A big data típusú architektúrák kialakításuknak köszönhetően képesek kezelni az olyan adatok bevitelét, feldolgozását és elemzését, amelyek túl nagyok vagy túl összetettek a hagyományos adatbázisrendszerek számára.

A big data-megoldások általában az alábbi számításifeladat-típusok legalább egyikét tartalmazzák:
- inaktív big data típusú adatforrások kötegelt feldolgozása,
- mozgásban lévő, big data típusú adatok valós idejű feldolgozása,
- big data típusú adatok interaktív feltárása,
- prediktív elemzés és gépi tanulás.
A legtöbb big data típusú architektúra tartalmazza az alábbi összetevők egy részét vagy mindegyikét:
Adatforrások: Minden big data-megoldás egy vagy több adatforrással kezdődik. Ide sorolhatóak például a kövekezők:
- Alkalmazások adattárai (pl. relációs adatbázisok).
- Az alkalmazások által létrehozott statikus fájlok (pl. webkiszolgálók naplófájljai).
- Valós idejű adatforrások (pl. IoT-eszközök).
Adattároló: A kötegelt feldolgozási műveletekhez használatos adatokat általában egy elosztott fájltároló tartalmazza, amely számos formátumú és nagy mennyiségű nagy méretű adatot képes tárolni. Az ilyen tárakat gyakran data lake-nek is nevezik. Az ilyen tárolók többek között az Azure Data Lake Store vagy az Azure Storage blobtárolóival valósíthatók meg.
Kötegelt feldolgozás: Mivel az adatkészletek rendkívül nagy méretűek, a big data-megoldásoknak gyakran hosszan futó kötegelt feladatok használatával kell feldolgozniuk az adatfájlokat az adatok szűréséhez, összesítéséhez és az elemzésre való egyéb módon történő előkészítéséhez. Ezek a feladatok általában magukban foglalják az adatforrások beolvasását, feldolgozását, valamint a kimenet új fájlokba történő írását. A lehetőségek többek között az alábbiak: U-SQL-feladatok futtatása az Azure Data Lake Analyticsben; Hive-, Pig- vagy egyéni Map/Reduce-feladatok használata egy HDInsight Hadoop-fürtben; illetve Java-, Scala- vagy Python-programok használata egy HDInsight Spark-fürtben.
Valós idejű üzenetbetöltés: Ha a megoldás tartalmaz valós idejű forrásokat, az architektúrának lehetővé kell tennie a valós idejű üzenetek rögzítését és tárolását a streamfeldolgozáshoz. Ez lehet egy egyszerű adattár, ahol a bejövő üzenetek egy mappába kerülnek feldolgozás céljából. Számos megoldás azonban egy üzenetbetöltő tárat is igényel, amely pufferként működik az üzenetek számára, és támogatja a kibővített feldolgozást, a megbízható kézbesítést, valamint más üzenetsor-kezelési szemantikákat. A lehetőségek többek között a következők: Azure Event Hubs, Azure IoT Hubs és a Kafka.
Streamfeldolgozás: A valós idejű üzenetek rögzítése után a megoldásnak fel kell dolgoznia, azaz szűrnie, összesítenie és egyéb módon elő kell készítenie az adatokat az elemzéshez. A rendszer ezután egy kimeneti fogadóba írja a feldolgozott streamadatokat. Az Azure Stream Analytics egy felügyelt streamfeldolgozási szolgáltatást biztosít, amely a korlátlan streameken működő, folyamatosan futó SQL-lekérdezéseken alapul. A HDInsight-fürtökben nyílt forráskód Apache streamelési technológiákat is használhat, például a Spark Streaminget.
Analitikai adattár: Számos big data-megoldás előkészíti az adatokat az elemzésre, majd strukturált formátumban rendelkezésre bocsátja a feldolgozott adatokat, hogy lekérdezhetők legyenek elemzőeszközökkel. A lekérdezések kiszolgálásáért felelős analitikai adattár lehet egy Kimball-stílusú relációs adattárház, ahogy ez a legtöbb hagyományos üzletiintelligencia- (BI-) megoldásban látható. Alternatív megoldásként az adatok egy alacsony késésű NoSQL-technológián (pl. HBase) keresztül is megjeleníthetők, illetve egy interaktív Hive-adatbázisban, amely az elosztott adattárban lévő adatfájlok metaadatainak absztrakcióját tartalmazza. Az Azure Synapse Analytics felügyelt szolgáltatást biztosít a nagy méretű felhőalapú adattárházakhoz. A HDInsight támogatja az interaktív Hive, HBase és Spark SQL használatát, amelyekkel szintén előkészíthetők az adatok elemzésre.
Elemzés és jelentéskészítés: A legtöbb big data-megoldás célja az, hogy elemzéssel és jelentéskészítéssel betekintést nyújtson az adatokba. Ahhoz, hogy a felhasználók képesek legyenek elemezni az adatokat, az architektúra tartalmazhat egy adatmodellező réteget, mint például egy többdimenziós OLAP-kockát vagy egy táblázatos adatmodellt az Azure Analysis Servicesben. Emellett a Microsoft Power BI-ban vagy Microsoft Excelben elérhető modellezési és vizualizációs technológiákkal önkiszolgáló üzletiintelligencia-megoldásokat is támogathatnak. Az elemzés és jelentéskészítés az adatszakértők vagy adatelemzők általi végzett interaktív adatfeltárással is végrehajtható. Az ilyen forgatókönyvekhez számos Azure-szolgáltatás támogat analitikus notebookokat (pl. Jupyter), így a felhasználók felhasználják a Python vagy az R terén már megszerzett tudásukat. Nagy méretű adatfeltárás esetén használhatja a Microsoft R Servert önállóan vagy a Sparkkal együtt.
Vezénylés: A legtöbb Big Data-megoldás munkafolyamatokba foglalt, ismétlődő adatfeldolgozási műveletekből áll, amelyek átalakítják a forrásadatokat, adatokat mozgatnak több forrás és fogadó között, betöltik a feldolgozott adatokat egy analitikus adattárba, vagy továbbítják az eredményeket egyenesen egy jelentésbe vagy irányítópultba. A munkafolyamatok automatizálhatók egy vezénylési technológia (pl. Azure Data Factory vagy Apache Oozie és Sqoop) használatával.
Az Azure számos olyan szolgáltatást tartalmaz, amelyek felhasználhatók a big data típusú architektúrákban. Ezek nagyjából két kategóriába sorolhatók:
- Felügyelt szolgáltatások, például az Azure Data Lake Store, az Azure Data Lake Analytics, az Azure Synapse Analytics, az Azure Stream Analytics, az Azure Event Hubs, az Azure IoT Hub és az Azure Data Factory.
- Az Apache Hadoop platformon alapuló nyílt forráskódú technológiák, például a HDFS, a HBase, a Hive, a Spark, az Oozie, a Sqoop és a Kafka. Az Azure-ban ezek a technológiák az Azure HDInsight szolgáltatásban érhetők el.
Ezek a lehetőségek nem zárják ki egymást, és számos megoldás használ nyílt forráskódú technológiákat az Azure-szolgáltatásokkal együtt.
Mikor érdemes ezt az architektúrát használni?
Akkor érdemes megfontolnia ezt az architektúrastílust, ha az alábbiakra van szüksége:
- a hagyományos adatbázisok számára túl nagy mennyiségű adat tárolása és feldolgozása,
- strukturálatlan adatok átalakítása elemzés és jelentéskészítés céljából,
- kötetlen adatstreamek rögzítése, feldolgozása és elemzése valós időben vagy kis késéssel,
- Használja az Azure Machine Tanulás vagy az Azure Cognitive Services szolgáltatást.
Előnyök
- Technológiai lehetőségek. Az Azure felügyelt szolgáltatásai és az Apache-technológiák szabadon kombinálhatók a HDInsight-fürtökben, így kihasználhatja a meglévő készségeit vagy technológiai befektetéseit.
- Teljesítmény a párhuzamosságon keresztül. A big data-megoldások kihasználják a párhuzamosságot, így nagy adatmennyiségekhez skálázható, nagy teljesítményű megoldásokat használhat.
- Rugalmas skálázás. A big data architektúra minden összetevője támogatja a kibővíthető kiépítést, így a számítási feladatokhoz méretéhez igazíthatja a megoldást, és csak a felhasznált erőforrások után kell fizetnie.
- Együttműködési lehetőség a meglévő megoldásokkal. A big data architektúra összetevői az IoT-feldolgozáshoz és a nagyvállalati BI-megoldásokhoz is használhatók, így olyan integrált megoldást hozhat létre, amely az összes adatszámítási feladatot felöleli.
Problémák
- Összetettség. A big data-megoldások rendkívül összetettek lehetnek, és számos összetevővel rendelkezhetnek a több adatforrásból származó adatok betöltéséhez. A big data-folyamatok felépítése, tesztelése és hibaelhárítása nagy kihívást jelenthet. Továbbá a többféle rendszer rengeteg olyan konfigurációs beállítást tartalmazhat, amelyek használatára szükség van az optimális teljesítmény érdekében.
- Készségek. Számos big data-technológia rendkívül specializált, és olyan keretrendszereket és nyelveket használ, amelyek nem jellemzőek az általánosabb alkalmazás-architektúrákra. Másrészről a big data-technológiák folyamatosan fejlesztenek ki a széles körben használt nyelvekre épülő új API-kat. Az Azure Data Lake Analyticsben használt U-SQL nyelv például a Transact-SQL és a C# nyelv kombinációján alapul. Ehhez hasonlóan a Hive, HBase és Spark esetében is elérhetők SQL-alapú API-k.
- Technológiai fejlettség. A big data területén használt számos technológia folyamatosan fejlődik. Az alapvető Hadoop-technológiák (például a Hive és a Pig) már stabilizálódtak, azonban a Sparkhoz hasonló új technológiák széles körű változásokat és fejlesztéseket vezetnek be minden egyes új kiadással. A felügyelt szolgáltatások (pl. Azure Data Lake Analytics és Azure Data Factory) viszonylag fiatalok a többi Azure-szolgáltatáshoz képest, és valószínűleg fejlődni fognak az idő előrehaladtával.
- Biztonság. A big data-megoldások általában az összes statikus adatot egy központosított data lake-ben tárolják. Az adatokhoz való hozzáférés biztosítása kihívást jelenthet, főleg, ha az adatokat több alkalmazásnak és platformnak is be kell töltenie és fel kell dolgoznia.
Ajánlott eljárások
A párhuzamosság kihasználása. A legtöbb big data típusú feldolgozási technológia több feldolgozóegység között osztja el a számítási feladatokat. Ehhez arra van szükség, hogy a statikus adatfájlok létrehozása és tárolása felosztható formátumban történjen. Az elosztott fájlrendszerek (pl. HDFS) optimalizálhatják az olvasási és írási teljesítményt, a tényleges feldolgozást pedig több fürtcsomópont hajthatja végre párhuzamosan. Ez csökkenti a feladatok elvégzéséhez szükséges időt.
Adatok particionálása. A kötegelt feldolgozás általában ismétlődő ütemezés szerint történik – például hetente vagy havonta. Az adatfájlokat és adatstruktúrákat (például táblákat) particionálhatja a feldolgozási ütemezéssel megegyező időszakok alapján. Ez leegyszerűsíti az adatbetöltést és a feladatok ütemezését, és megkönnyíti a hibaelhárítást. A Hive-, U-SQL- vagy SQL-lekérdezésekben használt táblák particionálása emellett jelentősen javíthatja a lekérdezések teljesítményét.
A séma a beolvasáskor szemantika alkalmazása. A data lake használatával több formátumban is kombinálhatja a fájlok tárolását, legyen szó strukturált, félig strukturált vagy strukturálatlan fájlokról. A séma a beolvasáskor szemantika nem az adatok tárolásakor, hanem a feldolgozás közben rendel hozzájuk egy sémát. Ez biztosítja a megoldás rugalmasságát, és megakadályozza az adatbetöltés során az adatok érvényesítése és a típus ellenőrzése miatt kialakuló szűk keresztmetszeteket.
Adatok feldolgozása a helyszínen. A hagyományos üzletiintelligencia-megoldások gyakran egy kinyerési, átalakítási és betöltési (ETL) folyamat használatával helyezik át az adatokat egy adattárházba. Nagy mennyiségű adat, illetve a formátumok nagyobb változatossága esetén a Big Data-megoldások általában az ETL-folyamat különféle változatait használják, mint például átalakítás, kinyerés és betöltés (TEL). Ezzel a módszerrel a rendszer az elosztott adattáron belül dolgozza fel az adatokat, átalakítja őket a szükséges struktúrára, majd áthelyezi az átalakított adatokat egy analitikai adattárba.
A kihasználtsággal és idővel járó költségek kiegyensúlyozása. A kötegelt feldolgozási feladatok esetében fontos figyelembe venni két tényezőt: a számítási csomópontok egységenkénti költségét, valamint a feladatok elvégzésére való csomóponthasználat percenkénti költségét. Egy kötegelt feladat például igénybe vehet nyolc órát és négy fürtcsomópontot. Előfordulhat azonban, hogy a feladat csak az első két órában használja mind a négy csomópontot, azután pedig csak kettőre van szükség. Ebben az esetben az egész feladat két csomóponton történő futtatása növelné a feladat teljes időtartamát, de nem duplázná meg, tehát a teljes költség kevesebb lenne. Egyes üzleti forgatókönyvekben a hosszabb feldolgozási idő előnyösebb lehet a kihasználatlan fürterőforrások használatának magasabb költségeihez.
Fürterőforrások különválasztása. HDInsight-fürtök üzembe helyezése során jellemzően jobb teljesítmény érhető el, ha különálló fürterőforrásokat épít ki az egyes számításifeladat-típusok számára. Például a Spark-fürtök tartalmazzák a Hive-ot, de ha a Hive-val és a Sparkkal is széles körű feldolgozási feladatokat kíván végezni, érdemes különálló dedikált Spark- és Hadoop-fürtöket üzembe helyeznie. Hasonlóképpen, ha HBase-t és Stormot használt a kis késésű streamfeldolgozáshoz, és Hive-ot a kötegelt feldolgozáshoz, érdemes különálló fürtöket létrehoznia a Storm, HBase és Hadoop számára.
Az adatbetöltés vezénylése. Bizonyos esetekben a meglévő üzleti alkalmazások adatfájlokat írhatnak közvetlenül az Azure Storage blobtárolóiba a kötegelt feldolgozáshoz, ahol a HDInsight vagy az Azure Data Lake Analytics felhasználhatja őket. Gyakran azonban vezényelnie kell a helyszíni vagy külső adatforrásokból származó adatok data lake tárolóba történő betöltését. Egy vezénylési munkafolyamat vagy folyamat, például az Azure Data Factory vagy Oozie által támogatott folyamatok használatával ezt kiszámítható és központilag felügyelhető módon teheti meg.
A bizalmas adatok időszerű törlése. Az adatbetöltési munkafolyamatnak a folyamat elején törölnie kell a bizalmas adatokat, hogy a data lake véletlenül se tárolja őket.
IoT-architektúra
A dolgok internete (IoT) a big data-megoldások speciális részhalmaza. Az alábbi ábrán egy Iot-megoldás lehetséges logikai architektúrája látható. Az ábra az architektúra eseménystreamelési összetevőit hangsúlyozza ki.
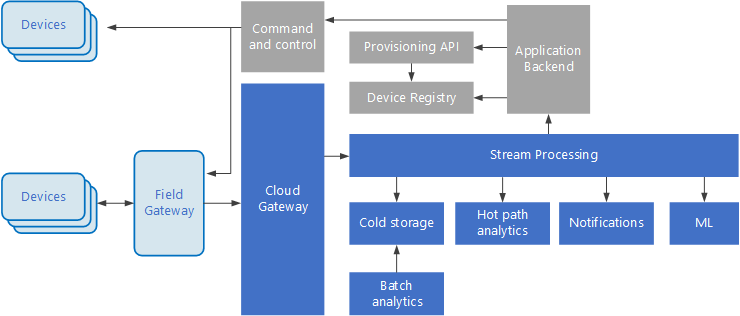
A felhőátjáró a felhő határán olvassa be az eszközeseményeket egy megbízható, alacsony késésű üzenetkezelési rendszert használva.
Az eszközök közvetlenül a felhőátjárónak vagy egy helyi átjárón keresztül küldhetik el az eseményeket. A helyi átjáró egy specializált, általában az eszközökkel egy helyen található eszköz vagy szoftver, amely fogadja az eseményeket, majd továbbítja azokat a felhőátjárónak. A helyi átjáró a nyers eszközesemények előfeldolgozására is képes, olyan feladatok végrehajtásával, mint a szűrés, az összesítés vagy a protokollátalakítás.
A beolvasást követően az események egy vagy több streamfeldolgozón haladnak át, amelyek továbbíthatják az adatokat (például egy tárolóba), vagy elemzést és más feldolgozási műveleteket végezhetnek.
Az alábbiakban a feldolgozás néhány gyakori típusát ismertetjük. (A felsorolás semmiképpen sem teljes.)
Eseményadatok írása offline tárolóba archiválás vagy kötegelt elemzés céljából.
Működő elérési út elemzése, vagyis az eseménystream (közel) valós idejű elemzése a rendellenességek észlelése, adott időtartamokra jellemző minták felismerése vagy riasztások aktiválása céljából, ha egy adott helyzet áll elő a streamben.
Az eszközöktől származó nem telemetriaüzenetek különleges típusainak, például az értesítéseknek és a riasztásoknak a kezelése.
Gépi tanulás.
A szürke dobozok az IoT-rendszer azon összetevőit jelölik, amelyek nem kapcsolódnak közvetlenül az eseménystreameléshez, a teljesség igénye miatt azonban az ábra részét képezik.
Az eszközjegyzék az üzembe helyezett eszközök adatbázisa, amely az eszközök azonosítóját és rendszerint az eszközök metaadatait, például a helyüket tartalmazza.
Az üzembe helyezési API egy általános külső felület az új eszközök üzembe helyezéséhez és regisztrálásához.
Egyes IoT-megoldások lehetővé teszik parancs- és vezérlő üzenetek küldését az eszközöknek.
Ez a szakasz az IoT nagyon általános áttekintését tartalmazza, amely mellett még nagyon sok apró részletet és kihívást jelentő tényezőt kell figyelembe venni. Részletesebb referenciaarchitektúrát és ismertetőt a Microsoft Azure IoT referenciaarchitektúráját tartalmazó dokumentumban talál (letölthető PDF-fájl).