A mesterséges intelligencia lehetőséget kínál a kiskereskedelem átalakítására, ahogy azt ma ismerjük. Ésszerű azt hinni, hogy a kiskereskedők egy mi által támogatott ügyfélélmény-architektúrát fejlesztenek. Egyes elvárások szerint az AI-vel bővített platform a hiper-személyre szabás miatt bevételi kiesést fog biztosítani. A digitális kereskedelem továbbra is fokozza az ügyfelek elvárásait, preferenciáit és viselkedését. Az olyan igények, mint a valós idejű előjegyzés, a releváns javaslatok és a hiper-személyre szabás egy kattintással gyors és kényelmes. Az alkalmazásokban a természetes beszéd, a látás és így tovább révén biztosítjuk az intelligenciát. Ez az intelligencia olyan fejlesztéseket tesz lehetővé a kiskereskedelemben, amelyek növelik az értéket, miközben megzavarják az ügyfelek vásárlási módját.
Ez a dokumentum a vizuális keresés AI-koncepciójára összpontosít, és néhány fontos szempontot kínál annak implementálásával kapcsolatban. Példa a munkafolyamatra, és a szakaszokat a releváns Azure-technológiákhoz rendeli. A koncepció azon alapul, hogy az ügyfelek képesek kihasználni a mobileszközükkel készített vagy az interneten található képet. A releváns és hasonló elemeket a tapasztalat szándékától függően keresnék. Így a vizualizációs keresés javítja a szövegbevitel sebességét egy több metaadat-ponttal rendelkező képre, hogy gyorsan felszínre hozhassa az összes elérhető elemet.
Vizuális keresőmotorok
A vizuális keresőmotorok a képeket használva kérik le az adatokat bemenetként, és gyakran – de nem kizárólag – kimenetként is.
A motorok egyre gyakoribbak a kiskereskedelmi iparban, és nagyon jó okokból:
- Egy 2017-ben közzétett Emarketer-jelentés szerint az internetezők körülbelül 75%-a keres képeket vagy videókat egy termékről.
- A felhasználók 74%-a a Slyce (vizuális kereső vállalat) 2015-ös jelentése szerint a szöveges kereséseket sem találja hatékonynak.
Ezért a képfelismerő piac 2019-ig több mint 25 milliárd dollárt ér a Markets > Markets kutatása szerint.
A technológia mára jelentős e-kereskedelmi márkákkal bővült, amelyek szintén jelentős mértékben hozzájárultak a fejlesztéshez. A legfontosabb korai örökbefogadók valószínűleg:
- Az eBay image search és a "Find It on eBay" eszközökkel az alkalmazásukban (ez jelenleg csak mobil felület).
- Pinterest a Lens vizualizációfelderítési eszközével.
- Microsoft a Bing Visual Search szolgáltatással.
Bevezetés és alkalmazkodás
Szerencsére nincs szükség nagy mennyiségű számítási teljesítményre a vizuális keresésből való profitszerzéshez. A képkatalógussal rendelkező vállalatok kihasználhatják a Microsoft Azure-szolgáltatásaiba beépített AI-szakértelmét.
A Bing Visual Search API lehetővé teszi, hogy környezeti információkat nyerjen ki a képekből, azonosítva például a lakberendezési tárgyakat, a divatot, a különféle termékeket stb.
Emellett vizuálisan hasonló képeket is visszaad saját katalógusából, relatív vásárlási forrásokkal rendelkező termékeket, kapcsolódó kereséseket. Bár érdekes, ez korlátozottan használható, ha a vállalat nem egyike ezeknek a forrásoknak.
A Bing a következőket is biztosítja:
- Címkék, amelyek lehetővé teszik a képen található objektumok vagy fogalmak felfedezését.
- Határolókeretek a kép szempontjából érdekes régiókhoz (például ruházati vagy bútorelemekhez).
Ezeket az információkat a cég termékkatalógusában található keresési terület (és idő) jelentős csökkentéséhez használhatja, így azokat olyan objektumokra korlátozhatja, mint a régióban és az érdeklődési körökben lévők.
Saját implementálása
A vizualizációs keresés megvalósításakor néhány fontos összetevőt érdemes figyelembe venni:
- Képek betöltése és szűrése
- Tárolási és lekérési technikák
- Featurization, kódolás vagy "kivonatolás"
- Hasonlósági mértékek vagy távolságok és rangsorolás
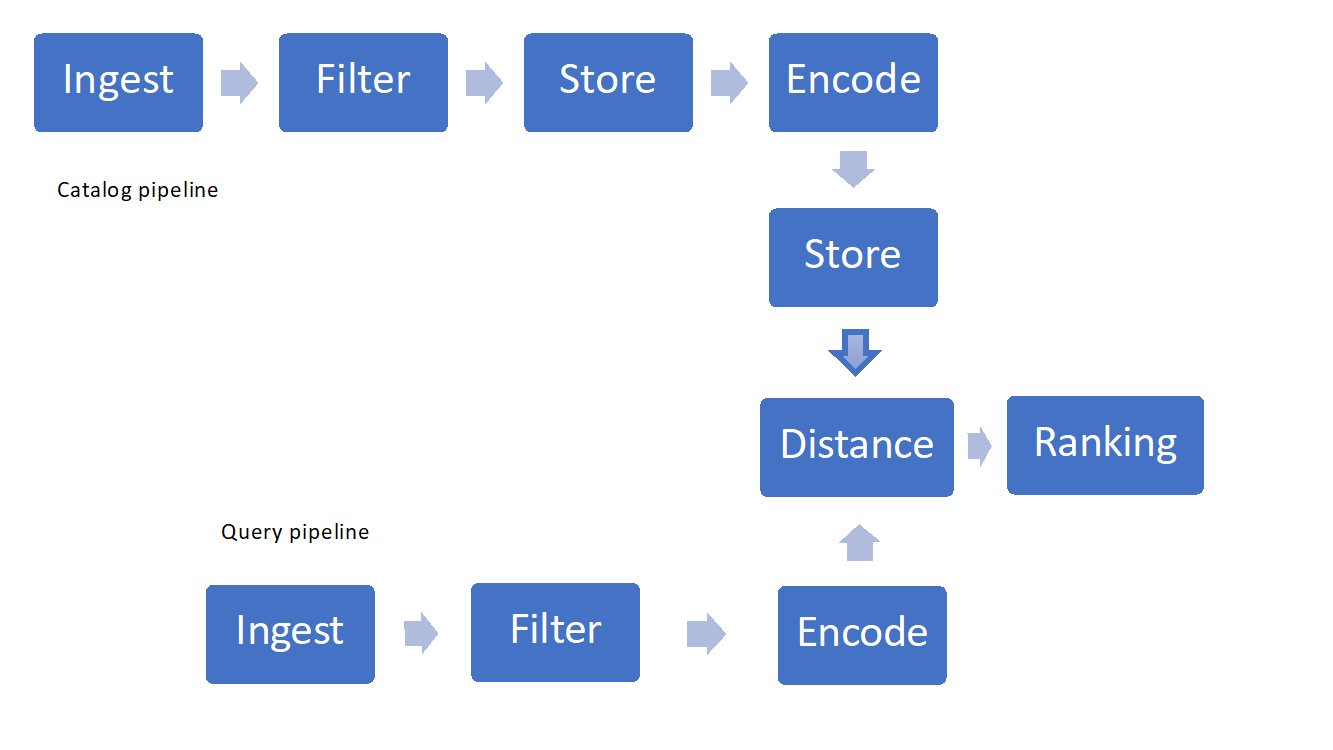
1. ábra: Példa a Visual Search-folyamatra
A képek beszerzése
Ha nem rendelkezik képkatalógussal, előfordulhat, hogy be kell tanítania az algoritmusokat a nyíltan elérhető adathalmazokra, például a divat MNIST-jára, a mély divatra stb. Számos termékkategóriát tartalmaznak, és gyakran használják a kép kategorizálására és a keresési algoritmusok összehasonlítására.

2. ábra: Példa a DeepFashion adatkészletből
A képek szűrése
A legtöbb teljesítményteszt-adatkészletet, például a korábban említetteket, már előre feldolgozták.
Ha saját teljesítménytesztet készít, legalább azt szeretné, hogy a képek mérete megegyezzen, többnyire a modell által betanított bemenet határozza meg.
Sok esetben a legjobb, ha normalizálja a képek fényerejét is. A keresés részletességi szintjétől függően a színek redundáns információk is lehetnek, ezért a fekete-fehérre való csökkentés segít a feldolgozási időkben.
Végül, de nem utolsósorban a képadatkészletet el kell osztani az általa képviselt különböző osztályok között.
Képadatbázis
Az adatréteg az architektúra különösen kényes összetevője. A következőt tartalmazza:
- Képek
- A rendszerképek metaadatai (méret, címkék, termékváltozatok, leírás)
- A gépi tanulási modell által létrehozott adatok (például képenként egy 4096 elemű numerikus vektor)
Amikor különböző forrásokból kér le képeket, vagy több gépi tanulási modellt használ az optimális teljesítmény érdekében, az adatok struktúrája megváltozik. Ezért fontos olyan technológiát vagy kombinációt választani, amely képes kezelni a félig strukturált adatokat, és nincs rögzített séma.
Szükség lehet minimális számú hasznos adatpontra (például képazonosítóra vagy kulcsra, termékváltozatra, leírásra vagy címkemezőre).
Az Azure Cosmos DB biztosítja a szükséges rugalmasságot és számos különböző hozzáférési mechanizmust a rá épülő alkalmazásokhoz (ami segít a katalóguskeresésben). Azonban óvatosnak kell lennie, hogy a legjobb árat / teljesítményt vezesse. Az Azure Cosmos DB lehetővé teszi a dokumentummellékletek tárolását, de a fiókonkénti teljes korlát költséges ajánlat lehet. Gyakori eljárás, hogy a tényleges képfájlokat blobokban tárolja, és beszúr egy hivatkozást az adatbázisba. Az Azure Cosmos DB esetében ez azt jelenti, hogy létrehoz egy dokumentumot, amely tartalmazza a képhez társított katalógustulajdonságokat (például termékváltozatot, címkét stb.), valamint egy mellékletet, amely tartalmazza a képfájl URL-címét (például az Azure Blob Storage-on, a OneDrive-on stb.).

3. ábra: Azure Cosmos DB hierarchikus erőforrásmodell
Ha azt tervezi, hogy kihasználja az Azure Cosmos DB globális terjesztését, vegye figyelembe, hogy a dokumentumokat és mellékleteket replikálja, a csatolt fájlokat azonban nem. Ezekhez érdemes megfontolnia egy tartalomterjesztési hálózatot.
Más alkalmazható technológiák az Azure SQL Database (ha a rögzített séma elfogadható) és blobok, vagy akár az Azure Tables és blobok kombinációja az olcsó és gyors tároláshoz és lekéréshez.
Funkciókinyerés > kódolás
A kódolási folyamat hasznos funkciókat nyer ki az adatbázisban lévő képekből, és mindegyiket leképezi egy ritka "funkció" vektorra (egy sok nullával rendelkező vektorra), amely több ezer összetevővel rendelkezhet. Ez a vektor a képet jellemző jellemzők (például élek és alakzatok) numerikus ábrázolása. Hasonlít egy kódhoz.
A funkciókinyerési technikák általában átviteli tanulási mechanizmusokat használnak. Ez akkor fordul elő, ha kiválaszt egy előre betanított neurális hálózatot, futtatja rajta az egyes képeket, és tárolja a képadatbázisban létrehozott funkcióvektort. Ily módon "át kell vinnie" a tanulást a hálózat betanítását képzőtől. A Microsoft számos előre betanított hálózatot fejlesztett ki és tett közzé, amelyeket széles körben használtak a képfelismerési feladatokhoz, például a ResNet50-hez.
A neurális hálózattól függően a funkcióvektor többé-kevésbé hosszú és ritka lesz, ezért a memória- és tárolási követelmények eltérőek lesznek.
Azt is tapasztalhatja, hogy a különböző hálózatok különböző kategóriákra vonatkoznak, ezért a vizuális keresés implementálása valójában különböző méretű funkcióvektorokat hozhat létre.
Az előre betanított neurális hálózatok viszonylag könnyen használhatók, de nem feltétlenül olyan hatékonyak, mint a képkatalógusban betanított egyéni modellek. Ezeket az előre betanított hálózatokat általában a teljesítménymutató-adathalmazok besorolására tervezték, nem pedig a képek adott gyűjteményére való keresésre.
Érdemes lehet módosítani és újratanítani őket, hogy egy kategória-előrejelzést és egy sűrű (azaz kisebb, nem ritka) vektort eredményeznek, amely nagyon hasznos lesz a keresési terület korlátozásához, a memória- és tárolási követelmények csökkentéséhez. Bináris vektorok használhatók, és gyakran nevezik " szemantikai kivonat" – a kifejezés származik a dokumentum kódolási és lekérési technikák. A bináris ábrázolás leegyszerűsíti a további számításokat.
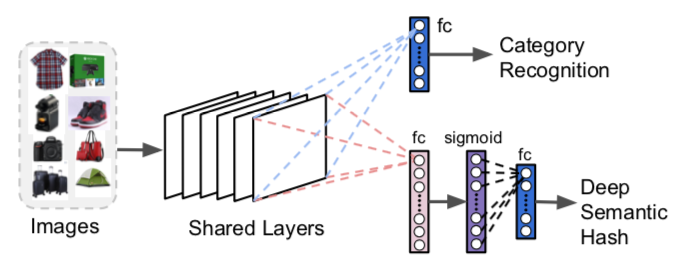
4. ábra: A ResNet for Visual Search módosítása – F. Yang et al., 2017
Akár előre betanított modelleket választ, akár saját fejlesztést szeretne, továbbra is el kell döntenie, hogy hol futtatja a modell featurizálását és/vagy betanítását.
Az Azure számos lehetőséget kínál: virtuális gépek, Azure Batch, Batch AI, Databricks-fürtök. A GPU-k használata azonban minden esetben a legjobb árat/teljesítményt adja.
A Microsoft nemrég bejelentette, hogy a GPU költségeinek töredékéért (Brainwave projekt) rendelkezésre állnak az FPGA-k a gyors számításokhoz. Az íráskor azonban ez az ajánlat bizonyos hálózati architektúrákra korlátozódik, ezért a teljesítményüket alaposan ki kell értékelnie.
Hasonlósági mérték vagy távolság
Ha a képek a jellemzővektortérben vannak ábrázolva, a hasonlóságok megállapítása az ilyen tér pontjai közötti távolság meghatározásának kérdése lesz. A távolság meghatározása után kiszámíthatja a hasonló rendszerképek fürtöit, és/vagy meghatározhat hasonlósági mátrixokat. A kiválasztott távolságmetrikától függően az eredmények eltérőek lehetnek. A leggyakoribb euklideszi távolságmérő például könnyen érthető: a távolság nagyságát rögzíti. A számítás szempontjából azonban nem hatékony.
A koszinusz távolságát gyakran használják a vektor tájolásának rögzítésére, nem pedig annak nagyságára.
Az olyan alternatívák, mint a bináris reprezentációk távolságának mérése, némi pontosságot képviselnek a hatékonyság és a sebesség szempontjából.
A vektorméret és a távolságmérő kombinációja határozza meg, hogy milyen számítási igényű és memóriaigényes lesz a keresés.
Keresés és rangsorolás
A hasonlóság meghatározása után ki kell dolgoznunk egy hatékony módszert, amely lekéri a legközelebbi N elemeket a bemenetként átadotthoz, majd visszaadjuk az azonosítók listáját. Ezt "kép rangsorolásnak" is nevezik. Nagy adathalmazok esetén az összes távolság kiszámításának ideje tiltott, ezért a legközelebbi szomszéd algoritmusokat használjuk. Ezekhez több nyílt forráskódú kódtár is létezik, így nem kell az alapoktól kódolja őket.
Végül a memória- és számítási követelmények határozzák meg a betanított modell üzembehelyezési technológiájának kiválasztását, valamint a magas rendelkezésre állást. A keresési terület általában particionálásra kerül, és a rangsorolási algoritmus több példánya párhuzamosan fog futni. A méretezhetőséget és a rendelkezésre állást lehetővé tevő egyik lehetőség az Azure Kubernetes-fürtök . Ebben az esetben ajánlott üzembe helyezni a rangsorolási modellt több tárolóban (a keresési terület partíciójának kezelése) és több csomóponton (a magas rendelkezésre állás érdekében).
Közreműködők
Ezt a cikket a Microsoft tartja karban. Eredetileg a következő közreműködők írták.
Fő szerzők:
- Giovanni Marchetti | Vezető, Azure Solution Architects
- Marija Zorotovich | Az ügyfélélmény vezetője, HLS > Feltörekvő technológia
Egyéb közreműködők:
- Scott Seely | Szoftvertervező
Következő lépések
A vizualizációs keresés implementálásának nem kell bonyolultnak lennie. Használhatja a Binget, vagy létrehozhatja sajátját az Azure-szolgáltatásokkal, miközben kihasználhatja a Microsoft AI-kutatásait és eszközeit.
Fejlesztés
- A testreszabott szolgáltatás létrehozásának megkezdéséhez tekintse meg a Bing Visual Search API áttekintését
- Az első kérés létrehozásához tekintse meg a következő rövid útmutatókat: C# | Java | Node.js Python |
- Tekintse át a Visual Search API referenciáját.
Háttér
- Mélytanulási kép szegmentációja: A Microsoft-tanulmány a képek háttértől való elválasztásának folyamatát ismerteti
- Vizuális keresés az Ebay-en: Cornell Egyetem kutatás
- Vizuális felfedezés a Pinterest Cornell Egyetem kutatásában
- Szemantikus Hashing University of Toronto kutatás