbejegyzés címeit és pontszámait növekvő pontszám sorrendben lekérheti a IDatabase.SortedSetRangeByRankWithScores következő módszerrel:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Megjegyzés:
A StackExchange könyvtár a metódust is biztosítja IDatabase.SortedSetRangeByRankAsync , amely pontszám sorrendben adja vissza az adatokat, de nem adja vissza a pontszámokat.
Az elemeket a pontszámok csökkenő sorrendjében is lekérheti, és korlátozhatja a visszaadott elemek számát úgy, hogy további paramétereket ad meg a IDatabase.SortedSetRangeByRankWithScoresAsync metódusnak. A következő példa az első 10 rangsorolt blogbejegyzés címét és pontszámait jeleníti meg:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
A következő példa a IDatabase.SortedSetRangeByScoreWithScoresAsync metódust használja, amellyel korlátozhatja az adott pontszámtartományba tartozó elemek visszaadott elemeit:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Üzenet csatornák használatával
Az adatgyorsítótáron kívül a Redis-kiszolgáló nagy teljesítményű közzétevői/előfizetői mechanizmuson keresztül is biztosít üzeneteket. Az ügyfélalkalmazások feliratkozhatnak egy csatornára, más alkalmazások vagy szolgáltatások pedig üzeneteket tehetnek közzé a csatornán. A feliratkozási alkalmazások ezután megkapják ezeket az üzeneteket, és feldolgozhatják őket.
A Redis a FELIRATKOZÁS parancsot biztosítja az ügyfélalkalmazásoknak a csatornákra való feliratkozáshoz. Ez a parancs egy vagy több csatorna nevét várja, amelyen az alkalmazás üzeneteket fogad. A StackExchange kódtár tartalmazza a ISubscription felületet, amely lehetővé teszi, hogy a .NET-keretrendszer-alkalmazások feliratkozzanak és közzétegyenek csatornákon.
Objektumot ISubscription a GetSubscriber Redis-kiszolgálóhoz való kapcsolódás módszerével hozhat létre. Ezután az objektum metódusával figyelheti az üzeneteket egy SubscribeAsync csatornán. Az alábbi példakód bemutatja, hogyan iratkozhat fel egy "messages:blogPosts" nevű csatornára:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
A metódus első paramétere Subscribe a csatorna neve. Ez a név ugyanazokat az egyezményeket követi, amelyeket a gyorsítótár kulcsai használnak. A név bármilyen bináris adatot tartalmazhat, de javasoljuk, hogy viszonylag rövid, értelmes sztringeket használjon a jó teljesítmény és a karbantarthatóság érdekében.
Vegye figyelembe azt is, hogy a csatornák által használt névtér eltér a kulcsok által használt névtértől. Ez azt jelenti, hogy rendelkezhet ugyanazzal a névvel rendelkező csatornákkal és kulcsokkal, bár ez megnehezítheti az alkalmazás kódjának karbantartását.
A második paraméter egy műveleti meghatalmazott. Ez a meghatalmazott aszinkron módon fut, amikor új üzenet jelenik meg a csatornán. Ez a példa egyszerűen megjeleníti az üzenetet a konzolon (az üzenet egy blogbejegyzés címét tartalmazza).
Csatornán való közzétételhez az alkalmazás használhatja a Redis PUBLISH parancsot. A StackExchange kódtár biztosítja a IServer.PublishAsync művelet végrehajtásának módját. A következő kódrészlet bemutatja, hogyan tehet közzé üzenetet az "messages:blogPosts" csatornán:
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
A közzétételi/előfizetési mechanizmusról több szempontot is érdemes ismernie:
- Több előfizető is feliratkozhat ugyanarra a csatornára, és mind megkapják az adott csatornán közzétett üzeneteket.
- Az előfizetők csak a feliratkozás után közzétett üzeneteket kapják. A csatornák nem pufferelhetők, és az üzenetek közzététele után a Redis-infrastruktúra minden előfizetőnek leküldi az üzenetet, majd eltávolítja azt.
- Alapértelmezés szerint az előfizetők az üzenetküldés sorrendjében fogadják az üzeneteket. A nagy számú üzenettel és sok előfizetővel és közzétevővel rendelkező, rendkívül aktív rendszerekben az üzenetek garantált szekvenciális kézbesítése lelassíthatja a rendszer teljesítményét. Ha minden üzenet független, és a sorrend nem lényeges, engedélyezheti a Redis rendszer egyidejű feldolgozását, ami segíthet a válaszkészség javításában. Ezt a StackExchange-ügyfélben úgy érheti el, hogy az előfizető által használt kapcsolat PreserveAsyncOrder értékét hamisra állítja:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Szerializálási szempontok
Szerializálási formátum kiválasztásakor fontolja meg a teljesítmény, az együttműködési képesség, a verziószámozás, a meglévő rendszerekkel való kompatibilitás, az adattömörítés és a memóriaterhelés közötti kompromisszumot. A teljesítmény értékelésekor ne feledje, hogy a teljesítménytesztek nagy mértékben függenek a környezettől. Előfordulhat, hogy nem tükrözik a tényleges számítási feladatot, és nem veszik figyelembe az újabb kódtárakat vagy verziókat. Nincs egyetlen "leggyorsabb" szerializáló minden forgatókönyvhöz.
Néhány megfontolandó lehetőség:
A protokollpufferek (más néven protobuf) a Google által a strukturált adatok hatékony szerializálására kifejlesztett szerializálási formátum. Erősen gépelt definíciós fájlokat használ az üzenetstruktúrák definiálásához. Ezeket a definíciófájlokat ezután nyelvspecifikus kódra fordítjuk az üzenetek szerializálásához és deszerializálásához. A Protobuf használható meglévő RPC-mechanizmusokon keresztül, vagy létrehozhat egy RPC-szolgáltatást.
Az Apache Thrift hasonló megközelítést alkalmaz, erősen gépelt definíciós fájlokkal és fordítási lépéssel hozza létre a szerializálási kódot és az RPC-szolgáltatásokat.
Az Apache Avro hasonló funkciókat biztosít a protokollpufferekhez és a Thrifthez, fordítási lépés azonban nincs. Ehelyett a szerializált adatok mindig tartalmaznak egy sémát, amely leírja a struktúrát.
A JSON egy nyílt szabvány, amely emberi olvasásra alkalmas szövegmezőket használ. Széles körű platformfüggetlen támogatással rendelkezik. A JSON nem használ üzenetsémákat. Mivel szövegalapú formátum, nem túl hatékony a vezetéken keresztül. Bizonyos esetekben azonban előfordulhat, hogy a gyorsítótárazott elemeket közvetlenül http-en keresztül adja vissza az ügyfélnek, ebben az esetben a JSON tárolása megtakaríthatja a deszerializálás költségét egy másik formátumból, majd szerializálhatja a JSON-ra.
A bináris JSON (BSON) egy bináris szerializálási formátum, amely a JSON-hoz hasonló struktúrát használ. A BSON-t úgy tervezték, hogy a JSON-hoz képest könnyű, könnyen vizsgálható és gyorsan szerializálható és deszerializálható legyen. A hasznos adatok mérete a JSON-hoz hasonló. Az adatoktól függően a BSON hasznos adatai kisebbek vagy nagyobbak lehetnek, mint a JSON hasznos adatai. A BSON további adattípusokkal rendelkezik, amelyek nem érhetők el a JSON-ban, például BinData (bájttömbök esetén) és Date.
MessagePack bináris szerializálási formátum, amely úgy van kialakítva, hogy kompakt legyen a vezetéken keresztüli átvitelhez. Nincsenek üzenetséma vagy üzenettípus-ellenőrzés.
A Bond egy platformfüggetlen keretrendszer a sémaalapú adatok kezeléséhez. Támogatja a nyelvközi szerializálást és a deszerializálást. Az itt felsorolt rendszerektől jelentős különbségek vannak az öröklés, a típus aliasok és az általánosak támogatása között.
A gRPC egy nyílt forráskódú RPC-rendszer, amelyet a Google fejlesztett ki. Alapértelmezés szerint a protokollpuffereket használja definíciónyelvként és mögöttes üzenetcserés formátumként.
Következő lépések
- az Azure Cache for Redis dokumentáció
- Azure Cache for Redis – gyakori kérdések
- Feladatalapú aszinkron minta
- A Redis dokumentációja
- StackExchange.Redis
- Adatparticionálási útmutató
Kapcsolódó erőforrások
Az alkalmazások gyorsítótárazásának megvalósításakor az alábbi minták is relevánsak lehetnek a forgatókönyvben:
Gyorsítótár-feltöltési minta: Ez a minta azt ismerteti, hogyan tölthet be igény szerinti adatokat egy adattárból származó gyorsítótárba. Ez a minta segít fenntartani a gyorsítótárban tárolt adatok és az eredeti adattárban tárolt adatok közötti konzisztenciát.
A horizontális particionálási minta információt nyújt a horizontális particionálás implementálásáról, így javítva a méretezhetőséget nagy mennyiségű adat tárolásakor és elérésekor.