Monitorozási és diagnosztikai útmutató
A felhőben futó elosztott alkalmazások és szolgáltatások természetükből adódóan összetett szoftverek, amelyek számos mozgó részből állnak. Éles környezetben fontos, hogy nyomon lehessen követni a felhasználók rendszerhasználati módját, nyomon lehessen követni az erőforrások kihasználtságát, és általában nyomon lehessen követni a rendszer állapotát és teljesítményét. Ezeknek a diagnosztikai információknak a segítségével észlelheti és javíthatja a problémákat, valamint felderítheti a potenciális problémákat, és megelőzheti azok bekövetkezését.
Monitorozási és diagnosztikai forgatókönyvek
A monitorozással betekintést nyerhet a rendszer működésébe. A monitorozás kulcsfontosságú része a szolgáltatásminőségi célok fenntartásának. A figyelési adatok gyűjtésének gyakori forgatókönyvei a következők:
- Gondoskodjon arról, hogy a rendszer kifogástalan állapotban maradjon.
- A rendszer és annak összetevői rendelkezésre állásának nyomon követése.
- A teljesítmény fenntartása annak biztosítása érdekében, hogy a rendszer átviteli sebessége ne csökkenjen váratlanul a munkamennyiség növekedésével.
- Annak garantálása, hogy a rendszer megfeleljen az ügyfelekkel kötött szolgáltatásiszint-szerződéseknek (SLA-k).
- A rendszer, a felhasználók és adataik védelmének és biztonságának védelme.
- A naplózási vagy szabályozási célokra végrehajtott műveletek nyomon követése.
- A rendszer napi használatának monitorozása és olyan trendek észlelése, amelyek problémákhoz vezethetnek, ha nem foglalkoznak vele.
- A felmerülő problémák nyomon követése a kezdeti jelentéstől a lehetséges okok elemzéséig, a kijavításig, az ebből eredő szoftverfrissítésekig és az üzembe helyezésig.
- Nyomkövetési műveletek és szoftverkiadások hibakeresése.
Megjegyzés:
Ez a lista nem célja, hogy átfogó legyen. Ez a dokumentum ezekre a forgatókönyvekre összpontosít, mint a figyelés végrehajtásának leggyakoribb helyzeteire. Előfordulhat, hogy mások kevésbé gyakoriak vagy a környezetére jellemzőek.
A következő szakaszok részletesebben ismertetik ezeket a forgatókönyveket. Az egyes forgatókönyvek adatait a következő formátumban tárgyaljuk:
- A forgatókönyv rövid áttekintése.
- A forgatókönyv jellemző követelményei.
- A forgatókönyv támogatásához szükséges nyers rendszerállapot-adatok és az információk lehetséges forrásai.
- Hogyan elemezhetők és kombinálhatók ezek a nyers adatok, hogy értelmes diagnosztikai információkat generáljanak.
Állapotfigyelés
A rendszer akkor kifogástalan, ha fut, és képes feldolgozni a kéréseket. Az állapotfigyelés célja, hogy pillanatképet hozzon létre a rendszer aktuális állapotáról, így ellenőrizheti, hogy a rendszer minden összetevője a várt módon működik-e.
Az állapotfigyelés követelményei
Az operátorokat gyorsan (másodpercek alatt) figyelmeztetni kell, ha a rendszer bármely része nem megfelelő állapotúnak minősül. Az operátornak meg kell tudnia állapítani, hogy a rendszer mely részei működnek megfelelően, és mely részek tapasztalnak problémákat. A rendszerállapot egy forgalomirányító rendszeren keresztül kiemelhető:
- Nem megfelelő állapot esetén piros (a rendszer leállt)
- Részlegesen kifogástalan állapotú sárga (a rendszer csökkentett funkcionalitással működik)
- Zöld a teljesen egészséges
Az átfogó állapotmonitorozási rendszer lehetővé teszi az operátor számára, hogy részletezve tekintse meg az alrendszerek és összetevők állapotát. Ha például a teljes rendszer részben kifogástalan állapotúként van ábrázolva, az operátornak képesnek kell lennie nagyítani, és meghatározni, hogy mely funkciók jelenleg nem érhetők el.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
Az állapotfigyelés támogatásához szükséges nyers adatok a következők eredményeként hozhatók létre:
- Felhasználói kérések végrehajtásának nyomon követése. Ezek az információk felhasználhatók annak meghatározására, hogy mely kérések lettek sikeresek, melyek sikertelenek, és mennyi ideig tart az egyes kérések.
- Szintetikus felhasználói figyelés. Ez a folyamat szimulálja a felhasználó által végrehajtott lépéseket, és előre meghatározott lépések sorozatát követi. Az egyes lépések eredményeit rögzíteni kell.
- Naplózási kivételek, hibák és figyelmeztetések. Ezek az információk rögzíthetők az alkalmazáskódba beágyazott nyomkövetési utasítások eredményeként, valamint a rendszer által hivatkozott szolgáltatások eseménynaplóiból származó információk lekérése.
- A rendszer által használt külső szolgáltatások állapotának monitorozása. Ez a monitorozás szükségessé teheti a szolgáltatások által nyújtott állapotadatok lekérését és elemzését. Ezek az információk számos formátumot tartalmazhatnak.
- Végpontfigyelés. Ezt a mechanizmust részletesebben a "Rendelkezésre állás monitorozása" című szakaszban ismertetjük.
- Környezeti teljesítményadatok gyűjtése, például háttér cpu-kihasználtság vagy I/O-tevékenység (beleértve a hálózati tevékenységet is).
Állapotadatok elemzése
Az állapotfigyelés elsődleges célja, hogy gyorsan jelezze, hogy a rendszer fut-e. Az azonnali adatok gyakori elemzése riasztást válthat ki, ha egy kritikus összetevő nem megfelelő állapotúként van észlelve. (Nem válaszol például egy egymást követő pingsorozatra.) Az operátor ezután elvégezheti a megfelelő korrekciós műveletet.
A fejlettebb rendszerek tartalmazhatnak egy prediktív elemet, amely hideg elemzést végez a legutóbbi és az aktuális számítási feladatokon. A hideg elemzések trendeket észlelhetnek, és megállapíthatják, hogy a rendszer valószínűleg kifogástalan állapotban marad-e, vagy a rendszernek további erőforrásokra lesz szüksége. Ennek a prediktív elemnek kritikus teljesítménymetrikákon kell alapulnia, például:
- Az egyes szolgáltatásokra vagy alrendszerekre irányuló kérelmek aránya.
- A kérések válaszideje.
- Az egyes szolgáltatásokba be- és kifelé áramló adatok mennyisége.
Ha bármely metrika értéke meghaladja a megadott küszöbértéket, a rendszer riasztást adhat, amely lehetővé teszi, hogy egy operátor vagy automatikus skálázás (ha elérhető) végrehajtsa a rendszerállapot fenntartásához szükséges megelőző műveleteket. Ezek a műveletek magukban foglalhatják az erőforrások hozzáadását, egy vagy több sikertelen szolgáltatás újraindítását, vagy az alacsonyabb prioritású kérelmek szabályozását.
Rendelkezésre állás figyelése
Egy valóban kifogástalan rendszer megköveteli, hogy a rendszert alkotó összetevők és alrendszerek elérhetők legyenek. A rendelkezésre állás monitorozása szorosan kapcsolódik az állapotfigyeléshez. Míg azonban az állapotfigyelés azonnali áttekintést nyújt a rendszer aktuális állapotáról, a rendelkezésre állás monitorozása a rendszer és összetevői rendelkezésre állásának nyomon követésével foglalkozik, hogy statisztikákat készíthessen a rendszer üzemidejéről.
Számos rendszerben egyes összetevők (például egy adatbázis) beépített redundanciával vannak konfigurálva, hogy lehetővé tegyék a gyors feladatátvételt súlyos hiba vagy kapcsolatvesztés esetén. Ideális esetben a felhasználóknak nem szabad tudniuk, hogy ilyen hiba történt. A rendelkezésre állás monitorozása szempontjából azonban a lehető legtöbb információt kell összegyűjteni az ilyen hibákról, hogy megállapítsuk az okot, és korrekciós műveleteket hajtsunk végre, hogy megakadályozzuk az ismétlődést.
A rendelkezésre állás nyomon követéséhez szükséges adatok számos alacsonyabb szintű tényezőtől függhetnek. Ezek közül számos tényező az alkalmazásra, a rendszerre és a környezetre lehet jellemző. A hatékony monitorozási rendszer rögzíti az alacsony szintű tényezőknek megfelelő rendelkezésre állási adatokat, majd összesíti őket, hogy átfogó képet adjon a rendszerről. Egy e-kereskedelmi rendszerben például a rendelések leadására szolgáló üzleti funkciók attól függhetnek, hogy a rendelések adatait hol tárolja a rendszer, és hogy milyen fizetési rendszer kezeli a pénzbeli tranzakciókat a rendelések kifizetéséhez. A rendszer rendeléselhelyezési részének rendelkezésre állása ezért az adattár és a fizetési alrendszer rendelkezésre állásának függvénye.
A rendelkezésre állás monitorozásának követelményei
Az operátoroknak emellett meg kell tudniuk tekinteni az egyes rendszerek és alrendszerek előzmény rendelkezésre állását, és ezen információk segítségével észlelni kell azokat a trendeket, amelyek egy vagy több alrendszer rendszeres meghibásodását okozhatják. (A szolgáltatások a maximális feldolgozási időnek megfelelő adott nap időpontban indulnak el?)
A monitorozási megoldásnak azonnali és előzménynézetet kell biztosítania az egyes alrendszerek rendelkezésre állásáról vagy elérhetetlenségéről. Képesnek kell lennie arra is, hogy gyorsan riasztást küldjön egy operátornak, ha egy vagy több szolgáltatás meghibásodik, vagy ha a felhasználók nem tudnak csatlakozni a szolgáltatásokhoz. Ez nemcsak az egyes szolgáltatások monitorozását, hanem az egyes felhasználók által végrehajtott műveleteket is vizsgálja, ha ezek a műveletek sikertelenek, amikor megpróbálnak kommunikálni egy szolgáltatással. Bizonyos mértékig a kapcsolat bizonyos fokú meghibásodása normális, és átmeneti hibák okozhatják. Hasznos lehet azonban engedélyezni a rendszer számára, hogy riasztást adjon ki egy adott alrendszer csatlakozási hibáinak számáról, amely egy adott időszakban következik be.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
Az állapotmonitorozáshoz hasonlóan a rendelkezésre állás monitorozásának támogatásához szükséges nyers adatok a szintetikus felhasználók figyelésének és az esetleges kivételek, hibák és figyelmeztetések naplózásának eredményeként hozhatók létre. Emellett a rendelkezésre állási adatok a végpontfigyelés végrehajtásával is lektorálódhatnak. Az alkalmazás egy vagy több állapotvégpontot is elérhetővé tehet, és mindegyik tesztelési hozzáférést biztosít a rendszer egy funkcionális területéhez. A monitorozási rendszer egy meghatározott ütemezés követésével pingelheti az egyes végpontokat, és összegyűjtheti az eredményeket (sikeres vagy sikertelen).
Minden időtúllépést, hálózati csatlakozási hibát és kapcsolat-újrapróbálkozási kísérletet rögzíteni kell. Minden adatot időbélyegzőnek kell lennie.
Rendelkezésre állási adatok elemzése
A rendszerállapot-adatokat összesíteni és korrelálni kell az alábbi elemzési típusok támogatásához:
- A rendszer és az alrendszerek azonnali rendelkezésre állása.
- A rendszer és az alrendszerek rendelkezésre állási hibáinak aránya. Ideális esetben egy operátornak képesnek kell lennie korrelálni a hibákat adott tevékenységekkel: mi történt, amikor a rendszer meghibásodott?
- A rendszer vagy bármely alrendszer meghibásodási arányának előzménynézete bármely meghatározott időszakban, valamint a rendszer terhelése (például felhasználói kérések száma), ha hiba történt.
- A rendszer vagy bármely alrendszer elérhetetlenségének okai. Előfordulhat például, hogy a szolgáltatás nem fut, megszakad a kapcsolat, csatlakozik, de időtúllépést végez, és csatlakozik, de hibákat ad vissza.
A szolgáltatás százalékos rendelkezésre állását az alábbi képlet használatával számíthatja ki egy adott időszak alatt:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Ez SLA-célokra hasznos. (Az SLA monitorozását az útmutató későbbi részében részletesebben ismertetjük.) Az állásidő definíciója a szolgáltatástól függ. A Visual Studio Team Services buildszolgáltatás például az állásidőt határozza meg az az időszak (összes felhalmozott perc), amely alatt a Build Szolgáltatás nem érhető el. Egy perc akkor tekinthető elérhetetlennek, ha az ügyfél által kezdeményezett műveletek végrehajtása érdekében a buildszolgáltatásnak küldött összes folyamatos HTTP-kérés hibakódot eredményez, vagy nem ad vissza választ.
Teljesítményfigyelés
Mivel a rendszer egyre nagyobb terhelésnek van alávetve (a felhasználók számának növelésével), a felhasználók által elért adathalmazok mérete nő, és egy vagy több összetevő meghibásodásának lehetősége egyre valószínűbbé válik. Az összetevők meghibásodását gyakran megelőzi a teljesítmény csökkenése. Ha képes észlelni egy ilyen csökkenést, proaktív lépéseket tehet a helyzet megoldásához.
A rendszer teljesítménye számos tényezőtől függ. Minden tényezőt általában fő teljesítménymutatók (KPI-k) mérnek, például az adatbázis-tranzakciók másodpercenkénti száma vagy a megadott időkeretben sikeresen kiszolgált hálózati kérelmek mennyisége. Ezen KPI-k némelyike konkrét teljesítménymérőként érhető el, míg mások metrikák kombinációjából származhatnak.
Megjegyzés:
A gyenge vagy jó teljesítmény meghatározásához tisztában kell lennie azzal, hogy a rendszer milyen teljesítményszinten fusson. Ehhez meg kell figyelnie a rendszert, miközben egy tipikus terhelés alatt működik, és rögzíteni kell az egyes KPI-k adatait egy adott időszakban. Ez magában foglalhatja a rendszer szimulált terhelés alatt való futtatását egy tesztkörnyezetben, és összegyűjtheti a megfelelő adatokat, mielőtt üzembe helyezné a rendszert egy éles környezetben.
Gondoskodnia kell arról is, hogy a teljesítmény szempontjából történő monitorozás ne jelentsen terhet a rendszer számára. Dinamikusan módosíthatja a teljesítményfigyelési folyamat által gyűjtött adatok részletességi szintjét.
A teljesítményfigyelés követelményei
A rendszer teljesítményének vizsgálatához az operátornak általában a következőket tartalmazó információkat kell látnia:
- A felhasználói kérések válaszaránya.
- Az egyidejű felhasználói kérések száma.
- A hálózati forgalom mennyisége.
- Azok az arányok, amelyeken az üzleti tranzakciók befejeződnek.
- A kérelmek átlagos feldolgozási ideje.
Hasznos lehet olyan eszközöket is biztosítani, amelyek lehetővé teszik az operátorok számára a korrelációk kiszúrásához, például:
- Az egyidejű felhasználók száma és a kérelmek késési ideje (mennyi ideig tart egy kérés feldolgozásának megkezdése a felhasználó elküldése után).
- Az egyidejű felhasználók száma az átlagos válaszidővel szemben (mennyi ideig tart egy kérés végrehajtása a feldolgozás megkezdése után).
- A kérelmek mennyisége és a feldolgozási hibák száma.
Ezen magas szintű funkcionális információk mellett az operátornak képesnek kell lennie részletes képet kapnia a rendszer egyes összetevőinek teljesítményéről. Ezeket az adatokat általában alacsony szintű teljesítményszámlálók biztosítják, amelyek nyomon követik az információkat, például:
- Memóriakihasználtság.
- Szálak száma.
- Processzorfeldolgozási idő.
- A kérelemsor hossza.
- Lemez- vagy hálózati I/O-sebességek és hibák.
- Megírt vagy olvasott bájtok száma.
- Köztes szoftverjelzők, például az üzenetsor hossza.
Minden vizualizációnak lehetővé kell tennie, hogy egy operátor meghatározhasson egy időszakot. A megjelenített adatok lehetnek pillanatképek az aktuális helyzetről vagy a teljesítmény előzménynézete.
Az operátornak képesnek kell lennie riasztást létrehozni bármely megadott érték teljesítménymérése alapján bármely megadott időintervallumban.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
Magas szintű teljesítményadatokat (átviteli sebesség, egyidejű felhasználók száma, üzleti tranzakciók száma, hibaarányok stb.) gyűjthet, ha figyeli a felhasználók kéréseinek előrehaladását, amint megérkeznek és áthaladnak a rendszeren. Ez magában foglalja a nyomkövetési utasítások beépítését az alkalmazáskód kulcsfontosságú pontjaira, valamint az időzítési információkat. Minden hibát, kivételt és figyelmeztetést elegendő adattal kell rögzíteni ahhoz, hogy korrelálni lehessen őket az őket okozó kérésekkel. Az Internet Information Services (IIS) naplója egy másik hasznos forrás.
Ha lehetséges, az alkalmazás által használt külső rendszerek teljesítményadatait is rögzítenie kell. Ezek a külső rendszerek saját teljesítményszámlálókat vagy más funkciókat biztosíthatnak a teljesítményadatok lekéréséhez. Ha ez nem lehetséges, a művelet állapotával (sikeres, sikertelen vagy figyelmeztetés) együtt jegyezze fel az olyan adatokat, mint a külső rendszer felé küldött kérések kezdési és befejezési időpontja. Használhat például stopperórás megközelítést az időkérésekhez: indítsa el az időzítőt a kérés indításakor, majd állítsa le az időzítőt, amikor a kérés befejeződik.
A rendszer egyes összetevőinek alacsony szintű teljesítményadatai olyan funkciókon és szolgáltatásokon keresztül érhetők el, mint a Windows teljesítményszámlálói és az Azure Diagnostics.
Teljesítményadatok elemzése
Az elemzési munka nagy része a teljesítményadatok felhasználói kérelemtípus, illetve az alrendszer vagy szolgáltatás szerint történő összesítéséből áll, amelyhez az egyes kéréseket küldik. A felhasználói kérések közé tartozik például egy elem hozzáadása egy bevásárlókocsihoz, vagy a pénztári folyamat végrehajtása egy e-kereskedelmi rendszerben.
Egy másik gyakori követelmény a teljesítményadatok összegzése a kiválasztott percentilisekben. Egy operátor például meghatározhatja a kérelmek 99 százalékára, a kérelmek 95 százalékára és a kérelmek 70 százalékára vonatkozó válaszidőt. Előfordulhat, hogy az egyes percentilisekhez SLA-célokat vagy egyéb célokat határoznak meg. A folyamatban lévő eredményeket közel valós időben kell jelenteni az azonnali problémák észleléséhez. Az eredményeket statisztikai célból hosszabb idő alatt is összesíteni kell.
A teljesítményt érintő késési problémák esetén az operátornak gyorsan azonosítania kell a szűk keresztmetszet okát az egyes kérések által végrehajtott lépések késésének vizsgálatával. A teljesítményadatoknak ezért lehetővé kell tenniük a teljesítménymérők korrelációját az egyes lépések esetében, hogy azokat egy adott kéréshez lehessen kötni.
A vizualizációs követelményektől függően hasznos lehet olyan adatkocka létrehozása és tárolása, amely a nyers adatok nézeteit tartalmazza. Ez az adatkocka lehetővé teszi a teljesítményadatok összetett alkalmi lekérdezését és elemzését.
Biztonsági monitorozás
Minden bizalmas adatot tartalmazó kereskedelmi rendszernek biztonsági struktúrát kell kialakítania. A biztonsági mechanizmus összetettsége általában az adatok bizalmassági függvénye. Olyan rendszerben, amely megköveteli a felhasználók hitelesítését, a következőt kell rögzítenie:
- Az összes bejelentkezési kísérlet, függetlenül attól, hogy sikertelenek vagy sikeresek-e.
- Egy hitelesített felhasználó által végrehajtott összes művelet és a hitelesített felhasználó által elért összes erőforrás részletei.
- Amikor egy felhasználó befejez egy munkamenetet, és kijelentkezik.
A monitorozás segíthet a rendszer elleni támadások észlelésében. A sikertelen bejelentkezési kísérletek nagy száma például találgatásos támadást jelezhet. A kérések váratlan megugrása egy elosztott szolgáltatásmegtagadási (DDoS-) támadás eredménye lehet. A kérések forrásától függetlenül fel kell készülnie az összes erőforrásra irányuló összes kérés figyelésére. A bejelentkezési sebezhetőséggel rendelkező rendszerek véletlenül elérhetővé tehetik az erőforrásokat a külvilág számára anélkül, hogy a felhasználónak ténylegesen be kellene jelentkeznie.
A biztonsági monitorozás követelményei
A biztonsági monitorozás legkritikusabb szempontjainak lehetővé kell tenni, hogy az operátorok gyorsan:
- Nem hitelesített entitás behatolási kísérletének észlelése.
- Azonosíthatja az entitások azon műveletekre tett kísérleteit, amelyekhez nem kaptak hozzáférést.
- Állapítsa meg, hogy a rendszer vagy a rendszer egy része támadás alatt áll-e kívülről vagy belülről. (Előfordulhat például, hogy egy rosszindulatú hitelesített felhasználó megpróbálja leállni a rendszert.)
A követelmények támogatásához az operátort értesíteni kell, ha:
- Egy fiók ismétlődő sikertelen bejelentkezési kísérleteket végez egy megadott időszakon belül.
- Egy hitelesített fiók egy adott időszakban többször is megpróbál hozzáférni egy tiltott erőforráshoz.
- Számos nem hitelesített vagy jogosulatlan kérés fordul elő egy adott időszakban.
Az operátornak megadott információknak tartalmazniuk kell az egyes kérések forrásának állomáscímét. Ha a biztonsági szabálysértések rendszeresen egy adott címtartományból erednek, előfordulhat, hogy ezek a gazdagépek le lesznek tiltva.
A rendszer biztonságának fenntartásában kulcsfontosságú szerepet játszik, hogy gyorsan észlelni tudja a szokásos mintától eltérő műveleteket. Az olyan információk, mint a sikertelen vagy sikeres bejelentkezési kérelmek száma vizuálisan megjeleníthetők, így könnyebben észlelhető, hogy szokatlan időpontban kiugróan magas a tevékenység. (Erre a tevékenységre példa az, hogy a felhasználók 3:00-kor jelentkeznek be, és nagy számú műveletet hajtanak végre, amikor a munkanapjuk 9:00-kor kezdődik). Ezek az információk az időalapú automatikus skálázás konfigurálásához is használhatók. Ha például egy operátor azt észleli, hogy nagy számú felhasználó jelentkezik be rendszeresen egy adott napon, az operátor további hitelesítési szolgáltatásokat indíthat a munkamennyiség kezeléséhez, majd a csúcsidőszak leteltével leállítja ezeket a további szolgáltatásokat.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
A biztonság a legtöbb elosztott rendszer átfogó aspektusa. A vonatkozó adatok valószínűleg a rendszer több pontján jönnek létre. Érdemes megfontolnia egy biztonsági információ- és eseménykezelési (SIEM) megközelítést, amely összegyűjti az alkalmazás, a hálózati berendezések, a kiszolgálók, a tűzfalak, a víruskereső szoftverek és más behatolás-megelőzési elemek által kiváltott eseményekből származó biztonsági információkat.
A biztonsági monitorozás olyan eszközök adatait is tartalmazhatja, amelyek nem részei az alkalmazásnak. Ezek az eszközök tartalmazhatnak olyan segédprogramokat, amelyek azonosítják a külső ügynökségek portkeresési tevékenységeit, vagy olyan hálózati szűrőket, amelyek észlelik az alkalmazáshoz és az adatokhoz való hitelesítés nélküli hozzáférésre tett kísérleteket.
Az összegyűjtött adatoknak minden esetben lehetővé kell tenniük a rendszergazdának, hogy meghatározza a támadások jellegét, és megtegye a megfelelő ellenintézkedéseket.
Biztonsági adatok elemzése
A biztonsági monitorozás egyik funkciója a különböző források, amelyekből az adatok származnak. A különböző formátumok és részletességi szint gyakran összetett elemzést igényelnek a rögzített adatokról, hogy koherens információlánchoz kösse őket. A legegyszerűbb eseteken (például nagyszámú sikertelen bejelentkezés észlelése vagy a kritikus erőforrásokhoz való jogosulatlan hozzáférésre tett ismétlődő kísérletek) kívül nem lehetséges a biztonsági adatok összetett automatizált feldolgozása. Ehelyett célszerűbb lehet ezeket az adatokat időbélyegekkel, de eredeti formájában egy biztonságos adattárba írni, hogy lehetővé tegye a szakértői manuális elemzést.
SLA monitorozása
Számos olyan kereskedelmi rendszer, amely támogatja a fizető ügyfeleket, garanciát vállal a rendszer teljesítményére SLA-k formájában. Az SLA-k lényegében azt állapítják meg, hogy a rendszer képes kezelni egy meghatározott mennyiségű munkát egy meghatározott időkereten belül, kritikus információk elvesztése nélkül. Az SLA monitorozása azzal foglalkozik, hogy a rendszer megfeleljen a mérhető SLA-knak.
Megjegyzés:
Az SLA monitorozása szorosan kapcsolódik a teljesítményfigyeléshez. Míg azonban a teljesítményfigyelés a rendszer optimális működésének biztosításával foglalkozik, az SLA-monitorozást egy szerződéses kötelezettség szabályozza, amely meghatározza, hogy valójában mit jelent az optimális.
A SLA-k meghatározása gyakran a következő:
- A rendszer általános rendelkezésre állása. Egy szervezet például garantálhatja, hogy a rendszer az idő 99,9 százalékában elérhető lesz. Ez évente legfeljebb 9 óra állásidőt vagy körülbelül heti 10 percet jelent.
- Működési átviteli sebesség. Ezt a szempontot gyakran egy vagy több magas vízjelként fejezik ki, például garantálják, hogy a rendszer akár 100 000 egyidejű felhasználói kérést is támogathat, vagy 10 000 egyidejű üzleti tranzakciót kezelhet.
- Működési válaszidő. A rendszer garanciát is vállalhat a kérelmek feldolgozásának sebességére. Például az összes üzleti tranzakció 99 százaléka 2 másodpercen belül befejeződik, és egyetlen tranzakció sem tart tovább 10 másodpercnél.
Megjegyzés:
Egyes kereskedelmi rendszerekre vonatkozó szerződések az ügyfélszolgálat SLA-kat is tartalmazhatnak. Ilyen például, hogy az ügyfélszolgálati kérések öt percen belül választ kapnak, és az összes probléma 99 százaléka 1 munkanapon belül teljes mértékben meg lesz oldva. A probléma hatékony nyomon követése (amelyet a jelen szakaszban később ismertetünk) kulcsfontosságú az ilyen SLA-knak való megfeleltetés szempontjából.
Az SLA monitorozásának követelményei
A legmagasabb szinten az operátornak képesnek kell lennie arra, hogy egy pillantással megállapítsa, hogy a rendszer megfelel-e az elfogadott SLA-knak, vagy sem. És ha nem, az operátornak képesnek kell lennie részletezni és megvizsgálni az alapul szolgáló tényezőket a nem megfelelő teljesítmény okainak meghatározásához.
A vizuálisan ábrázolható tipikus magas szintű mutatók a következők:
- A szolgáltatás üzemidejének százalékos aránya.
- Az alkalmazás átviteli sebessége (a sikeres tranzakciók vagy műveletek másodpercenkénti mértéke).
- A sikeres/sikertelen alkalmazáskérések száma.
- Az alkalmazás- és rendszerhibák, kivételek és figyelmeztetések száma.
Ezeknek a mutatóknak képesnek kell lenniük arra, hogy meghatározott időtartamon belül szűrjenek.
A felhőalkalmazások valószínűleg számos alrendszerből és összetevőből állnak majd. Az operátornak ki kell tudnia választania egy magas szintű mutatót, és látnia kell, hogyan áll az alapul szolgáló elemek állapotából. Ha például a teljes rendszer üzemideje egy elfogadható érték alá esik, az operátornak képesnek kell lennie nagyítani és meghatározni, hogy mely elemek járulnak hozzá ehhez a hibához.
Megjegyzés:
A rendszer üzemidejét gondosan kell meghatározni. Egy olyan rendszerben, amely redundanciát használ a maximális rendelkezésre állás biztosításához, előfordulhat, hogy az egyes elemek példányai meghiúsulnak, de a rendszer működőképes maradhat. Az állapotmonitorozás által bemutatott rendszer-üzemidőnek az egyes elemek összesített üzemidejét kell jeleznie, és nem feltétlenül azt, hogy a rendszer valóban leállt-e. Emellett előfordulhat, hogy a hibák el lesznek különítve. Így még akkor is, ha egy adott rendszer nem érhető el, a rendszer többi része továbbra is elérhető marad, bár csökkent funkcionalitással. (Egy e-kereskedelmi rendszerben a rendszer hibája megakadályozhatja, hogy az ügyfél megrendeléseket küldjön, de az ügyfél továbbra is böngészhet a termékkatalógusban.)
Riasztási célokból a rendszernek képesnek kell lennie eseményt létrehozni, ha a magas szintű jelzők bármelyike meghaladja a megadott küszöbértéket. A magas szintű jelzőt alkotó különböző tényezők alacsonyabb szintű részleteinek környezeti adatokként kell rendelkezésre állniuk a riasztási rendszer számára.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
Az SLA-monitorozás támogatásához szükséges nyers adatok hasonlóak a teljesítményfigyeléshez szükséges nyers adatokhoz, valamint az állapot- és rendelkezésre állásfigyelés néhány aspektusához. (További részletekért tekintse meg ezeket a szakaszokat.) Ezeket az adatokat a következő módon rögzítheti:
- Végpontfigyelés végrehajtása.
- Naplózási kivételek, hibák és figyelmeztetések.
- A felhasználói kérések végrehajtásának nyomon követése.
- A rendszer által használt külső szolgáltatások rendelkezésre állásának monitorozása.
- Teljesítménymetrikák és számlálók használata.
Minden adatnak időzítve és időbélyegzítve kell lennie.
SLA-adatok elemzése
A rendszerállapot-adatokat összesíteni kell, hogy képet lehessen készíteni a rendszer általános teljesítményéről. Az összesített adatoknak támogatniuk kell a részletezéseket is az alapul szolgáló alrendszerek teljesítményének vizsgálatához. Például a következőt kell tudnia:
- Számítsa ki a felhasználói kérelmek teljes számát egy adott időszakban, és határozza meg ezeknek a kéréseknek a sikerességét és sikertelenségét.
- A felhasználói kérések válaszidejének egyesítése a rendszer válaszidejének általános nézetének létrehozásához.
- Elemezze a felhasználói kérések előrehaladását, hogy a kérések teljes válaszideje az adott kérelem egyes munkaelemeinek válaszideje szerint legyen lebontva.
- Határozza meg a rendszer általános rendelkezésre állását az üzemidő százalékos arányában bármely adott időszakra vonatkozóan.
- Elemezze a rendszer egyes összetevőinek és szolgáltatásainak százalékos rendelkezésre állását. Ez magában foglalhatja a külső szolgáltatások által létrehozott naplók elemzését.
Számos kereskedelmi rendszernek kell valós teljesítményadatokat jelentenie egy meghatározott időszakra, jellemzően egy hónapra vonatkozóan. Ezek az információk felhasználhatók az ügyfelek kreditjeinek vagy egyéb visszafizetési formáinak kiszámítására, ha az SLA-k nem teljesülnek ebben az időszakban. A szolgáltatás rendelkezésre állásának kiszámításához használja a rendelkezésre állási adatok elemzése című szakaszban ismertetett technikát.
Belső célokból a szervezet nyomon követheti a szolgáltatások meghiúsulását okozó incidensek számát és jellegét is. A problémák gyors megoldásának vagy teljes megszüntetésének elsajátítása segít csökkenteni az állásidőt, és megfelelni az SLA-knak.
Könyvvizsgálat
Az alkalmazás jellegétől függően lehetnek olyan törvényi vagy egyéb jogi szabályozások, amelyek meghatározzák a felhasználók műveleteinek naplózására és az összes adathozzáférés rögzítésére vonatkozó követelményeket. A naplózás olyan bizonyítékokat nyújthat, amelyek az ügyfeleket adott kérésekhez kötik. A meg nem felelés fontos tényező számos e-üzleti rendszerben, hogy a bizalom megmaradjon az ügyfél és az alkalmazásért vagy szolgáltatásért felelős szervezet között.
A naplózás követelményei
Az elemzőnek képesnek kell lennie nyomon követni a felhasználók által végrehajtott üzleti műveletek sorrendjét, hogy rekonstruálhassa a felhasználók műveleteit. Erre szükség lehet egyszerűen a nyilvántartás, vagy egy törvényszéki vizsgálat részeként.
A naplózási adatok nagyon érzékenyek. Valószínűleg olyan adatokat is tartalmazni fog, amelyek azonosítják a rendszer felhasználóit, valamint az általuk végrehajtott feladatokat. Ezért a naplózási információk nagy valószínűséggel olyan jelentések formájában jelennek meg, amelyek csak megbízható elemzők számára érhetők el, nem pedig interaktív rendszerként, amely támogatja a grafikus műveletek lehatolását. Az elemzőknek képesnek kell lenniük jelentések sorozatának létrehozására. Előfordulhat például, hogy a jelentések felsorolják a felhasználók adott időkeretben végzett tevékenységeit, részletezik egy felhasználó tevékenységének időrendjét, vagy felsorolják az egy vagy több erőforráson végrehajtott műveletek sorrendjét.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
A naplózás elsődleges információforrásai a következők lehetnek:
- A felhasználói hitelesítést kezelő biztonsági rendszer.
- A felhasználói tevékenységet rögzítő nyomkövetési naplók.
- Az összes azonosítható és azonosíthatatlan hálózati kérést nyomon követő biztonsági naplók.
A naplózási adatok formátumát és tárolási módját szabályozási követelmények vezérelhetik. Előfordulhat például, hogy semmilyen módon nem lehet megtisztítani az adatokat. (Az eredeti formátumban kell rögzíteni.) A jogosulatlan hozzáférés megakadályozása érdekében védeni kell annak az adattárnak a hozzáférését, ahol a tárház található.
Naplózási adatok elemzése
Az elemzőknek teljes egészében, eredeti formájukban kell tudniuk hozzáférni a nyers adatokhoz. A gyakori auditjelentések létrehozásának követelménye mellett az adatok elemzésére szolgáló eszközök valószínűleg specializáltak, és a rendszeren kívül maradnak.
Használatfigyelés
A használatfigyelés nyomon követi az alkalmazások funkcióinak és összetevőinek használatát. Az operátor az összegyűjtött adatokat a következő célra használhatja:
Határozza meg, hogy mely szolgáltatásokat használják nagy mértékben, és határozza meg a rendszer esetleges hotspotjait. A nagy forgalmú elemek kihasználhatják a funkcionális particionálást vagy akár a replikációt is a terhelés egyenletesebb elosztása érdekében. Az operátorok ezen információk segítségével megállapíthatják, hogy mely funkciókat használják ritkán, és lehetséges, hogy a rendszer egy későbbi verziójában nyugdíjba vonulnak vagy lecserélik azokat.
Szerezze be a rendszer normál használatú működési eseményeire vonatkozó információkat. Egy e-kereskedelmi webhelyen például rögzítheti a tranzakciók számával és a felelős ügyfelek mennyiségével kapcsolatos statisztikai adatokat. Ez az információ a kapacitástervezéshez használható az ügyfelek számának növekedésével.
Észlelheti (esetleg közvetve) a felhasználók elégedettségét a rendszer teljesítményével vagy funkciójával. Ha például egy e-kereskedelmi rendszerben sok ügyfél rendszeresen elhagyja a bevásárlókosarait, ennek oka a pénztár funkcióval kapcsolatos probléma lehet.
Számlázási adatok létrehozása. Egy kereskedelmi alkalmazás vagy több-bérlős szolgáltatás díjat számíthat fel az ügyfeleknek az általuk használt erőforrásokért.
Kvóták kikényszerítése. Ha egy több-bérlős rendszerben egy felhasználó túllépi a megadott időszakban a feldolgozási idő vagy az erőforrás-használat fizetős kvótáját, a hozzáférése korlátozott lehet, vagy a feldolgozás szabályozható.
A használat monitorozásának követelményei
A rendszerhasználat vizsgálatához az operátornak általában a következőket tartalmazó információkat kell látnia:
- Az egyes alrendszerek által feldolgozott és az egyes erőforrásokhoz irányított kérések száma.
- Az egyes felhasználók által végzett munka.
- Az egyes felhasználók által használt adattárolás mennyisége.
- Az egyes felhasználók által elért erőforrások.
Egy operátornak képesnek kell lennie grafikonok létrehozására is. Egy grafikonon például megjelenhetnek a leginkább erőforrás-éhes felhasználók, illetve a leggyakrabban használt erőforrások vagy rendszerfunkciók.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
A használat nyomon követése viszonylag magas szinten végezhető el. Az egyes kérések kezdési és befejezési idejét, valamint a kérés természetét (olvasás, írás stb. a kérdéses erőforrástól függően) jegyezheti fel. Ezeket az információkat a következő módon szerezheti be:
- Felhasználói tevékenység nyomon követése.
- Az egyes erőforrások kihasználtságát mérő teljesítményszámlálók rögzítése.
- Az erőforrás-felhasználás monitorozása minden felhasználó számára.
Mérés céljából azt is meg kell tudnia állapítani, hogy mely felhasználók felelősek a műveletek végrehajtásáért, valamint azokat az erőforrásokat, amelyeket ezek a műveletek használnak. Az összegyűjtött adatoknak elég részletesnek kell lenniük a pontos számlázáshoz.
Problémakövetés
Az ügyfelek és más felhasználók problémákat jelenthetnek, ha váratlan események vagy viselkedés történik a rendszerben. A problémakövetés a problémák kezelésével, a rendszer bármilyen mögöttes problémájának megoldására irányuló erőfeszítésekkel való társításával és az ügyfelek lehetséges megoldásairól való tájékoztatásával foglalkozik.
A problémakövetés követelményei
Az operátorok gyakran egy külön rendszer használatával végzik el a problémák nyomon követését, amely lehetővé teszi számukra a felhasználók által jelentett problémák részleteinek rögzítését és jelentését. Ezek a részletek magukban foglalhatják a felhasználó által végrehajtani kívánt feladatokat, a probléma tüneteit, az események sorrendjét, valamint a kiadott hibaüzeneteket vagy figyelmeztető üzeneteket.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
A problémakövetési adatok kezdeti adatforrása az a felhasználó, aki először jelentette a problémát. A felhasználó további adatokat is megadhat, például:
- Összeomlási memóriakép (ha az alkalmazás tartalmaz egy összetevőt, amely a felhasználó asztalán fut).
- Képernyő pillanatképe.
- A hiba bekövetkezésének dátuma és időpontja, valamint minden egyéb környezeti információ, például a felhasználó tartózkodási helye.
Ezek az információk segíthetnek a hibakeresési erőfeszítésekben, és segíthetnek a szoftver jövőbeli kiadásainak hátralékának összeállításában.
Problémakövetési adatok elemzése
Előfordulhat, hogy a különböző felhasználók ugyanazt a problémát jelentik. A problémakövető rendszernek közös jelentéseket kell társítania.
A hibakeresési munka előrehaladását minden problémajelentésben rögzíteni kell. A probléma megoldása után az ügyfél tájékoztatást kaphat a megoldásról.
Ha egy felhasználó olyan hibát jelez, amely ismert megoldással rendelkezik a problémakövető rendszerben, az operátornak képesnek kell lennie arra, hogy azonnal tájékoztassa a felhasználót a megoldásról.
Nyomkövetési műveletek és szoftverkiadások hibakeresése
Amikor egy felhasználó jelentést tesz egy problémáról, a felhasználó gyakran csak arról tud, hogy milyen azonnali hatása van a műveleteire. A felhasználó csak a saját tapasztalataik eredményeit jelentheti vissza egy olyan operátornak, aki a rendszer fenntartásáért felelős. Ezek a tapasztalatok általában csak egy vagy több alapvető probléma látható tünete. Sok esetben az elemzőnek át kell ásnia a mögöttes műveletek kronológiáját a probléma kiváltó okának megállapításához. Ezt a folyamatot kiváltó okok elemzésének nevezzük.
Megjegyzés:
A kiváltó okok elemzése során előfordulhat, hogy nem hatékonyak az alkalmazások tervezése során. Ilyen esetekben lehetséges lehet az érintett elemek újradolgozása és üzembe helyezése egy későbbi kiadás részeként. Ez a folyamat gondos ellenőrzést igényel, és a frissített összetevőket szorosan figyelni kell.
A nyomkövetésre és a hibakeresésre vonatkozó követelmények
A váratlan események és egyéb problémák nyomon követéséhez elengedhetetlen, hogy a monitorozási adatok elegendő információt adjanak ahhoz, hogy az elemzők visszakövethessék a problémák eredetét, és rekonstruálhassák a bekövetkezett események sorrendjét. Ennek az információnak elegendőnek kell lennie ahhoz, hogy az elemző diagnosztizálhassa a problémák kiváltó okát. A fejlesztő ezután elvégezheti a szükséges módosításokat, hogy megakadályozza őket az ismétlődésben.
Adatforrások, rendszerállapot és adatgyűjtési követelmények
A hibaelhárítás magában foglalhatja a művelet részeként meghívott összes metódus (és paraméter) nyomon követését egy olyan fa létrehozásához, amely a rendszeren keresztüli logikai folyamatot ábrázolja, amikor egy ügyfél egy adott kérést küld. A folyamat eredményeként a rendszer által generált kivételeket és figyelmeztetéseket rögzíteni és naplózni kell.
A hibakeresés támogatásához a rendszer olyan horgokat tud biztosítani, amelyek lehetővé teszik az operátor számára az állapotinformációk rögzítését a rendszer kritikus pontjain. Vagy a rendszer részletes, lépésenkénti információkat is képes szolgáltatni a kiválasztott műveletek előrehaladása során. Az adatok ilyen szintű rögzítése további terhelést róhat a rendszerre, és ideiglenes folyamatnak kell lennie. Az operátor elsősorban akkor használja ezt a folyamatot, ha rendkívül szokatlan események sorozata történik, és nehezen replikálható, vagy ha egy vagy több elem új kiadása egy rendszerbe gondos monitorozást igényel annak biztosítása érdekében, hogy az elemek a várt módon működjenek.
A monitorozási és diagnosztikai folyamat
A kiterjedt, elosztott rendszerek megfigyelése meglehetősen nehéz. Az előző szakaszban leírt forgatókönyvek nem feltétlenül tekinthetők külön-külön. Az egyes helyzetekhez szükséges monitorozási és diagnosztikai adatok között valószínűleg jelentős átfedés van, bár előfordulhat, hogy ezeket az adatokat különböző módokon kell feldolgozni és bemutatni. Ezen okok miatt holisztikusan kell áttekintenie a monitorozást és a diagnosztikát.
A teljes monitorozási és diagnosztikai folyamatot az 1. ábrán látható szakaszokból álló folyamatként képzelheti el.
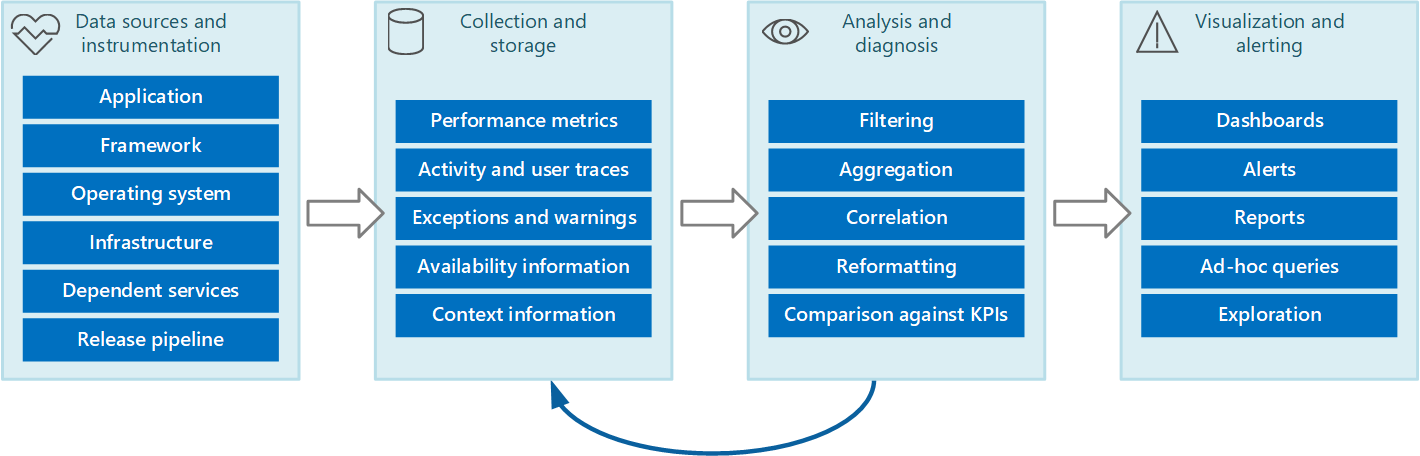
1. ábra – A monitorozási és diagnosztikai folyamat szakaszai.
Az 1. ábra azt mutatja be, hogyan származhatnak a monitorozási és diagnosztikai adatok különböző adatforrásokból. A rendszerezés és a gyűjtési szakaszok az adatok rögzítésének forrásainak azonosításával, a rögzítendő adatok meghatározásával, az adatok rögzítésének módjával és az adatok könnyű vizsgálatának módjával kapcsolatosak. Az elemzési/diagnosztikai fázis a nyers adatokat veszi át, és azokat arra használja, hogy értelmes információkat hozzon létre, amelyeket az operátorok a rendszer állapotának meghatározására használhatnak. Az operátor ezeket az információkat arra használhatja, hogy döntéseket hozzon a végrehajtandó lehetséges műveletekről, majd az eredményeket visszatáplálódjon a rendszerállapot és a gyűjtési fázisokba. A vizualizációs/riasztási fázis a rendszerállapot hasznos nézetét jeleníti meg. Az irányítópultok sorozatával közel valós időben jelenítheti meg az információkat. Emellett jelentéseket, grafikonokat és diagramokat is létrehozhat, amelyek előzménynézetet biztosítanak az adatokról, amelyek segítenek azonosítani a hosszú távú trendeket. Ha az információk azt jelzik, hogy a KPI valószínűleg meghaladja az elfogadható korlátokat, ez a szakasz riasztást is indíthat egy operátor számára. Bizonyos esetekben a riasztások olyan automatizált folyamat indítására is használhatók, amelyek korrekciós műveleteket, például automatikus skálázást kísérelnek meg végrehajtani.
Vegye figyelembe, hogy ezek a lépések folyamatos folyamatot alkotnak, ahol a szakaszok párhuzamosan történnek. Ideális esetben az összes fázisnak dinamikusan konfigurálhatónak kell lennie. Bizonyos esetekben, különösen akkor, ha egy rendszer újonnan lett üzembe helyezve, vagy problémákat tapasztal, előfordulhat, hogy gyakrabban kell kiterjesztett adatokat gyűjteni. Máskor lehetővé kell tenni, hogy vissza lehessen állítani az alapvető információk alapszintjének rögzítését annak ellenőrzéséhez, hogy a rendszer megfelelően működik-e.
Emellett a teljes monitorozási folyamatot élő, folyamatban lévő megoldásnak kell tekinteni, amelynek finomhangolása és fejlesztése a visszajelzések eredményeként történik. Előfordulhat például, hogy számos tényező mérésével határozza meg a rendszer állapotát. Az időalapú elemzés finomításhoz vezethet, mivel elveti a nem releváns mértékeket, így pontosabban összpontosíthat a szükséges adatokra, miközben minimalizálja a háttérzajt.
A monitorozási és diagnosztikai adatok forrásai
A monitorozási folyamat által használt információk több forrásból is származhatnak, az 1. ábrán látható módon. Az alkalmazás szintjén az információk a rendszer kódjába beépített nyomkövetési naplókból származnak. A fejlesztőknek szabványos megközelítést kell követniük a vezérlési folyamat kódon keresztüli nyomon követéséhez. Egy metódus bejegyzése például olyan nyomkövetési üzenetet tud kibocsátani, amely megadja a metódus nevét, az aktuális időt, az egyes paraméterek értékét és minden egyéb kapcsolódó információt. A be- és kilépési idők rögzítése is hasznosnak bizonyulhat.
Minden kivételt és figyelmeztetést naplóznia kell, és gondoskodnia kell arról, hogy a beágyazott kivételek és figyelmeztetések teljes nyomkövetése megmaradjon. Ideális esetben olyan információkat is rögzítenie kell, amelyek azonosítják a kódot futtató felhasználót, valamint a tevékenység korrelációs adatait (a kérések nyomon követéséhez a rendszeren áthaladva). Naplóznia kell az összes erőforrás elérésére tett kísérleteket, például üzenetsorokat, adatbázisokat, fájlokat és egyéb függő szolgáltatásokat. Ezek az információk mérési és naplózási célokra használhatók.
Számos alkalmazás kódtárakat és keretrendszereket használ olyan gyakori feladatok végrehajtásához, mint az adattár elérése vagy a hálózaton keresztüli kommunikáció. Ezek a keretrendszerek konfigurálhatók úgy, hogy saját nyomkövetési üzeneteket és nyers diagnosztikai információkat, például tranzakciós arányokat és adatátviteli sikereket és hibákat nyújtsanak.
Megjegyzés:
Számos modern keretrendszer automatikusan közzéteszi a teljesítmény- és nyomkövetési eseményeket. Ezeknek az információknak a rögzítése egyszerűen csak egy eszköz biztosítása annak lekéréséhez és tárolásához, ahol feldolgozható és elemezhető.
Az az operációs rendszer, amelyen az alkalmazás fut, alacsony szintű rendszerszintű információk forrása lehet, például az I/O-sebességeket, a memóriahasználatot és a processzorhasználatot jelző teljesítményszámlálók. Az operációs rendszer hibáit (például a fájl helyes megnyitásának sikertelenségét) is jelentheti.
Figyelembe kell vennie azokat az alapul szolgáló infrastruktúrát és összetevőket is, amelyeken a rendszer fut. A virtuális gépek, a virtuális hálózatok és a tárolási szolgáltatások mind fontos infrastruktúraszintű teljesítményszámlálók és egyéb diagnosztikai adatok forrásai lehetnek.
Ha az alkalmazás más külső szolgáltatásokat, például webkiszolgálót vagy adatbázis-kezelő rendszert használ, ezek a szolgáltatások közzétehetik saját nyomkövetési adataikat, naplóikat és teljesítményszámlálóikat. Ilyenek például az SQL Server dinamikus felügyeleti nézetei az SQL Server-adatbázison végrehajtott műveletek nyomon követéséhez, valamint a webkiszolgálóra irányuló kérések rögzítésére szolgáló IIS-nyomkövetési naplók.
A rendszer összetevőinek módosítása és az új verziók üzembe helyezése során fontos, hogy a problémákat, eseményeket és metrikákat az egyes verziókhoz lehessen hozzárendelni. Ezeket az információkat vissza kell kötni a kiadási folyamathoz, hogy az összetevők egy adott verziójával kapcsolatos problémák gyorsan nyomon követhetők és kijavíthatók legyenek.
A rendszer bármely pontján biztonsági problémák léphetnek fel. Előfordulhat például, hogy egy felhasználó érvénytelen felhasználói azonosítóval vagy jelszóval próbál bejelentkezni. Egy hitelesített felhasználó megpróbálhat jogosulatlan hozzáférést szerezni egy erőforráshoz. Vagy egy felhasználó érvénytelen vagy elavult kulcsot adhat meg a titkosított információk eléréséhez. A sikeres és sikertelen kérelmek biztonsági adatait mindig naplózni kell.
Az alkalmazás rendszerezése című szakasz további útmutatást tartalmaz a rögzítendő információkról. A következő információk gyűjtésére azonban többféle stratégia is használható:
Alkalmazás-/rendszerfigyelés. Ez a stratégia belső forrásokat használ az alkalmazáson, az alkalmazás-keretrendszereken, az operációs rendszeren és az infrastruktúrán belül. Az alkalmazáskód képes saját monitorozási adatokat létrehozni az ügyfélkérés életciklusa során jelentős pontokon. Az alkalmazás tartalmazhat olyan nyomkövetési utasításokat, amelyek a körülmények diktálása szerint szelektíven engedélyezhetők vagy letilthatók. A diagnosztikát dinamikusan is injektálhatja egy diagnosztikai keretrendszer használatával. Ezek a keretrendszerek általában olyan beépülő modulokat biztosítanak, amelyek a kód különböző rendszerállapot-pontjaihoz csatolhatók, és ezeken a pontokon rögzítik a nyomkövetési adatokat.
Emellett a kód vagy a mögöttes infrastruktúra kritikus pontokon is eseményeket eredményezhet. Az események figyelésére konfigurált figyelési ügynökök rögzíthetik az eseményadatokat.
Valós felhasználófigyelés. Ez a megközelítés rögzíti a felhasználó és az alkalmazás közötti interakciókat, és megfigyeli az egyes kérések és válaszok folyamatát. Ennek az információnak kétirányú célja lehet: felhasználható az egyes felhasználók általi fogyasztásméréshez, és annak meghatározására, hogy a felhasználók megfelelő minőségű szolgáltatást kapnak-e (például gyors válaszidők, alacsony késés és minimális hibák). A rögzített adatok segítségével azonosíthatja azokat a területeket, ahol a leggyakrabban előfordulnak hibák. Az adatokkal azonosíthatja azokat az elemeket is, amelyekben a rendszer lelassul, esetleg az alkalmazásban lévő hotspotok vagy más szűk keresztmetszetek miatt. Ha gondosan implementálja ezt a megközelítést, hibakeresési és tesztelési célokból lehetséges lehet rekonstruálni a felhasználók folyamatait az alkalmazásban.
Fontos
A valós felhasználók monitorozásával rögzített adatokat rendkívül bizalmasnak kell tekinteni, mert bizalmas adatokat tartalmazhatnak. Ha mentette a rögzített adatokat, tárolja biztonságosan. Ha teljesítményfigyelési vagy hibakeresési célokra szeretné használni az adatokat, először törölje az összes személyes adatot.
Szintetikus felhasználói figyelés. Ebben a megközelítésben saját tesztügyfélt ír, amely szimulál egy felhasználót, és konfigurálható, de tipikus műveletek sorozatát hajtja végre. Nyomon követheti a tesztügyfél teljesítményét a rendszer állapotának meghatározásához. A terheléstesztelési művelet részeként a tesztügyfél több példányát is használhatja annak megállapításához, hogy a rendszer hogyan reagál stresszhelyzetben, és milyen típusú monitorozási kimenet jön létre ilyen körülmények között.
Megjegyzés:
Valós és szintetikus felhasználói monitorozást valósíthat meg a metódushívások és az alkalmazás egyéb kritikus részeinek követését és idejét nyomon követő kódokkal.
Profilkészítés. Ez a megközelítés elsősorban az alkalmazások teljesítményének monitorozására és javítására irányul. Ahelyett, hogy a valós és szintetikus felhasználói monitorozás funkcionális szintjén működjön, az alkalmazás futtatásakor az alacsonyabb szintű információkat rögzíti. A profilkészítést az alkalmazás végrehajtási állapotának rendszeres mintavételezésével valósíthatja meg (annak meghatározásával, hogy az alkalmazás melyik kódrészlete fut egy adott időpontban). Olyan eszközrendszert is használhat, amely mintavételeket szúr be a kódba fontos szakaszokban (például egy metódushívás kezdete és vége), valamint rögzíti, hogy mely metódusok voltak meghívva, mikor és mennyi ideig tartott az egyes hívások. Ezután elemezheti ezeket az adatokat annak megállapításához, hogy az alkalmazás mely részei okozhatnak teljesítményproblémát.
Végpontfigyelés. Ez a technika egy vagy több diagnosztikai végpontot használ, amelyeket az alkalmazás kifejezetten a figyelés engedélyezéséhez tesz elérhetővé. A végpont egy útvonalat biztosít az alkalmazás kódjába, és képes a rendszer állapotára vonatkozó információkat visszaadni. A különböző végpontok a funkciók különböző aspektusaira összpontosíthatnak. Írhat saját diagnosztikai ügyfelet, amely rendszeres kéréseket küld ezeknek a végpontoknak, és asszimilálja a válaszokat. További információkért tekintse meg az állapotvégpont monitorozási mintáját.
A maximális lefedettség érdekében ezen technikák kombinációját kell használnia.
Alkalmazás rendszerezése
A rendszerállapot a monitorozási folyamat kritikus része. A rendszer teljesítményével és állapotával kapcsolatban csak akkor hozhat értelmes döntéseket, ha először rögzíti azokat az adatokat, amelyek lehetővé teszik ezeknek a döntéseknek a meghozatalát. A rendszerállapot használatával gyűjtött információknak elegendőnek kell lenniük ahhoz, hogy felmérhessék a teljesítményt, diagnosztizálhassák a problémákat, és döntéseket hozhassanak anélkül, hogy a távoli éles kiszolgálóra kellene bejelentkeznie a nyomkövetés (és hibakeresés) manuális elvégzéséhez. A rendszerállapot-adatok általában a nyomkövetési naplókba írt metrikákat és információkat tartalmazzák.
A nyomkövetési napló tartalma lehet az alkalmazás által írt szöveges adatok vagy egy nyomkövetési esemény eredményeként létrehozott bináris adatok eredménye, ha az alkalmazás Eseménykövetést használ Windowshoz (ETW). Ezek olyan rendszernaplókból is létrehozhatók, amelyek rögzítik az infrastruktúra egyes részeiből, például egy webkiszolgálóról származó eseményeket. A szöveges naplóüzeneteket gyakran emberi olvasásra tervezték, de olyan formátumban is meg kell őket írni, amely lehetővé teszi, hogy egy automatizált rendszer könnyen elemezhesse őket.
A naplókat is kategorizálnia kell. Ne írjon minden nyomkövetési adatot egyetlen naplóba, hanem használjon külön naplókat a rendszer különböző működési aspektusaiból származó nyomkövetési kimenet rögzítéséhez. Ezután gyorsan szűrheti a naplóüzeneteket úgy, hogy a megfelelő naplóból olvas, nem pedig egyetlen hosszú fájlt kell feldolgoznia. Soha ne írjon más biztonsági követelményekkel (például naplózási adatokkal és hibakeresési adatokkal) kapcsolatos információkat ugyanarra a naplóra.
Megjegyzés:
A naplók fájlként implementálhatók a fájlrendszerben, vagy más formátumban is tárolhatók, például blobként a Blob Storage-ban. A naplóadatok strukturáltabb tárolókban is tárolhatók, például egy tábla soraiban.
A metrikák általában a rendszer bizonyos aspektusainak vagy erőforrásainak mértéke vagy száma egy adott időpontban, egy vagy több társított címkével vagy dimenzióval (más néven mintával). A metrikák egyetlen példánya általában nem használható külön-külön. Ehelyett a metrikákat idővel rögzíteni kell. A legfontosabb megfontolandó probléma az, hogy milyen metrikákat kell rögzítenie, és milyen gyakran. A metrikák adatainak túl gyakran történő generálása jelentős többletterhelést okozhat a rendszeren, míg a metrikák ritkán történő rögzítése miatt kihagyhatja azokat a körülményeket, amelyek jelentős eseményhez vezetnek. A szempontok metrika szerint változnak. A kiszolgáló processzorhasználata például jelentősen eltérhet a másodiktól a másodikig, de a magas kihasználtság csak akkor válik problémává, ha hosszú ideig tart néhány perc alatt.
Adatok korrelációjának információi
Egyszerűen monitorozhatja az egyes rendszerszintű teljesítményszámlálókat, rögzítheti az erőforrások mérőszámait, és alkalmazáskövetési információkat kérhet le különböző naplófájlokból. A monitorozás bizonyos formái azonban megkövetelik a monitorozási folyamat elemzési és diagnosztikai szakaszát a több forrásból lekért adatok korrelálásához. Ezek az adatok több űrlapot is tartalmazhatnak a nyers adatokban, és az elemzési folyamatnak elegendő rendszerállapot-adattal kell rendelkeznie ahhoz, hogy leképezhesse ezeket a különböző űrlapokat. Az alkalmazás-keretrendszer szintjén például egy tevékenység szálazonosítóval azonosítható. Egy alkalmazáson belül ugyanez a munka társítható az adott feladatot végrehajtó felhasználó felhasználói azonosítójával.
Emellett nem valószínű, hogy 1:1 leképezés történik a szálak és a felhasználói kérések között, mert az aszinkron műveletek ugyanazokat a szálakat használhatják fel a műveletek több felhasználó nevében történő végrehajtásához. A további bonyolítás érdekében egyetlen kérést több szál is kezelhet, miközben a végrehajtás a rendszeren halad át. Ha lehetséges, társítsa az egyes kéréseket egy egyedi tevékenységazonosítóval, amelyet a rendszer a kérelemkörnyezet részeként propagál. (A tevékenységazonosítók nyomkövetési információkban való létrehozására és belefoglalására szolgáló technika a nyomkövetési adatok rögzítéséhez használt technológiától függ.)
Minden monitorozási adatot ugyanúgy kell időzíteni. A konzisztencia érdekében rögzítse az összes dátumot és időpontot a koordinált univerzális idő használatával. Ez segít könnyebben nyomon követni az események sorozatait.
Megjegyzés:
Előfordulhat, hogy a különböző időzónákban és hálózatokban működő számítógépek nem szinkronizálódnak. Ne függenek attól, hogy csak időbélyegeket használnak a több gépet felölelő rendszerállapot-adatok korrelálására.
A rendszerállapot-adatokba belefoglalandó információk
Vegye figyelembe a következő szempontokat, amikor eldönti, hogy milyen rendszerállapot-adatokat kell gyűjtenie:
Győződjön meg arról, hogy a nyomkövetési események által rögzített információk gépi és emberi olvashatók. A naplóadatok rendszerek közötti automatizált feldolgozásának megkönnyítése, valamint a naplókat olvasó üzemeltetési és mérnöki személyzet konzisztenciájának biztosítása érdekében jól definiált sémákat alkalmazhat ezekhez az információkhoz. Adjon meg környezeti információkat, például az üzembehelyezési környezetet, a folyamatot futtató gépet, a folyamat részleteit és a hívásvermet.
Csak akkor engedélyezze a profilkészítést, ha szükséges, mert jelentős többletterhelést okozhat a rendszeren. A rendszerállapot használatával végzett profilkészítés minden alkalommal rögzít egy eseményt (például metódushívást), míg a mintavételezés csak a kiválasztott eseményeket rögzíti. A kijelölés lehet időalapú ( n másodpercenként egyszer) vagy gyakoriságalapú (minden n kérés esetén). Ha az események nagyon gyakran fordulnak elő, a rendszerállapot szerinti profilkészítés túl nagy terhet okozhat, és maga is hatással lehet az általános teljesítményre. Ebben az esetben a mintavételezési módszer előnyösebb lehet. Ha azonban az események gyakorisága alacsony, előfordulhat, hogy a mintavételezés kihagyja őket. Ebben az esetben a rendszerezés lehet a jobb megközelítés.
Adjon meg elegendő környezetet ahhoz, hogy egy fejlesztő vagy rendszergazda meghatározhassa az egyes kérések forrását. Ez tartalmazhat valamilyen tevékenységazonosítót, amely azonosítja a kérés egy adott példányát. Olyan információkat is tartalmazhat, amelyek segítségével korrelálható ez a tevékenység az elvégzett számítási munkával és a felhasznált erőforrásokkal. Vegye figyelembe, hogy ez a munka átlépheti a folyamat és a gép határait. A méréshez a kontextusnak tartalmaznia kell (közvetlenül vagy közvetve más korrelált információkon keresztül) a kérelmet létrehozó ügyfélre mutató hivatkozást is. Ez a környezet értékes információkat nyújt az alkalmazás állapotáról a monitorozási adatok rögzítésekor.
Rögzítse az összes kérést, valamint azokat a helyeket vagy régiókat, amelyekből ezeket a kéréseket kéri. Ezek az információk segíthetnek annak meghatározásában, hogy vannak-e helyspecifikus hotspotok. Ezek az információk annak meghatározásában is hasznosak lehetnek, hogy egy alkalmazás vagy az általa használt adatok újraparticionálására van-e szükség.
A kivételek részleteit gondosan rögzítse és rögzítse. A kritikus hibakeresési információk gyakran elvesznek a gyenge kivételkezelés miatt. Rögzítse az alkalmazás által kiadott kivételek teljes részleteit, beleértve a belső kivételeket és egyéb környezeti információkat. Ha lehetséges, vegye fel a hívásvermet.
Konzisztensnek kell lennie az alkalmazás különböző elemei által rögzített adatokban, mert ez segíthet az események elemzésében és a felhasználói kérésekkel való korrelációban. Fontolja meg egy átfogó és konfigurálható naplózási csomag használatát az információk gyűjtéséhez, ahelyett, hogy a fejlesztőktől függenek, hogy ugyanazt a megközelítést alkalmazzák, mint a rendszer különböző részeit. Adatokat gyűjthet a fő teljesítményszámlálókból, például a végrehajtott I/O mennyisége, a hálózat kihasználtsága, a kérelmek száma, a memóriahasználat és a CPU-kihasználtság. Egyes infrastruktúra-szolgáltatások saját teljesítményszámlálókat biztosíthatnak, például az adatbázishoz való csatlakozások számát, a tranzakciók végrehajtásának sebességét, valamint a sikeres vagy sikertelen tranzakciók számát. Az alkalmazások saját teljesítményszámlálókat is meghatározhatnak.
Naplózza a külső szolgáltatásokra, például adatbázisrendszerekre, webszolgáltatásokra vagy az infrastruktúra részét képező egyéb rendszerszintű szolgáltatásokra irányuló összes hívást. Jegyezze fel az egyes hívások végrehajtásához szükséges időt, valamint a hívás sikerességét vagy sikertelenségét. Ha lehetséges, rögzítse az összes újrapróbálkozási kísérletről és hibáról az esetleges átmeneti hibákra vonatkozó információkat.
A telemetriai rendszerekkel való kompatibilitás biztosítása
A rendszerállapot által generált információk sok esetben események sorozataként jönnek létre, és egy külön telemetriai rendszernek továbbítják feldolgozásra és elemzésre. A telemetriai rendszerek általában függetlenek bármely adott alkalmazástól vagy technológiától, de elvárják, hogy az információk egy adott, általában séma által meghatározott formátumot kövessenek. A séma gyakorlatilag egy szerződést határoz meg, amely meghatározza azokat az adatmezőket és típusokat, amelyeket a telemetriai rendszer betölthet. A sémát általánosítva kell engedélyezni, hogy több platformról és eszközről érkező adatok érkezhessenek.
A közös sémáknak olyan mezőket kell tartalmazniuk, amelyek az összes eszközeseményre jellemzőek, például az esemény neve, az esemény időpontja, a feladó IP-címe, valamint a más eseményekkel való korrelációhoz szükséges adatok (például felhasználói azonosító, eszközazonosító és alkalmazásazonosító). Ne feledje, hogy tetszőleges számú eszköz eseményt idézhet elő, ezért a séma nem függhet az eszköz típusától. Emellett a különböző eszközök eseményeket is eredményezhetnek ugyanahhoz az alkalmazáshoz; az alkalmazás támogathatja a barangolást vagy az eszközközi terjesztés más formáját.
A séma olyan tartománymezőket is tartalmazhat, amelyek egy adott, különböző alkalmazásokban gyakori forgatókönyv szempontjából relevánsak. Ezek lehetnek kivételekre, alkalmazásindítási és befejezési eseményekre, valamint a webszolgáltatás API-hívásainak sikerességére vagy sikertelenségére vonatkozó információk. Minden olyan alkalmazásnak, amely ugyanazt a tartománymezőkészletet használja, ugyanazt az eseménykészletet kell kibocsátania, ami lehetővé teszi a gyakori jelentések és elemzések létrehozását.
Végül egy séma tartalmazhat egyéni mezőket az alkalmazásspecifikus események részleteinek rögzítéséhez.
Ajánlott eljárások az alkalmazások rendszerezéséhez
Az alábbi lista összefoglalja a felhőben futó elosztott alkalmazások rendszerezésének ajánlott eljárásait.
A naplók könnyen olvashatóvá és könnyen elemezhetővé tétele. Ahol csak lehetséges, használjon strukturált naplózást. Legyen tömör és leíró a naplóüzenetekben.
Minden naplóban azonosítsa a forrást, és adjon meg környezeti és időzítési információkat az egyes naplórekordok írása során.
Használja ugyanazt az időzónát és formátumot minden időbélyeghez. Ez segít korrelálni a különböző földrajzi régiókban futó hardverekre és szolgáltatásokra kiterjedő műveletek eseményeit.
Naplók kategorizálása és üzenetek írása a megfelelő naplófájlba.
Ne tegyen közzé bizalmas információkat a rendszerről vagy a felhasználók személyes adatairól. A naplózás előtt mossa le ezeket az adatokat, de győződjön meg arról, hogy a vonatkozó adatok megmaradnak. Távolítsa el például az azonosítót és a jelszót az adatbázis kapcsolati sztringjeiből, de írja be a fennmaradó adatokat a naplóba, hogy az elemző megállapíthassa, hogy a rendszer a megfelelő adatbázishoz fér-e hozzá. Naplózza az összes kritikus kivételt, de engedélyezze a rendszergazda számára, hogy be- és kikapcsolja a naplózást az alacsonyabb szintű kivételek és figyelmeztetések esetében. Emellett rögzítse és naplózza az újrapróbálkozási logikai adatokat. Ezek az adatok hasznosak lehetnek a rendszer átmeneti állapotának monitorozásában.
Nyomon követheti a folyamathívásokat, például külső webszolgáltatásokra vagy adatbázisokra irányuló kéréseket.
Ne keverje a naplóüzeneteket különböző biztonsági követelményekkel ugyanabban a naplófájlban. Ne írjon például hibakeresési és naplózási adatokat ugyanarra a naplóra.
A naplózási események kivételével győződjön meg arról, hogy minden naplózási hívás olyan tűz- és felejtési művelet, amely nem blokkolja az üzleti műveletek előrehaladását. A naplózási események azért kivételesek, mert kritikus fontosságúak az üzleti tevékenység szempontjából, és az üzleti műveletek alapvető részének tekinthetők.
Győződjön meg arról, hogy a naplózás bővíthető, és nincs közvetlen függőség egy konkrét céltól. Például aHelyett, hogy a System.Diagnostics.Trace használatával írnál adatokat, definiáljon egy absztrakt felületet (például ILogger), amely elérhetővé teszi a naplózási módszereket, és amely bármilyen megfelelő módon implementálható.
Győződjön meg arról, hogy az összes naplózás sikertelen, és soha nem vált ki kaszkádolt hibákat. A naplózás nem hozhat kivételt.
A rendszerállapot kezelése folyamatos iteratív folyamatként, és a naplók rendszeres áttekintése, nem csak akkor, ha probléma merül fel.
Adatok gyűjtése és tárolása
A monitorozási folyamat gyűjtési szakasza a rendszerállapot által generált információk lekérésével, az adatok formázásával, az elemzési/diagnosztikai szakasz felhasználásának megkönnyítésével és az átalakított adatok megbízható tárolóba való mentésével foglalkozik. Az elosztott rendszer különböző részeiből gyűjtött rendszerállapot-adatok különböző helyeken és különböző formátumokban tárolhatók. Előfordulhat például, hogy az alkalmazáskód nyomkövetési naplófájlokat hoz létre, és alkalmazásesemény-naplóadatokat hoz létre, míg az alkalmazás által használt infrastruktúra fő aspektusait monitorozó teljesítményszámlálók más technológiákkal rögzíthetők. Az alkalmazás által használt külső összetevők és szolgáltatások különböző formátumokban, különálló nyomkövetési fájlok, blobtárolók vagy akár egyéni adattárak használatával biztosíthatják a rendszerállapot-információkat.
Az adatgyűjtést gyakran olyan gyűjtési szolgáltatáson keresztül hajtják végre, amely a rendszerállapot-adatokat létrehozó alkalmazásból önállóan futtatható. A 2. ábra egy példát mutat be erre az architektúrára, kiemelve a rendszerállapot-adatgyűjtés alrendszerét.
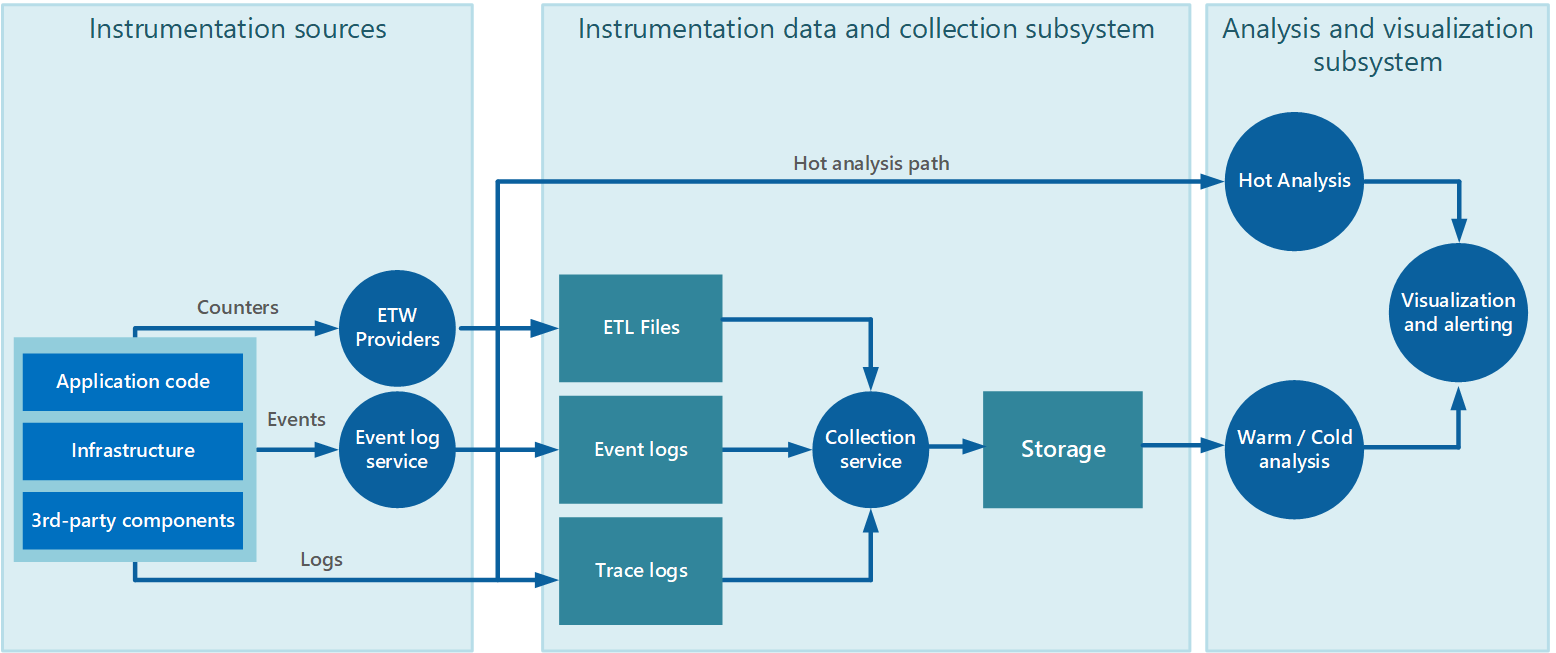
2. ábra – Rendszerállapot-adatok gyűjtése.
Vegye figyelembe, hogy ez egy egyszerűsített nézet. A gyűjtési szolgáltatás nem feltétlenül egyetlen folyamat, és számos, különböző gépen futó összetevőből állhat, az alábbi szakaszokban leírtak szerint. Továbbá, ha néhány telemetriai adat elemzését gyorsan el kell végezni (a gyakori elérésű , a meleg és a hideg elemzést támogató szakaszban leírtak szerint a dokumentum későbbi részében), a gyűjtési szolgáltatáson kívül működő helyi összetevők azonnal elvégezhetik az elemzési feladatokat. A 2. ábra ezt a helyzetet mutatja be a kiválasztott események esetében. Az elemzési feldolgozás után az eredmények közvetlenül a vizualizációs és riasztási alrendszernek küldhetők. A meleg vagy hideg elemzésnek alávetett adatok tárolásra kerülnek, amíg feldolgozásra várnak.
Az Azure-alkalmazások és -szolgáltatások esetében az Azure Diagnostics egy lehetséges megoldást kínál az adatok rögzítésére. Az Azure Diagnostics az alábbi forrásokból gyűjt adatokat minden számítási csomóponthoz, összesíti, majd feltölti azOkat az Azure Storage-ba:
- IIS-naplók
- Az IIS sikertelen kérelemnaplói
- Windows-eseménynaplók
- Teljesítményszámlálók
- Összeomlási memória-dumpok
- Az Azure Diagnostics infrastruktúra naplói
- Egyéni hibanaplók
- NET-eseményforrás
- jegyzékalapú ETW.
További információ: Azure: Telemetriai alapismeretek és hibaelhárítás.
A rendszerállapot-adatok gyűjtésének stratégiái
Figyelembe véve a felhő rugalmas jellegét, és nem szükséges manuálisan lekérni a telemetriai adatokat a rendszer minden csomópontjáról, gondoskodnia kell arról, hogy az adatok egy központi helyre kerüljenek, és konszolidálva legyenek. A több adatközpontot felölelő rendszerekben hasznos lehet először az adatok régiónkénti gyűjtése, összesítése és tárolása, majd a regionális adatok összesítése egyetlen központi rendszerbe.
A sávszélesség használatának optimalizálása érdekében dönthet úgy, hogy kötegekként kevesebb sürgős adatot továbbít az adattömbökbe. Az adatokat azonban nem szabad határozatlan ideig késleltetni, különösen akkor, ha időérzékeny információkat tartalmaznak.
Rendszerállapot-adatok lekérése és leküldése
A rendszerállapot-adatgyűjtési alrendszer aktívan lekérheti a rendszerállapot-adatokat a különböző naplókból és más forrásokból az alkalmazás egyes példányaihoz (a lekéréses modellhez). Vagy passzív fogadóként is működhet, amely megvárja, amíg az adatok az alkalmazás minden példányát alkotó összetevőkből (a leküldéses modellből) érkeznek.
A lekéréses modell implementálásának egyik módszere a helyileg futó monitorozási ügynökök használata az alkalmazás minden egyes példányával. A monitorozási ügynök egy külön folyamat, amely rendszeresen lekéri (lekéri) a helyi csomóponton gyűjtött telemetriai adatokat, és ezeket az adatokat közvetlenül az alkalmazás összes példánya által megosztott központosított tárolóba írja. Ezt a mechanizmust implementálja az Azure Diagnostics. Egy Azure-web- vagy feldolgozói szerepkör minden példánya konfigurálható a helyileg tárolt diagnosztikai és egyéb nyomkövetési információk rögzítésére. Az egyes példányok mellett futó figyelési ügynök a megadott adatokat az Azure Storage-ba másolja. A diagnosztika engedélyezése az Azure Cloud Servicesben és a virtuális gépeken című cikk további részleteket tartalmaz erről a folyamatról. Egyes elemek, például az IIS-naplók, az összeomlási memóriaképek és az egyéni hibanaplók a Blob Storage-ba vannak írva. A windowsos eseménynaplóból, az ETW-eseményekből és a teljesítményszámlálókból származó adatok a táblatárolóban lesznek rögzítve. A 3. ábra ezt a mechanizmust szemlélteti.
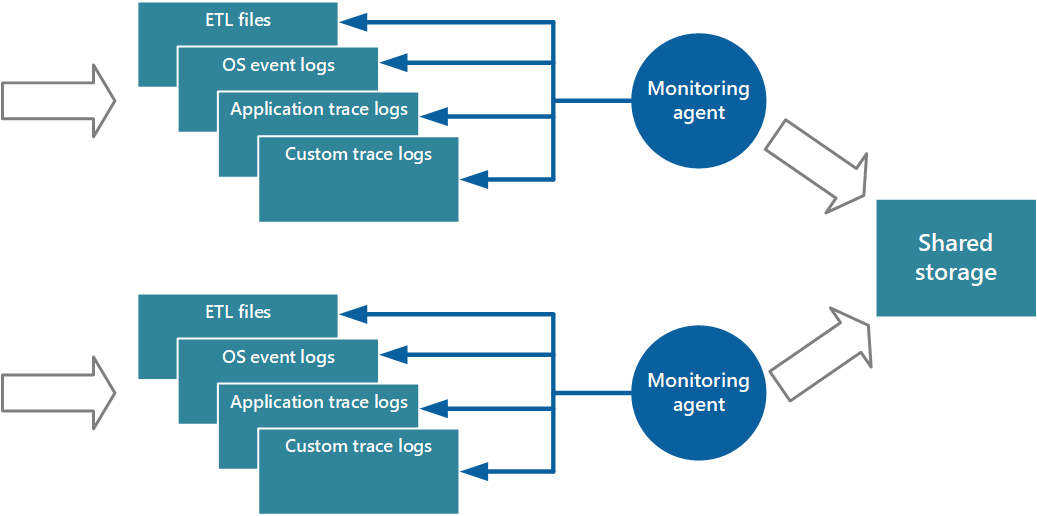
3. ábra – Egy monitorozási ügynök használata adatok lekérésére és megosztott tárolóba való írásra.
Megjegyzés:
A monitorozási ügynökök ideális megoldást jelentenek az adatforrásokból magától értetődően lekért rendszerállapot-adatok rögzítéséhez. Ilyen például az SQL Server dinamikus felügyeleti nézeteiből származó információk vagy egy Azure Service Bus-üzenetsor hossza.
Megvalósítható az imént ismertetett módszer, a telemetriai adatok tárolása korlátozott számú csomóponton, egyetlen helyen futó kis léptékű alkalmazások esetében. Egy összetett, nagymértékben skálázható globális felhőalkalmazás azonban hatalmas mennyiségű adatot generálhat több száz webes és feldolgozói szerepkörből, adatbázis-szegmensből és egyéb szolgáltatásból. Ez az adatáradat könnyen túlterhelheti az egyetlen központi helyen elérhető I/O-sávszélességet. Ezért a telemetriai megoldásnak méretezhetőnek kell lennie, hogy megakadályozza, hogy szűk keresztmetszetként viselkedjen a rendszer bővülése során. Ideális esetben a megoldásnak olyan mértékű redundanciát kell tartalmaznia, amely csökkenti a fontos monitorozási adatok (például a naplózás vagy a számlázási adatok) elvesztésének kockázatát, ha a rendszer egy része meghibásodik.
A problémák megoldásához a 4. ábrán látható módon implementálhatja a sorba állítást. Ebben az architektúrában a helyi monitorozási ügynök (ha megfelelően konfigurálható) vagy egyéni adatgyűjtési szolgáltatás (ha nem) az adatokat üzenetsorba küldi. Az aszinkron módon futó külön folyamat (a 4. ábrán található tárolási írási szolgáltatás) az üzenetsor adatait veszi át, és megosztott tárolóba írja. Az üzenetsor azért alkalmas erre a forgatókönyvre, mert "legalább egyszer" szemantikát biztosít, amely segít biztosítani, hogy az üzenetsorba helyezett adatok ne vesszenek el a közzététel után. A tárolóírási szolgáltatást külön feldolgozói szerepkörrel implementálhatja.
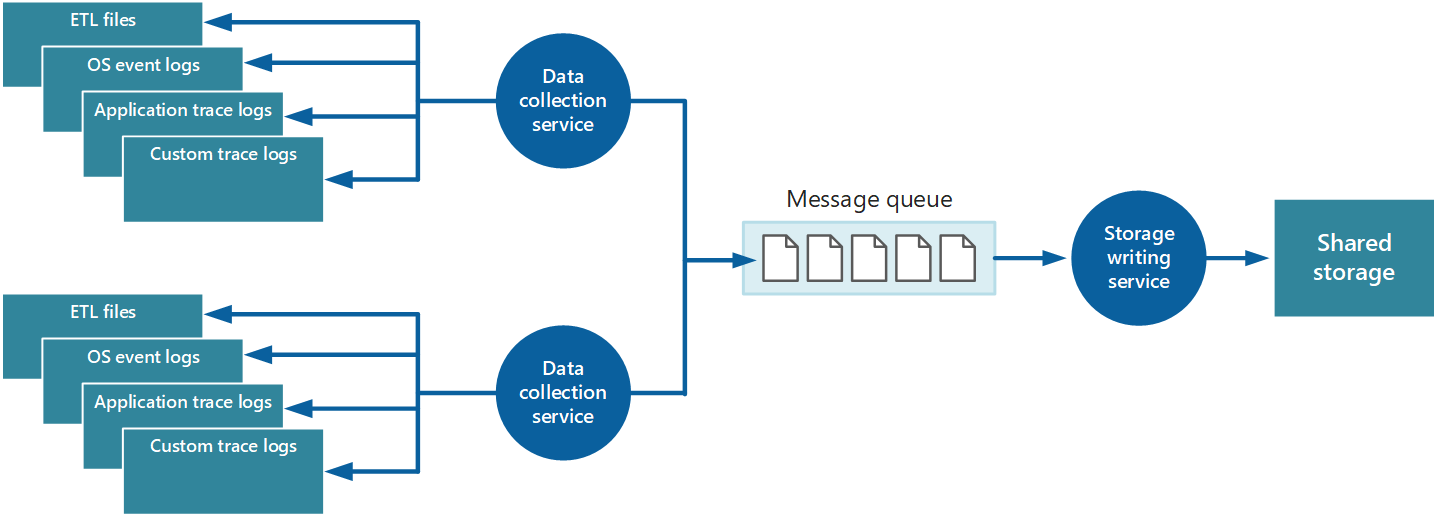
4. ábra – A rendszerállapot-adatok pufferelése üzenetsor használatával.
A helyi adatgyűjtési szolgáltatás közvetlenül a beérkezés után adatokat adhat hozzá az üzenetsorhoz. Az üzenetsor pufferként működik, és a tárolási írási szolgáltatás a saját tempójában tudja lekérni és írni az adatokat. Alapértelmezés szerint az üzenetsorok első, első előtti alapon működnek. Az üzeneteket azonban rangsorolhatja, hogy felgyorsítsa őket az üzenetsoron, ha olyan adatokat tartalmaznak, amelyeket gyorsabban kell kezelni. További információkért tekintse meg a prioritási üzenetsor mintáját. Másik lehetőségként használhat különböző csatornákat (például Service Bus-témaköröket) az adatok különböző célhelyekre való irányításához a szükséges elemzési feldolgozás formájától függően.
A méretezhetőség érdekében a tárolási írási szolgáltatás több példányát is futtathatja. Nagy mennyiségű esemény esetén egy eseményközpont használatával különböző számítási erőforrásokba küldheti az adatokat feldolgozás és tárolás céljából.
A rendszerállapot adatainak összesítése
Az adatgyűjtési szolgáltatás által egy alkalmazás egyetlen példányából lekért rendszerállapot-adatok lokalizált képet adnak a példány állapotáról és teljesítményéről. A rendszer általános állapotának felméréséhez össze kell egyesíteni az adatok néhány aspektusát a helyi nézetekben. Ezt az adatok tárolása után is végrehajthatja, de bizonyos esetekben az adatok gyűjtésekor is elérheti őket. Ahelyett, hogy közvetlenül megosztott tárolóba írnak, a rendszerállapot-adatok átjuthatnak egy külön adatkonszolidációs szolgáltatáson, amely egyesíti az adatokat, és szűrési és tisztítási folyamatként működik. Például az azonos korrelációs adatokat, például a tevékenységazonosítót tartalmazó rendszerállapot-adatok összeolvaszthatók. (Lehetséges, hogy egy felhasználó elkezd üzleti műveletet végrehajtani egy csomóponton, majd csomóponthiba esetén vagy a terheléselosztás konfigurálásának módjától függően egy másik csomópontra kerül át.) Ez a folyamat képes észlelni és eltávolítani a duplikált adatokat is (mindig lehetséges, ha a telemetriai szolgáltatás üzenetsorokkal küldi le a rendszerállapot-adatokat a tárolóba). Az 5. ábra erre a struktúrára mutat példát.
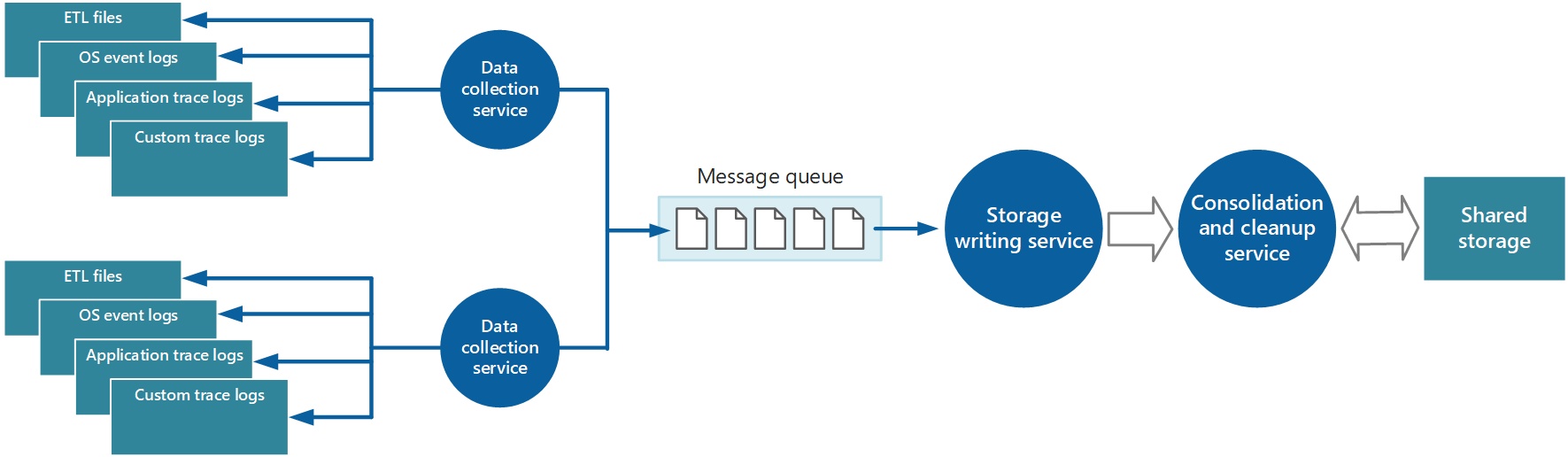
5. ábra – Különálló szolgáltatás használata a rendszerállapot-adatok összevonásához és törléséhez.
Rendszerállapot-adatok tárolása
Az előző vitafórumok meglehetősen leegyszerűsített képet mutatnak a rendszerállapot-adatok tárolásának módjáról. A valóságban érdemes lehet a különböző típusú információkat olyan technológiákkal tárolni, amelyek leginkább megfelelnek az egyes típusok használatának.
Az Azure Blob és a Table Storage például hasonlóságokkal rendelkezik a hozzáférés módjában. A használatukkal végrehajtható műveletekre azonban korlátozások vonatkoznak, és az általuk tárolt adatok részletessége meglehetősen eltérő. Ha további elemzési műveleteket kell végrehajtania, vagy teljes szöveges keresési képességekre van szüksége az adatok vonatkozásában, jobb megoldás lehet a különféle lekérdezés- és adathozzáférés-típusokra optimalizált képességeket biztosító adattárakat használni. Például:
- A teljesítményszámlálók adatainak SQL-adatbázisban való tárolása lehetővé teszi az ad hoc elemzést.
- A nyomkövetési naplók jobban tárolhatók az Azure Cosmos DB-ben.
- A biztonsági információk a HDFS-be írhatók.
- A teljes szöveges keresést igénylő információk az Elasticsearchen keresztül tárolhatók (ami gazdag indexeléssel is felgyorsíthatja a keresést).
Implementálhat egy további szolgáltatást, amely rendszeres időközönként lekéri az adatokat a megosztott tárolóból, particionálja és szűri az adatokat a rendeltetésének megfelelően, majd a 6. ábrán látható módon egy megfelelő adattárkészletbe írja. Egy másik megközelítés ezen funkció belefoglalása a konszolidálási és tisztítási folyamatba, és az adatoknak közvetlenül ezen tárolókba, nem pedig egy közbenső megosztott tárterületre való írása a lekérésüket követően. Mindegyik megközelítésnek vannak előnyei és hátrányai. Egy külön particionálási szolgáltatás implementálása csökkenti a konszolidálási és tisztítási szolgáltatás terhelését, és lehetővé teszi a particionált adatok legalább egy részének újragenerálását, ha szükséges (attól függően, hogy mennyi adatot őriznek meg a megosztott tárban). Azonban további erőforrásokat használ fel. Emellett elképzelhető, hogy a rendszerállapot-adatok később érkeznek meg az egyes alkalmazáspéldányokról, és később történik a gyakorlatban használható információkká való átalakításuk.
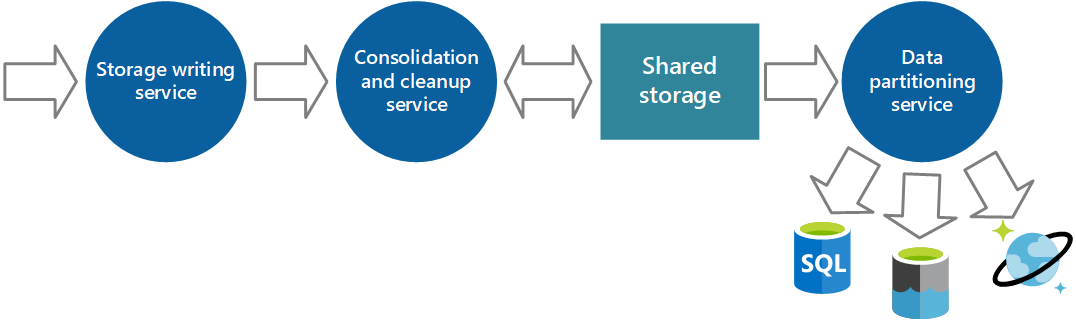
6. ábra – Adatok particionálása elemzési és tárolási követelmények szerint.
Ugyanazok a rendszerállapot-adatok több célból is szükségesek lehetnek. A teljesítményszámlálók segítségével például előzményként tekintheti meg a rendszer teljesítményét az idő függvényében. Ezeket az információkat más használati adatokkal egyesítve létrehozhatók az ügyfélre vonatkozó számlázási információk. Ezekben az esetekben ugyanazok az adatok több célhelyre is elküldhetők, például egy dokumentumadatbázis, amely hosszú távú tárolóként szolgálhat a számlázási adatok tárolásához, valamint egy többdimenziós tároló az összetett teljesítményelemzés kezeléséhez.
Azt is figyelembe kell vennie, hogy milyen sürgősen van szükség az adatokra. A riasztási adatokat gyorsan el kell érni, ezért gyors adattárban kell tárolni, és indexelni vagy strukturálni kell a riasztási rendszer által végrehajtott lekérdezések optimalizálása érdekében. Bizonyos esetekben szükség lehet arra, hogy az egyes csomópontokon adatokat összegyűjtő telemetriai szolgáltatás helyileg formázza és mentse az adatokat, hogy a riasztási rendszer helyi példánya gyorsan értesíthesse Önt a problémákról. Ugyanezek az adatok elirányíthatók az előző ábrákon látható tárolóírási szolgáltatásnak, és központilag tárolhatók, ha más célokból is szükség lenne rájuk.
A megfontoltabb elemzésekhez, a jelentéskészítéshez és a korábbi trendek kiszúrásához használt információk kevésbé sürgősek, és olyan módon tárolhatók, amely támogatja az adatbányászatot és az alkalmi lekérdezéseket. További információkért lásd a dokumentum későbbi részében a gyakori, meleg és hideg elemzés támogatása című szakaszt.
Naplóforgatás és adatmegőrzés
A rendszerállapot jelentős mennyiségű adatot hozhat létre. Ezek az adatok több helyen is tárolhatók, kezdve a nyers naplófájlokkal, a nyomkövetési fájlokkal és az egyes csomópontokban rögzített egyéb adatokkal a megosztott tárolóban tárolt adatok összevont, tisztított és particionált nézetéhez. Bizonyos esetekben az adatok feldolgozása és átvitele után az eredeti nyers forrásadatok eltávolíthatók az egyes csomópontokból. Más esetekben előfordulhat, hogy a nyers információk mentése szükséges vagy egyszerűen hasznos. Előfordulhat például, hogy a hibakeresési célokra létrehozott adatok a legjobban a nyers formájukban maradnak, de a hibák kijavítása után gyorsan elvethetők.
A teljesítményadatok gyakran hosszabb élettartamúak, így felhasználhatók a teljesítménytrendek észlelésére és a kapacitástervezésre. Az ilyen adatok konszolidált nézeteit szokás a gyorsabb elérés érdekében határozott ideig online megőrizni. Ezt követően archiválhatók vagy elvethetők. A mérési és számlázási célból gyűjtött adatokat néha határozatlan ideig meg kell őrizni. Emellett a szabályozási követelmények azt is előírják, hogy a naplózási és biztonsági célból gyűjtött információkat is archiválni és menteni kell. Ezek az adatok is érzékenyek, és előfordulhat, hogy titkosítani vagy más módon védeni kell őket a manipuláció megakadályozása érdekében. Soha ne rögzítse a felhasználók jelszavát vagy más olyan információkat, amelyek személyazonossági csalások elkövetéséhez használhatók. Ezeket a részleteket a tárolás előtt le kell mosni az adatokból.
Levételes mintavételezés
Az előzményadatokat célszerű menteni a hosszú távú trendek felismerése érdekében. Ahelyett, hogy a régi adatokat teljes egészében mentené, lehetséges lehet az adatok lemintázása a felbontás csökkentése és a tárolási költségek megtakarítása érdekében. Például a percenkénti teljesítménymutatók mentése helyett összevonhatja az egy hónapnál régebbi adatokat, hogy óránkénti nézetet alakítsanak ki.
Ajánlott eljárások naplózási adatok gyűjtéséhez és tárolásához
Az alábbi lista a naplózási adatok rögzítésének és tárolásának ajánlott eljárásait foglalja össze:
A monitorozási ügynöknek vagy az adatgyűjtési szolgáltatásnak folyamaton kívüli szolgáltatásként kell futnia, és egyszerűen üzembe helyezhetőnek kell lennie.
A monitorozási ügynök vagy az adatgyűjtési szolgáltatás összes kimenetének olyan agnosztikus formátumnak kell lennie, amely független a géptől, az operációs rendszertől vagy a hálózati protokolltól. Például az ETL/ETW helyett önleíró formátumban, például JSON, MessagePack vagy Protobuf formátumban bocsát ki információkat. A szabványos formátum használatával a rendszer feldolgozási folyamatokat hozhat létre; azokat az összetevőket, amelyek az elfogadott formátumban olvasnak, átalakítanak és küldenek adatokat, könnyen integrálhatók.
A monitorozási és adatgyűjtési folyamatnak sikertelennek kell lennie, és nem válthat ki kaszkádolt hibafeltételeket.
Abban az esetben, ha átmeneti hiba történik az adatgyűjtőknek történő információküldés során, a monitorozási ügynöknek vagy az adatgyűjtési szolgáltatásnak fel kell készülnie a telemetriai adatok átrendezésére, hogy a legújabb információk először el legyenek küldve. (A monitorozási ügynök/adatgyűjtési szolgáltatás dönthet úgy, hogy saját belátása szerint elveti a régebbi adatokat, vagy helyben menti őket, és később továbbítja őket a felzárkózáshoz.)
Adatok elemzése és problémák diagnosztizálása
A monitorozási és diagnosztikai folyamat fontos része az összegyűjtött adatok elemzése, hogy képet kapjon a rendszer általános jólétéről. Saját KPI-ket és teljesítménymetrikákat kellett volna definiálnia, és fontos megértenie, hogyan strukturálhatja az összegyűjtött adatokat az elemzési követelményeknek megfelelően. Azt is fontos megérteni, hogy a különböző metrikákban és naplófájlokban rögzített adatok hogyan vannak korrelálva, mivel ezek az információk kulcsfontosságúak lehetnek az események sorozatának nyomon követéséhez és a felmerülő problémák diagnosztizálásához.
A rendszerállapot-adatok konszolidálása című szakaszban leírtak szerint a rendszer egyes részeinek adatait általában helyileg rögzítik, de általában össze kell kapcsolni a rendszerben részt vevő más helyeken létrehozott adatokkal. Ezek az információk gondos korrelációt igényelnek az adatok pontos kombinálásához. Egy művelet használati adatai például egy olyan webhelyet üzemeltető csomópontra terjedhetnek ki, amelyhez egy felhasználó csatlakozik, egy olyan csomópontra, amely a művelet részeként egy külön szolgáltatást futtat, valamint egy másik csomóponton tárolt adattárolást. Ezeket az információkat össze kell kötni, hogy átfogó képet lehessen adni az erőforrásról és a művelet használati adatainak feldolgozásáról. Előfordulhat, hogy az adatok előfeldolgozása és szűrése azon a csomóponton történik, amelyen az adatok rögzítve vannak, míg az összesítés és a formázás nagyobb valószínűséggel fordul elő egy központi csomóponton.
Meleg, meleg és hideg elemzés támogatása
A vizualizációs, jelentéskészítési és riasztási célú adatok elemzése és újraformázása összetett folyamat lehet, amely saját erőforráskészletet használ fel. A monitorozás egyes formái időkritikusak, és az adatok azonnali elemzését igénylik, hogy hatékonyak legyenek. Ezt gyakori elemzésnek nevezzük. Ilyenek például a riasztáshoz szükséges elemzések és a biztonsági monitorozás néhány aspektusa (például a rendszer elleni támadás észlelése). Az ilyen célokhoz szükséges adatoknak gyorsan elérhetővé és strukturáltnak kell lenniük a hatékony feldolgozás érdekében. Bizonyos esetekben szükség lehet az elemzési feldolgozás áthelyezésére az egyes csomópontokra, ahol az adatok találhatók.
Az elemzés egyéb formái kevésbé időkritikusak, és a nyers adatok beérkezése után némi számítást és összesítést igényelhetnek. Ezt meleg elemzésnek nevezzük. A teljesítményelemzés gyakran ebbe a kategóriába tartozik. Ebben az esetben egy izolált, egyetlen teljesítményesemény nem valószínű, hogy statisztikailag jelentős. (Ezt okozhatja egy hirtelen kiugrás vagy hiba.) Az események sorozatából származó adatoknak megbízhatóbb képet kell nyújtaniuk a rendszer teljesítményéről.
A meleg elemzés az egészségügyi problémák diagnosztizálásához is használható. Az állapoteseményeket általában gyakori elemzéssel dolgozzák fel, és azonnal riasztást adhatnak ki. Az operátornak meg kell tudnia vizsgálni az állapotesemény okait a meleg elérési út adatainak vizsgálatával. Az adatoknak információkat kell tartalmazniuk az állapoteseményt okozó problémához vezető eseményekről.
Bizonyos típusú monitorozás hosszabb távú adatokat hoz létre. Ez az elemzés egy későbbi időpontban végezhető el, esetleg előre meghatározott ütemezés szerint. Bizonyos esetekben előfordulhat, hogy az elemzésnek összetett szűrést kell végeznie az adott időszakban rögzített nagy mennyiségű adatra vonatkozóan. Ezt hideg elemzésnek nevezzük. A legfontosabb követelmény, hogy az adatok tárolása biztonságosan, a rögzítés után legyen. A használatfigyeléshez és a naplózáshoz például pontos képet kell adni a rendszer állapotáról a rendszeres időpontokban, de ennek az állapotinformációnak nem kell közvetlenül az összegyűjtése után feldolgozásra rendelkezésre állnia.
Az operátor hideg elemzéssel is biztosíthatja az adatokat a prediktív állapotelemzéshez. Az operátor összegyűjtheti az előzményadatokat egy adott időszakban, és az aktuális állapotadatokkal együtt használhatja (a gyakori elérésű útvonalról lekérve), hogy észlelje azokat a trendeket, amelyek hamarosan egészségügyi problémákat okozhatnak. Ezekben az esetekben szükség lehet egy riasztásra, hogy korrekciós intézkedéseket lehessen tenni.
Adatok korrelációja
A rendszerállapot-rögzítő adatok pillanatképet adhatnak a rendszerállapotról, de az elemzés célja az adatok végrehajthatóvá tétele. Például:
- Mi okozta az intenzív I/O-terhelést a rendszer szintjén egy adott időpontban?
- Nagy számú adatbázisművelet eredménye?
- Ez tükröződik az adatbázis válaszidejében, a másodpercenkénti tranzakciók számában és az alkalmazások válaszidejében is?
Ha igen, az egyik olyan szervizművelet, amely csökkentheti a terhelést, az lehet, hogy több kiszolgálóra szilánkozza az adatokat. Emellett a rendszer bármely szintjén fellépő hiba miatt kivételek léphetnek fel. Az egyik szint kivétele gyakran egy másik hibát vált ki a fenti szinten.
Ezért képesnek kell lennie a különböző típusú monitorozási adatok korrelációjára minden szinten, hogy átfogó képet nyújthasson a rendszer állapotáról és az azon futó alkalmazásokról. Ezeket az információkat felhasználhatja arra, hogy döntéseket hozzon arról, hogy a rendszer elfogadhatóan működik-e, vagy sem, és meghatározhatja, hogy mit lehet tenni a rendszer minőségének javítása érdekében.
Az Adatok korrelációja című szakaszban leírtaknak megfelelően gondoskodnia kell arról, hogy a nyers rendszerállapot-adatok elegendő környezeti és tevékenységazonosító-információt tartalmazzanak az események korrelációihoz szükséges összesítések támogatásához. Emellett előfordulhat, hogy ezek az adatok különböző formátumban lesznek tárolva, és szükség lehet ezen adatok elemzésére, hogy szabványosított elemzési formátummá alakítsa őket.
Hibaelhárítás és a problémák diagnosztizálása
A diagnosztikához szükség van a hibák okának vagy a váratlan viselkedésnek a meghatározására, beleértve a kiváltó okok elemzését is. A szükséges információk általában a következők:
- Részletes információk az eseménynaplókból és nyomkövetésekből, akár a teljes rendszerre, akár egy adott alrendszerre vonatkozóan egy adott időkeret során.
- Teljes veremkövetkezések, amelyek a rendszeren vagy egy adott alrendszeren belül egy adott időszakban előforduló bármely meghatározott szint kivételeiből és hibáiból erednek.
- Összeomlási memóriaképek a rendszer bármely pontján vagy egy adott alrendszerben egy adott időkeret során meghiúsult folyamatokhoz.
- A tevékenységnaplók rögzítik azokat a műveleteket, amelyeket az összes felhasználó vagy a kijelölt felhasználók egy adott időszakban hajtanak végre.
Az adatok hibaelhárítási célokra történő elemzéséhez gyakran a rendszerarchitektúra és a megoldást alkotó különböző összetevők részletes technikai ismerete szükséges. Ennek eredményeképpen gyakran nagy mértékű manuális beavatkozásra van szükség az adatok értelmezéséhez, a problémák okának megállapításához, és megfelelő stratégia ajánlására az adatok kijavításához. Célszerű lehet egyszerűen tárolni az információk egy példányát eredeti formájában, és elérhetővé tenni egy szakértő hideg elemzéséhez.
Adatok vizualizációja és riasztások emelése
A monitorozási rendszerek egyik fontos eleme az adatok olyan módon való bemutatása, hogy az operátor gyorsan észlelhesse a trendeket vagy problémákat. Az is fontos, hogy gyorsan tájékoztassuk az operátort, ha olyan jelentős esemény történt, amely figyelmet igényelhet.
Az adatbemutatás több űrlapot is tartalmazhat, például az irányítópultok, riasztások és jelentések használatával történő vizualizációt.
Vizualizáció irányítópultok használatával
Az adatok vizualizációjának leggyakoribb módja olyan irányítópultok használata, amelyek diagramok, grafikonok vagy más ábrák sorozataként jeleníthetik meg az információkat. Ezek az elemek paraméterezhetők, és az elemzőnek képesnek kell lennie kiválasztani a fontos paramétereket (például az időtartamot) minden adott helyzetben.
Az irányítópultok hierarchikusan rendszerezhetők. A legfelső szintű irányítópultok átfogó képet adhatnak a rendszer minden aspektusáról, de lehetővé teszik az operátoroknak, hogy részletezhessék a részleteket. Például egy olyan irányítópultnak, amely a rendszer teljes lemez I/O-ját ábrázolja, lehetővé kell tenni az elemző számára, hogy minden egyes lemez I/O-díjait megtekintse annak megállapításához, hogy egy vagy több adott eszköz aránytalan mennyiségű forgalmat bonyolít-e. Ideális esetben az irányítópultnak a kapcsolódó információkat is meg kell jelenítenie, például az egyes kérések forrását (a felhasználót vagy tevékenységet), amelyek létrehozták ezt az I/O-t. Ez az információ ezután annak meghatározására használható, hogy (és hogyan) egyenletesebben terjessze-e el a terhelést az eszközök között, és hogy a rendszer jobban teljesít-e, ha több eszközt adnak hozzá.
Az irányítópultok színkódolást vagy más vizuális jeleket is használhatnak a rendellenesnek tűnő vagy a várt tartományon kívül eső értékek jelzésére. Az előző példában:
- Egy olyan I/O-sebességgel rendelkező lemez, amely hosszabb idő alatt megközelíti a maximális kapacitását (egy gyorslemez) pirossal kiemelhető.
- Egy olyan I/O-sebességgel rendelkező lemez, amely rendszeres időközönként a maximális korláton fut rövid ideig (meleg lemez) sárga színnel kiemelhető.
- A normál használatú lemezek zöld színnel jeleníthetők meg.
Vegye figyelembe, hogy ahhoz, hogy egy irányítópult-rendszer hatékonyan működjön, a nyers adatokkal kell rendelkeznie. Ha saját irányítópult-rendszert hoz létre, vagy egy másik szervezet által kifejlesztett irányítópultot használ, tisztában kell lennie azzal, hogy milyen rendszerállapot-adatokat kell gyűjtenie, milyen részletességi szinteken, és hogyan kell formázni az irányítópultot a felhasználáshoz.
A jó irányítópultok nem csak információkat jelenítenek meg, hanem lehetővé teszik az elemzők számára, hogy eseti kérdéseket is feltehessenek ezzel az információval kapcsolatban. Egyes rendszerek olyan felügyeleti eszközöket biztosítanak, amelyekkel egy operátor végrehajthatja ezeket a feladatokat, és feltárhatja az alapul szolgáló adatokat. Másik lehetőségként az információk tárolására használt adattártól függően lehetséges, hogy közvetlenül lekérdezi ezeket az adatokat, vagy importálja azokat olyan eszközökbe, mint a Microsoft Excel, a további elemzéshez és jelentéskészítéshez.
Megjegyzés:
Korlátoznia kell az irányítópultokhoz való hozzáférést a jogosult személyzet számára, mert ezek az információk üzleti szempontból érzékenyek lehetnek. Az irányítópultok alapjául szolgáló adatokat is védenie kell, hogy a felhasználók ne módosíthassak őket.
Riasztások emelése
A riasztás a monitorozási és rendszerállapot-adatok elemzésének és egy értesítés generálásának folyamata, ha jelentős eseményt észlel.
A riasztás segít biztosítani, hogy a rendszer kifogástalan, rugalmas és biztonságos maradjon. Ez minden olyan rendszer fontos része, amely teljesítménnyel, rendelkezésre állási és adatvédelmi garanciával jár azoknak a felhasználóknak, ahol az adatok azonnali végrehajtása szükséges lehet. Előfordulhat, hogy egy operátort értesíteni kell a riasztást kiváltó eseményről. A riasztások olyan rendszerfunkciók meghívására is használhatók, mint az automatikus skálázás.
A riasztás általában a következő rendszerállapot-adatoktól függ:
- Biztonsági események. Ha az eseménynaplók azt jelzik, hogy ismétlődő hitelesítési vagy engedélyezési hibák történnek, előfordulhat, hogy a rendszer támadás alatt áll, és értesíteni kell egy operátort.
- Teljesítménymetrikák. A rendszernek gyorsan válaszolnia kell, ha egy adott teljesítménymetrika meghaladja a megadott küszöbértéket.
- Rendelkezésre állási információk. Hiba észlelése esetén szükség lehet egy vagy több alrendszer gyors újraindítására, vagy egy biztonsági mentési erőforrás feladatátvételére. Az alrendszer ismétlődő hibái súlyosabb aggodalmakat jelezhetnek.
Az operátorok riasztási információkat kaphatnak számos kézbesítési csatornán, például e-mailen, lapozóeszközön vagy SMS-üzenetben. A riasztások azt is jelezhetik, hogy mennyire kritikus a helyzet. Számos riasztási rendszer támogatja az előfizetői csoportokat, és minden olyan operátor, aki ugyanannak a csoportnak a tagja, ugyanazt a riasztáskészletet kaphatja.
A riasztási rendszernek testreszabhatónak kell lennie, és paraméterekként meg lehet adni a mögöttes rendszerállapot-adatok megfelelő értékeit. Ez a megközelítés lehetővé teszi, hogy az operátor szűrje az adatokat, és azokra a küszöbértékekre vagy értékkombinációkra összpontosítson, amelyek fontosak. Vegye figyelembe, hogy bizonyos esetekben a nyers rendszerállapot-adatok megadhatók a riasztási rendszer számára. Más helyzetekben célszerűbb lehet összesített adatokat szolgáltatni. (Például riasztás akkor aktiválható, ha egy csomópont processzorhasználata az elmúlt 10 percben meghaladta a 90%-ot). A riasztási rendszernek megadott részleteknek tartalmazniuk kell a megfelelő összefoglaló és környezeti információkat is. Ezek az adatok segíthetnek csökkenteni annak a lehetőségét, hogy a hamis pozitív események megússnak egy riasztást.
Jelentéskészítés
A jelentéskészítés a rendszer átfogó képének létrehozására szolgál. Előfordulhat, hogy az aktuális információk mellett előzményadatokat is tartalmaz. Maguk a jelentési követelmények két átfogó kategóriába sorolhatók: a működési jelentéskészítés és a biztonsági jelentéskészítés.
A működési jelentések általában a következő szempontokat tartalmazzák:
- Statisztikák összesítése, amelyek segítségével megismerheti a teljes rendszer vagy a megadott alrendszerek erőforrás-kihasználtságát egy adott időablakban.
- A teljes rendszer vagy a megadott alrendszerek erőforrás-felhasználási trendjeinek azonosítása egy adott időszakban.
- A rendszer vagy a meghatározott alrendszerek során egy adott időszakban előforduló kivételek monitorozása.
- Az alkalmazás hatékonyságának meghatározása az üzembe helyezett erőforrások tekintetében, és annak megértése, hogy az erőforrások mennyisége (és az ahhoz kapcsolódó költségek) csökkenthetők-e anélkül, hogy szükségtelenül befolyásolnák a teljesítményt.
A biztonsági jelentés az ügyfelek rendszerhasználatának nyomon követésével foglalkozik. Ez a következőket tartalmazhatja:
- Felhasználói műveletek naplózása. Ehhez rögzíteni kell az egyes felhasználók által végrehajtott egyéni kéréseket, dátumokkal és időpontokkal együtt. Az adatokat úgy kell strukturálni, hogy a rendszergazdák gyorsan rekonstruálhassák a felhasználó által egy adott időszakban végrehajtott műveletek sorrendjét.
- Az erőforrás felhasználó általi használatának nyomon követése. Ehhez rögzíteni kell, hogy egy felhasználó egyes kérései hogyan férnek hozzá a rendszert alkotó különböző erőforrásokhoz, és mennyi ideig. A rendszergazdának képesnek kell lennie arra, hogy ezeket az adatokat felhasználva használati jelentést hozzon létre a felhasználó számára egy megadott időszakban, esetleg számlázási célokra.
Sok esetben kötegelt folyamatok is létrehozhatnak jelentéseket egy meghatározott ütemezés szerint. (A késés általában nem probléma.) De szükség esetén a generációk számára is elérhetőknek kell lenniük. Ha például egy relációs adatbázisban, például az Azure SQL Database-ben tárol adatokat, egy olyan eszközzel, mint az SQL Server Reporting Services, kinyerheti és formázhatja az adatokat, és jelentéseket jeleníthet meg.
Következő lépések
- Azure Monitor – áttekintés
- Microsoft Azure Storage felügyelete, diagnosztizálása és hibaelhárítása
- A Microsoft Azure riasztásainak áttekintése
- Szolgáltatás állapotára vonatkozó értesítések megtekintése az Azure Portalon
- Mi az Application Insights?
- Azure-beli virtuális gépek teljesítménydiagnosztikája
- SQL Server Data Tools (SSDT) letöltése és telepítése a Visual Studio-hoz
Kapcsolódó erőforrások
- Az automatikus méretezési útmutató bemutatja, hogyan csökkentheti a felügyeleti többletterhelést azáltal, hogy csökkenti annak szükségességét, hogy egy operátor folyamatosan monitorozza a rendszer teljesítményét, és döntéseket hozzon az erőforrások hozzáadásáról vagy eltávolításáról.
- Az állapotvégpont-monitorozási minta azt ismerteti, hogyan valósíthat meg funkcionális ellenőrzéseket egy olyan alkalmazáson belül, amelyet külső eszközök rendszeres időközönként érhetnek el a közzétett végpontokon keresztül.
- A prioritási üzenetsor mintája bemutatja, hogyan rangsorolhatja az üzenetsoros üzeneteket, hogy sürgős kérések érkezhessenek, és feldolgozhatók a kevésbé sürgős üzenetek előtt.