Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Azure
Engedélyezheti egy alkalmazás számára a szolgáltatásokhoz vagy hálózati erőforrásokhoz való csatlakozáskor jelentkező átmeneti meghibásodások kezelését egy meghiúsult művelet transzparens módon való ismételt megkísérlésével. Ez javíthatja az alkalmazás stabilitását.
Kontextus és probléma
A felhőben futó elemekkel kommunikáló alkalmazásoknak érzékenynek kell lenniük az ebben a környezetben előforduló átmeneti hibákra. Ilyen hiba lehet az összetevők és szolgáltatások hálózati kapcsolatának pillanatnyi megszakadása, a szolgáltatások átmeneti elérhetetlensége, valamint a foglalt szolgáltatás miatti időtúllépés.
Ezek a hibák gyakran maguktól megoldódnak, és ha megfelelő idő múlva megismételik a hibát kiváltó műveletet, az valószínűleg sikeresen végbemegy. Egy nagy számú egyidejű kérést feldolgozó adatbázis-szolgáltatás például olyan szabályozási stratégiát valósíthat meg, amely ideiglenesen elutasítja a további kéréseket, amíg a számítási feladat le nem enyhül. Az adatbázist elérni próbáló alkalmazás csatlakozása sikertelen lehet, de ha később próbálkozik, sikerülhet a csatlakozás.
Megoldás
A felhőben átmeneti hibákra kell számítani, és az alkalmazásokat elegánsan és transzparensen kell kezelni. Ezzel minimálisra csökkenti a hibáknak az alkalmazás által végrehajtott üzleti tevékenységekre gyakorolt hatását. A leggyakrabban használt tervezési minta egy újrapróbálkozási mechanizmus bevezetése.
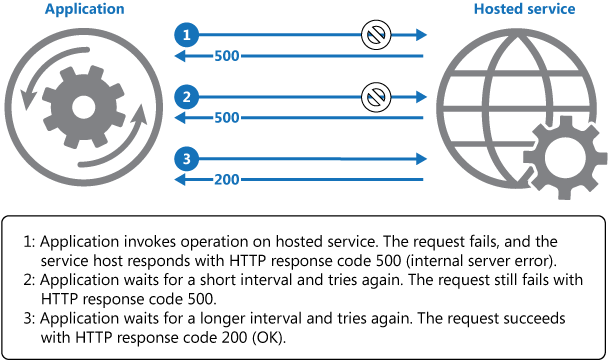
A fenti ábra egy üzemeltetett szolgáltatásban végrehajtott művelet meghívását szemlélteti újrapróbálkozási mechanizmus használatával. Ha a kérés a kísérletek előre meghatározott száma után is sikertelen, az alkalmazásnak kivételként kell kezelnie a hibát.
Feljegyzés
Az átmeneti hibák gyakori jellege miatt a beépített újrapróbálkozási mechanizmusok már számos ügyfélkódtárban és felhőszolgáltatásban elérhetők, bizonyos fokú konfigurálhatóság mellett a maximális újrapróbálkozások száma, az újrapróbálkozások közötti késés és más paraméterek esetében. A Microsoft Entity Framework lehetőséget biztosít a sikertelen adatbázis-műveletek újrapróbálkozására.
Újrapróbálkozási stratégiák
Ha egy alkalmazás hibát észlel, amikor kéréseket próbál küldeni egy távoli szolgáltatásnak, a következő stratégiákkal kezelheti a hibát:
Megszakítás. Ha a hiba azt jelzi, hogy a probléma nem átmeneti vagy nem valószínű, hogy a művelet a megismétlésekor sikeres lesz, az alkalmazásnak meg kell szakítania a műveletet, és kivételt kell jelentenie.
Próbálkozzon újra azonnal. Ha a jelentett hiba szokatlan vagy ritka, például egy hálózati csomag megsérül az átvitel közben, a legjobb megoldás lehet a kérés azonnali újrapróbálkozása.
Újrapróbálkozás később. Ha a hibát az egyik leggyakoribb kapcsolati vagy foglaltsági hiba okozza, előfordulhat, hogy a hálózatnak vagy a szolgáltatásnak rövid időre van szüksége, amíg a csatlakozási problémákat kijavítják, vagy a munka hátraléka törlődik, ezért az újrapróbálkozások programozott késleltetése jó stratégia. Sok esetben az újrapróbálkozások közötti időszakot úgy kell megválasztani, hogy az alkalmazás több példányából érkező kérelmeket a lehető leg egyenletesen terjessze el, hogy csökkentse az elfoglalt szolgáltatások túlterheltségének esélyét.
Ha a kérés továbbra is sikertelen, az alkalmazás várhat és megismételheti a kísérletet. Szükség esetén ez a folyamat megismételhető az újrapróbálkozások közötti késleltetések növelésével, amíg a rendszer el nem éri a kísérletek maximális számát. A késleltetés növekményesen vagy exponenciálisan növelhető a hiba típusától és annak valószínűségétől függően, hogy ezen idő alatt megoldódik-e.
Az alkalmazásnak olyan kódba kell csomagolnia a távoli szolgáltatások elérési kísérleteit, amely a fent felsorolt stratégiák egyikének megfelelő újrapróbálkozási szabályzatot valósít meg. A különböző szolgáltatásoknak küldött kérésekre különböző szabályzatok lehetnek érvényesek.
Az alkalmazásoknak naplózniuk kell a hibák és a sikertelen műveletek részleteit. Ez az információ hasznos az operátorok számára. Ennek ellenére annak érdekében, hogy elkerüljük az olyan műveletekre vonatkozó riasztásokkal rendelkező operátorokat, amelyek később újrapróbálkozási kísérletek sikeresek voltak, a legjobb, ha a korai hibákat tájékoztató bejegyzésként naplózza, és csak az újrapróbálkozási kísérletek utolsó sikertelenségét tényleges hibaként. Íme egy példa a naplózási modell megjelenésére.
Ha egy szolgáltatás gyakran elérhetetlen vagy foglalt, azt leggyakrabban a szolgáltatás erőforrásainak kimerülése okozza. A szolgáltatás horizontális felskálázásával csökkentheti ezeknek a hibáknak a gyakoriságát. Ha például egy adatbázis-szolgáltatás folyamatosan túlterhelt, érdemes lehet particionálni az adatbázist, és több kiszolgáló között elosztani a terhelést.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe.
A teljesítményre gyakorolt hatás
Az újrapróbálkozási szabályzatot úgy kell beállítani, hogy megfeleljen az alkalmazás az üzleti követelményeinek és a hiba természetének. Néhány nem kritikus művelet esetén jobb, ha gyorsan meghiúsul ahelyett, hogy többször újrapróbálkoznál, és befolyásolná az alkalmazás átviteli sebességét. Egy távoli szolgáltatást elérő interaktív webalkalmazásban például jobb, ha kisebb számú újrapróbálkozás után meghiúsul, és csak rövid késleltetéssel próbálkozik az újrapróbálkozások között, és megjelenít egy megfelelő üzenetet a felhasználónak (például "próbálkozzon újra később"). Kötegelt alkalmazásokhoz érdemes lehet növelni az újrapróbálkozási kísérletek számát, ezzel exponenciálisan növelve a kísérletek közötti késleltetést.
A kísérletek között minimális késleltetést használó agresszív újrapróbálkozási szabályzat és a számos újrapróbálkozás tovább ronthat az elfoglalt szolgáltatás állapotán, amely maximális vagy közel maximális kapacitással fut. Az újrapróbálkozási szabályzat az alkalmazás válaszkészségét is befolyásolhatja, ha folyamatosan sikertelen műveletet próbál végezni.
Ha egy kérés jelentős számú újrapróbálkozás után is meghiúsul, jobb, ha az alkalmazás megakadályozza, hogy a további kérések ugyanarra az erőforrásra lépjenek, és azonnal jelentsenek hibát. Amikor az időszak lejár, az alkalmazás feltételesen átengedhet egy vagy több kérést, hogy megállapítsa, azok sikeresek-e. A stratégiával kapcsolatos további információkért lásd a Circuit Breaker pattern-t.
Idempotencia
Gondolja át, hogy a művelet idempotens-e. Ha igen, alapvetően biztonságos az újrapróbálkozás. Más esetekben az újrapróbálkozások miatt előfordulhat, hogy a művelet többször lesz végrehajtva, nem kívánt mellékhatásokkal. Egy szolgáltatás például fogadhatja a kérést, sikeresen feldolgozhatja a kérést, de lehet, hogy nem tud választ küldeni. Ezen a ponton az újrapróbálkozási logika újraküldheti a kérést, feltételezve, hogy a szolgáltatás nem kapta meg az első kérést.
Kivételtípus
A szolgáltatásra irányuló kérések a hiba jellegétől függően különböző okokból meghiúsulhatnak. Néhány kivétel gyorsan megoldható hibát jelez, míg mások azt jelzik, hogy a hiba hosszabb ideig tart. Hasznos lehet, ha az újrapróbálkozási szabályzat a kivétel típusa alapján állítja be az újrapróbálkozási kísérletek közötti időt.
Tranzakciókonzisztencia
Fontolja meg, hogy egy tranzakció részét képező művelet újrapróbálása milyen hatással lesz a tranzakció teljes konzisztenciájára. Finomhangolja az újrapróbálkozási szabályzatot a tranzakciós műveletekhez, hogy a műveletek minél nagyobb eséllyel sikeresek legyenek, és ne kelljen visszavonni a tranzakció összes lépését.
Általános útmutatás
Győződjön meg arról, hogy az újrapróbálkozási kód teljes mértékben tesztelve van a különböző hibafeltételek között. Ellenőrizze, hogy ez nem befolyásolja-e súlyosan az alkalmazás teljesítményét vagy megbízhatóságát, túlzott terhelést okoz-e a szolgáltatásokra és az erőforrásokra, vagy versenyfeltételeket vagy szűk keresztmetszeteket hoz-e létre.
Csak ott alkalmazzon újrapróbálkozási logikát, ahol a meghiúsuló műveletek teljes kontextusa érthető. Ha például egy újrapróbálkozási szabályzatot tartalmazó feladat egy újrapróbálkozási szabályzatot tartalmazó másik feladatot hív meg, az újrapróbálkozások extra rétege miatt a feldolgozás során hosszú késések lesznek tapasztalhatóak. Érdemes úgy konfigurálni az alacsonyabb szintű feladatot, hogy gyorsan hiúsuljon meg és jelentse a hiba okát az azt elindító feladatnak. Ez a magasabb szintű feladat ezután a saját szabályzata alapján kezelheti a hibát.
Naplózza azokat a csatlakozási hibákat, amelyek újrapróbálkozást okoznak, hogy az alkalmazással, szolgáltatásokkal vagy erőforrásokkal kapcsolatos mögöttes problémák azonosíthatók legyenek.
Vizsgálja meg egy szolgáltatás vagy erőforrás legvalószínűbb hibáit annak felderítése érdekében, hogy valószínűleg tartósak vagy végzetesek-e. Ha igen, jobb kivételként kezelni a hibát. Az alkalmazás jelentheti vagy naplózhatja a kivételt, majd a folytatáshoz megpróbálhat alternatív szolgáltatást elindítani (ha van elérhető) vagy csökkentett teljesítményű funkciókat alkalmazni. A tartós hibák észlelésével és kezelésével kapcsolatos további információkért lásd az áramkör-megszakítási mintát.
Mikor érdemes ezt a mintát használni?
Ezt a mintát használja, ha egy alkalmazás átmeneti hibákat tapasztalhat, amikor távoli szolgáltatással kommunikál, vagy távoli erőforráshoz fér hozzá. Ezek a hibák várhatóan rövid életűek, és a korábban meghiúsult kérések megismétlése egy későbbi kísérlet során sikeres lehet.
Nem érdemes ezt a mintát használni a következő esetekben:
- Amikor egy hiba valószínűleg tartós, mert ez befolyásolhatja az alkalmazások válaszkészségét. Előfordulhat, hogy az alkalmazás időt és erőforrásokat pazarol egy olyan kérés megismétlésére, amely valószínűleg sikertelen lesz.
- A nem átmeneti hibák által okozott hibák kezeléséhez, például amikor egy alkalmazás üzleti logikájában lévő hibák belső kivételeket okoznak.
- A rendszer skálázhatósági hibáinak kezelési alternatívájaként. Ha egy alkalmazás gyakori foglaltsági hibákat észlel, az gyakran azt jelzi, hogy az elért szolgáltatást vagy erőforrást vertikálisan fel kell skálázni.
Számítási feladatok tervezése
Az építészeknek értékelniük kell, hogy az Újrapróbálkozási minta hogyan használható a számítási feladat kialakításában az Azure Well-Architected Framework pilléreiben foglalt célok és alapelvek kezelésére. Példa:
| Pillér | Hogyan támogatja ez a minta a pillércélokat? |
|---|---|
| A megbízhatósági tervezési döntések segítenek a számítási feladatnak ellenállóvá válni a hibás működéssel szemben, és biztosítani, hogy a hiba bekövetkezése után teljesen működőképes állapotba kerüljön. | Az elosztott rendszerek átmeneti hibáinak enyhítése alapvető módszer a számítási feladatok rugalmasságának javításához. - RE:07 Önmegőrzés - RE:07 Átmeneti hibák |
Mint minden tervezési döntésnél, fontolja meg az ezzel a mintával bevezethető többi pillér céljaival szembeni kompromisszumokat.
Példa
Az Azure SDK beépített újrapróbálkozési mechanizmus támogatásával történő használatával részletes példáért tekintse meg az Újrapróbálkozás szabályzat implementálása .NET-útmutatóval című témakört.
Következő lépések
Mielőtt egyéni újrapróbálkoztatási logikát ír, fontolja meg egy általános keretrendszer használatát, például a Polly for .NET vagy a Resilience4j for Java használatát.
Az üzleti adatokat módosító parancsok feldolgozásakor vegye figyelembe, hogy az újrapróbálkozások kétszer is végrehajthatják a műveletet, ami problémás lehet, ha ez a művelet olyan, mint az ügyfél hitelkártyájának feltöltése. Az ebben a blogbejegyzésben ismertetett idempotencia-minta használata segíthet kezelni ezeket a helyzeteket.
Kapcsolódó erőforrások
A megbízható webalkalmazás-minta bemutatja, hogyan alkalmazhatja az újrapróbálkozási mintát a felhőben konvergens webalkalmazásokra.
A legtöbb Azure-szolgáltatás esetében az ügyféloldali SDK-k beépített újrapróbálkozési logikát tartalmaznak.
Áramkör-megszakítási minta. Ha egy hiba várhatóan tartósabb, célszerűbb lehet az áramkör-megszakítási mintát implementálni. Az újrapróbálkozási és megszakítóminták kombinálása átfogó megközelítést biztosít a hibák kezeléséhez.