Egy összetett feldolgozást végrehajtó feladatot lebonthat különálló, újrahasznosítható elemek sorává. Ezzel javíthatja a kezdeti lépések teljesítményét, méretezhetőségét és újrafelhasználhatóságát azáltal, hogy lehetővé teszi a feldolgozást végző tevékenységelemek egymástól függetlenül történő üzembe helyezését és skálázását. A csövek és szűrők mintázata támogatja a magas szintű modularitást.
Kontextus és probléma
Rendelkezik egy szekvenciális feladatokkal, amelyeket fel kell dolgoznia. Az alkalmazás implementálásának egyszerű, de rugalmatlan megközelítése, ha ezt a feldolgozást monolitikus modulban hajtja végre. Ez a megközelítés azonban valószínűleg csökkenti a kód újrabontásának, optimalizálásának vagy újrafelhasználásának lehetőségét, ha az alkalmazás más részein is szükség van ugyanannak a feldolgozásnak a részeire.
Az alábbi ábra az adatok monolitikus megközelítéssel történő feldolgozásának egyik problémáját mutatja be, amely azt mutatja be, hogy a kód több folyamaton keresztül nem használható újra. Ebben a példában egy alkalmazás két forrásból fogad és dolgoz fel adatokat. Egy külön modul feldolgozza az adatokat az egyes forrásból, és feladatokat hajt végre az adatok átalakításához, mielőtt átadná az eredményt az alkalmazás üzleti logikájának.
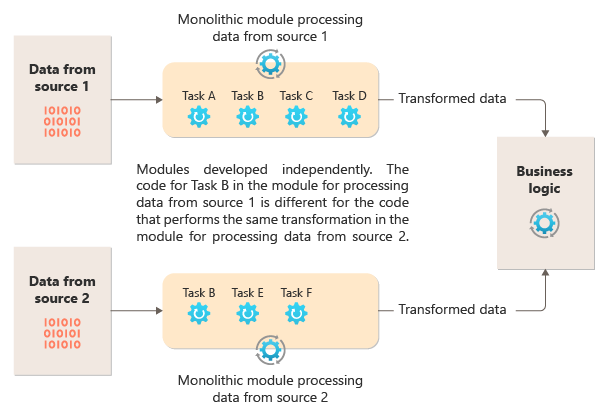
A monolitikus modulok által végrehajtott feladatok némelyike funkcionálisan hasonló, de a kódot mindkét modulban meg kell ismételni, és valószínűleg szorosan kapcsolódik a modulhoz. A logika újrafelhasználásának képtelensége mellett ez a megközelítés kockázatot is jelent a követelmények változásakor. Ne feledje, hogy mindkét helyen frissítenie kell a kódot.
A monolitikus implementáció több folyamathoz vagy újrafelhasználáshoz nem kapcsolódó monolitikus implementációval kapcsolatos egyéb kihívásokat is jelent. Monolit használatával nem futtathat meghatározott feladatokat különböző környezetekben, és nem skálázhatja őket egymástól függetlenül. Egyes feladatok nagy számítási igényűek lehetnek, és kihasználhatják a hatékony hardveren vagy több példány párhuzamos futtatását. Előfordulhat, hogy más feladatokra nem ugyanazok a követelmények vonatkoznak. Emellett monolitok esetén nehéz feladatokat átrendezni vagy új feladatokat injektálni a folyamatba. Ezek a módosítások a teljes folyamat újratesztelését igénylik.
Megoldás
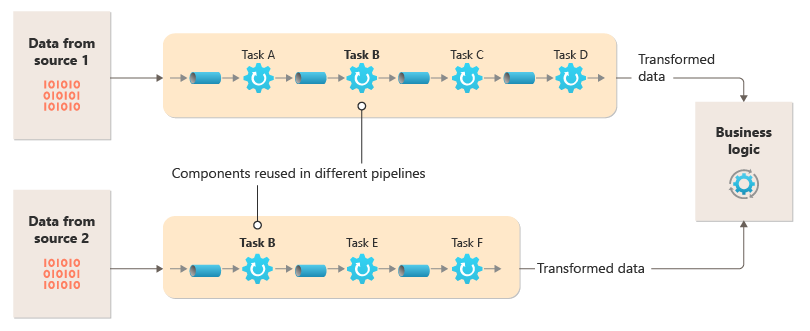
Ossza fel az egyes streamekhez tartozó feldolgozási folyamatot olyan különálló összetevőkre (vagy szűrőkre), amelyek mindegyike egyetlen feladatot végez. Az összetett feladatoknak nem egy, hanem több szűrőt kell használniuk. A szűrők a szűrők csövekkel való összekapcsolásával folyamatokba vannak összeállítva. A szűrők függetlenek, önállóak és jellemzően állapot nélküliek. A szűrők üzeneteket fogadnak egy bejövő csőből, és üzeneteket tesznek közzé egy másik kimenő csőben. A szűrők átalakíthatják az üzenetet, vagy tesztelhetik egy vagy több feltételen, hogy feltételes logikát is tartalmazzanak. A csövek nem hajtanak végre útválasztást vagy más logikát. Csak szűrőket csatlakoztatnak, és az egyik szűrőből érkező kimeneti üzenetet adják át bemenetként a következőnek.
A szűrők egymástól függetlenül működnek, és nem ismerik az egyéb szűrőket. Csak a bemeneti és kimeneti sémákat ismerik. Így a szűrők bármilyen sorrendben rendezhetők, amíg bármely szűrő bemeneti sémája megegyezik az előző szűrő kimeneti sémájában. Ha minden szűrőhöz szabványosított sémát használ, az növeli a szűrők átrendezésének lehetőségét. A csövek és szűrők architektúrája ösztönzi a kompozíciós újrafelhasználást.
A szűrők laza összekapcsolása megkönnyíti a következőt:
- Meglévő szűrőkből álló új folyamatok létrehozása
- Logika frissítése vagy cseréje az egyes szűrőkben
- Szükség esetén átrendezi a szűrőket
- Szűrők futtatása eltérő hardveren, ahol szükséges
- Szűrők futtatása párhuzamosan
Ez az ábra egy csövekkel és szűrőkkel implementált megoldást mutat be:
Az egyetlen kérés feldolgozásához szükséges idő a folyamat leglassabb szűrőinek sebességétől függ. Egy vagy több szűrő szűk keresztmetszetet jelenthet, különösen akkor, ha egy adott adatforrásból származó streamben nagy számú kérés jelenik meg. A lassú szűrők párhuzamos példányainak futtatásával a rendszer eloszthatja a terhelést, és javíthatja az átviteli sebességet.
A szűrők különböző számítási példányokon való futtatásának lehetősége lehetővé teszi, hogy egymástól függetlenül skálázhatók legyenek, és kihasználhassák a számos felhőkörnyezet által biztosított rugalmasságot. A számításigényes szűrők nagy teljesítményű hardvereken futtathatók, míg más kevésbé igényes szűrők kevésbé költséges hardvereken üzemeltethetők. A szűrőknek nem is kell ugyanabban az adatközpontban vagy földrajzi helyen lenniük, így a folyamat minden eleme olyan környezetben futhat, amely közel van a szükséges erőforrásokhoz. Ezek az erőfeszítések olyan speciális tervezési technikákat igényelnek, mint az üzenetkezelés, a többszálas készítés stb. az egyes csövek vagy szűrők rugalmasságának maximalizálása érdekében. Ez az ábra az 1. forrásból származó adatok folyamatára alkalmazott példát mutatja be:
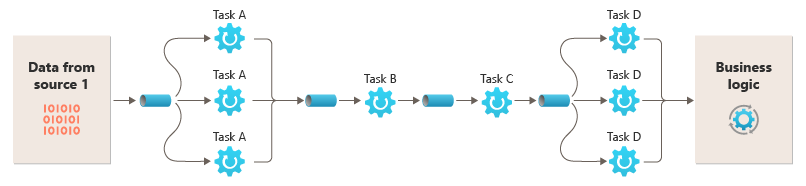
Ha egy szűrő bemenete és kimenete streamként van strukturálva, az egyes szűrők feldolgozása párhuzamosan is elvégezhető. A folyamat első szűrője elindíthatja a munkáját, és kimenetelheti az eredményeit, amelyeket közvetlenül a következő szűrőnek ad át a sorozatban, mielőtt az első szűrő befejezi a munkáját.
Az elosztott tranzakciók implementálásának alternatív módszere a Csövek és szűrők minta és a Kompenzáló tranzakció minta együttes használata. Az elosztott tranzakciókat külön, kompenzálható tevékenységekre bonthatja, amelyek mindegyike implementálható egy szűrővel, amely a kompenzáló tranzakció mintáját is implementálja. A folyamatok szűrőit olyan különálló üzemeltetett feladatokként implementálhatja, amelyek az általuk kezelt adatok közelében futnak.
Problémák és megfontolandó szempontok
Vegye figyelembe a következő szempontokat, amikor úgy dönt, hogy hogyan valósítja meg ezt a mintát:
Monolitikus természet. Ez a minta általában monolitikus folyamatként van implementálva, így bármilyen változás esetén a teljes szűrőláncot teljes körűen tesztelni kell. Emellett figyelembe kell venni a teljes folyamat hibatűrését is; ha egy szűrő vagy cső meghibásodik, a teljes folyamat valószínűleg sikertelen lesz.
Összetettség. A minta által biztosított megnövelt rugalmasság összetettséget is eredményezhet, különösen akkor, ha a folyamat szűrői különböző kiszolgálókon vannak elosztva.
Megbízhatóság. Olyan infrastruktúrát használjon, amely biztosítja, hogy a cső szűrői között áramló adatok ne vesszenek el.
Idempotencia. Ha egy folyamat szűrője egy üzenet fogadása után meghiúsul, és a munka a szűrő egy másik példányára van ütemezve, a munka egy része már befejeződött. Ha a munka frissíti a globális állapot valamely aspektusát (például az adatbázisban tárolt adatokat), egyetlen frissítés megismételhető. Hasonló probléma akkor fordulhat elő, ha egy szűrő meghiúsul, miután az eredményeket a következő szűrőre adhatja, de mielőtt azt jelezné, hogy sikeresen befejezte a munkáját. Ezekben az esetekben a szűrő egy másik példánya megismételheti ezt a munkát, ami ugyanazt az eredményt kétszer is közzéteheti. Ez a forgatókönyv azt eredményezheti, hogy a folyamat további szűrői kétszer dolgoznak fel ugyanazokat az adatokat. Ezért a folyamat szűrőit idempotensnek kell tervezni. További információ: Idempotency Patterns on Jonathan Oliver's blog.
Ismétlődő üzenetek. Ha egy folyamat szűrője meghiúsul, miután üzenetet tesz közzé a folyamat következő szakaszára, előfordulhat, hogy a szűrő egy másik példánya fut, és ugyanannak az üzenetnek egy példányát közzéteszi a folyamatnak. Ez a forgatókönyv azt eredményezheti, hogy ugyanannak az üzenetnek két példánya lesz átadva a következő szűrőnek. A probléma elkerülése érdekében a folyamatnak észlelnie kell és meg kell szüntetnie az ismétlődő üzeneteket.
Feljegyzés
Ha üzenetsorok (például Azure Service Bus-üzenetsorok) használatával valósítja meg a folyamatot, az üzenetsor-kezelési infrastruktúra automatikusan ismétlődő üzenetészlelést és -eltávolítást biztosíthat.
Kontextus és állapot. A folyamatokban a szűrők gyakorlatilag elkülönítve futnak, és nem tudják feltételezni azok aktiválásuk módját. Ezért minden szűrőnek elegendő kontextust kell biztosítani a munkájához. Ez a környezet jelentős mennyiségű állapotinformációt tartalmazhat. Ha a szűrők külső állapotot használnak, például egy adatbázisban vagy egy külső tárolóban lévő adatokat, akkor figyelembe kell vennie a teljesítményre gyakorolt hatást. Minden szűrőnek be kell töltenie, működtetnie és meg kell őriznie ezt az állapotot, ami többletterhelést okoz a külső állapotot egyetlen alkalommal betöltő megoldásokon.
Üzenettűrés. A szűrőknek toleránsnak kell lenniük a bejövő üzenetben szereplő adatoktól, amelyeken nem működnek. A hozzájuk kapcsolódó adatokon működnek, figyelmen kívül hagyják a többi adatot, és változatlanul továbbítják őket a kimeneti üzenetben.
Hibakezelés – Minden szűrőnek meg kell határoznia, hogy mi a teendő kompatibilitástörő hiba esetén. A szűrőnek meg kell állapítania, hogy nem sikerül-e a folyamat, vagy propagálja a kivételt.
Mikor érdemes ezt a mintát használni?
Használja ezt a mintát, ha:
Az alkalmazások számára szükséges feldolgozási folyamat egyszerűen lebontható független lépések sorozatára.
Az alkalmazások által végrehajtott feldolgozási lépések különböző skálázhatósági követelményekkel rendelkeznek.
Feljegyzés
Csoportosíthatja azokat a szűrőket, amelyeknek ugyanabban a folyamatban együtt kell skálázniuk. További információkért lásd a számításierőforrás-konszolidálási mintát.
Rugalmasságot igényel ahhoz, hogy lehetővé tegye az alkalmazás által végrehajtott feldolgozási lépések átrendezését, vagy lehetővé tegye a lépések hozzáadását és eltávolítását.
A rendszer számára előnyös lehet, ha az egyes lépésekhez tartozó feldolgozási folyamatok különböző kiszolgálókra vannak elosztva.
Olyan megbízható megoldásra van szüksége, amely minimálisra csökkenti az adatok feldolgozása során fellépő hibák hatásait egy lépésben.
Nem érdemes ezt a mintát használni, ha:
Az alkalmazás egy kérés-válasz mintát követ.
A feladatfeldolgozást egy kezdeti kérés részeként kell elvégezni, például egy kérés/válasz forgatókönyv részeként.
Az alkalmazás által végrehajtott feldolgozási lépések nem függetlenek, vagy egy tranzakció részeként együtt kell végrehajtani őket.
A környezeti vagy állapotinformációk egy lépésben való mennyisége miatt ez a megközelítés nem hatékony. Előfordulhat, hogy meg tudja őrizni az állapotinformációkat egy adatbázisban, de ne használja ezt a stratégiát, ha az adatbázis többletterhelése túlzott versengést okoz.
Számítási feladatok tervezése
Az építészeknek értékelniük kell, hogy a csövek és szűrők minta hogyan használható a számítási feladat kialakításában az Azure Well-Architected Framework pilléreiben foglalt célok és alapelvek kezelésére. Példa:
| Pillér | Hogyan támogatja ez a minta a pillércélokat? |
|---|---|
| A megbízhatósági tervezési döntések segítenek a számítási feladatnak ellenállóvá válni a hibás működéssel szemben, és biztosítani, hogy a hiba bekövetkezése után teljesen működőképes állapotba kerüljön. | Az egyes szakaszok önálló felelőssége lehetővé teszi a koncentrált figyelmet, és elkerüli a zavaró tényezőket az összevonásos adatfeldolgozásban. - RE:01 Egyszerűség - RE:07 Háttérfeladatok |
Mint minden tervezési döntésnél, fontolja meg az ezzel a mintával bevezethető többi pillér céljaival szembeni kompromisszumokat.
Példa
A folyamat implementálásához szükséges infrastruktúra biztosításához üzenetsorok sorozatát is használhatja. A kezdeti üzenetsorok feldolgozatlan üzeneteket kapnak, amelyek a csövek és a szűrők mintájának implementálásának kezdeteivé válnak. A szűrőfeladatként implementált összetevő figyeli az üzenetsor üzeneteit, végrehajtja a munkáját, majd új vagy átalakított üzenetet küld a következő üzenetsorba a sorrendben. Egy másik szűrőfeladat figyelheti az üzenetsoron lévő üzeneteket, feldolgozhatja őket, közzéteheti az eredményeket egy másik üzenetsorba, és így tovább, amíg az utolsó lépés, amely befejezi a csövek és a szűrők folyamatát. Ez az ábra egy üzenetsorokat használó folyamatot szemléltet:

Ezzel a mintával egy képfeldolgozó folyamat implementálható. Ha a számítási feladat lemezképet készít, a rendszerkép nagyrészt független és átrendezhető szűrők sorozatán haladhat át az olyan műveletek végrehajtásához, mint például:
- con sátormód ration
- átméretezés
- Vízjel
- tájolás
- Metaadatok exif eltávolítása
- Tartalomkézbesítési hálózat (CDN) kiadványa
Ebben a példában a szűrők egyénileg üzembe helyezett Azure Functionsként vagy akár egyetlen Azure-függvényalkalmazásként is implementálhatók, amelyek az egyes szűrőket izolált üzemelő példányként tartalmazzák. Az Azure-függvény eseményindítóinak, bemeneti kötéseinek és kimeneti kötéseinek használata leegyszerűsítheti a szűrőkódot, és automatikusan együttműködhet egy üzenetsoralapú csővel a rendszerkép jogcím-ellenőrzése segítségével a feldolgozáshoz.

Íme egy példa arra, hogy egy Azure-függvényként implementált szűrő hogyan aktiválódik egy Queue Storage-csőből egy jogcímellenőrzéssel a képre, és hogyan nézhet ki egy új jogcím-ellenőrzés írása egy másik Queue Storage-csőbe. Az implementációt a rövidség kedvéért pszeudokódra cseréltük. Ehhez hasonló kód a GitHubon elérhető Csövek és szűrők minta bemutatójában található.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Feljegyzés
A Spring Integration Framework a csövek és szűrők mintájának implementálásával rendelkezik.
Következő lépések
A minta megvalósításakor a következő erőforrások lehetnek hasznosak:
- A GitHubon bemutatjuk a csövek és szűrők mintáját a képfeldolgozási forgatókönyv használatával.
- Idempotencia minták, Jonathan Oliver blogján.
Kapcsolódó erőforrások
A minta megvalósításakor az alábbi minták is relevánsak lehetnek:
- Jogcím-ellenőrzési minta. Előfordulhat, hogy egy üzenetsort használó folyamat nem a szűrőkön keresztül küldött tényleges elemet tárolja, hanem a feldolgozandó adatokra mutató mutatót. A példa egy jogcím-ellenőrzést használ az Azure Queue Storage-ban az Azure Blob Storage-ban tárolt képekhez.
- Versengő felhasználókat ismertető minta. A folyamatok adott szűrők több példányát is tartalmazhatják. Ez a módszer lassú szűrők párhuzamos példányainak futtatásához hasznos. Lehetővé teszi a rendszer számára a terhelés elterjesztését és az átviteli sebesség javítását. A szűrő minden példánya versenge a többi példánnyal való bemenetért, de a szűrő két példánya nem tudja feldolgozni ugyanazokat az adatokat. Ez a cikk a megközelítést ismerteti.
- Számításierőforrás-konszolidálási minta. Lehetséges, hogy olyan szűrőket csoportosítunk, amelyeknek egyetlen folyamatba kell skálázniuk. Ez a cikk további információt nyújt a stratégia előnyeiről és kompromisszumairól.
- Kompenzáló tranzakció mintája. A szűrőt megfordítható műveletként implementálhatja, vagy olyan kompenzáló művelettel rendelkezik, amely hiba esetén visszaállítja az állapotot egy korábbi verzióra. Ez a cikk azt ismerteti, hogyan valósíthatja meg ezt a mintát a végleges konzisztencia fenntartása vagy elérése érdekében.
- Csövek és szűrők – Vállalati integrációs minták.