Ez az ügyfélprojekt segített egy Fortune 500 élelmiszer-vállalatnak javítani a kereslet előrejelzését. A vállalat közvetlenül több kiskereskedelmi üzletbe szállít termékeket. A fejlesztés segített nekik optimalizálni termékeik raktárkészletét a Egyesült Államok több régiójában található különböző üzletekben. Ennek elérése érdekében a Microsoft kereskedelmi szoftvermérnöki (C Standard kiadás) csapata az ügyfél adattudósaival együtt dolgozott egy kísérleti tanulmányon, amely testre szabott gépi tanulási modelleket fejlesztett ki a kiválasztott régiók számára. A modellek a következőket veszik figyelembe:
- Vásárlói demográfiai adatok
- Történelmi és előrejelzési időjárás
- Korábbi szállítmányok
- Termékvisszajelzések
- Speciális események
A harisnya optimalizálásának célja a projekt egyik fő összetevője volt, és az ügyfél jelentős értékesítési emelést valósított meg a korai helyszíni kísérletekben. A csapat emellett 40%-kal csökkentette az előrejelzés átlagos abszolút százalékos hibáját (MAPE) egy korábbi átlagos alapmodellhez képest.
A projekt egyik fontos része az adatelemzési munkafolyamat vertikális felskálázása volt a próbatanulmánytól az éles szintre. Ehhez az éles szintű munkafolyamathoz a C Standard kiadás csapatnak a következőket kellett végeznie:
- Modellek fejlesztése számos régióhoz.
- A modellek teljesítményének folyamatos frissítése és monitorozása.
- Az adatok és a mérnöki csapatok közötti együttműködés elősegítése.
A tipikus adatelemzési munkafolyamat ma közelebb áll egy egyszeri laborkörnyezethez, mint egy éles munkafolyamathoz. Az adattudósok környezetének alkalmasnak kell lennie a következő célokra:
- Készítse elő az adatokat.
- Kísérletezzen különböző modellekkel.
- Hiperparaméterek hangolása.
- Hozzon létre egy build-test-evaluate-refine ciklust.
Az ilyen feladatokhoz használt eszközök többsége konkrét célokkal rendelkezik, és nem alkalmas az automatizálásra. Az éles szintű gépi tanulási műveleteknél nagyobb figyelmet kell fordítani az alkalmazás életciklus-felügyeletére és a DevOpsra.
A C Standard kiadás csapat segített az ügyfélnek a műveletet éles szintre skálázni. A folyamatos integráció és a folyamatos teljesítés (CI/CD) képességeinek különböző aspektusait valósították meg, és olyan problémákat kezeltek, mint a megfigyelhetőség és az Azure-képességekkel való integráció. A megvalósítás során a csapat hiányosságokat tárt fel a meglévő MLOps-útmutatóban. Ezeket a réseket ki kellett tölteni, hogy az MLOps jobban megérthető legyen, és nagy léptékben alkalmazható legyen.
Az MLOps-eljárások megismerése segít a szervezeteknek biztosítani, hogy a rendszer által előállított gépi tanulási modellek olyan éles minőségű modellek legyenek, amelyek javítják az üzleti teljesítményt. Az MLOps megvalósításakor a szervezetnek már nem kell annyi időt fordítania az alacsony szintű részletekre, mint azokra az infrastruktúrára és mérnöki munkára, amelyek az éles üzemhez szükséges gépi tanulási modellek fejlesztéséhez és futtatásához szükségesek. Az MLOps implementálása abban is segít az adatelemzési és szoftvermérnöki közösségeknek, hogy megtanuljanak együttműködni egy éles üzemre kész rendszer megvalósításában.
A C Standard kiadás csapat ezt a projektet használta a gépi tanulási közösség igényeinek kielégítésére olyan problémák megoldásával, mint egy MLOps-érettségi modell fejlesztése. Ezek az erőfeszítések célja az MLOps bevezetésének javítása volt, az MLOps-folyamat kulcsfontosságú szereplőinek tipikus kihívásainak megértésével.
Előjegyzési és technikai forgatókönyvek
Az előjegyzési forgatókönyv azokat a valós kihívásokat ismerteti, amelyeket a C Standard kiadás csapatnak meg kellett oldania. A technikai forgatókönyv meghatározza egy olyan MLOps-életciklus létrehozásának követelményeit, amely ugyanolyan megbízható, mint a jól bevált DevOps-életciklus.
Előjegyzési forgatókönyv
Az ügyfél rendszeresen szállít termékeket közvetlenül a kiskereskedelmi üzletekbe. Az egyes kiskereskedelmi üzletek a termékhasználati mintákban eltérőek, ezért a termékleltárnak minden héten eltérőnek kell lennie. Az ügyfél által használt kereslet-előrejelzési módszerek célja az értékesítés maximalizálása és a termékvisszatérítések és az elveszett értékesítési lehetőségek minimalizálása. Ez a projekt a gépi tanulást használta az előrejelzések javítására.
A C Standard kiadás csapat két fázisra osztotta a projektet. Az 1. fázis a gépi tanulási modellek fejlesztésére összpontosított a kiválasztott értékesítési régió gépi tanulási előrejelzésének hatékonyságáról szóló helyszíni próbatanulmány támogatására. Az 1. fázis sikeressége a 2. fázishoz vezetett, amelyben a csapat a kezdeti kísérleti tanulmányt egy olyan minimális modellcsoportból skálázta fel, amely egyetlen földrajzi régiót támogatott fenntartható termelési szintű modellek készletére az ügyfél összes értékesítési régiójában. A vertikálisan felskálázott megoldás elsődleges szempontja a nagy számú földrajzi régió és a helyi kiskereskedelmi egységek elhelyezésének szükségessége volt. A csapat a gépi tanulási modelleket az egyes régiókban található nagy és kis kiskereskedelmi üzleteknek szentelte.
Az 1. fázisú kísérleti tanulmány megállapította, hogy egy régió kiskereskedelmi egységeinek dedikált modellje a helyi értékesítési előzményeket, a helyi demográfiai adatokat, az időjárást és a különleges eseményeket használhatja a régióban található üzletek kereslet-előrejelzésének optimalizálásához. Négy együttes gépi tanulási előrejelzési modell szolgálta a piacokat egyetlen régióban. A modellek heti kötegekben dolgozták fel az adatokat. A csapat emellett két alapmodellt is kifejlesztett az összehasonlításhoz használt előzményadatokkal.
A felskálázott 2. fázisú megoldás első verziójában a C Standard kiadás csapat 14 földrajzi régiót választott ki a részvételhez, beleértve a kis és nagy piaci piacokat is. Több mint 50 gépi tanulási előrejelzési modellt használtak. A csapat további rendszernövekedést és a gépi tanulási modellek folyamatos finomítását várta. Gyorsan világossá vált, hogy ez a szélesebb körű gépi tanulási megoldás csak akkor fenntartható, ha a DevOps ajánlott gyakorlati alapelvein alapul a gépi tanulási környezetben.
| Környezet | Piaci régió | Formátum | Modellek | Modell alosztálya | Modell leírása |
|---|---|---|---|---|---|
| Fejlesztői környezet | Minden földrajzi piac/régió (például Észak-Texas) | Nagy formátumú üzletek (szupermarketek, big box üzletek stb.) | Két együttes modell | Termékek lassú mozgatása | A lassú és a gyors is rendelkezik legalább abszolút zsugorodási és kiválasztási operátorral (LASSO) rendelkező lineáris regressziós modellel és kategorikus beágyazásokkal rendelkező neurális hálózattal |
| Gyorsan mozgó termékek | A lassú és a gyors is rendelkezik EGY LASSO lineáris regressziós modellből és egy neurális hálózatból álló együttessel kategorikus beágyazásokkal | ||||
| Egy együttes modell | n/a | Előzményátlag | |||
| Kis formátumú üzletek (gyógyszertárak, kisboltok stb.) | Két együttes modell | Termékek lassú mozgatása | A lassú és a gyors is rendelkezik EGY LASSO lineáris regressziós modellből és egy neurális hálózatból álló együttessel kategorikus beágyazásokkal | ||
| Gyorsan mozgó termékek | A lassú és mindkettő lasso lineáris regressziós modellből és kategorikus beágyazásokkal rendelkező neurális hálózatból áll | ||||
| Egy együttes modell | n/a | Előzményátlag | |||
| Ugyanaz, mint egy további 13 földrajzi régió esetében | |||||
| Ugyanaz, mint a prod környezet esetében |
Az MLOps-folyamat egy keretrendszert biztosított a felskálázott rendszer számára, amely a gépi tanulási modellek teljes életciklusát kezelte. A keretrendszer magában foglalja a fejlesztést, tesztelést, üzembe helyezést, üzemeltetést és monitorozást. Kielégíti a klasszikus CI/CD-folyamat igényeit. A DevOpshoz képest viszonylagos éretlensége miatt azonban nyilvánvalóvá vált, hogy a meglévő MLOps-útmutatóban hiányosságok voltak. A projektcsapat azon dolgozott, hogy kitöltse a hiányosságok egy részét. Olyan funkcionális folyamatmodellt akartak biztosítani, amely biztosítja a felskálázott gépi tanulási megoldás életképességét.
A projektből kifejlesztett MLOps-folyamat jelentős valós lépést tett az MLOps magasabb szintű érettséghez és életképességhez való áthelyezéséhez. Az új folyamat közvetlenül alkalmazható más gépi tanulási projektekre. A C Standard kiadás csapat a tanultak alapján készített egy MLOps-érettségi modell vázlatát, amelyet bárki alkalmazhat más gépi tanulási projektekre.
Technikai forgatókönyv
Az MLOps, más néven DevOps a gépi tanuláshoz egy olyan gyűjtőkifejezés, amely olyan filozófiákat, gyakorlatokat és technológiákat foglal magában, amelyek a gépi tanulási életciklusok éles környezetben való implementálásához kapcsolódnak. Még mindig viszonylag új fogalom. Számos kísérlet történt az MLOps meghatározására, és sokan megkérdőjelezték, hogy az MLOps képes-e mindent eltűrni attól, hogy az adattudósok hogyan készítik elő az adatokat a gépi tanulási eredmények végső kézbesítéséhez, monitorozásához és kiértékeléséhez. Bár a DevOpsnak sok éve van arra, hogy alapvető gyakorlatokat dolgozzon ki, az MLOps még mindig korai fejlesztés alatt áll. Ahogy fejlődik, felfedezzük azokat a kihívásokat, amelyek két olyan szemlélet összevonásával járnak, amelyek gyakran különböző képességkészletekkel és prioritásokkal működnek: a szoftver-/ops engineering és az adatelemzés.
Az MLOps valós éles környezetben való implementálása egyedi kihívásokkal rendelkezik, amelyeket meg kell oldani. A Teams az Azure használatával támogatja az MLOps-mintákat. Az Azure eszközkezelési és vezénylési szolgáltatásokat is biztosít az ügyfeleknek a gépi tanulási életciklus hatékony kezeléséhez. Az Ebben a cikkben ismertetett MLOps-megoldás alapja az Azure-szolgáltatások.
Gépi tanulási modell követelményei
Az 1. fázisú kísérleti tanulmány során a munka nagy része azokat a gépi tanulási modelleket hozta létre, amelyeket a C Standard kiadás csapata egyetlen régióban alkalmazott a nagy és kis kiskereskedelmi üzletekre. A mellékelt modellekre vonatkozó jelentős követelmények:
Az Azure Machine Tanulás szolgáltatás használata.
A Jupyter notebookokban kifejlesztett és Pythonban implementált kezdeti kísérleti modellek.
Feljegyzés
A Teams ugyanezt a gépi tanulási módszert használta a nagy és a kis üzletek esetében is, de a betanítási és pontozási adatok az áruház méretétől függtek.
A modellhasználat előkészítését igénylő adatok.
A kötegelt feldolgozású adatok nem valós időben, hanem kötegelt feldolgozásra kerülnek.
A modell újratanítása kód- vagy adatváltozáskor, illetve a modell elavult állapotában.
A modell teljesítményének megtekintése a Power BI-irányítópultokon.
A modell teljesítménye a pontozásban, amely akkor számít jelentősnek, ha a MAPE <= 45% egy korábbi átlagos alapmodellhez képest.
MLOps-követelmények
A csapatnak több alapvető követelménynek is meg kellett felelnie ahhoz, hogy felskálázza a megoldást az 1. fázisú kísérleti tanulmányból, amelyben csak néhány modellt fejlesztettek ki egyetlen értékesítési régióhoz. A 2. fázis egyéni gépi tanulási modelleket implementált több régióhoz. A megvalósítás a következőt tartalmazza:
Heti kötegelt feldolgozás nagy és kis méretű üzletek számára minden régióban a modellek új adatkészletekkel való újratanításához.
A gépi tanulási modellek folyamatos finomítása.
A CI/CD-hez gyakran használt fejlesztési/tesztelési/csomag-/tesztelési/üzembe helyezési folyamat integrálása az MLOpshoz készült DevOps-szerű feldolgozási környezetben.
Feljegyzés
Ez azt jelenti, hogy az adattudósok és az adatmérnökök gyakran dolgoztak a múltban.
Egyedi modell, amely az áruházelőzmények, demográfiai adatok és egyéb kulcsváltozók alapján képviselte az egyes régiókat a nagy és a kis üzletek számára. A modellnek a teljes adatkészletet fel kellett dolgoznia, hogy minimalizálja a feldolgozási hibák kockázatát.
A 14 értékesítési régió támogatására való kezdeti skálázás lehetősége további vertikális felskálázási tervekkel.
További modelleket tervez a régiók és más tárolófürtök hosszabb távú előrejelzéséhez.
Gépi tanulási modellmegoldás
A gépi tanulási életciklus, más néven adatelemzési életciklus nagyjából az alábbi magas szintű folyamatfolyamathoz illeszkedik:
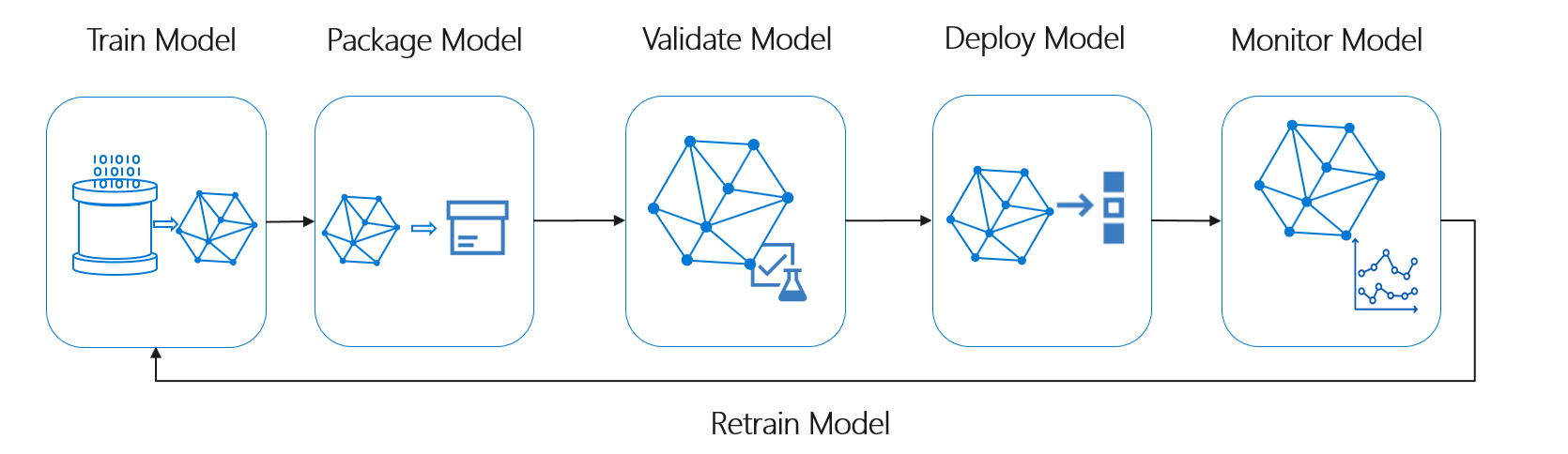
Az üzembe helyezési modell az érvényesített gépi tanulási modell bármilyen működési használatát jelentheti. A DevOpshoz képest az MLOps további kihívást jelent a gépi tanulási életciklusnak a tipikus CI/CD-folyamatba való integrálásával.
Az adatelemzési életciklus nem követi a szoftverfejlesztési életciklust. Magában foglalja az Azure Machine Tanulás használatát a modellek betanítása és pontszáma érdekében, ezért ezeket a lépéseket bele kellett foglalni a CI/CD automatizálásába.
Az architektúra alapja az adatok kötegelt feldolgozása. A folyamat középpontjában két Azure Machine Tanulás folyamat áll, az egyik a betanításhoz, a másik pedig a pontozáshoz. Ez az ábra az ügyfélprojekt kezdeti fázisához használt adatelemzési módszertant mutatja be:
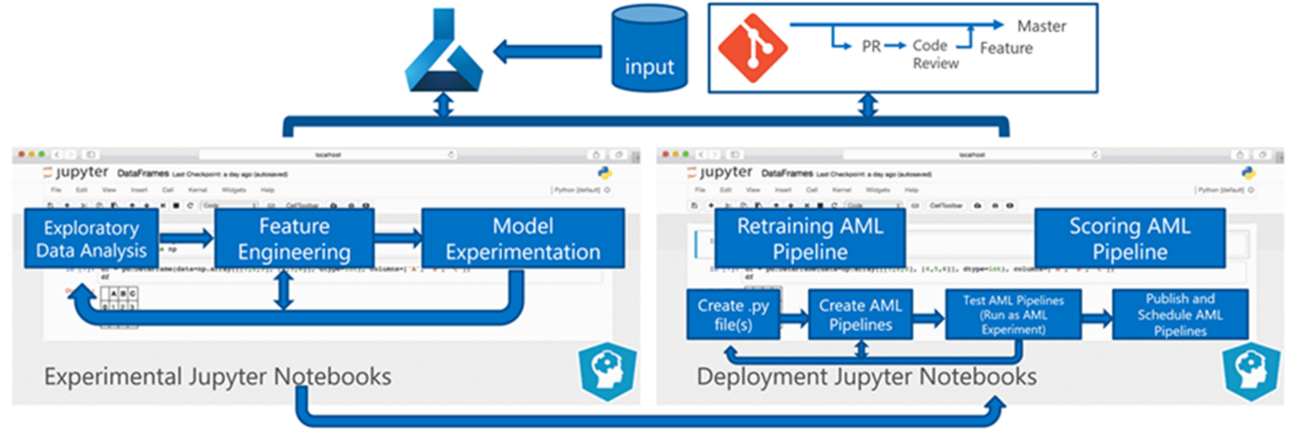
A csapat több algoritmust is tesztelt. Végül egy LASSO lineáris regressziós modell és egy kategorikus beágyazású neurális hálózat együttes kialakítását választották. A csapat ugyanazt a modellt használta, amelyet az ügyfél által a helyszínen tárolható termékszint határoz meg mind a nagy, mind a kis üzletek esetében. A csapat tovább osztotta a modellt gyorsan mozgó és lassan mozgó termékekre.
Az adattudósok betanítják a gépi tanulási modelleket, amikor a csapat új kódot ad ki, és amikor új adatok állnak rendelkezésre. A betanítás általában hetente történik. Ezért minden feldolgozási futtatás nagy mennyiségű adatot foglal magában. Mivel a csapat számos forrásból gyűjti az adatokat különböző formátumokban, kondicionálást igényel, hogy az adatokat hasznosítható formátumban helyezhesse el, mielőtt az adatszakértők feldolgozhatják őket. Az adatkondicionálás jelentős manuális erőfeszítést igényel, és a C Standard kiadás csapat az automatizálás elsődleges jelöltjeként azonosította.
Mint említettük, az adattudósok az 1. fázis kísérleti tereptanulmányában egyetlen értékesítési régióban fejlesztették ki és alkalmazták a kísérleti Azure Machine Tanulás modelleket az előrejelzési megközelítés hasznosságának kiértékelésére. A C Standard kiadás csapat úgy ítélte meg, hogy a kísérleti tanulmányban szereplő üzletek értékesítési emelése jelentős volt. Ez a siker indokolta a megoldás alkalmazását a 2. fázis teljes termelési szintjeire, kezdve 14 földrajzi régióval és több ezer üzlettel. A csapat ezután ugyanezt a mintát használhatja további régiók hozzáadásához.
A felskálázott megoldás alapjául a próbamodell szolgált, de a C Standard kiadás csapata tudta, hogy a modell további finomítást igényel a teljesítmény javítása érdekében.
MLOps-megoldás
Az MLOps-fogalmak érlelése során a csapatok gyakran szembesülnek az adatelemzési és DevOps-szemléletek összefogásával kapcsolatos kihívásokkal. Ennek az az oka, hogy a tudományágak, a szoftvermérnökök és az adattudósok fő szereplői különböző képességkészletekkel és prioritásokkal működnek.
De vannak hasonlóságok, amelyekre építeni kell. Az MLOps, mint a DevOps, egy eszközlánc által implementált fejlesztési folyamat. Az MLOps eszközlánc többek között a következőket tartalmazza:
- Verziókövetés
- Kódelemzés
- Buildautomatizálás
- Folyamatos integráció
- Tesztelési keretrendszerek és automatizálás
- A CI/CD-folyamatokba integrált megfelelőségi szabályzatok
- Üzembe helyezés automatizálása
- Figyelés
- Vészhelyreállítás és magas rendelkezésre állás
- Csomag- és tárolókezelés
Mint fentebb említettük, a megoldás kihasználja a meglévő DevOps-útmutatást, de ki van bővítve, hogy egy érettebb MLOps-implementációt hozzon létre, amely megfelel az ügyfél és az adatelemzési közösség igényeinek. Az MLOps a DevOps útmutatására épül az alábbi további követelményekkel:
- Az adatok és a modellek verziószámozása nem ugyanaz, mint a kódverziók: Az adathalmazok verziószámozásának a séma és a forrásadatok változásakor kell végbemenően végbemenően végbemenő verziószámozást végeznie.
- Digitális naplózási nyomvonalra vonatkozó követelmények: A kód- és ügyféladatok kezelésekor minden változás nyomon követése.
- Általánosítás: A modellek eltérnek az újrafelhasználási kódtól, mivel az adatelemzőknek a bemeneti adatok és forgatókönyvek alapján kell finomhangolniuk a modelleket. Ha egy modellt újra fel szeretne használni egy új forgatókönyvhöz, lehet, hogy finomhangolnia/átadnia/tanulnia kell. Szüksége van a betanítási folyamatra.
- Elavult modellek: A modellek idővel romlanak, és igény szerint újra kell őket képezni annak biztosítása érdekében, hogy továbbra is relevánsak maradjanak az éles környezetben.
MLOps-kihívások
Nem éretlen MLOps standard
Az MLOps standard mintája még mindig fejlődik. A megoldások általában az alapoktól készülnek, és egy adott ügyfél vagy felhasználó igényeinek megfelelően készülnek. A C Standard kiadás csapata felismerte ezt a hiányosságot, és a DevOps ajánlott eljárásait próbálta használni ebben a projektben. Bővítették a DevOps-folyamatot, hogy megfeleljenek az MLOps további követelményeinek. A csapat által kifejlesztett folyamat egy működőképes példa arra, hogyan kell kinéznie egy MLOps standard mintának.
A képességkészletek különbségei
A szoftvermérnökök és az adattudósok egyedi képességkészleteket hoznak létre a csapat számára. Ezek a különböző képességkészletek megnehezíthetik a mindenki igényeinek megfelelő megoldás megtalálását. Fontos egy jól érthető munkafolyamat létrehozása a modellkiterjesztéshez a kísérletezéstől az éles környezetig. A csapattagoknak tisztában kell lenniük azzal, hogyan integrálhatják a változásokat a rendszerbe az MLOps-folyamat megszakítása nélkül.
Több modell kezelése
Gyakran több modellre van szükség a nehéz gépi tanulási forgatókönyvek megoldásához. Az MLOps egyik kihívása ezeknek a modelleknek a kezelése, beleértve a következőket:
- Koherens verziószámozási sémával rendelkezik.
- Az összes modell folyamatos kiértékelése és monitorozása.
A modellproblémák diagnosztizálásához és reprodukálható modellek létrehozásához a kód és az adatok nyomon követhető vonalvezetésére is szükség van. Az egyéni irányítópultok képesek értelmezni az üzembe helyezett modellek működését, és jelezhetik, hogy mikor kell beavatkozni. A csapat ilyen irányítópultokat hozott létre ehhez a projekthez.
Szükség van az adatkondicionálásra
Az ezekkel a modellekkel használt adatok számos privát és nyilvános forrásból származnak. Mivel az eredeti adatok rendezetlenek, a gépi tanulási modell nem tud nyers állapotban felhasználni. Az adatelemzőknek szabványos formátumba kell kondicionálást végeznie a gépi tanulási modellek használatához.
A kísérleti teszt nagy része a nyers adatok kondicionálására összpontosított, hogy a gépi tanulási modell feldolgozhassa azokat. Egy MLOps-rendszerben a csapatnak automatizálnia kell ezt a folyamatot, és nyomon kell követnie a kimeneteket.
MLOps érettségi modell
Az MLOps-lejárati modell célja az alapelvek és gyakorlatok tisztázása, valamint az MLOps-implementáció hiányosságainak azonosítása. Azt is meg tudja mutatni az ügyfélnek, hogyan növelheti növekményesen az MLOps-képességet ahelyett, hogy egyszerre próbálná meg végrehajtani. Az ügyfélnek a következő útmutatóként kell használnia:
- Becsülje meg a projekthez tartozó munka hatókörét.
- Sikerességi feltételek létrehozása.
- Termékek azonosítása.
Az MLOps fejlettségi modell öt műszaki képességet határoz meg:
| Level | Leírás |
|---|---|
| 0 | Nincs műveleti művelet |
| 0 | DevOps, de mlOps nélkül |
| 2 | Automatizált betanítás |
| 3 | Automatizált modell üzembe helyezése |
| 4 | Automatizált műveletek (teljes MLOps) |
Az MLOps-lejárati modell aktuális verziójáról lásd az MLOps lejárati modellről szóló cikket.
MLOps-folyamatdefiníció
Az MLOps a nyers adatok beszerzésétől a modell kimenetének biztosításáig minden tevékenységet magában foglal, más néven pontozást:
- Adatkondicionálás
- A modell betanítása
- Modell tesztelése és kiértékelése
- Builddefiníció és folyamat
- Kiadási folyamat
- Telepítés
- Pontozás
Alapszintű gépi tanulási folyamat
Az alapszintű gépi tanulási folyamat hasonlít a hagyományos szoftverfejlesztésre, de jelentős különbségek vannak. Ez az ábra a gépi tanulási folyamat főbb lépéseit mutatja be:
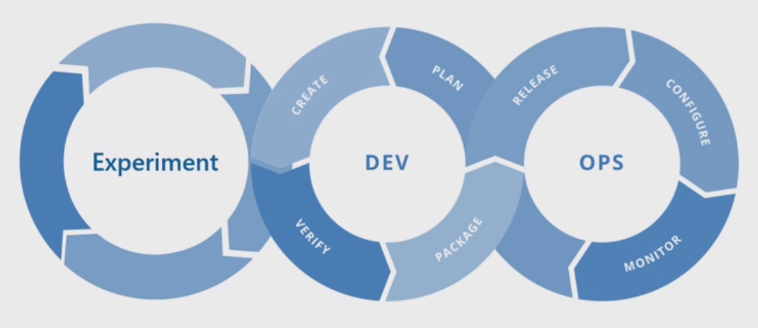
A Kísérlet fázis egyedi az adatelemzési életciklusban, amely tükrözi, hogy az adattudósok hagyományosan hogyan végzik munkájukat. Különbözik attól, ahogyan a kódfejlesztők végzik a munkájukat. Az alábbi ábra részletesebben szemlélteti ezt az életciklust.
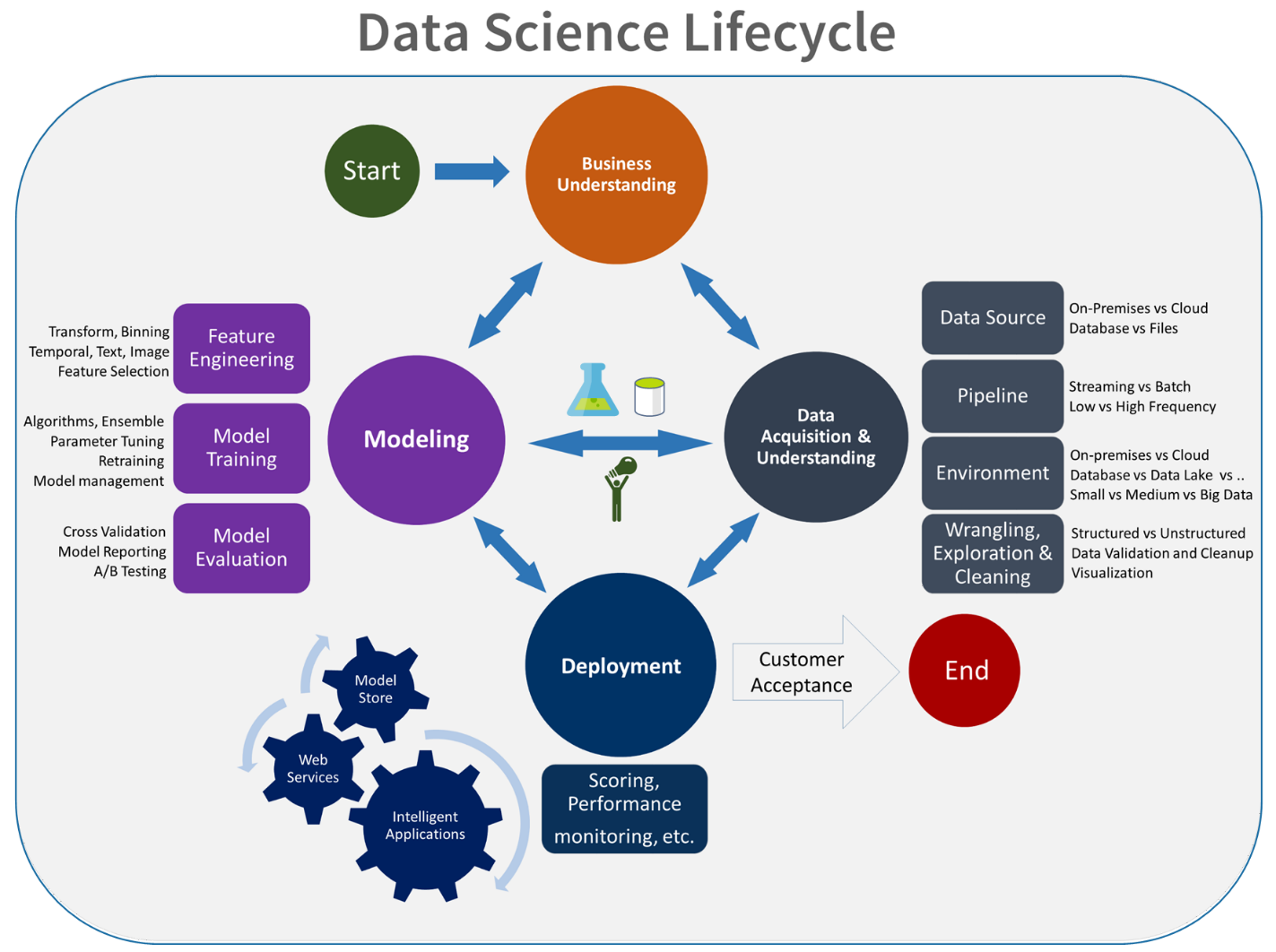
Az adatfejlesztési folyamat MLOpsba való integrálása kihívást jelent. Itt látható az a minta, amelyet a csapat a folyamat integrálásához használt egy olyan űrlapba, amelyet az MLOps támogat:
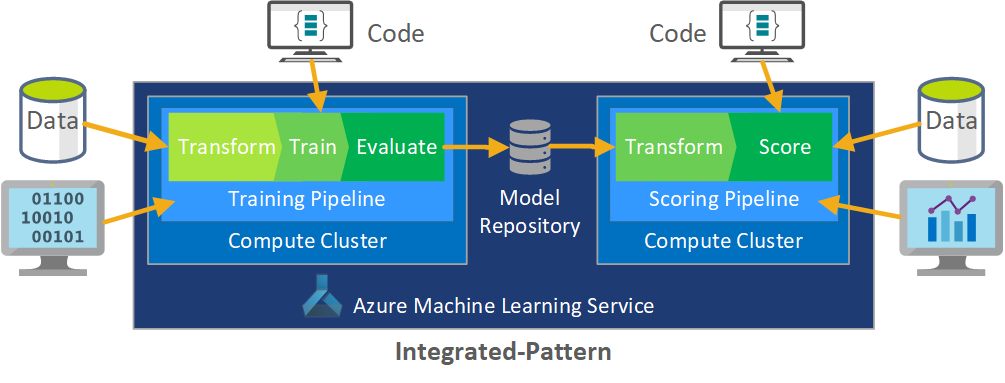
Az MLOps szerepe egy olyan összehangolt folyamat létrehozása, amely hatékonyan támogatja az éles szintű rendszerekben gyakran használt nagyméretű CI/CD-környezeteket. Elméletileg az MLOps-modellnek tartalmaznia kell a kísérletezéstől a pontozásig minden folyamatkövetelményt.
A C Standard kiadás csapat finomított az MLOps-folyamatot az ügyfél egyedi igényeinek megfelelően. A legfontosabb igény a kötegelt feldolgozás volt a valós idejű feldolgozás helyett. Ahogy a csapat kifejlesztette a felskálázott rendszert, azonosítottak és megoldottak néhány hiányosságot. E hiányosságok közül a legjelentősebb az Azure Data Factory és az Azure Machine Tanulás közötti híd kialakításához vezetett, amelyet a csapat egy beépített összekötővel implementált az Azure Data Factoryben. Ezt az összetevőkészletet azért hozták létre, hogy megkönnyítsék a folyamatautomatizálás működéséhez szükséges aktiválást és állapotfigyelést.
Egy másik alapvető változás az volt, hogy az adattudósoknak szükségük volt arra, hogy a kísérleti kódot Jupyter-notebookokból exportálják az MLOps üzembehelyezési folyamatába ahelyett, hogy közvetlenül aktiválták volna a betanítást és a pontozást.
Íme az MLOps-folyamatmodell végső koncepciója:
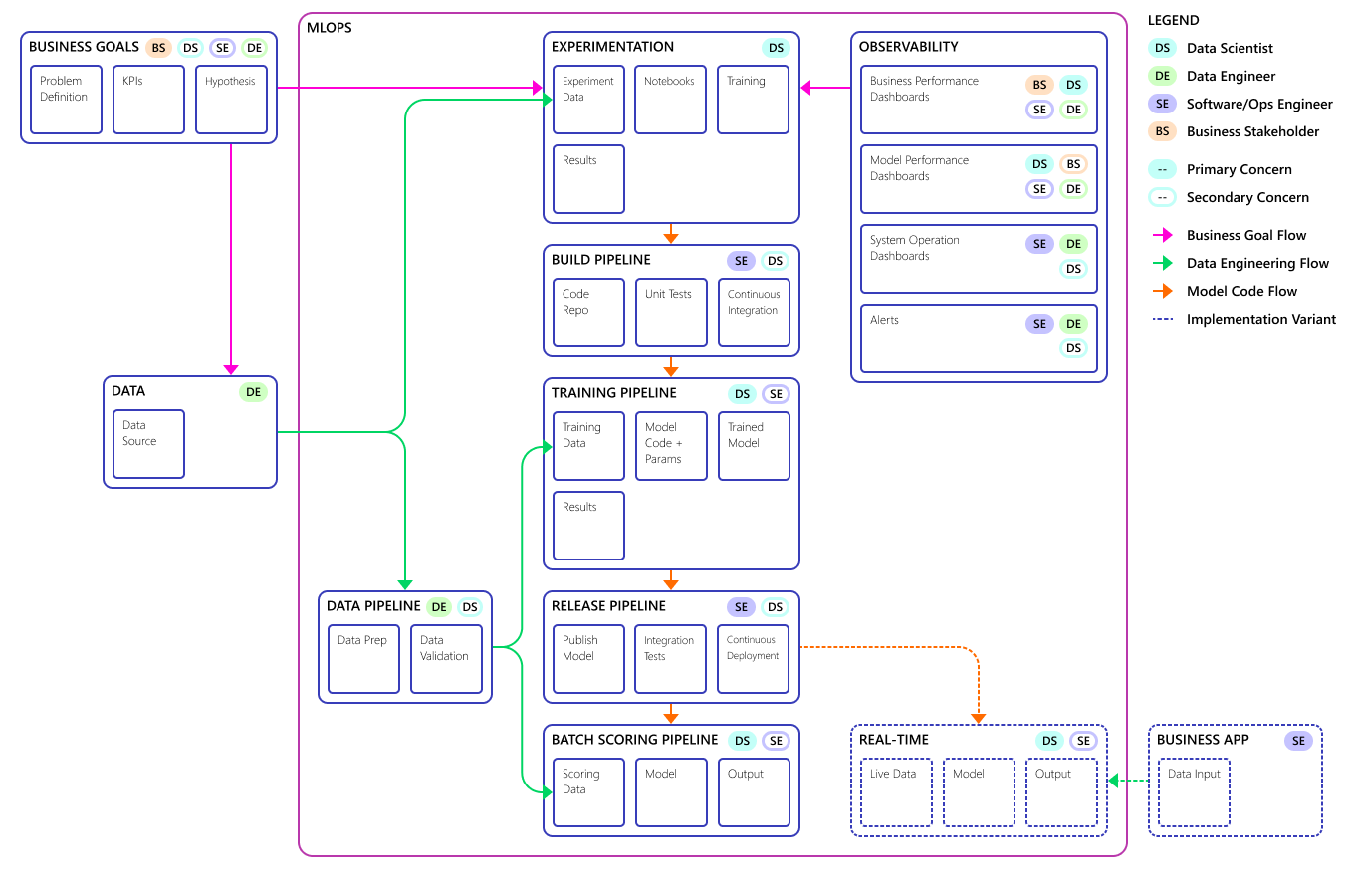
Fontos
A pontozás az utolsó lépés. A folyamat a gépi tanulási modellt futtatja előrejelzések készítéséhez. Ez az igény-előrejelzés alapvető üzleti használati esetkövetelményével foglalkozik. A csapat a MAPE használatával értékeli az előrejelzések minőségét, amely a statisztikai előrejelzési módszerek előrejelzési pontosságának mértéke, valamint a gépi tanulás regressziós problémáinak veszteségfüggvénye. Ebben a projektben a csapat egy = 45%-os MAPE-t <tekintett jelentősnek.
MLOps folyamat
Az alábbi ábra bemutatja, hogyan alkalmazhatók CI-/CD-fejlesztési és kiadási munkafolyamatok a gépi tanulási életciklusra:
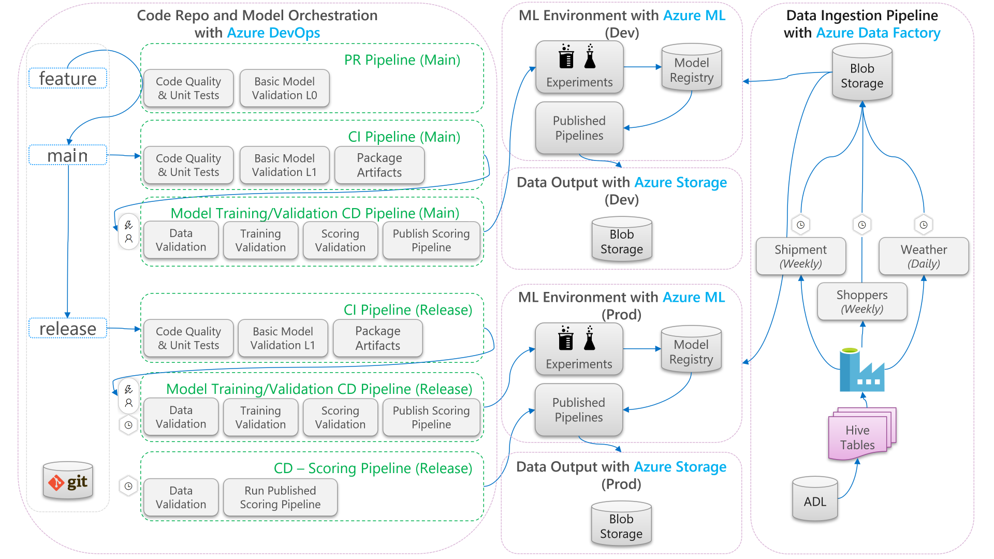
- Ha egy szolgáltatáságból jön létre lekéréses kérelem (PR), a folyamat kódérvényesítési teszteket futtat a kód minőségének egységteszteken és kódminőségi teszteken keresztül történő ellenőrzéséhez. A minőség felsőbb rétegbeli ellenőrzéséhez a folyamat alapszintű modellérvényesítési teszteket is futtat a végpontok közötti betanítási és pontozási lépések ellenőrzéséhez egy példaként megadott adatkészlettel.
- A lekéréses kérelem fő ágba való egyesítésekor a CI-folyamat ugyanazokat a kódérvényesítési teszteket és az alapszintű modellérvényesítési teszteket fogja futtatni a megnövekedett időszakkal. A folyamat ezután csomagolja a kódot és bináris fájlokat tartalmazó összetevőket a gépi tanulási környezetben való futtatáshoz.
- Miután az összetevők elérhetővé válnak, a rendszer elindít egy modellérvényesítési CD-folyamatot . A fejlesztési gépi tanulási környezetben végpontok közötti ellenőrzést futtat. A rendszer közzétett egy pontozási mechanizmust. Kötegelt pontozási forgatókönyv esetén a rendszer közzétevő egy pontozási folyamatot a gépi tanulási környezetben, és aktiválódik az eredmények előállításához. Ha valós idejű pontozási forgatókönyvet szeretne használni, közzétehet egy webalkalmazást, vagy üzembe helyezhet egy tárolót.
- A mérföldkő létrehozása és a kiadási ágba való egyesítése után a rendszer ugyanazt a CI-folyamatot és a modellérvényesítési CD-folyamatot aktiválja. Ezúttal a kiadási ágból származó kódon futnak.
A fent látható MLOps-folyamatokat archetípus-keretrendszerként tekintheti a hasonló architekturális döntéseket hozó projektekhez.
Kódérvényesítési tesztek
A gépi tanulás kódérvényesítési tesztjei a kódbázis minőségének ellenőrzésére összpontosítanak. Ez ugyanaz a koncepció, mint bármely olyan mérnöki projekt, amely kódminőségi tesztekkel (linting), egységtesztekkel és kódlefedettségi mérésekkel rendelkezik.
Alapszintű modellérvényesítési tesztek
A modellérvényesítés általában az érvényes gépi tanulási modell létrehozásához szükséges teljes körű folyamatlépések érvényesítését jelenti. A következő lépéseket tartalmazza:
- Adatérvényesítés: Biztosítja a bemeneti adatok érvényességét.
- Betanítás ellenőrzése: Biztosítja a modell sikeres betanítását.
- Pontozás ellenőrzése: Biztosítja, hogy a csapat sikeresen használja a betanított modellt a bemeneti adatokkal való pontozáshoz.
A gépi tanulási környezetben a lépések teljes készletének futtatása költséges és időigényes. Ennek eredményeképpen a csapat helyileg végzett alapszintű modellérvényesítési teszteket egy fejlesztőgépen. A fenti lépéseket futtatta, és a következőket használta:
- Helyi tesztelési adatkészlet: Egy kis adatkészlet, amely gyakran el van rejtve, be van jelentkezve az adattárba, és bemeneti adatforrásként van felhasználva.
- Helyi jelző: A modell kódjában lévő jelölő vagy argumentum, amely azt jelzi, hogy a kód helyileg kívánja futtatni az adathalmazt. A jelző arra utasítja a kódot, hogy megkerülje a gépi tanulási környezet hívását.
Ezen érvényesítési tesztek célja nem a betanított modell teljesítményének kiértékelése. Ehelyett ellenőrizni kell, hogy a végpontok közötti folyamat kódja jó minőségű-e. Biztosítja a leküldéses kód minőségét, például a modellérvényesítési tesztek beépítését a PR- és CI-buildbe. Emellett lehetővé teszi a mérnökök és adattudósok számára, hogy hibakeresési célokra töréspontokat helyezzenek a kódba.
Modellérvényesítési CD-folyamat
A modellérvényesítési folyamat célja, hogy érvényesítse a gépi tanulási környezetben a modell betanítási és pontozási lépéseit a tényleges adatokkal. A létrehozott betanított modellek bekerülnek a modellregisztrációs adatbázisba, és címkézve lesznek, hogy az ellenőrzés befejezése után várják az előléptetést. Kötegelt előrejelzés esetén az előléptetés a modell ezen verzióját használó pontozási folyamat közzététele lehet. Valós idejű pontozás esetén a modell címkézhető, hogy jelezze, hogy előléptették.
A CD-folyamat pontozása
A pontozó CD-folyamat a kötegelt következtetési forgatókönyvre alkalmazható, ahol a modellérvényesítéshez használt modellvezénylő aktiválja a közzétett pontozási folyamatot.
Fejlesztési és éles környezetek
Célszerű elkülöníteni a fejlesztési (fejlesztői) környezetet az éles (prod) környezettől. Az elkülönítés lehetővé teszi, hogy a rendszer különböző ütemezések szerint aktiválja a modellérvényesítési CD-folyamatot, és pontozza a CD-folyamatot. A leírt MLOps-folyamat esetében a fő ágat célzó folyamatok a fejlesztői környezetben futnak, és a kiadási ágat célzó folyamat a prod környezetben fut.
Kódmódosítások és adatváltozások
Az előző szakaszok elsősorban a kódmódosítások fejlesztésről kiadásra történő kezelésével foglalkoznak. Az adatmódosításnak azonban ugyanazt a szigorúságot kell követnie, mint a kódmódosítások, hogy azonos érvényesítési minőséget és konzisztenciát biztosítson az éles környezetben. Adatmódosítási eseményindítóval vagy időzítő eseményindítóval a rendszer aktiválhatja a modellérvényesítési CD-folyamatot és a pontozó CD-folyamatot a modell vezénylőjétől, hogy ugyanazt a folyamatot futtassa, amely a kiadási ág prod környezetében a kódmódosítások esetében fut.
MLOps-személyek és szerepkörök
Az MLOps-folyamatok egyik legfontosabb követelménye, hogy megfeleljen a folyamat számos felhasználójának igényeinek. Tervezés céljából ezeket a felhasználókat egyéni személyként kell figyelembe venni. Ebben a projektben a csapat a következő személyeket azonosította:
- Adatelemző: Létrehozza a gépi tanulási modellt és annak algoritmusait.
- Mérnök
- Adatszakértő: Kezeli az adatkondicionálást.
- Szoftvermérnök: Kezeli az eszközcsomagba és a CI/CD-munkafolyamatba való modellintegrációt.
- Üzemeltetés vagy informació: Felügyeli a rendszerműveleteket.
- Üzleti érdekelt: A gépi tanulási modell előrejelzéseivel és az üzletmenet segítésével kapcsolatos kérdések.
- Adatfelhasználó: A modell kimenetét olyan módon használja fel, amely segíti az üzleti döntések meghozatalát.
A csapatnak három fő megállapítást kellett kezelnie a személy- és szerepkör-vizsgálatokból:
- Az adattudósok és a mérnökök eltérő megközelítést és készségeket dolgoznak. Az MLOps-folyamat tervezésénél fontos szempont az adattudós és a mérnök együttműködésének megkönnyítése. Ehhez minden csapattag új képességszerzést igényel.
- Össze kell egyesíteni az összes fő személyiséget anélkül, hogy bárkit is elidegenítenek. Ennek egyik módja a következő:
- Győződjön meg arról, hogy megértik az MLOps koncepcionális modelljét.
- Egyeztesd meg a csapat azon tagjait, amelyek együtt fognak működni.
- Munkairánymutatók létrehozása a közös célok eléréséhez.
- Ha az üzleti érdekelt feleknek és az adatvégzőknek módot kell adni a modellekből származó adatkimenetek használatára, a szabványos megoldás a felhasználóbarát felhasználói felület.
Más csapatok minden bizonnyal hasonló problémákkal találkoznak más gépi tanulási projektekben, amikor éles használatra felskálázzák őket.
MLOps-megoldásarchitektúra
Logikai architektúra
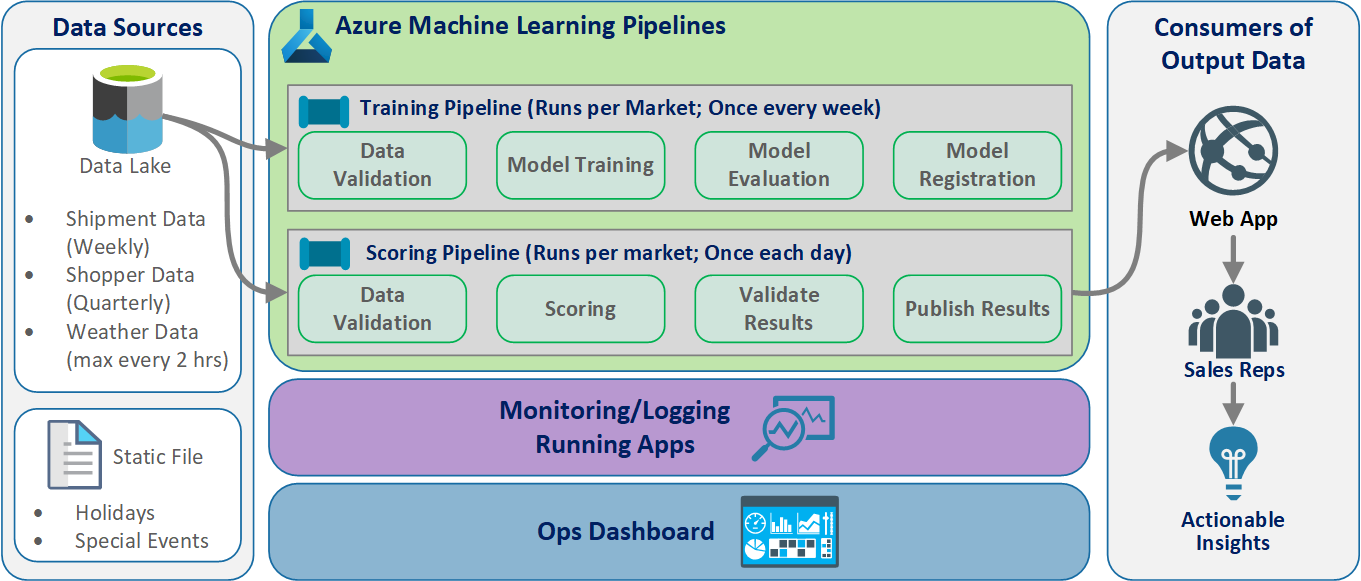
Az adatok számos különböző formátumú forrásból származnak, ezért a data lake-be való beszúrás előtt kondicionáltak. A kondicionálás azure Functions-ként működő mikroszolgáltatások használatával történik. Az ügyfelek úgy szabják testre a mikroszolgáltatásokat, hogy illeszkedjenek az adatforrásokhoz, és szabványosított CSV-formátummá alakítsák őket, amelyet a betanítási és pontozási folyamatok használnak.
Rendszerarchitektúra
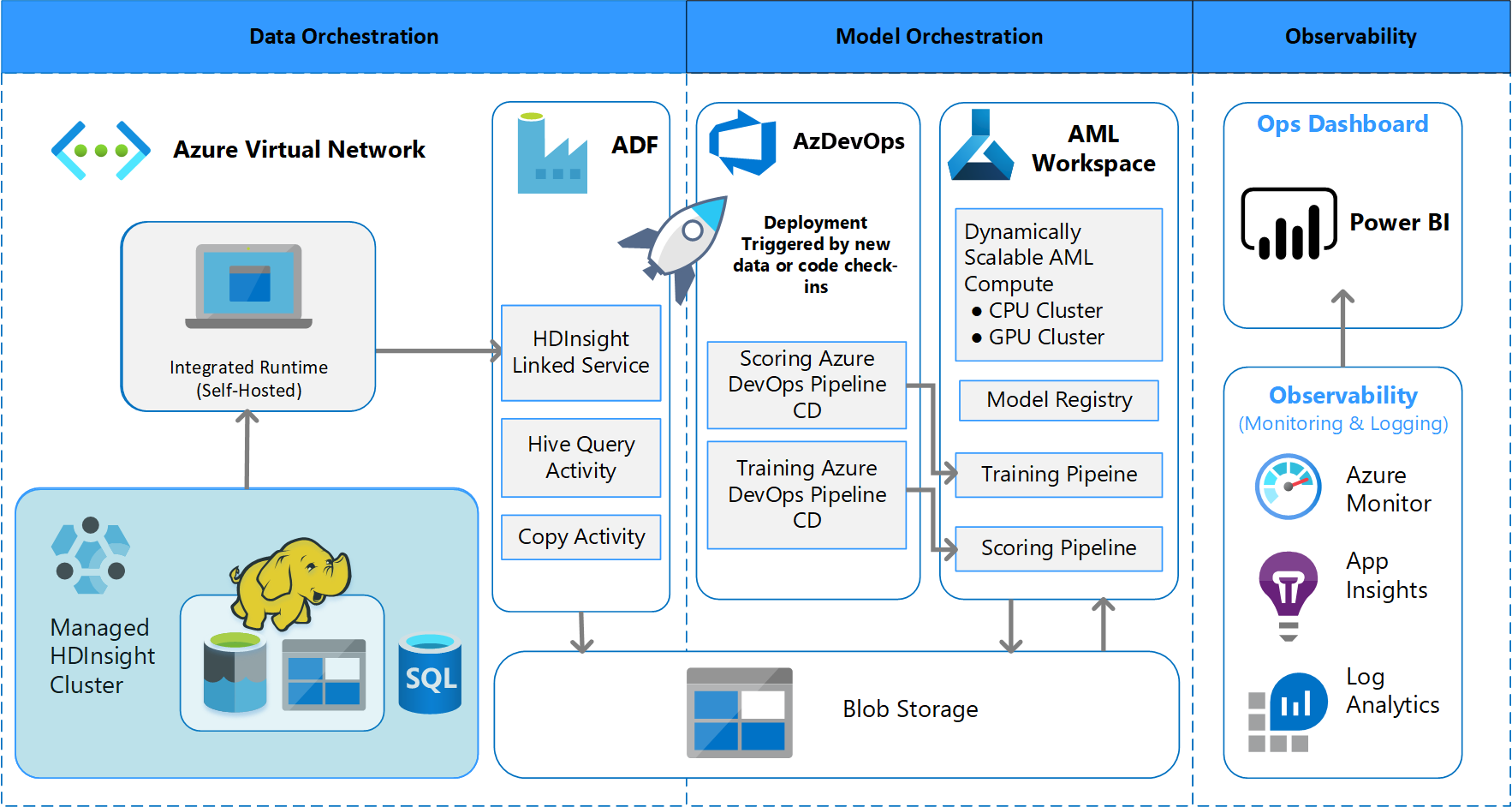
Kötegelt feldolgozási architektúra
A csapat kidolgozta az architektúratervet, hogy támogassa a kötegelt adatfeldolgozási sémát. Vannak alternatívák, de bármi is legyen használva, támogatnia kell az MLOps-folyamatokat. Az elérhető Azure-szolgáltatások teljes használata tervezési követelmény volt. Az alábbi ábrán az architektúra látható:
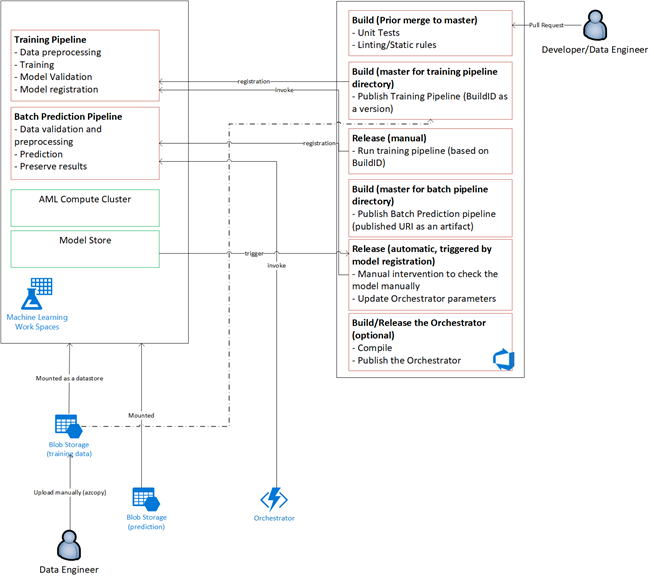
Megoldás áttekintése
Az Azure Data Factory a következőket végzi el:
- Aktivál egy Azure-függvényt az adatbetöltés elindításához és az Azure Machine Tanulás folyamat futtatásához.
- Elindít egy tartós függvényt, amely lekérdezi az Azure Machine Tanulás folyamatot a befejezéshez.
A Power BI egyéni irányítópultjai megjelenítik az eredményeket. Más Azure-irányítópultok, amelyek openCensus Python SDK-val csatlakoznak az Azure SQL-hez, az Azure Monitorhoz és az Alkalmazáshoz Elemzések, nyomon követhetik az Azure-erőforrásokat. Ezek az irányítópultok információt nyújtanak a gépi tanulási rendszer állapotáról. Emellett az ügyfél által a termékrendelések előrejelzéséhez használt adatokat is felhasználják.
Modell vezénylése
A modell vezénylése a következő lépéseket követi:
- A lekéréses kérelem elküldésekor a DevOps elindít egy kódérvényesítési folyamatot.
- A folyamat egységteszteket, kódminőségi teszteket és modellérvényesítési teszteket futtat.
- A fő ágba való egyesítéskor ugyanazok a kódérvényesítési tesztek futnak, és a DevOps csomagolja az összetevőket.
- Az összetevőket gyűjtő DevOps az Azure Machine-Tanulás aktiválja a következőket:
- Adatkiértékelés.
- Betanítás ellenőrzése.
- Pontozás ellenőrzése.
- Az ellenőrzés befejezése után a végső pontozási folyamat lefut.
- Az adatok módosítása és egy új lekéréses kérelem elküldése újra aktiválja az érvényesítési folyamatot, majd a végső pontozási folyamatot.
Kísérletezés engedélyezése
Mint említettük, a hagyományos adatelemzési gépi tanulási életciklus nem támogatja az MLOps-folyamatot módosítás nélkül. Különböző manuális eszközöket és kísérletezést, érvényesítést, csomagolást és modell-átadást használ, amelyek nem skálázhatók könnyen egy hatékony CI/CD-folyamathoz. Az MLOps magas szintű folyamatautomatizálást igényel. Akár új gépi tanulási modellt fejlesztenek, akár egy régit módosítanak, automatizálni kell a gépi tanulási modell életciklusát. A 2. fázis projektben a csapat az Azure DevOps használatával vezénylte és tette közzé újra az Azure Machine Tanulás folyamatokat a betanítási feladatokhoz. A hosszú ideig futó főág elvégzi a modellek alapszintű tesztelését, és stabil kiadásokat küld a hosszú ideig futó kiadási ágon keresztül.
A forrásvezérlés fontos része lesz ennek a folyamatnak. A Git az a verziókövetési rendszer, amely a jegyzetfüzet és a modellkód nyomon követésére szolgál. A folyamatautomatizálást is támogatja. A forrásvezérléshez implementált alapszintű munkafolyamat a következő alapelveket alkalmazza:
- Használjon formális verziószámozást kód- és adatkészletekhez.
- Használjon ágat az új kód fejlesztéséhez, amíg a kód teljesen ki nem fejlesztve és érvényesítve nem lesz.
- Az új kód ellenőrzése után egyesíthető a főágba.
- Egy kiadáshoz létrejön egy állandó verziójú ág, amely a fő ágtól elkülönül.
- A betanításhoz vagy felhasználáshoz kondicionált adathalmazokhoz használjon verzió- és forrásvezérlőt, hogy megőrizhesse az egyes adathalmazok integritását.
- A Jupyter Notebook-kísérletek nyomon követéséhez használja a forrásvezérlőt.
Integráció adatforrásokkal
Az adattudósok számos nyers adatforrást és feldolgozott adatkészletet használnak a különböző gépi tanulási modellekkel való kísérletezéshez. Az éles környezetben az adatok mennyisége túlterhelt lehet. Ahhoz, hogy az adattudósok különböző modellekkel kísérletezhessenek, olyan felügyeleti eszközöket kell használniuk, mint az Azure Data Lake. A formális azonosítás és verziókövetés követelménye minden nyers adatra, előkészített adatkészletre és gépi tanulási modellre vonatkozik.
A projektben az adattudósok a következő adatokat kondicionálták a modellbe való bemenethez:
- Korábbi heti szállítási adatok 2017 januárja óta
- Az egyes irányítószámokkal kapcsolatos előzmény- és előrejelzési napi időjárási adatok
- Vásárlói adatok az egyes üzletazonosítókhoz
Integráció a forrásvezérlővel
Ahhoz, hogy az adattudósok a mérnöki ajánlott eljárásokat alkalmazzák, az általuk használt eszközöket kényelmesen integrálni kell a GitHubhoz hasonló forrásvezérlő rendszerekkel. Ez a gyakorlat lehetővé teszi a gépi tanulási modellek verziószámozását, a csapattagok közötti együttműködést és a vészhelyreállítást, ha a csapatok adatvesztést vagy rendszerkimaradást tapasztalnak.
Modell együttes támogatása
Ebben a projektben a modellterv egy együttes modell volt. Vagyis az adattudósok számos algoritmust használtak a végső modelltervben. Ebben az esetben a modellek ugyanazt az alapszintű algoritmus-kialakítást használták. Az egyetlen különbség az volt, hogy különböző betanítási adatokat és pontozási adatokat használtak. A modellek egy LASSO lineáris regressziós algoritmus és egy neurális hálózat kombinációját használták.
A csapat megvizsgálta, de nem implementálta azt a lehetőséget, hogy továbbvihesse a folyamatot arra a pontra, ahol támogatja, hogy számos valós idejű modell futjon éles környezetben egy adott kérés kiszolgálásához. Ez a lehetőség lehetővé teheti az együttes modellek használatát az A/B-tesztelésben és az interleaved kísérletekben.
Végfelhasználói felületek
A csapat végfelhasználói felhasználói felületeket fejlesztett ki a megfigyelhetőség, a monitorozás és a rendszerezés érdekében. Ahogy már említettük, az irányítópultok vizuálisan jelenítik meg a gépi tanulási modell adatait. Ezek az irányítópultok a következő adatokat jelenítik meg felhasználóbarát formátumban:
- Folyamat lépései, beleértve a bemeneti adatok előzetes feldolgozását is.
- A gépi tanulási modell feldolgozásának állapotának monitorozása:
- Milyen metrikákat gyűjt az üzembe helyezett modellből?
- MAPE: Átlagos abszolút százalékos hiba, az általános teljesítmény nyomon követéséhez szükséges fő metrika. (A MAPE értéke <= 0,45 minden modell esetében.)
- RM Standard kiadás 0: Gyökér-közép-négyzet hiba (RM Standard kiadás), ha a tényleges célérték = 0.
- RM Standard kiadás Minden: RM Standard kiadás a teljes adatkészleten.
- Hogyan értékeli ki, hogy a modell a várt módon teljesít-e az éles környezetben?
- Van mód annak kiderítésére, hogy az éles adatok túl sokat térnek-e el a várt értékektől?
- A modell rosszul teljesít az éles környezetben?
- Van feladatátvételi állapota?
- Milyen metrikákat gyűjt az üzembe helyezett modellből?
- A feldolgozott adatok minőségének nyomon követése.
- A gépi tanulási modell által előállított pontszámok/előrejelzések megjelenítése.
Az alkalmazás az adatok jellegének, valamint az adatok folyamatának és elemzésének módjának megfelelően tölti ki az irányítópultokat. Ezért a csapatnak minden használati esethez meg kell terveznie az irányítópultok pontos elrendezését. Íme két minta irányítópult:
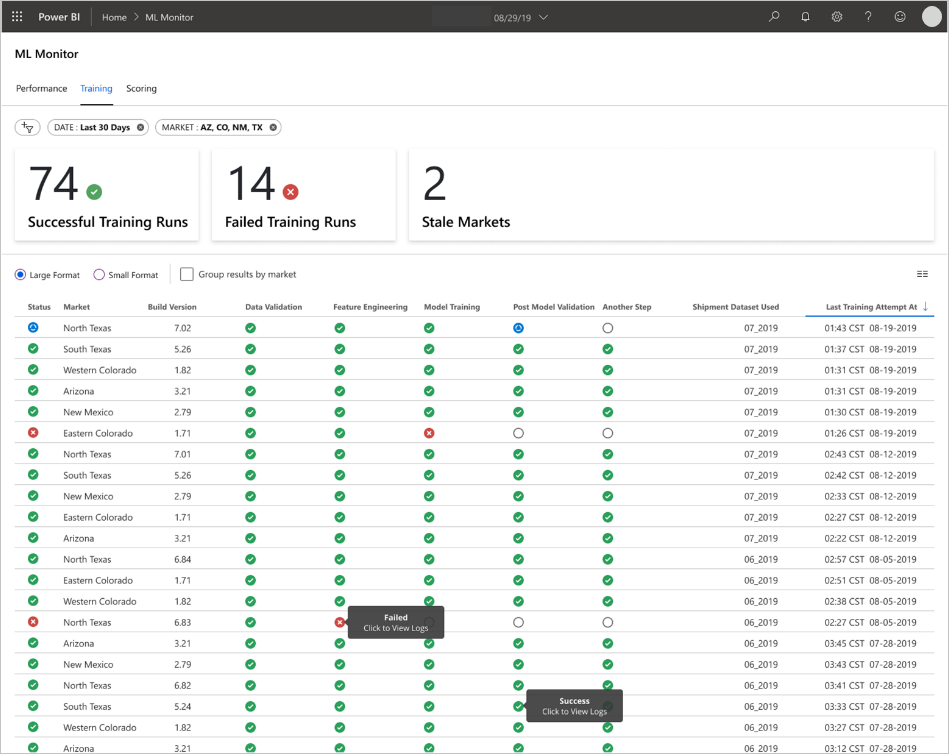
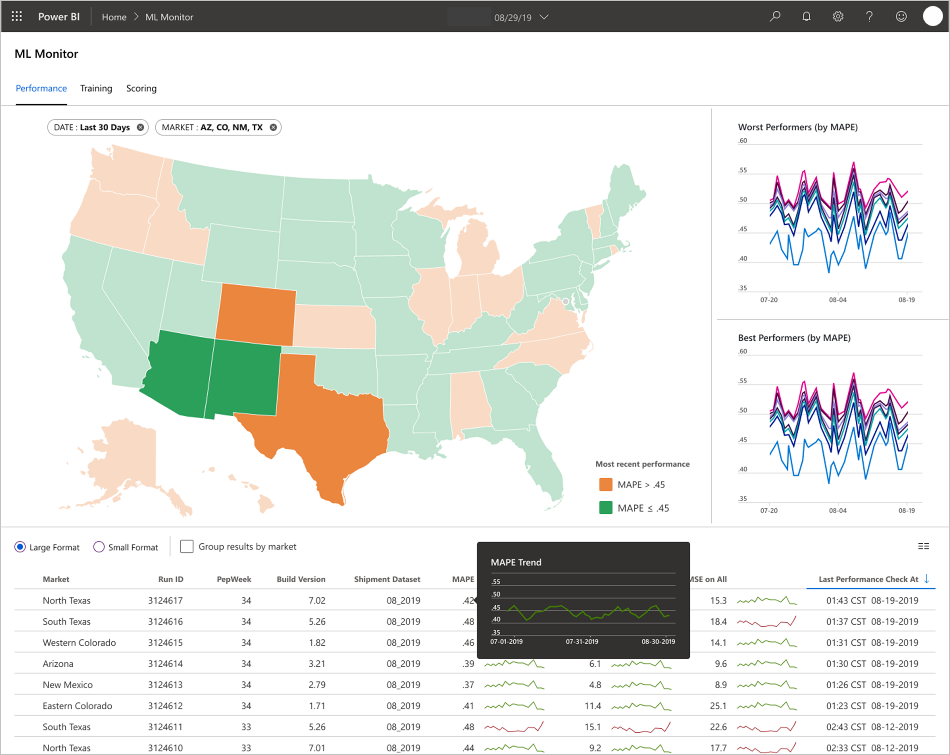
Az irányítópultok úgy lettek kialakítva, hogy könnyen használható információkat nyújtsanak a gépi tanulási modell előrejelzéseinek végfelhasználói számára.
Feljegyzés
Az elavult modellek olyan pontozási futtatások, amelyek során az adattudósok a pontozástól számított 60 napon belül betanítják a pontozáshoz használt modellt. Az ML Monitor irányítópult pontozási oldala megjeleníti ezt az állapotmetrikát.
Összetevők
- Azure Machine Learning
- Azure Blob Storage
- Azure Data Lake Storage
- Azure Pipelines
- Azure Data Factory
- Azure Functions for Python
- Azure Monitor
- Azure SQL Database
- Azure-irányítópultok
- Power BI
Megfontolások
Itt megtalálja a vizsgálandó szempontok listáját. Ezek a C Standard kiadás csapat által a projekt során tanultakon alapulnak.
Környezeti szempontok
- Az adattudósok a legtöbb gépi tanulási modellt a Python használatával fejlesztik, gyakran Jupyter-notebookokkal kezdve. Kihívást jelenthet ezeknek a jegyzetfüzeteknek az éles kódként való implementálása. A Jupyter notebookok inkább kísérleti eszközök, míg a Python-szkriptek inkább éles környezetben használhatók. A csapatoknak gyakran időt kell fordítaniuk a modelllétrehozási kód Python-szkriptekbe való újrabontására.
- A DevOps és a gépi tanulás új ügyfeleinek tudatnia kell, hogy a kísérletezéshez és az éles környezethez eltérő szigorúság szükséges, ezért célszerű elkülöníteni a kettőt.
- Az olyan eszközök, mint az Azure Machine Tanulás Visual Tervező vagy az AutoML, hatékonyan le tudják venni az alapmodelleket a földről, miközben az ügyfél a standard DevOps-eljárásokra támaszkodik, hogy a megoldás többi részére vonatkozzanak.
- Az Azure DevOps beépülő moduljai integrálhatók az Azure Machine Tanulás a folyamat lépéseinek aktiválásához. Az MLOpsPython adattárban van néhány példa az ilyen folyamatokra.
- A gépi tanuláshoz gyakran nagy teljesítményű grafikus feldolgozóegység-(GPU-) gépek szükségesek a betanításhoz. Ha az ügyfél még nem rendelkezik ilyen hardverekkel, az Azure Machine Tanulás számítási fürtök hatékony elérési utat biztosíthatnak az automatikusan skálázható, költséghatékony, hatékony hardverek gyors kiépítéséhez. Ha egy ügyfél speciális biztonsági vagy monitorozási igényekkel rendelkezik, más lehetőségek is rendelkezésre állnak, például standard virtuális gépek, Databricks vagy helyi számítás.
- Ahhoz, hogy egy ügyfél sikeres legyen, a modellkészítő csapatoknak (adattudósoknak) és az üzembe helyezési csapatoknak (DevOps-mérnököknek) erős kommunikációs csatornával kell rendelkezniük. Ezt napi stand-up értekezletekkel vagy egy hivatalos online csevegési szolgáltatással tehetik meg. Mindkét megközelítés segít integrálni a fejlesztési erőfeszítéseket egy MLOps-keretrendszerben.
Adat-előkészítési szempontok
Az Azure Machine Tanulás használatának legegyszerűbb megoldása az adatok tárolása egy támogatott adattárolási megoldásban. Az olyan eszközök, mint az Azure Data Factory, hatékonyak arra, hogy az adatok ezeken a helyeken és helyekről ütemezetten legyenek beszúrva.
Fontos, hogy az ügyfelek gyakran rögzítsenek további újratanítási adatokat a modelljeik naprakészen tartása érdekében. Ha még nem rendelkezik adatfolyamkal, a létrehozás a teljes megoldás fontos része lesz. Ha olyan megoldást használ, mint az Azure Machine Tanulás adatkészletei, hasznos lehet az adatok verziószámozásához, hogy segítsen a modellek nyomon követhetőségében.
Modellbetanítási és értékelési szempontok
Egy olyan ügyfél számára, aki éppen most kezdi meg a gépi tanulási folyamatot, hogy megpróbáljon implementálni egy teljes MLOps-folyamatot. Szükség esetén az Azure Machine Tanulás segítségével nyomon követhetik a kísérletfuttatásokat, és betanítási célként használhatják az Azure Machine Tanulás compute-t. Ezek a lehetőségek alacsonyabb belépési akadályt eredményezhetnek az Azure-szolgáltatások integrálásának megkezdéséhez.
A jegyzetfüzet-kísérletről az megismételhető szkriptekre való áttérés sok adatelemző számára durva átmenet. Minél hamarabb ráveheti őket a betanítási kód Python-szkriptekben való megírására, annál könnyebb lesz számukra a betanítási kód verziószámozása és az újratanítás engedélyezése.
Nem ez az egyetlen lehetséges módszer. A Databricks támogatja a jegyzetfüzetek feladatként való ütemezését. A jelenlegi ügyfélélmény alapján azonban ezt a megközelítést a tesztelési korlátozások miatt nehéz teljes DevOps-gyakorlatokkal alkalmazni.
Azt is fontos megérteni, hogy milyen metrikákat használnak a modell sikeresnek ítéléséhez. A pontosság önmagában gyakran nem elég jó ahhoz, hogy meghatározza az egyik modell általános teljesítményét a másikhoz képest.
Számítási szempontok
- Az ügyfeleknek érdemes megfontolniuk a tárolók használatát a számítási környezetek szabványosításához. Szinte az összes Azure Machine Tanulás számítási cél a Docker használatával való támogatás. A függőségek tárolóval való kezelése jelentősen csökkentheti a súrlódást, különösen akkor, ha a csapat számos számítási célt használ.
Modellszolgáltatás szempontjai
- Az Azure Machine Tanulás SDK lehetővé teszi, hogy egy regisztrált modellből közvetlenül az Azure Kubernetes Service-be telepítsen, és korlátozza a biztonsági/metrikák használatát. Megpróbálhat egyszerűbb megoldást találni az ügyfelek számára a modell tesztelésére, de az éles számítási feladatokhoz a legjobb, ha robusztusabb üzembe helyezést fejleszt az AKS-ben.
Következő lépések
- További információ az MLOpsról
- MLOps az Azure-ban
- Azure Monitor-vizualizációk
- Gépi Tanulás életciklusa
- Azure DevOps Machine Tanulás bővítmény
- Azure Machine Learning CLI
- Azure Machine Learning-eseményeken alapuló alkalmazások, folyamatok vagy CI/CD-munkafolyamatok aktiválása
- Modell betanításának és üzembe helyezésének beállítása az Azure DevOps használatával
Kapcsolódó erőforrások
- MLOps-lejárati modell
- MLOps vezénylálása az Azure Databricksen a Databricks Notebook használatával
- MLOps Python-modellekhez az Azure Machine Tanulás használatával
- Adatelemzés és gépi tanulás az Azure Databricks használatával
- Citizen AI a Power Platformmal
- Mi- és gépi tanulási számítástechnika üzembe helyezése a helyszínen és a peremhálózaton