Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure NetApp Files-kötet kötetnyelve (az ügyfél operációs rendszerek rendszerbeállításaihoz hasonló) az NFS- és SMB-protokollok használatakor szabályozza a támogatott nyelveket és karakterkészleteket. Az Azure NetApp Files a C.UTF-8 alapértelmezett kötetnyelvét használja, amely POSIX-kompatibilis UTF-8 kódolást biztosít a karakterkészletekhez. A C.UTF-8 nyelv natív módon támogatja a 0-3 bájt méretű karaktereket, amely magában foglalja a világ nyelveinek többségét az alapszintű többnyelvű síkon (BMP) (beleértve a japánt, a németet, valamint a legtöbb héber és cirill betűset). A BMP-vel kapcsolatos további információkért lásd a Unicode-t.
A BMP-n kívüli karakterek néha meghaladják az Azure NetApp Files által támogatott 3 bájtos méretet. Ezért helyettesítő párlogikát kell használniuk, ahol több karakter bájtkészlet van kombinálva, hogy új karaktereket alkotjanak. Az emoji szimbólumok például ebbe a kategóriába tartoznak, és az Azure NetApp Filesban olyan esetekben támogatottak, amikor az UTF-8 nincs kényszerítve: ilyenek például az UTF-16 kódolást használó Windows-ügyfelek vagy az UTF-8-at nem kényszerítő NFSv3. Az NFSv4.x nem kényszeríti az UTF-8-at, ami azt jelenti, hogy a helyettesítő pár karakterei nem jelennek meg megfelelően az NFSv4.x használatakor.
A nem szabványos kódolás, például a Shift-JIS és a kevésbé gyakori CJK-karakterek szintén nem jelennek meg megfelelően, ha az UTF-8 az Azure NetApp Filesban van kényszerítve.
Tipp.
Az UTF-8 használatával kell szöveget küldenie és fogadnia, hogy elkerülje azokat a helyzeteket, amikor a karakterek nem fordíthatók le megfelelően, ami fájllétrehozást/átnevezést vagy másolást okozhat.
A kötet nyelvi beállításai jelenleg nem módosíthatók az Azure NetApp Filesban. További információ: Protokoll viselkedése speciális karakterkészletekkel.
Az ajánlott eljárásokért tekintse meg a Karakterkészlet ajánlott eljárásait.
Karakterkódolás az Azure NetApp Files NFS- és SMB-köteteiben
Az Azure NetApp Files fájlmegosztási környezetében a fájl- és mappaneveket a végfelhasználók által olvasott és értelmezett karakterek sorozata jelöli. A karakterek megjelenítési módja attól függ, hogy az ügyfél hogyan küldi el és kapja meg a karakterek kódolását. Ha például egy ügyfél régebbi American Standard Code for Information Interchange (ASCII) kódolást küld az Azure NetApp Files-kötetre a hozzáféréskor, akkor az csak az ASCII formátumban támogatott karakterek megjelenítésére korlátozódik.
Az adatok japán karaktere például 資. Mivel ez a karakter nem jeleníthető meg az ASCII-ben, az ASCII kódolást használó ügyfél "?" helyett 資.
Az ASCII csak 95 nyomtatható karaktert támogat, elsősorban az angol nyelvű karaktereket. Ezek a karakterek 1 bájtot használnak, amelyet egy Azure NetApp Files-kötet teljes fájlútvonal-hosszában számítunk ki. Ez korlátozza az adathalmazok nemzetköziesítését, mivel a fájlnevek számos olyan karaktert tartalmazhatnak, amelyeket az ASCII nem ismer fel, a japántól a cirill betűsig és az emojiig. Egy nemzetközi szabvány (ISO/IEC 8859) több nemzetközi karaktert próbált támogatni, de korlátai is voltak. A legtöbb modern ügyfél valamilyen Unicode-formában küld és fogad karaktereket.
Unicode
Az ASCII és az ISO/IEC 8859 kódolás korlátozásai miatt a Unicode szabványt azért hozták létre, hogy bárki megtekinthesse a saját régiója nyelvét az eszközeiről.
- A Unicode több mint egymillió karakterkészletet támogat azáltal, hogy a karakterenkénti bájtok számát (legfeljebb 4 bájt) és a fájlelérési útvonalon engedélyezett bájtok számát is növeli, szemben a régebbi kódolásokkal, például az ASCII-kkel.
- A Unicode az ASCII első 128 karakterének megőrzésével támogatja a visszamenőleges kompatibilitást, ugyanakkor biztosítja, hogy az első 256 kódpont megegyezik az ISO/IEC 8859 szabványokkal.
- A Unicode szabványban a karakterkészletek síkokra vannak bontva. A sík 65 536 kódpontból álló folyamatos csoport. A Unicode szabványban összesen 17 sík (0-16) található. A korlát az UTF-16 korlátozásai miatt 17.
- A 0. sík az alapszintű többnyelvű sík (BMP). Ez a sík a leggyakrabban használt karaktereket tartalmazza több nyelven.
- A 17 sík közül jelenleg csak öt rendelkezik hozzárendelt karakterkészlettel a Unicode 15.1-es verziójában.
- Az 1–17. síkok kiegészítő többnyelvű síkok (SMP) néven ismertek, és kevésbé használt karakterkészleteket tartalmaznak, például ősi írási rendszereket, például ékírási és hieroglifákat, valamint speciális kínai/japán/koreai (CJK) karaktereket.
- A karakterhosszok és elérési utak méretének megtekintésére és a rendszernek küldött kódolás szabályozására vonatkozó módszerekért lásd : Fájlok konvertálása különböző kódolásokra.
A Unicode szabványként a Unicode átalakítási formátumot használja, a két fő formátum az UTF-8 és az UTF-16.
Unicode-síkok
A Unicode 17 síkot használ 65 536 karakterből (256 kódpont szorozva a sík 256 dobozával), a Sík 0 pedig alapszintű többnyelvű síkként (BMP). Ez a sík a leggyakrabban használt karaktereket tartalmazza több nyelven. Mivel a világ nyelveinek és karakterkészleteinek száma meghaladja a 65536 karaktert, több síkra van szükség a ritkábban használt karakterkészletek támogatásához.
Például az 1. sík (a kiegészítő többnyelvű síkok (SMP)) olyan történelmi szkripteket tartalmaz, mint a ékírás és az egyiptomi hieroglifák, valamint néhány Osage, Warang Citi, Adlam, Wancho és Toto. Az 1. sík néhány szimbólumot és hangulatjelet is tartalmaz.
A 2. sík – a kiegészítő ideográfiai sík (SIP) – kínai/japán/koreai (CJK) egyesített ideográfokat tartalmaz. Az 1. és a 2. sík karakterei általában 4 bájt méretűek.
Példa:
- A "grinning face with big eyes" emoticon "😃" az 1. síkban 4 bájt méretű.
- Az egyiptomi hieroglif "𓀀" az 1. síkban 4 bájt méretű.
- A "𐒸" osage karakter az 1. síkban 4 bájt méretű.
- A "𫝁" CJK karakter a 2. síkban 4 bájt méretű.
Mivel ezek a karakterek mind >3 bájt méretűek, a helyettesítő párok megfelelő működését igénylik. Az Azure NetApp Files natív módon támogatja a helyettesítő párokat, de a karakterek megjelenítése a használt protokolltól, az ügyfél területi beállításaitól és a távoli ügyfélelérési alkalmazás beállításaitól függően változik.
UTF-8
Az UTF-8 8 bites kódolást használ, és legfeljebb 1 112 064 kódponttal (vagy karakterekkel) rendelkezhet. Az UTF-8 a Linux-alapú operációs rendszerek összes nyelvének szabványos kódolása. Mivel az UTF-8 8 bites kódolást használ, a legfeljebb aláíratlan egész szám legfeljebb 255 (2^8 – 1), ami egyben a kódolás maximális fájlnévhossza is. Az UTF-8 az internetes oldalak több mint 98%-ában használatos, így messze a legelterjedtebb kódolási szabvány. A Web Hypertext Application Technology Working Group (WHATWG) úgy véli, hogy az UTF-8 "az összes [szöveg] kötelező kódolása", és biztonsági okokból a böngészőalkalmazások nem használhatják az UTF-16-ot.
Az UTF-8 formátumú karakterek mindegyike 1–4 bájtot használ, de az összes nyelv szinte minden karaktere 1 és 3 bájt között van. Ilyenek például a következők:
- Az "A" latin betű 1 bájtot használ. (A 128 fenntartott ASCII-karakter egyike)
- A "©" szerzői jogi szimbólum 2 bájtot használ.
- Az "ä" karakter 2 bájtot használ. (1 bájt az "a" + 1 bájt az umlaut)
- Az adatok japán Kanji szimbóluma (資) 3 bájtot használ.
- A grinning face emoji (😃) 4 bájtot használ.
A nyelvi területi beállítások használhatják a szabványos UTF-8 (C.UTF-8) vagy egy régióspecifikusabb formátumot, például en_US. UTF-8, ja. UTF-8 stb. Amikor csak lehetséges, UTF-8 kódolást kell használnia Linux-ügyfelekhez az Azure NetApp Files elérésekor. Az OS X-hez hasonlóan a macOS-ügyfelek az UTF-8-at is használják az alapértelmezett kódoláshoz, és nem szabad módosítani.
A Windows-ügyfelek UTF-16-ot használnak. A legtöbb esetben ezt a beállítást kell alapértelmezettként hagyni az operációs rendszer területi beállításához, de az újabb ügyfelek bétaverziós támogatást nyújtanak az UTF-8 karakterekhez egy jelölőnégyzeten keresztül. A Windows terminálalkalmazásai igény szerint úgy is módosíthatók, hogy az UTF-8-at használják a PowerShellben vagy a CMD-ben. További információ: Kettős protokoll viselkedése speciális karakterkészletekkel.
UTF-16
Az UTF-16 16 bites kódolást használ, és képes a Unicode 1 112 064 kódpontjának kódolására. Az UTF-16 kódolása egy vagy két 16 bites kódegységet használhat, mindegyik 2 bájt méretű. Az UTF-16 minden karaktere 2 vagy 4 bájt méretű. Az UTF-16 4 bájtot használó karakterei helyettesítő párokat használnak, amelyek két különálló kétbájtos karaktert egyesítenek egy új karakter létrehozásához. Ezek a kiegészítő karakterek a standard BMP síkon kívül esnek, és a többi többnyelvű sík egyikébe kerülnek.
Az UTF-16 windowsos operációs rendszerekben és API-kban, Java-ban és JavaScriptben használatos. Mivel nem támogatja az ASCII formátumokkal való visszamenőleges kompatibilitást, soha nem szerzett népszerűséget a weben. Az UTF-16 csak az internet összes oldalának körülbelül 0,002%-át teszi ki. A Web Hypertext Application Technology Working Group (WHATWG) úgy véli, hogy az UTF-8 "az összes szöveg kötelező kódolása", és azt javasolja, hogy az alkalmazások ne használják az UTF-16-ot a böngésző biztonsága érdekében.
Az Azure NetApp Files a legtöbb UTF-16 karaktert támogatja, beleértve a helyettesítő párokat is. Olyan esetekben, amikor a karakter nem támogatott, a Windows-ügyfelek "a megadott fájlnév érvénytelen vagy túl hosszú" hibaüzenetet jelentenek.
Karakterkészlet kezelése távoli ügyfeleken keresztül
Az Azure NetApp Files-köteteket csatlakoztató ügyfelek távoli kapcsolatai (például az NFS-csatlakoztatások eléréséhez linuxos ügyfelekhez való SSH-kapcsolatok) konfigurálhatók adott kötetnyelvi kódolások küldésére és fogadására. A távoli kapcsolati segédprogramon keresztül az ügyfélnek küldött nyelvi kódolás szabályozza a karakterkészletek létrehozását és megtekintését. Ennek eredményeképpen egy távoli kapcsolat, amely más nyelvi kódolást használ, mint egy másik távoli kapcsolat (például két különböző PuTTY-ablak) különböző eredményeket jeleníthet meg a karakterek esetében, amikor fájl- és mappaneveket sorol fel az Azure NetApp Files-kötetben. A legtöbb esetben ez nem okoz eltéréseket (például latin/angol karakterek esetében), de speciális karakterek, például hangulatjelek esetén az eredmények eltérőek lehetnek.
Ha például az UTF-8 kódolását használja a távoli kapcsolathoz, kiszámítható eredményeket jelenít meg az Azure NetApp Files-kötetekben lévő karakterekre vonatkozóan, mivel a C.UTF-8 a kötet nyelve. Az "data" (資) japán karaktere a terminál által küldött kódolástól függően eltérően jelenik meg.
Karakterkódolás a PuTTY-ban
Ha egy PuTTY-ablak UTF-8-at használ (a Windows fordítási beállításai között található), a karakter megfelelően jelenik meg az Azure NetApp Files NFSv3-ra csatlakoztatott kötetéhez:

Ha a PuTTY-ablak más kódolást használ, például ISO-8859-1:1998 (Latin-1, Nyugat-Európa), ugyanaz a karakter másképp jelenik meg, annak ellenére, hogy a fájl neve ugyanaz.

A PuTTY alapértelmezés szerint nem tartalmaz CJK-kódolásokat. Vannak olyan javítások, amelyek hozzáadják ezeket a nyelvi csoportokat a PuTTY-hoz.
Karakterkódolások a Bastionban
A Microsoft Azure a Bastion használatát javasolja az Azure-beli virtuális gépekhez (virtuális gépekhez) való távoli kapcsolódáshoz. A Bastion használatakor az elküldött és fogadott nyelvi kódolás nem jelenik meg a konfigurációban, de a standard UTF-8 kódolást használja. Ennek eredményeképpen a PuTTY-ban az UTF-8 használatával látott legtöbb karakterkészletnek a Bastionban is láthatónak kell lennie, feltéve, hogy a használt protokoll támogatja a karakterkészleteket.

Tipp.
Más SSH-terminálok is használhatók, például a TeraTerm. A TeraTerm alapértelmezés szerint a támogatott karakterkészletek szélesebb körét biztosítja, beleértve a CJK-kódolásokat és a nem szabványos kódolásokat, például a Shift-JIS-t.
Protokollviselkedések speciális karakterkészletekkel
Az Azure NetApp Files-kötetek UTF-8 kódolást használnak, és natív módon támogatják a 3 bájtot meg nem haladó karaktereket. Az ASCII és az UTF-8 készlet összes karaktere megfelelően jelenik meg, mert az 1–3 bájtos tartományba esik. Példa:
- Az "A" latin betűs betű 1 bájtot használ (a 128 fenntartott ASCII-karakter egyike).
- A szerzői jogi szimbólumok © 2 bájtot használnak.
- Az "ä" karakter 2 bájtot használ (1 bájt az "a" és 1 bájt az umlaut esetében).
- Az adatok japán Kanji szimbóluma (資) 3 bájtot használ.
Az Azure NetApp Files emellett támogatja a 3 bájtot meghaladó karaktereket helyettesítő párlogikával (például emojival), feltéve, hogy az ügyfél kódolása és protokollverziója támogatja őket. A protokoll viselkedéséről további információt a következő témakörben talál:
SMB-viselkedések
Az SMB-kötetekben az Azure NetApp Files két nevet hoz létre és tart fenn minden olyan könyvtárban, amely SMB-ügyfélről rendelkezik hozzáféréssel: az eredeti hosszú név és egy 8.3 formátumú név.
Fájlnevek az SMB-ben az Azure NetApp Files használatával
Ha a fájl- vagy könyvtárnevek túllépik az engedélyezett karakterbájtokat, vagy nem támogatott karaktereket használnak, az Azure NetApp Files a következőképpen hoz létre 8,3 formátumú nevet:
- Csonkolja az eredeti fájl vagy könyvtár nevét.
- Egy tilde (~) és egy szám (1-5) hozzáfűzi azokat a fájl- vagy könyvtárneveket, amelyek csonkítás után már nem egyediek. Ha ötnél több, nemunique nevű fájl van, az Azure NetApp Files létrehoz egy egyedi nevet, amely nem áll kapcsolatban az eredeti névvel. Fájlok esetén az Azure NetApp Files három karakterre csonkolja a fájlnévkiterjesztést.
Ha például egy NFS-ügyfél létrehoz egy fájlt, specifications.htmlaz Azure NetApp Files a 8.3 formátumot követve hozza létre a fájlnevet specif~1.htm . Ha ez a név már létezik, az Azure NetApp Files egy másik számot használ a fájlnév végén. Ha például egy NFS-ügyfél létrehoz egy másik fájlt, specifications\_new.htmlakkor a 8.3 formátuma specifications\_new.html az .specif~2.htm
Különleges karakter az SMB-ben az Azure NetApp Files használatával
Ha SMB-t használ az Azure NetApp Files-kötetekkel, a helyettesítő párok támogatása miatt a fájl- és mappanevekben használt 3 bájtot meghaladó karakterek (beleértve a hangulatjeleket is) engedélyezettek. A Windows Intéző a következőt látja a BMP-n kívüli karakterek esetében egy Windows-ügyfélből létrehozott mappában, amikor az alapértelmezett UTF-16 kódolású angol nyelvet használja.
Feljegyzés
A Windows Explorer alapértelmezett betűtípusa a Segoe felhasználói felület. A betűtípus-módosítások hatással lehetnek arra, hogy egyes karakterek hogyan jelenjenek meg az ügyfeleken.

Az ügyfélen megjelenő karakterek a rendszer betűtípusától, a nyelvtől és a területi beállításoktól függenek. A BMP-be tartozó karakterek általában minden protokollban támogatottak, függetlenül attól, hogy a kódolás UTF-8 vagy UTF-16.
CMD vagy PowerShell használatakor a karakterkészlet megjelenítése a betűtípus beállításaitól függ. Ezek a segédprogramok alapértelmezés szerint korlátozott betűkészlet-beállításokkal rendelkeznek. A CMD a Consolast használja alapértelmezett betűtípusként.
Előfordulhat, hogy a fájlnevek nem a várt módon jelennek meg a használt betűtípustól függően, mivel egyes konzolok nem támogatják natív módon a Segoe felhasználói felületét vagy más, speciális karaktereket megfelelően megjelenítő betűtípusokat.
Ez a probléma Windows-ügyfeleken a PowerShell ISE használatával oldható meg, amely robusztusabb betűtípus-támogatást nyújt. Ha például a PowerShell ISE-t Segoe felhasználói felületre állítja, akkor a fájlnevek megfelelően jelennek meg támogatott karakterekkel.

A PowerShell ISE azonban a megosztások kezelése helyett szkriptelésre lett tervezve. Az újabb Windows-verziók a Windows Terminált kínálják, amely lehetővé teszi a betűtípusok és a kódolási értékek vezérlését.
Feljegyzés
chcp A parancs használatával megtekintheti a terminál kódolását. A kódlapok teljes listáját a Kódoldal-azonosítók című témakörben találja.

Ha a kötet engedélyezve van a kettős protokollhoz (NFS és SMB esetén is), különböző viselkedéseket figyelhet meg. További információ: Kettős protokoll viselkedése speciális karakterkészletekkel.
NFS-viselkedések
Az NFS speciális karakterek megjelenítésének módjától függ a használt NFS verziója, az ügyfél területi beállításai, a telepített betűtípusok és a használt távoli kapcsolati ügyfél beállításai. Ha például a Bastion használatával fér hozzá egy Ubuntu-ügyfélkezelő karakterhez, az eltérő módon jelenik meg, mint egy PuTTY-ügyfél, amely ugyanazon a virtuális gépen egy másik területi beállításra van beállítva. A következő NFS-példák az Ubuntu virtuális gép területi beállításaira támaszkodnak:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3 viselkedés
Az NFSv3 nem kényszeríti ki az UTF-kódolást a fájlokon és mappákon. A legtöbb esetben a speciális karakterkészletek nem lehetnek problémák. A használt kapcsolati ügyfél azonban befolyásolhatja a karakterek küldését és fogadását. Ha például a BMP-n kívüli Unicode-karaktereket használ egy mappanévhez az Azure connection client Bastionban, az az ügyfélkódolás működése miatt váratlan viselkedést eredményezhet.
Az alábbi képernyőképen a Bastion nem tudja másolni és beilleszteni az értékeket a parancssori felületre a böngészőn kívülről, amikor címtárat nevez el az NFSv3-on keresztül. Az érték másolása és beillesztésekor NFSv3Bastion𓀀𫝁😃𐒸a speciális karakterek idézőjelekként jelennek meg a bemenetben.

A másolás-beillesztés parancs engedélyezett az NFSv3-n keresztül, de a karakterek numerikus értékekként jönnek létre, ami hatással van a megjelenítésükre:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Ez a megjelenítés a Bastion által a szövegértékek másoláskor és beillesztéskor történő küldéséhez használt kódolásnak köszönhető.
Ha a PuTTY használatával olyan mappát hoz létre, amely ugyanazokkal a karakterekkel rendelkezik az NFSv3-ban, a mappa neve nem más, mint a Bastionban, mint amikor a Bastiont használták a létrehozáshoz. A hangulatjel a várt módon jelenik meg (a telepített betűtípusok és a területi beállítás miatt), de a többi karakter (például az Osage "𐒸") nem.

Egy PuTTY-ablakban a karakterek helyesen jelennek meg:

NFSv4.x viselkedés
Az NFSv4.x az RFC-8881 nemzetköziesítési specifikációk szerint kényszeríti az UTF-8 kódolást a fájl- és mappanevekben.
Ennek eredményeképpen, ha egy speciális karaktert nem UTF-8 kódolással küldenek, előfordulhat, hogy az NFSv4.x nem engedélyezi az értéket.
Bizonyos esetekben a parancsok az Alapszintű többnyelvű síkon (BMP) kívül is használhatók, de előfordulhat, hogy a parancs létrehozása után nem jeleníti meg az értéket.
Például a "𓀀𫝁mkdir𐒸" karaktereket tartalmazó mappanév (a kiegészítő többnyelvű síkok (SMP) és a 😃) karaktereinek kiadása sikeresnek tűnik az NFSv4.x-ben. A mappa nem lesz látható a ls parancs futtatásakor.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
A mappa megtalálható a kötetben. A rejtett könyvtárnévre való váltás a PuTTY-ügyfélről működik, és a könyvtáron belül is létrehozhat egy fájlt.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
A PuTTY stat parancsa azt is megerősíti, hogy a mappa létezik:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Annak ellenére, hogy a mappa létezik, a helyettesítő karakterek parancsai nem működnek, mivel az ügyfél hivatalosan nem tudja "látni" a mappát a kijelzőn.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
Az NFSv4.1 hibát küld az ügyfélnek, ha olyan karakterrel találkozik, amely nem támaszkodik UTF-8 kódolásra.
Ha például a Bastion használatával próbál hozzáférni ahhoz a könyvtárhoz, amelyet a PuTTY használatával hoztunk létre az NFSv4.1-en keresztül, ez az eredmény:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL RFC-8881 vonatkozik.
Mivel a mappa elérhető a PuTTY-ból (az elküldött és fogadott kódolás miatt), a név megadása után másolható. Miután átmásolta a mappát az NFSv4.1 Azure NetApp Files-kötetről az NFSv3 Azure NetApp Files-kötetre, megjelenik a mappa neve:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
Ugyanez NFS4ERR\_INVAL a hiba akkor jelenik meg, ha a rendszer nem UTF-8 formátumú fájlkonvertálást (például Shift-JIS) kísérel meg.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
További információ: Fájlok konvertálása különböző kódolásokra.
Kettős protokoll viselkedése
Az Azure NetApp Files lehetővé teszi, hogy az NFS és az SMB kétprotokollos hozzáféréssel is hozzáférjen a kötetekhez. Az NFS (UTF-8) és az SMB (UTF-16) által használt nyelvkódolási különbségek miatt a karakterkészletek, a fájl- és mappanevek, valamint az elérési utak hossza nagyon eltérő viselkedést mutathat a protokollok között.
NFS által létrehozott fájlok és mappák megtekintése az SMB-ből
Ha az Azure NetApp Files kétprotokollos hozzáféréshez (SMB és NFS) használatos, az UTF-16 által nem támogatott karakterkészletek az UTF-8 használatával NFS-en keresztül létrehozott fájlnévben használhatók. Ezekben az esetekben, amikor az SMB nem támogatott karaktereket tartalmazó fájlhoz fér hozzá, a rendszer csonkolja a nevet az SMB-ben a 8.3-as rövid fájlnév-konvencióval.
NFSv3 által létrehozott fájlok és SMB-viselkedések karakterkészletekkel
Az NFSv3 nem kényszeríti az UTF-8 kódolást. A nem szabványos nyelvi kódolást (például Shift-JIS) használó karakterek az Azure NetApp Files használatával működnek az NFSv3 használatakor.
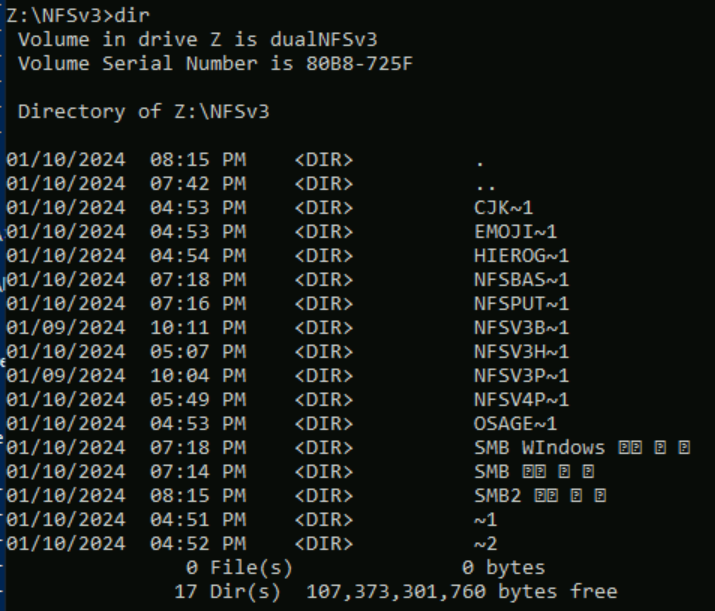
Az alábbi példában a Unicode különböző síkjainak különböző karakterkészleteit használó mappanevek sorozata egy Azure NetApp Files-kötetben jött létre az NFSv3 használatával. Az NFSv3-ból való megtekintéskor ezek megfelelően jelennek meg.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
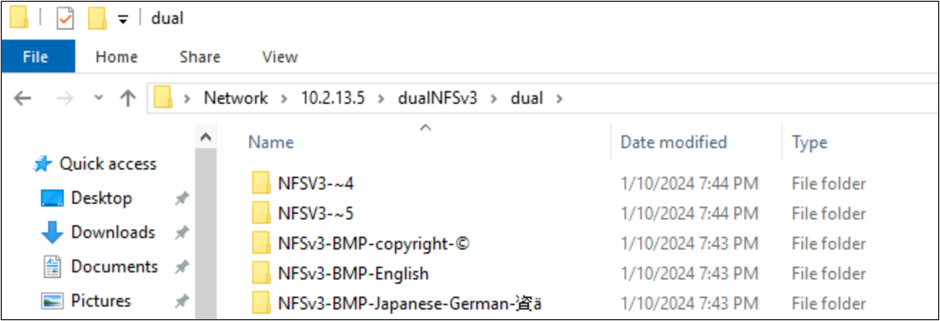
A Windows SMB-ben a BMP-ben található karaktereket tartalmazó mappák megfelelően jelennek meg, de a síkon kívüli karakterek a 8.3-as névformátummal jelennek meg, mivel az UTF-8/UTF-16 átalakítás nem kompatibilis ezekhez a karakterekhez.
NFSv4.1 által létrehozott fájlok és SMB-viselkedések karakterkészletekkel
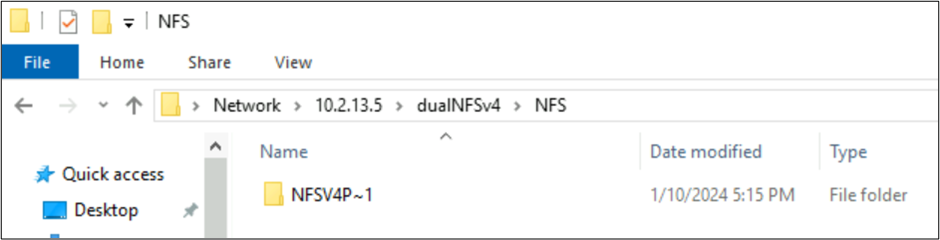
Az előző példákban egy NFSv4.1-en keresztül létrehozott egy azure NetApp Files-köteten elnevezett NFSv4 Putty 𓀀𫝁😃𐒸 mappát, de nem volt megtekinthető az NFSv4.1 használatával. Az SMB használatával azonban látható. A név SMB-ben csonkolva van egy támogatott 8.3-as formátumra az NFS-ügyfél által létrehozott nem támogatott karakterkészletek és a különböző Unicode-síkokban lévő karakterek inkompatibilis UTF-8/UTF-16 konvertálása miatt.
Ha egy mappanév szabványos UTF-8 karaktert használ a BMP-ben (angol vagy más módon), akkor az SMB megfelelően lefordítja a neveket.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
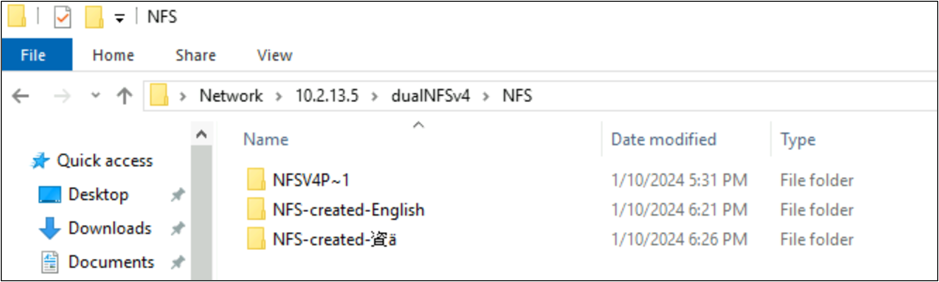
SMB által létrehozott fájlok és mappák az NFS-en keresztül
A Windows-ügyfelek az SMB-megosztások eléréséhez használt elsődleges ügyfelek. Ezek az ügyfelek alapértelmezés szerint UTF-16 kódolást használnak. A windowsos UTF-8 kódolt karakterek támogatása a régióbeállításokban való engedélyezésével lehetséges:
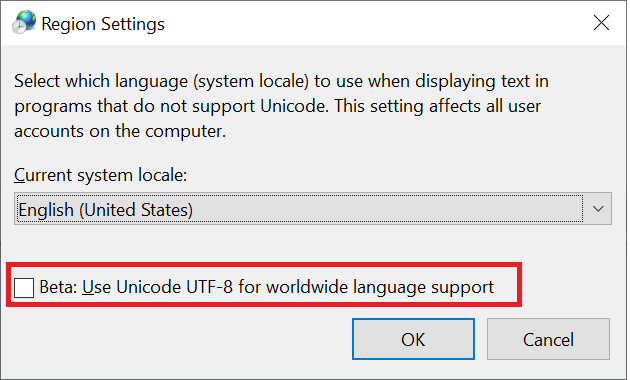
Ha egy fájl vagy mappa SMB-megosztáson keresztül jön létre az Azure NetApp Filesban, a karakterkészlet UTF-16-ként kódol. Emiatt előfordulhat, hogy az UTF-8 kódolást használó ügyfelek (például Linux-alapú NFS-ügyfelek) nem tudják megfelelően lefordítani bizonyos karakterkészleteket – különösen az alapszintű többnyelvű síkon (BMP) kívül eső karaktereket.
Nem támogatott karakter viselkedése
Ezekben az esetekben, amikor egy NFS-ügyfél nem támogatott karaktereket tartalmazó SMB használatával létrehozott fájlt ér el, a név numerikus értékek sorozataként jelenik meg, amelyek a karakter Unicode-értékeit jelölik.
Ezt a mappát például a Windows Intézőben hozták létre a BMP-n kívüli karakterek használatával.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
NFSv3-n keresztül megjelenik az SMB által létrehozott mappa:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Az NFSv4.1-en keresztül az SMB által létrehozott mappa a következőképpen jelenik meg:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Támogatott karakter viselkedése
Ha a karakterek a BMP-ben vannak, az SMB és az NFS protokollok és azok verziói között nincs probléma.
Egy Azure NetApp Files-kötet SMB használatával létrehozott mappaneve például több nyelven (angol, német, cirill, runic) található karaktereket tartalmaz a BMP-ben.
- Egyszerű latin "SMB"
- Görög "ͶΘΩ"
- Cirill "ЁЄЊ"
- Rúnák "ᚠᚱᛯ"
- CJK kompatibilitási ideográfok "豈滑虜"
Így jelenik meg a név az SMB-ben:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Így jelenik meg a név az NFSv3-ból:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Így jelenik meg a név az NFSv4.1-ből:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Fájlok konvertálása különböző kódolásokra
A fájl- és mappanevek nem csak a fájlrendszer-objektumok nyelvi kódolást használó részei. A fájl tartalma (például egy szövegfájl speciális karakterei) is szerepet játszhatnak. Ha például egy fájlt nem kompatibilis formátumban kísérel meg speciális karakterekkel menteni, hibaüzenet jelenhet meg. Ebben az esetben a Katagana-karaktereket tartalmazó fájl nem menthető az ANSI-ben, mivel ezek a karakterek nem léteznek ebben a kódolásban.
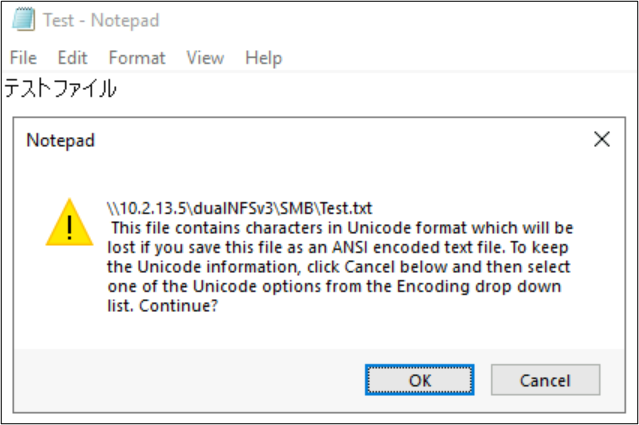
Miután a fájlt ebben a formátumban mentette, a karakterek kérdőjelekké alakulnak:
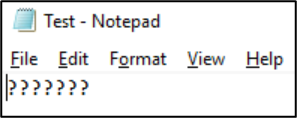
A fájlkódolások a NAS-ügyfelekről tekinthetők meg. Windows-ügyfeleken egy olyan alkalmazást használhat, mint a Jegyzettömb vagy a Jegyzettömb++ egy fájl kódolásának megtekintéséhez. Ha Linuxos Windows-alrendszer (WSL) vagy Git van telepítve az ügyfélen, a file parancs használható.
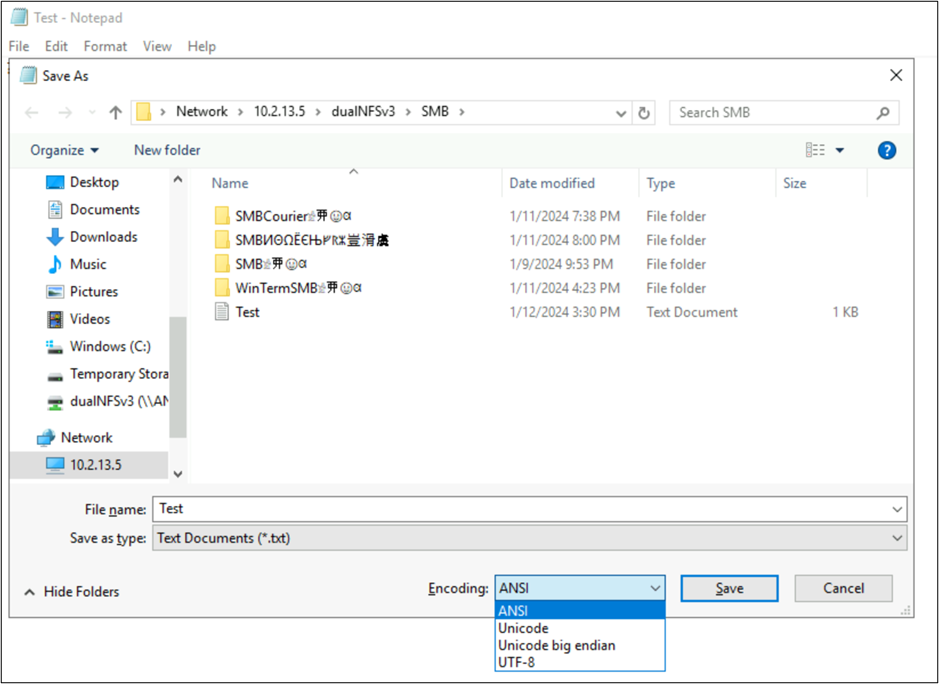
Ezek az alkalmazások lehetővé teszik a fájl kódolásának módosítását is különböző kódolási típusokként való mentéssel. Emellett a PowerShell használható a kódolás konvertálására a parancsmagokkal és Get-Content a Set-Content parancsmagokkal rendelkező fájlokon.
A fájl utf8-text.txt például UTF-8 kódolású, és a BMP-n kívüli karaktereket tartalmaz. Az UTF-8 használata miatt a karakterek megfelelően jelennek meg.
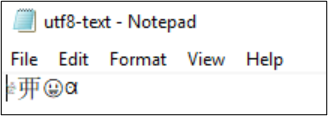
Ha a kódolás UTF-32 formátumra van konvertálva, a karakterek nem jelennek meg megfelelően.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
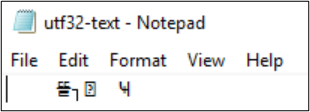
Get-Content a fájl tartalmának megjelenítésére is használható. A PowerShell alapértelmezés szerint UTF-16 kódolást használ (kódlap 437), és a konzol betűtípus-beállításai korlátozottak, így a speciális karaktereket tartalmazó UTF-8 formátumú fájl nem jeleníthető meg megfelelően:
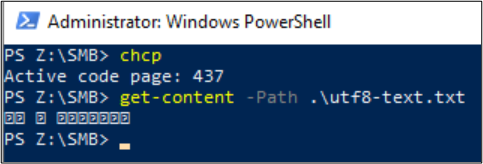
A Linux-ügyfelek a file parancs használatával megtekinthetik a fájl kódolását. Kétprotokollos környezetekben, ha egy fájl SMB használatával jön létre, a Linux-ügyfél NFS használatával ellenőrizheti a fájlkódolást.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
A fájlkódolás konvertálása Linux-ügyfeleken a parancs használatával iconv végezhető el. A támogatott kódolási formátumok listájának megtekintéséhez használja iconv -la következőt: .
Az UTF-8 kódolt fájl például UTF-16-ra konvertálható.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Ha a fájl nevére vagy tartalmára beállított karaktert a célkódolás nem támogatja, akkor a konvertálás nem engedélyezett. A Shift-JIS például nem támogatja a fájl tartalmában szereplő karaktereket.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Ha egy fájl olyan karakterekkel rendelkezik, amelyeket a kódolás támogat, az átalakítás sikeres lesz. Ha például a fájl tartalmazza a Katagana-karaktereket テストファイル, akkor a Shift-JIS konvertálása sikeres lesz az NFS-en keresztül. Mivel az itt használt NFS-ügyfél nem érti a Shift-JIS-t a területi beállítások miatt, a kódolás az "ismeretlen-8bit" értéket jeleníti meg.
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Mivel az Azure NetApp Files-kötetek csak az UTF-8-kompatibilis formázást támogatják, a Katagana-karakterek olvashatatlan formátumba lesznek konvertálva.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
NFSv4.x használatakor az átalakítás akkor engedélyezett, ha nem kompatibilis karakterek találhatók a fájl tartalmában, annak ellenére, hogy az NFSv4.x kényszeríti az UTF-8 kódolást. Ebben a példában egy UTF-8 kódolt fájl katagana karakterekkel, amely egy Azure NetApp Files-köteten található, megfelelően jeleníti meg a fájl tartalmát.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
A konvertálás után azonban a fájlban lévő karakterek helytelenül jelennek meg a nem kompatibilis kódolás miatt.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Ha a fájl neve nem támogatott karaktereket tartalmaz az UTF-8-hoz, akkor az átalakítás az NFSv3 protokollal sikeres, de az NFSv4.x protokollverzió UTF-8 kényszerítése miatt meghiúsul.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Ajánlott eljárások a karakterkészlethez
Ha az Azure NetApp Files-köteteken a szabványos többnyelvű síkon (BMP) kívül speciális karaktereket vagy karaktereket használ, figyelembe kell venni néhány ajánlott eljárást.
- Mivel az Azure NetApp Files-kötetek UTF-8 kötetnyelvet használnak, az NFS-ügyfelek fájlkódolásának UTF-8 kódolást is kell használnia a konzisztens eredmények érdekében.
- A fájlnevekben vagy a fájltartalomban található karakterkészletek UTF-8 kompatibilisnek kell lenniük a megfelelő megjelenítéshez és működéshez.
- Mivel az SMB UTF-16 karakterkódolást használ, előfordulhat, hogy a BMP-n kívüli karakterek nem jelennek meg megfelelően az NFS-en keresztül kétprotokollos kötetekben. Lehetőség szerint minimalizálja a speciális karakterek használatát a fájl tartalmában.
- Ne használjon speciális karaktereket a BMP-n kívül a fájlnevekben, különösen akkor, ha NFSv4.1 vagy kettős protokollú köteteket használ.
- A BMP-ben nem szereplő karakterkészletek esetében az UTF-8 kódolásnak lehetővé kell tenni a karakterek megjelenítését az Azure NetApp Filesban egyetlen fájlprotokoll használata esetén (csak SMB vagy csak NFS esetén). A kétprotokollos kötetek azonban a legtöbb esetben nem tudják befogadni ezeket a karakterkészleteket.
- A nem szabványos kódolás (például a Shift-JIS) nem támogatott az Azure NetApp Files-köteteken.
- A helyettesítő pár karakterei (például az emoji) támogatottak az Azure NetApp Files-köteteken.