A természetes nyelvi feldolgozásnak (NLP) számos felhasználási módja van: hangulatelemzés, témakörészlelés, nyelvészlelés, kulcskifejezés-kinyerés és dokumentumkategorizálás.
Az NLP-t a következőre használhatja:
- Dokumentumok osztályozása. A dokumentumokat például bizalmasként vagy levélszemétként is megjelölheti.
- Végezze el a további feldolgozást vagy keresést. Ezekhez a célokhoz használhat NLP-kimenetet.
- Összegezze a szöveget a dokumentumban található entitások azonosításával.
- Dokumentumok címkézése kulcsszavakkal. A kulcsszavak esetében az NLP azonosított entitásokat használhat.
- Tartalomalapú keresés és lekérés. A címkézés lehetővé teszi ezt a funkciót.
- A dokumentum fontos témaköreinek összegzése. Az NLP képes az azonosított entitásokat témakörökké egyesíteni.
- Dokumentumok kategorizálása navigációhoz. Erre a célra az NLP észlelt témaköröket használ.
- Kapcsolódó dokumentumok számbavétele egy kijelölt témakör alapján. Erre a célra az NLP észlelt témaköröket használ.
- Szöveg pontozása a hangulathoz. Ezzel a funkcióval felmérheti egy dokumentum pozitív vagy negatív tónusát.
Az Apache®, az Apache Spark és a láng emblémája az Apache Software Foundation bejegyzett védjegyei vagy védjegyei a Egyesült Államok és/vagy más országokban. Az Apache Software Foundation nem támogatja ezeket a jeleket.
Lehetséges használati esetek
Az egyéni NLP előnyeit kihasználó üzleti forgatókönyvek a következők:
- Dokumentumintelligencia kézzel írt vagy géppel létrehozott dokumentumokhoz a pénzügyi, egészségügyi, kiskereskedelmi, kormányzati és egyéb ágazatokban.
- Iparági NLP-feladatok szövegfeldolgozáshoz, például néventititás-felismeréshez (NER), besoroláshoz, összegzéshez és relációs kinyeréshez. Ezek a feladatok automatizálják a dokumentuminformációk, például a szöveg és a strukturálatlan adatok beolvasásának, azonosításának és elemzésének folyamatát. Ilyen feladatok például a kockázati rétegző modellek, az ontológiai besorolás és a kiskereskedelmi összegzések.
- Információlekérés és tudásgráf létrehozása szemantikai kereséshez. Ez a funkció lehetővé teszi olyan orvosi tudásgráfok létrehozását, amelyek támogatják a gyógyszerfelderítést és a klinikai kísérleteket.
- Szöveges fordítás beszélgetési AI-rendszerekhez az ügyféloldali alkalmazásokban a kiskereskedelmi, pénzügyi, utazási és egyéb iparágakban.
Apache Spark testre szabott NLP-keretrendszerként
Az Apache Spark egy párhuzamos feldolgozási keretrendszer, amely támogatja a memórián belüli feldolgozást a big data elemzési alkalmazások teljesítményének növelése érdekében. Az Azure Synapse Analytics, az Azure HDInsight és az Azure Databricks hozzáférést biztosít a Sparkhoz, és kihasználja feldolgozási teljesítményét.
A testreszabott NLP-számítási feladatokhoz a Spark NLP hatékony keretrendszerként szolgál nagy mennyiségű szöveg feldolgozásához. Ez a nyílt forráskódú NLP-kódtár Python-, Java- és Scala-kódtárakat biztosít, amelyek olyan hagyományos NLP-kódtárak teljes funkcionalitását kínálják, mint a spaCy, az NLTK, a Stanford CoreNLP és az Open NLP. A Spark NLP olyan funkciókat is kínál, mint a helyesírás-ellenőrzés, a hangulatelemzés és a dokumentumbesorolás. A Spark NLP a legmodernebb pontosság, sebesség és méretezhetőség biztosításával javítja a korábbi erőfeszítéseket.
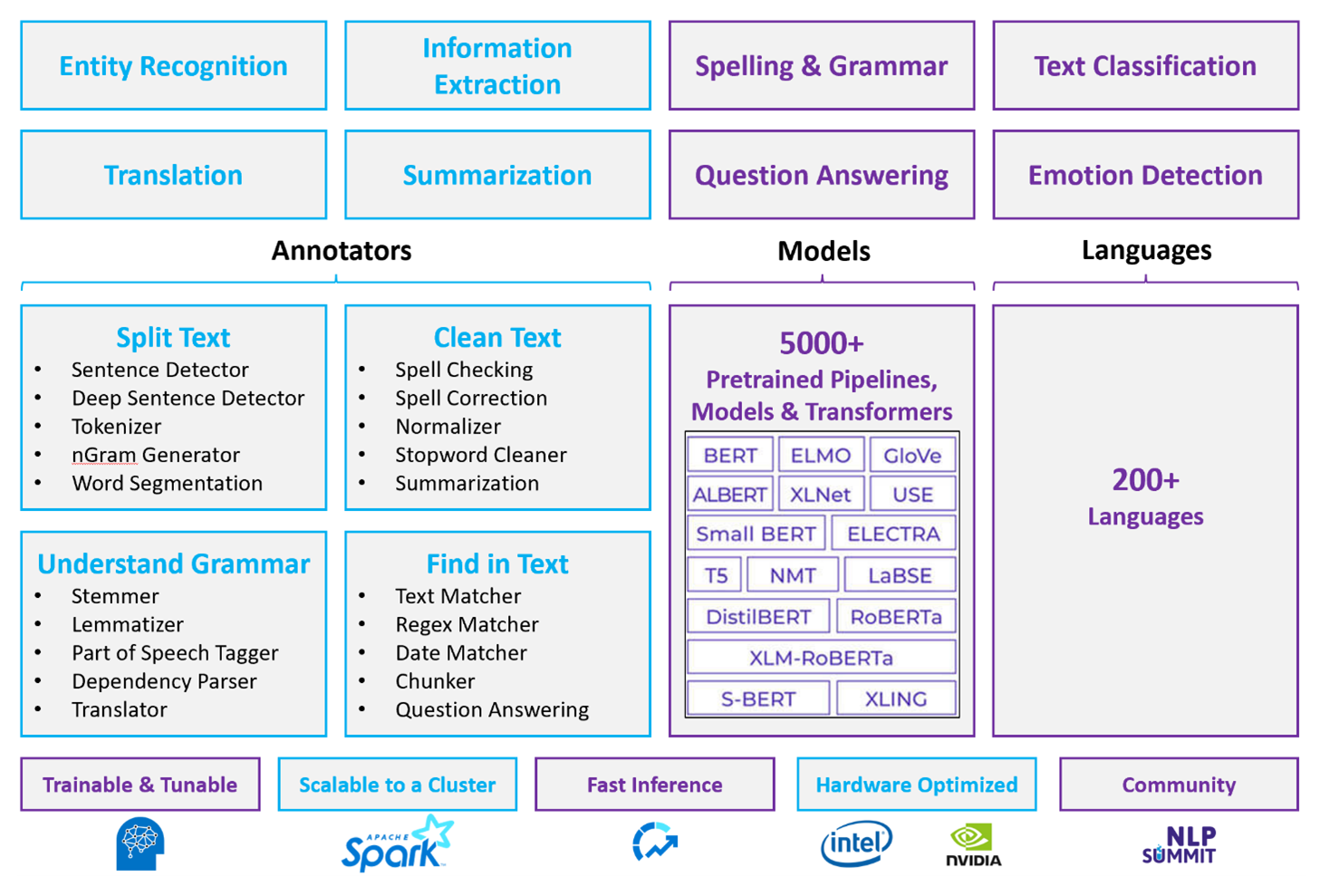
A legutóbbi nyilvános teljesítménymutatók szerint a Spark NLP 38 és 80-szor gyorsabb, mint a SpaCy, és hasonló pontosságot mutat az egyéni modellek betanításához. A Spark NLP az egyetlen nyílt forráskódú kódtár, amely elosztott Spark-fürtöt használhat. A Spark NLP a Spark ML natív bővítménye, amely közvetlenül adatkereteken működik. Ennek eredményeképpen a fürt gyorsulása a teljesítménynövekedés egy másik nagyságrendjét eredményezi. Mivel minden Spark NLP-folyamat Egy Spark ML-folyamat, a Spark NLP kiválóan alkalmas egységes NLP- és gépi tanulási folyamatok, például dokumentumbesorolás, kockázat-előrejelzés és ajánlófolyamatok létrehozására.
A Kiváló teljesítmény mellett a Spark NLP a legmodernebb pontosságot is biztosítja egyre több NLP-feladathoz. A Spark NLP csapata rendszeresen olvassa a legújabb releváns tanulmányokat, és korszerű modelleket implementál. Az elmúlt két-három évben a legjobban teljesítő modellek mély tanulást használtak. A kódtár előre összeállított mélytanulási modelleket tartalmaz a nevesített entitásfelismeréshez, a dokumentumbesoroláshoz, a hangulat- és érzelemfelismeréshez, valamint a mondatészleléshez. A kódtár több tucat előre betanított nyelvi modellt is tartalmaz, amelyek támogatják a szavak, adattömbök, mondatok és dokumentumok beágyazását.
A kódtár processzorokhoz, GPU-khoz és a legújabb Intel Xeon chipekhez optimalizált buildeket. A Spark-fürtök előnyeinek kihasználásához skálázhatja a betanítási és következtetési folyamatokat. Ezek a folyamatok éles környezetben futtathatók az összes népszerű elemzési platformon.
Problémák
- A szabad formátumú szöveges dokumentumok gyűjteményének feldolgozása jelentős mennyiségű számítási erőforrást igényel. A feldolgozás is időigényes. Az ilyen folyamatok gyakran gpu-alapú számítási üzembe helyezést is magukban foglalnak.
- Szabványosított dokumentumformátum nélkül nehéz lehet következetesen pontos eredményeket elérni, ha a szabad formátumú szövegfeldolgozással konkrét tényeket nyer ki egy dokumentumból. Gondoljunk például egy számla szöveges ábrázolására – nehéz lehet olyan folyamatot létrehozni, amely megfelelően kinyeri a számlaszámot és a dátumot, amikor a számlák különböző szállítóktól származnak.
Kulcsválasztási feltételek
Az Azure-ban a Spark-szolgáltatások, például az Azure Databricks, az Azure Synapse Analytics és az Azure HDInsight NLP-funkciókat biztosítanak, amikor a Spark NLP-vel használja őket. Az Azure AI-szolgáltatások egy másik lehetőség az NLP-funkciókhoz. A használni kívánt szolgáltatás kiválasztásához vegye figyelembe az alábbi kérdéseket:
Előre összeállított vagy előre betanított modelleket szeretne használni? Ha igen, fontolja meg az Azure AI-szolgáltatások által kínált API-k használatát. Vagy töltse le a választott modellt a Spark NLP-n keresztül.
Be kell tanítania az egyéni modelleket nagy mennyiségű szöveges adatra? Ha igen, fontolja meg az Azure Databricks, az Azure Synapse Analytics vagy az Azure HDInsight használatát a Spark NLP-vel.
Szüksége van alacsony szintű NLP-képességekre, például tokenizálásra, lemmatizálásra és kifejezés gyakoriságra/inverz dokumentum gyakoriságra (TF/IDF)? Ha igen, fontolja meg az Azure Databricks, az Azure Synapse Analytics vagy az Azure HDInsight használatát a Spark NLP-vel. Vagy használjon egy nyílt forráskódú szoftvertárat a választott feldolgozási eszközben.
Szüksége van egyszerű, magas szintű NLP-képességekre, például entitás- és szándékazonosításra, témakörészlelésre, helyesírás-ellenőrzésre vagy hangulatelemzésre? Ha igen, fontolja meg az Azure AI-szolgáltatások által kínált API-k használatát. Vagy töltse le a választott modellt a Spark NLP-n keresztül.
Képességmátrix
Az alábbi táblázatok összefoglalják az NLP-szolgáltatások képességeinek főbb különbségeit.
Általános képességek
| Funkció | Spark-szolgáltatás (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) a Spark NLP-vel | Azure AI services |
|---|---|---|
| Előre betanított modelleket biztosít szolgáltatásként | Igen | Igen |
| REST API | Igen | Igen |
| Programozhatóság | Python, Scala | A támogatott nyelvekért lásd: További források |
| Támogatja a big data-készletek és a nagyméretű dokumentumok feldolgozását | Igen | Nem |
Alacsony szintű NLP-képességek
| A széljegyzetek képessége | Spark-szolgáltatás (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) a Spark NLP-vel | Azure AI services |
|---|---|---|
| Mondatérzékelő | Igen | Nem |
| Mély mondatérzékelő | Igen | Igen |
| Tokenizer | Igen | Igen |
| N-gram generátor | Igen | Nem |
| Word szegmentálás | Igen | Igen |
| Szár | Igen | Nem |
| Lemmatizer | Igen | Nem |
| Beszédrészlet-címkézés | Igen | Nem |
| Függőségelemző | Igen | Nem |
| Fordítás | Igen | Nem |
| Stopword tisztító | Igen | Nem |
| Helyesírás-javítás | Igen | Nem |
| Normalizáló | Igen | Igen |
| Szövegegyező | Igen | Nem |
| TF/IDF | Igen | Nem |
| Reguláris kifejezésegyező | Igen | Beágyazva a Language Understanding Service-be (LUIS). A LUIS-t lecserélő Beszélgetési nyelv megértése (CLU) nem támogatott. |
| Dátumegyező | Igen | Lehetséges a LUIS-ban és a CLU-ban DateTime-felismerőkön keresztül |
| Adattömb | Igen | Nem |
Magas szintű NLP-képességek
| Funkció | Spark-szolgáltatás (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) a Spark NLP-vel | Azure AI services |
|---|---|---|
| Helyesírás-ellenőrzés | Igen | Nem |
| Összegzés | Igen | Igen |
| Kérdésmegválaszolás | Igen | Igen |
| Hangulatfelismerés | Igen | Igen |
| Érzelemészlelés | Igen | Támogatja a véleménybányászatot |
| Tokenek besorolása | Igen | Igen, egyéni modelleken keresztül |
| Szövegbesorolás | Igen | Igen, egyéni modelleken keresztül |
| Szövegábrázolás | Igen | Nem |
| NER | Igen | Igen – a szövegelemzés NER-készletet biztosít, és az egyéni modellek entitásfelismerésben vannak |
| Entitások felismerése | Igen | Igen, egyéni modelleken keresztül |
| Nyelvfelismerés | Igen | Igen |
| Az angol mellett a nyelveket is támogatja | Igen, több mint 200 nyelvet támogat | Igen, több mint 97 nyelvet támogat |
A Spark NLP beállítása az Azure-ban
A Spark NLP telepítéséhez használja a következő kódot, de cserélje le <version> a legújabb verziószámra. További információkért tekintse meg a Spark NLP dokumentációját.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
NLP-folyamatok fejlesztése
Egy NLP-folyamat végrehajtási sorrendjében a Spark NLP ugyanazt a fejlesztési koncepciót követi, mint a hagyományos Spark ML-gépi tanulási modellek. A Spark NLP azonban NLP-technikákat alkalmaz.
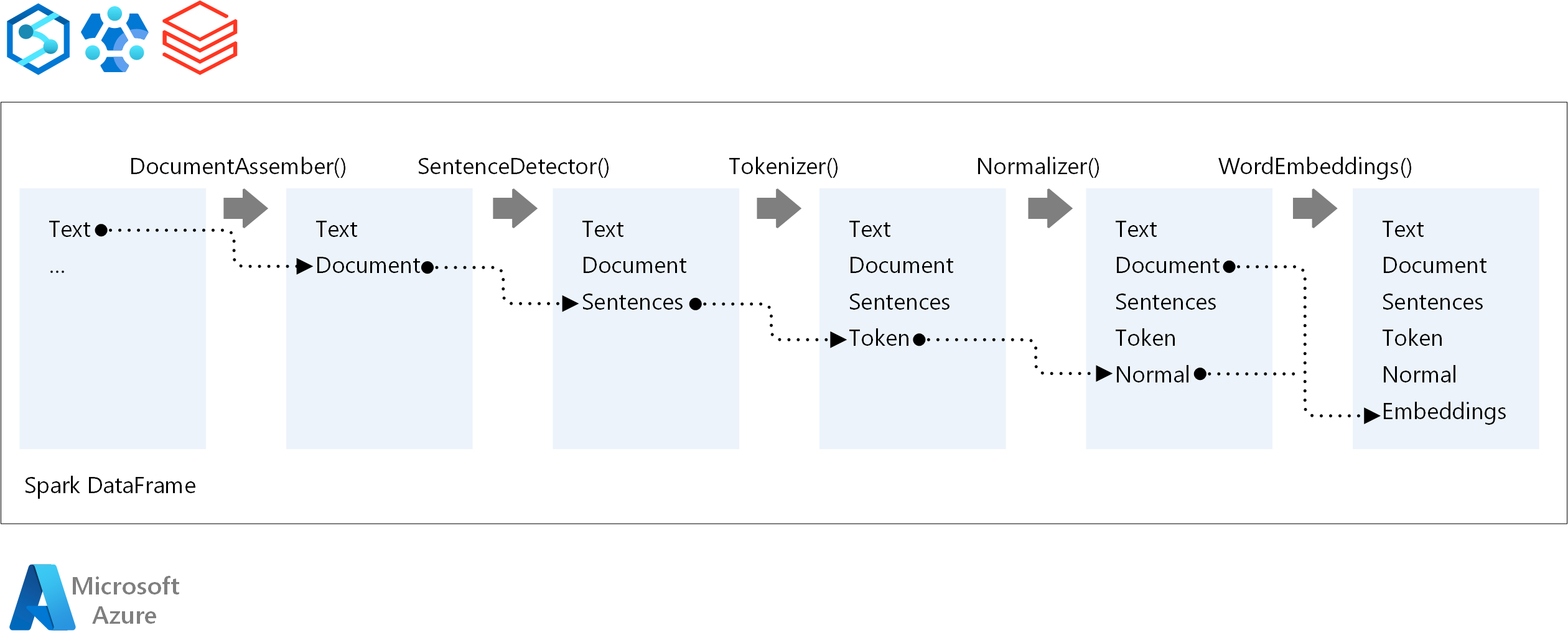
A Spark NLP-folyamatok alapvető összetevői a következők:
DocumentAssembler: Olyan transzformátor, amely úgy készíti elő az adatokat, hogy a Spark NLP által feldolgozható formátumra módosítja őket. Ez a szakasz minden Spark NLP-folyamat belépési pontja. A DocumentAssembler egy oszlopot
Stringvagy egyArray[String]. A szöveg előfeldolgozására használhatósetCleanupMode. Alapértelmezés szerint ez a mód ki van kapcsolva.SentenceDetector: Egy széljegyzet, amely a megadott megközelítéssel észleli a mondathatárokat. Ez a széljegyzet minden kibontott mondatot visszaadhat egy
Array. Az egyes mondatokat egy másik sorban is visszaadhatja, ha igaz értékre van állítvaexplodeSentences.Tokenizer: Egy jegyzet, amely a nyers szöveget jogkivonatokra vagy egységekre( például szavakra, számokra és szimbólumokra) választja el, és visszaadja a jogkivonatokat egy
TokenizedSentencestruktúrában. Ez az osztály nincs beépítve. Ha megfelel egy jogkivonat-szabályzónak, a belsőRuleFactorya bemeneti konfigurációt használja a tokenizálási szabályok beállításához. A Tokenizer nyílt szabványokat használ a jogkivonatok azonosításához. Ha az alapértelmezett beállítások nem felelnek meg az igényeinek, szabályokat adhat hozzá a Tokenizer testreszabásához.Normalizer: Jogkivonatokat tisztító széljegyzet. Normalizer igényel szárak. A Normalizer normál kifejezéseket és szótárakat használ a szöveg átalakításához és a piszkos karakterek eltávolításához.
WordEmbeddings: Keresési széljegyzetek, amelyek a jogkivonatokat vektorokhoz rendelik. A beágyazásokhoz egyéni jogkivonat-keresőszótárat is
setStoragePathmegadhat. A szótár minden sorának tartalmaznia kell egy jogkivonatot és annak vektoros ábrázolását szóközök szerint elválasztva. Ha nem található jogkivonat a szótárban, az eredmény egy azonos dimenzióból álló nulla vektor.
A Spark NLP Spark MLlib-folyamatokat használ, amelyeket az MLflow natív módon támogat. Az MLflow egy nyílt forráskódú platform a gépi tanulási életciklushoz. Összetevői a következők:
- MLflow Tracking: A kísérleteket rögzíti, és lehetővé teszi az eredmények lekérdezését.
- MLflow-projektek: Lehetővé teszi adatelemzési kód futtatását bármely platformon.
- MLflow-modellek: Különböző környezetekben helyez üzembe modelleket.
- Modellregisztrációs adatbázis: Egy központi adattárban tárolt modellek kezelése.
Az MLflow integrálva van az Azure Databricksbe. Az MLflow bármely más Spark-alapú környezetben telepíthető a kísérletek nyomon követéséhez és kezeléséhez. Az MLflow Modellregisztrációs adatbázis használatával is elérhetővé teheti a modelleket éles környezetben.
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerzők:
- Moritz Steller | Vezető felhőmegoldás-tervező
- Zoiner Tejada | vezérigazgató és tervező
Következő lépések
A Spark NLP dokumentációja:
Azure-összetevők:
További források:
Kapcsolódó erőforrások
- Nagy léptékű egyéni természetes nyelvi feldolgozás az Azure-ban
- Microsoft Azure AI-szolgáltatási technológia kiválasztása
- A Microsoft gépi tanulási termékeinek és technológiáinak összehasonlítása
- MLflow és Azure Machine Learning
- Mesterséges intelligenciák bővítése képekkel és természetes nyelvi feldolgozással az Azure Cognitive Searchben
- Hírcsatornák elemzése közel valós idejű elemzéssel kép- és természetes nyelvi feldolgozással