Indexeket hozhat létre a lekérdezések által gyakran hivatkozott adattárbeli mezőkről. Ez a minta javíthat a lekérdezési teljesítményen, mivel engedélyezi az alkalmazások részére, hogy gyorsabban azonosíthassanak egy adattárból lekérni kívánt adatot.
Kontextus és probléma
Számos adattároló egy entitásgyűjteménybe rendezi az adatokat az elsődleges kulcs használatával. Egy alkalmazás használhatja ezt a kulcsot az adatok megkeresésére és kinyerésére. Az ábra egy példát mutat be, amikor egy adattár ügyfél-információkat tárol. Az elsődleges kulcs az ügyfél azonosítója. Az ábra az elsődleges kulcs (az ügyfél-azonosító) által rendezett ügyfél-információt mutatja.
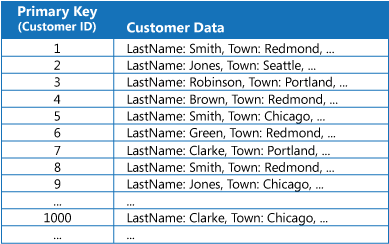
Míg az elsődleges kulcs értékes olyan lekérdezések esetén, amelyek a kulcs értéke alapján szereznek be adatokat, elképzelhető, hogy egy alkalmazás nem tudja használni az elsődleges kulcsot, ha más területről kell kinyernie az adatokat. Az ügyfélpéldában egy alkalmazás nem tudja használni az ügyfél-azonosító elsődleges kulcsot az ügyfelek kinyerésére, ha csak egy másik attribútum, például az ügyfél székhelyeként szolgáló város értékére történő hivatkozással kérdez le adatokat. Egy ilyen lekérdezés elvégzéséhez az alkalmazásnak valószínűleg minden ügyfélrekordot be kell gyűjtenie és meg kell vizsgálnia, ami elég lassú folyamat lehet.
Számos relációs adatbáziskezelő-rendszer támogatja a másodlagos indexeket. A másodlagos index egy elkülönülő adatszerkezet, amelyet egy vagy több nem elsődleges (másodlagos) kulcsmező rendszerez. Azt jelzi, hogy hol tárolódnak az egyes indexelt értékek adatai. A másodlagos indexek elemei általában a másodlagos kulcsok értékei szerint vannak rendezve, így lehetővé válik az adatok gyors keresése. Ezeket az indexeket általában automatikusan tartja karban az adatbázis-kezelő rendszer.
Annyi másodlagos indexet hozhat létre, amennyire csak szükség van az alkalmazás által végrehajtott különböző lekérdezése támogatásához. Például, ha egy relációs adatbázis ügyfelek táblájában az ügyfél-azonosító az elsődleges kulcs, érdemes hozzáadni egy másodlagos indexet a város mezőhöz, ha az alkalmazás gyakran keres az ügyfelekre a tartózkodási város alapján.
Bár a másodlagos indexek gyakoriak a relációs rendszerekben, a felhőalkalmazások által használt egyes NoSQL-adattárak nem nyújtanak egyenértékű funkciót.
Megoldás
Ha az adattároló nem támogatja a másodlagos indexeket, emulálhatja őket úgy is, ha manuálisan létrehozza saját indextábláit. Az indextáblák egy adott kulcs alapján rendezik az adatokat. Ezeket a stratégiákat az igényelt másodlagos indexek számától és az alkalmazás által végrehajtott lekérdezések jellegétől függően gyakran használják az indextáblák strukturálására.
Az első stratégia az adatok duplikálása minden egyes indextáblában, majd a rendezésük különféle kulcsok szerint (teljes denormalizáció). A következő ábra olyan indextáblákat mutat be, amelyek ugyanezeket az ügyfél-információkat rendezik város és vezetéknév szerint.
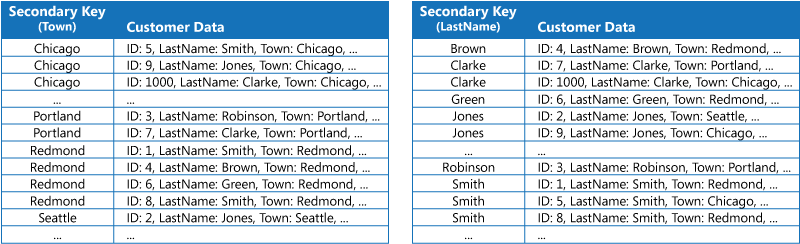
Ez a stratégia akkor megfelelő, ha az adatok viszonylag statikusak ahhoz képest, hogy hányszor vannak lekérdezve az adott kulcsok használatával. Ha az adatok dinamikusabbak, az egyes indextáblák feldolgozási többletterhelése túl nagy lesz ahhoz, hogy a módszert hatékonyan lehessen használni. Ha az adatok mennyisége túl nagy, a duplikált adatok tárolásához szükséges lemezterület mennyisége is jelentős.
A második stratégia szerint normalizált indextáblákat kell létrehozni, amelyeket különböző kulcsok rendeznek. Ezek a táblák az eredeti adatokra hivatkoznak az elsődleges kulcsot használatával, nem pedig duplikálják azt, ahogy az alábbi képen is látható. Az eredeti adat neve „fact table” (ténytábla).
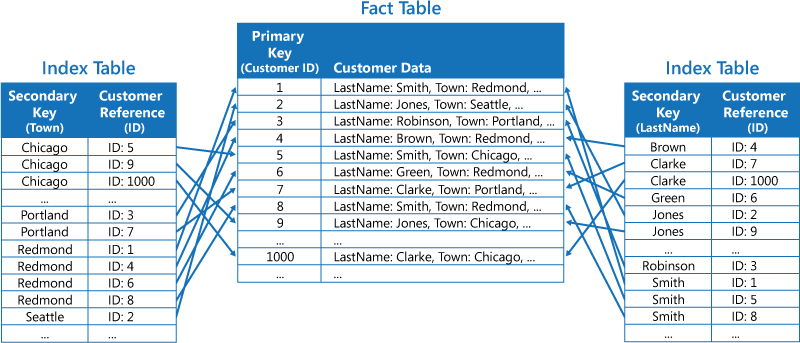
Ez a technika helyet takarít meg, és csökkenti a duplikált adatok fenntartása jelentette terhelést. Hátránya, hogy az alkalmazásnak egy másodlagos kulcs használatával két keresési műveletet kell végrehajtania az adatok kereséséhez. Meg kell találnia az adat elsődleges kulcsát az indextáblában, majd használnia az elsődleges kulcsot, hogy megtalálja az adatot a ténytáblában.
A harmadik stratégia részlegesen normalizált indextáblák létrehozása, amelyeket különböző, a gyakran kinyert mezőket duplikáló kulcsok rendszereznek. Hivatkozzon a ténytáblára a ritkábban elért mezők eléréséhez. Az alábbi ábra bemutatja, hogyan duplikálódnak a gyakran hozzáfért adatok minden indextáblában.
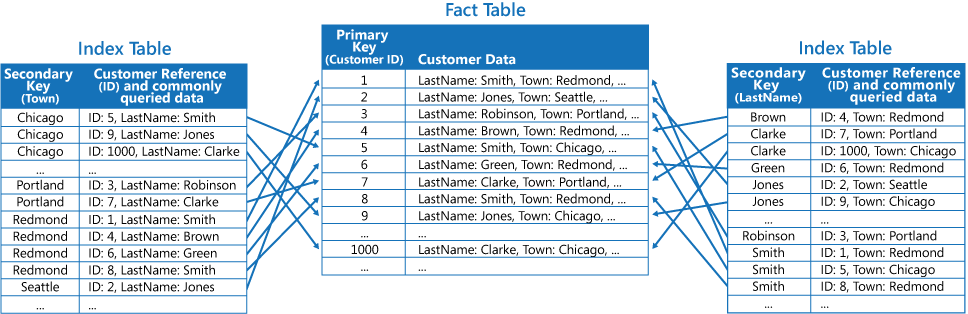
Ezzel a stratégiával kiegyensúlyozható az első két módszer. A gyakori lekérdezések adatai egy egyszerű kereséssel megtalálhatóak, ugyanakkor a helyhasználat és a karbantartási terhelés nem annyira jelentős, mintha a teljes adatkészletet duplikálná.
Ha egy alkalmazás gyakran lekérdezi az adatokat az értékek kombinációjának megadásával (például "Keresse meg a Redmondban élő és Smith vezetéknevű ügyfeleket"), az indextáblában szereplő elemek kulcsait a Town attribútum és a LastName attribútum összefűzésével implementálhatja. A következő ábra egy kompozit kulcsokon alapuló indextáblát mutat be. A kulcsok város szerint vannak rendezve, majd pedig vezetéknév szerint azon rekordok esetén, amelyek ugyanazzal az értékkel rendelkeznek a városra.

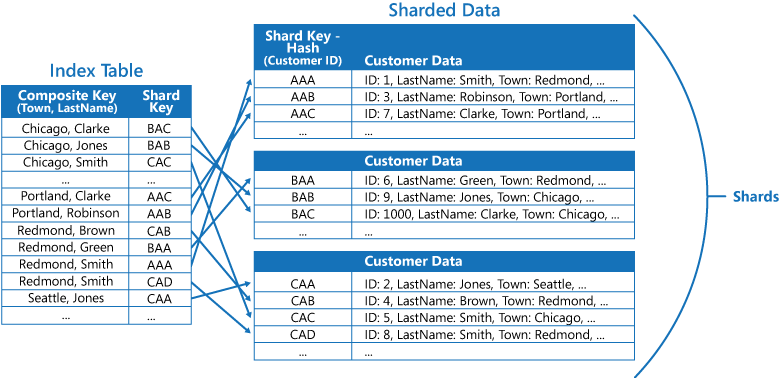
Az indextáblák felgyorsíthatják a lekérdezési műveleteket a horizontálisan skálázott adatok között, és különösen hasznosak, ha a szegmenskulcs kivonatolt. A következő ábra egy példát mutat be, ahol a szegmenskulcs az ügyfél-azonosító kivonata. Az indextábla a nem kivonatolt érték (város és vezetéknév) szerint rendszerezheti az adatokat, és a kivonatolt szegmenskulcsot biztosíthatja keresési adatként. Ez megelőzi, hogy az alkalmazás ismételten kiszámolja a kivonatolt kulcsokat (ami költséges művelet), ha csak egy tartományon belüli adatot kell kinyernie vagy ha a nem kivonatolt kulcs szerint kell az adatokat lekérnie. Például egy olyan lekérdezés, mint a "Minden ügyfél megkeresése, aki Redmondban él" gyorsan megoldható az indextábla egyező elemeinek megkeresésével, ahol az összes egybefüggő blokkban van tárolva. Ezután kövesse a hivatkozásokat az ügyféladatokra a szegmenskulcs használatával, amely az indextáblában tárolódik.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
A másodlagos indexek karbantartása által jelentett terhelés jelentős lehet. Elemeznie és értenie kell az alkalmazás által használt lekérdezéseket. Csak akkor hozzon létre indextáblákat, ha valószínűleg gyakran lesznek használatban. Ne hozzon létre spekulatív indextáblákat olyan lekérdezések támogatására, amelyeket az alkalmazás sosem vagy csak alkalmanként hajt végre.
Az indextáblák adatainak duplikálása jelentős többletterhelést jelenthet a tárolási költségek és a többszörös adatmásolatok fenntartására irányuló erőfeszítések tekintetében.
Az indextábláknak az eredeti adatokra hivatkozó normalizált szerkezetként való implementálása azt igényli az alkalmazástól, hogy két keresési művelettel keressen adatokat. Az első művelet az indextáblából keresi ki az elsődleges kulcsot, a második az elsődleges kulccsal kéri le az adatot.
Ha egy rendszer számos indextáblát használ nagyon nagy adathalmazokhoz, nehéz lehet fenntartani a konzisztenciát az indextáblák és az eredeti adatok között. Elképzelhető, hogy lehetséges a végül konzisztens modell köré megtervezni az alkalmazást. Például egy adat beszúrásához, frissítéséhez vagy törléséhez egy alkalmazás elküldhet egy üzenetet egy üzenetsorba, és engedheti, hogy egy külön feladat hajtsa végre a műveletet, és tartsa karban az indextáblákat, amelyek aszinkron módon hivatkoznak ezekre az adatokra. A végül bekövetkező konzisztenciával kapcsolatos további információkat az adatkonzisztenciát ismertető szakaszban találja.
Tipp.
A Microsoft Azure Storage-táblák támogatják az ugyanazon a partíción tárolt adatokon végzett módosítások tranzakciós frissítéseit (entitáscsoport-tranzakciók). Ha egy ténytáblát és egy vagy több indextáblát ugyanazon a partíción tud tárolni, ennek a szolgáltatásnak a használatával biztosíthatja a konzisztenciát.
Maguk az indextáblák lehetnek particionáltak vagy horizontálisan skálázottak.
Mikor érdemes ezt a mintát használni?
Ennek a mintának a használatával javíthatja a lekérdezési teljesítményt, ha egy alkalmazásnak rendszeresen az elsődleges kulcstól eltérő (vagy horizontálisan skálázott) kulccsal kell adatokat keresnie.
Nem érdemes ezt a mintát használni, ha:
- Az adatok ideiglenesek. Egy indextábla gyorsan idejétmúlttá, és ezáltal nem hatékonnyá válhat, illetve az indextábla karbantartása által jelentett terhelése nagyobb, mint a használatával megtakarított erőforrások.
- Egy indextábla számára másodlagos kulcsként kiválasztott mező nem tesz különbséget, és csak kis értékkészlettel rendelkezhet (például: nem).
- Az indextábla számára másodlagos kulcsként kiválasztott mező adatértékeinek egyensúlya nagyon el van tolódva. Például ha a rekordok 90%-a egy mezőben ugyanazt az értéket tartalmazza, akkor az ezen a mezőn alapuló, adatok keresése céljából létrehozott és fenntartott indextábla több terhelést jelenthet, mintha sorrendben végignézné a rendszer az adatokat. Azonban ha a lekérdezés gyakran érint olyan értékeket, amelyek a maradék 10 %-ba tartoznak, ez az index hasznos lehet. Legyen tisztában vele, hogy milyen lekérdezéseket és milyen gyakran hajt végre az alkalmazás.
Számítási feladatok tervezése
Az építészeknek értékelniük kell, hogyan használható az indextábla-minta a számítási feladat kialakításában az Azure Well-Architected Framework pilléreiben foglalt célok és alapelvek kezelésére. Példa:
| Pillér | Hogyan támogatja ez a minta a pillércélokat? |
|---|---|
| A megbízhatósági tervezési döntések segítenek a számítási feladatnak ellenállóvá válni a hibás működéssel szemben, és biztosítani, hogy a hiba bekövetkezése után teljesen működőképes állapotba kerüljön. | Mivel az ügyfelek egy keresési folyamaton keresztül mutatnak a szegmensükre, partíciójukra vagy végpontjukra, ezzel a mintával megkönnyítheti az adathozzáférés feladatátvételi megközelítését. - RE:06 Adatparticionálás - RE:09 Vészhelyreállítás |
| A teljesítményhatékonyság a skálázás, az adatok és a kód optimalizálásával segíti a számítási feladatok hatékony kielégítését . | Az ügyfelek a szegmensükre, partíciójukra vagy végpontjukra mutatnak, amelyek lehetővé teszik a dinamikus adatparticionálást a teljesítményoptimalizáláshoz. - PE:05 Skálázás és particionálás - PE:08 Adatteljesítmény |
Mint minden tervezési döntésnél, fontolja meg az ezzel a mintával bevezethető többi pillér céljaival szembeni kompromisszumokat.
Példa
Az Azure Storage-táblák jól skálázható kulcs/érték adattárolót biztosítanak a felhőben futó alkalmazások számára. Az alkalmazások a kulcs használatával tárolják és kérik le az adatértékeket. Az adatértékek több mezőt is tartalmazhatnak, de egy adatelem struktúrája átlátszatlan a táblatároló számára, amely egyszerűen bitek tömbjeként kezeli az adatelemet.
Az Azure Storage-táblák a horizontális skálázást is támogatják. A horizontális skálázási kulcs két elemet tartalmaz: egy partíciókulcsot és egy sorkulcsot. Az ugyanazon partíciós kulccsal rendelkező elemek ugyanazon a partíción (horizontálisan skálázáson) tárolódnak, az elemek pedig sorkulcsrendben tárolódnak a horizontális skálázáson belül. A táblatároló olyan keresések végrehajtására van optimalizálva, amelyek egy összefüggő sorkulcsérték-tartományon belül eső adatokra irányulnak egy partíción belül. Ha Azure-táblákban információkat tároló felhőalkalmazásokat fejleszt, tartsa ezt szem előtt, amikor az adatokat strukturálja.
Például vegyünk egy alkalmazást, amely filmekről tárol információkat. Az alkalmazás rendszeresen kérdezi le műfaj szerint a filmeket (akció, dokumentum, történelmi vígjáték, dráma stb.). Létrehozhat egy Azure-táblát mindegyik műfajhoz egy partícióval, ha a műfajt használja partíciókulcsként és a film címét adja meg sorkulcsként, ahogy a következő ábrán látható.
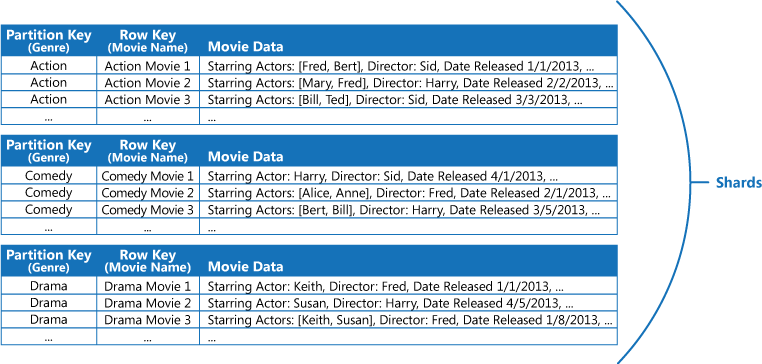
Ez a megközelítés kevésbé hatékony, ha az alkalmazásnak ugyanakkor a főszereplő színészt is le kell kérdeznie. Ebben az esetben létrehozható egy elkülönített Azure-tábla, amely indextáblaként működik. A partíciókulcs a színész, a sorkulcs pedig a film címe. Minden egyes színész adatai külön partícióban tárolódnak. Ha egy filmben egynél több színész szerepel, ugyanaz a filmcím több partícióban is megjelenik.
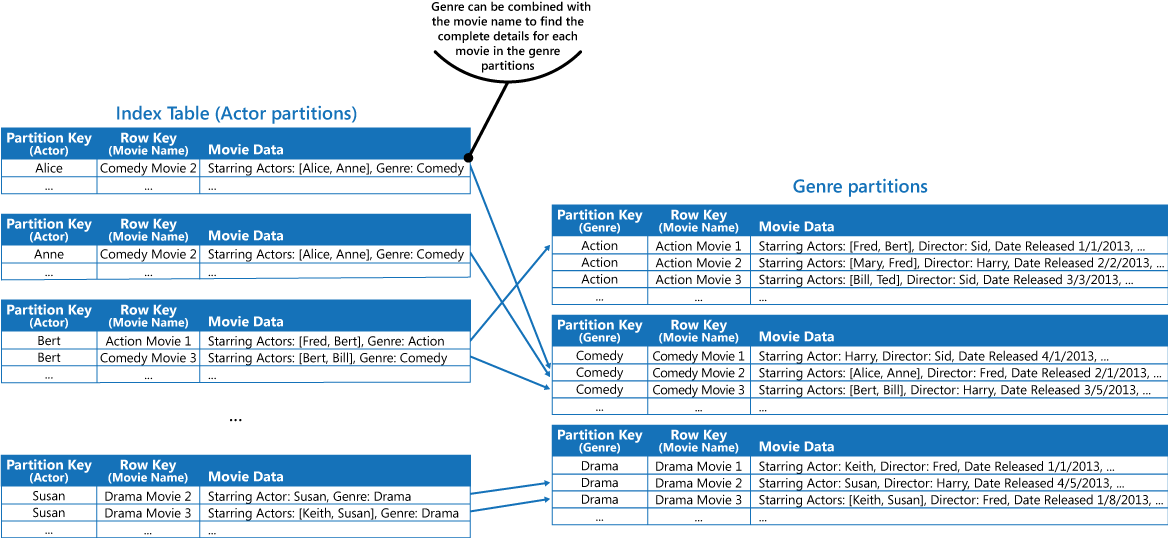
A fenti Megoldás részben leírt első megközelítés alkalmazásával duplikálhatja a film adatait az egyes partíciók értékeiben. Ugyanakkor valószínű, hogy minden film többször is másolódik (minden színész esetében egyszer), így valószínűleg hatékonyabb megoldás, ha részlegesen denormalizálja az adatokat a leggyakoribb lekérdezések támogatására (például a többi színész neve), és engedélyezi, hogy egy alkalmazás lekérhessen bármilyen egyéb részletet. Ez úgy lehetséges, hogy a műfaj-partíciókhoz hozzáadja a teljes információ megtalálásához szükséges partíciókulcsot. Erről a megközelítésről a Megoldás szakasz harmadik pontjában talál leírást. A következő ábra ezt a módszert ábrázolja.
Következő lépések
- Adatkonzisztencia – Ismertető. Az indextáblákat karban kell tartani, mivel az általuk indexelt adatok változnak. Elképzelhető, hogy a felhőben nem lehetséges vagy megfelelő olyan műveleteket elvégezni, amelyek ugyanazon tranzakció keretében frissítik is az indexet, mint amellyel módosítják az adatot. Ebben az esetben a végül konzisztens megközelítés megfelelő. Információt szolgáltat a végül bekövetkező konzisztenciát érintő kérdésekről.
Kapcsolódó erőforrások
A minta megvalósításakor az alábbi minták is relevánsak lehetnek:
- Horizontális skálázási minta. Az indextábla minta gyakran használják együtt a horizontális skálázással particionált adatokkal. A horizontális skálázási minta további információkkal szolgál arról, hogyan oszthat el egy adattárolót horizontálisan skálázott készletekbe.
- Tényleges táblán alapuló nézet minta. Ahelyett, hogy indexelné az adatokat összegző lekérdezéseket támogató adatokat, megfelelőbb lehet tényleges táblán alapuló nézetet létrehozni az adatokról. Ez a szakasz bemutatja, hogyan támogathatóak a hatékony összegző lekérdezések az előfeltöltött nézetek létrehozásával az adatokról.