Manage file space for databases in Azure SQL Database
A következőre vonatkozik:![]() Azure SQL Database
Azure SQL Database
Ez a cikk az Azure SQL Database-ben található adatbázisok különböző tárolási típusait ismerteti, valamint azokat a lépéseket, amelyek akkor végezhetők el, amikor a lefoglalt fájlterületet explicit módon kell kezelni.
Áttekintés
Az Azure SQL Database-ben vannak olyan számítási feladatok, amelyekben az adatbázisok alapjául szolgáló adatfájlok kiosztása nagyobb lehet, mint a használt adatlapok száma. Ez a feltétel akkor fordulhat elő, ha a felhasznált terület növekszik, és az adatok később törlődnek. Az oka pedig az, hogy a lefoglalt fájlterület nem szabadul fel automatikusan az adatok törlésekor.
A következő esetekben szükség lehet a fájlterület használatának monitorozására és az adatfájlok zsugorítására:
- Ha lehetővé szeretné tenni egy rugalmas készletben található adatmennyiség növelését, ha az adatbázisokhoz lefoglalt fájlterület eléri a készlet maximális méretét.
- Ha lehetővé szeretné tenni egy önálló adatbázis vagy rugalmas készlet maximális méretének csökkentését.
- Ha lehetővé szeretné tenni egy önálló adatbázis vagy rugalmas készlet módosítását egy másik, kisebb maximális méretű szolgáltatási vagy teljesítményszintre.
Megjegyzés:
A zsugorítási műveletek nem tekinthetők rendszeres karbantartási műveletnek. A rendszeres, ismétlődő üzleti műveletek miatt növekvő adat- és naplófájlok nem igényelnek zsugorítási műveleteket.
A fájlterület használatának monitorozása
Az alábbi API-kban megjelenített tárterület-metrikák többsége csak a használt adatlapok méretét méri:
- Azure Resource Manager-alapú metrikák API-k, beleértve a PowerShell get-metricst
Az alábbi API-k viszont az adatbázisok és rugalmas készletek számára lefoglalt terület méretét is mérik:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
Az adatbázis tárhelytípusainak ismertetése
Az adatbázis fájlterületének kezeléséhez fontos a következő tárterület-mennyiségek ismerete.
| Az adatbázis mennyisége | Definíció | Megjegyzések |
|---|---|---|
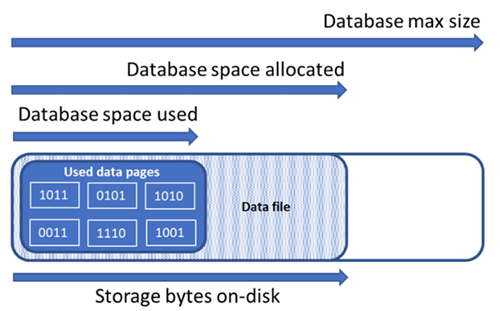
| Felhasznált adattér | Az adatbázisadatok tárolására használt terület. | A felhasznált terület általában nő (csökken) a beszúrásokon (törléseken). Bizonyos esetekben a felhasznált terület nem változik a beszúrások és törlések esetében a műveletben érintett adatok mennyiségétől és mintájától, valamint a töredezettségtől függően. Ha például minden adatoldalról töröl egy sort, az nem feltétlenül csökkenti a felhasznált területet. |
| Lefoglalt adattér | Az adatbázisadatok tárolásához elérhetővé tett formátumfájl területének mennyisége. | A lefoglalt terület mennyisége automatikusan nő, de a törlés után soha nem csökken. Ez a viselkedés biztosítja, hogy a jövőbeli beszúrások gyorsabbak legyenek, mivel a helyet nem kell újraformálni. |
| Lefoglalt, de nem használt adatterület | A lefoglalt és a felhasznált adatterület közötti különbség. | Ez a mennyiség az adatbázis-adatfájlok zsugorításával visszanyerhető szabad terület maximális mennyiségét jelöli. |
| Adat maximális mérete | Az adatbázisadatok tárolására használható maximális terület. | A lefoglalt adatterület nem haladhatja meg a maximális adatméretet. |
Az alábbi ábra az adatbázis különböző tárolási típusai közötti kapcsolatot szemlélteti.
Egyetlen adatbázis lekérdezése fájltérinformációkhoz
A sys.database_files a következő lekérdezés használatával adja vissza a lefoglalt adatbázisfájl-területet és a lefoglalt fel nem használt területet. A lekérdezés eredményeinek mértékegysége a MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
A rugalmas készlet tárterület-típusainak megismerése
A rugalmas készlet fájlterületének kezeléséhez fontos a következő tárterület-mennyiségek ismerete.
| Rugalmas készlet mennyisége | Definíció | Megjegyzések |
|---|---|---|
| Felhasznált adattér | A rugalmas készletben található összes adatbázis által használt adatterület összege. | |
| Lefoglalt adattér | A rugalmas készletben található összes adatbázis által lefoglalt adatterület összege. | |
| Lefoglalt, de nem használt adatterület | A rugalmas készletben található összes adatbázis által lefoglalt és felhasznált adatterület összege közötti különbség. | Ez a mennyiség az adatbázis-adatfájlok zsugorításával visszanyerhető rugalmas készlet számára lefoglalt maximális területet jelöli. |
| Adat maximális mérete | A rugalmas készlet által az összes adatbázishoz használható maximális adatterület. | A rugalmas készlet számára lefoglalt terület nem haladhatja meg a rugalmas készlet maximális méretét. Ha ez a feltétel jelentkezik, akkor az adatbázis-adatfájlok zsugorításával visszaigényelhető a nem használt terület. |
Megjegyzés:
A "A rugalmas készlet elérte a tárterületkorlátot" hibaüzenet azt jelzi, hogy az adatbázis-objektumok elegendő helyet foglalnak le a rugalmas készlet tárterületkorlátjának teljesítéséhez, de előfordulhat, hogy az adatterület-kiosztásban nem használt terület található. Fontolja meg a rugalmas készlet tárterületkorlátjának növelését, vagy rövid távú megoldásként az adatterület felszabadítását a reclaim fel nem használt lefoglalt terület mintáival. Tisztában kell lennie az adatbázisfájlok zsugorításának lehetséges negatív teljesítménybeli hatásával is, lásd : Indexkarbantartás zsugorodás után.
Rugalmas készlet lekérdezése a tárterület adataihoz
Az alábbi lekérdezések segítségével meghatározható a rugalmas készlethez kapcsolódó tárterület mennyisége.
Rugalmas készlet felhasznált adatterülete
Módosítsa a következő lekérdezést a felhasznált rugalmas készlet adatterületének visszaadásához. A lekérdezés eredményeinek mértékegysége a MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Kiosztott rugalmas készlet adatterülete és kihasználatlan lefoglalt terület
Módosítsa az alábbi példákat, hogy visszaadjon egy táblát, amely felsorolja a rugalmas készletben lévő adatbázisokhoz lefoglalt és fel nem használt lefoglalt területet. A tábla azokat az adatbázisokat rendeli el ezektől az adatbázisoktól, amelyekben a legnagyobb mennyiségű fel nem használt lefoglalt terület a legkisebb kihasználatlan lefoglalt terület. A lekérdezés eredményeinek mértékegysége a MB.
A lekérdezés eredményei a készlet egyes adatbázisai számára lefoglalt terület meghatározásához összeadhatók a rugalmas készlethez lefoglalt teljes terület meghatározásához. A lefoglalt rugalmas készletterület nem haladhatja meg a rugalmas készlet maximális méretét.
Fontos
A PowerShell Azure Resource Manager modult továbbra is támogatja az Azure SQL Database, de minden jövőbeli fejlesztés az Az.Sql modulhoz tartozik. Az AzureRM-modul legalább 2020 decemberéig továbbra is megkapja a hibajavításokat. Az Az modulban és az AzureRm-modulokban található parancsok argumentumai lényegében azonosak. A kompatibilitásukról további információt az új Azure PowerShell Az modul bemutatása című témakörben talál.
A PowerShell-szkripthez SQL Server PowerShell-modul szükséges – a telepítéshez lásd a PowerShell-modul letöltését.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Az alábbi képernyőkép egy példa a szkript kimenetére:

Rugalmas készlet adatainak maximális mérete
Módosítsa a következő T-SQL-lekérdezést az utolsó rögzített rugalmas készletadatok maximális méretének visszaadásához. A lekérdezés eredményeinek mértékegysége a MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Reclaim unused allocated space
Fontos
A zsugorítási parancsok hatással vannak az adatbázis-teljesítményre a futtatásuk során, és lehetőség szerint alacsony használatú időszakokban ajánlott futtatni őket.
Adatfájlok zsugorítása
Az adatbázis teljesítményére gyakorolt lehetséges hatás miatt az Azure SQL Database nem zsugorítja automatikusan az adatfájlokat. Az ügyfelek azonban önkiszolgáló szolgáltatással csökkenthetik az adatfájlokat a választott időpontban. Ez nem lehet rendszeres ütemezett művelet, hanem egy egyszeri esemény, amely a felhasznált adatfájlok jelentős csökkenésére reagál.
Tipp.
Nem javasolt csökkenteni az adatfájlok méretét, ha az alkalmazás általános működése során a fájlok mérete ismét megnő, és ugyanannyi lefoglalt területet fognak igényelni.
Az Azure SQL Database-ben a fájlok zsugorításához használhatja a DBCC SHRINKFILE következő parancsokat:DBCC SHRINKDATABASE
DBCC SHRINKDATABASEegyetlen paranccsal zsugorítja az adatbázis összes adatát és naplófájljait. A parancs egyszerre egy adatfájlt zsugorítja, ami hosszabb időt vehet igénybe a nagyobb adatbázisok esetében. Emellett zsugorítja a naplófájlt, ami általában szükségtelen, mivel az Azure SQL Database szükség szerint automatikusan zsugorítja a naplófájlokat.DBCC SHRINKFILEa parancs speciálisabb forgatókönyveket támogat:- Szükség szerint meg tudja célozni az egyes fájlokat, nem pedig az adatbázis összes fájljának zsugorítását.
- Minden
DBCC SHRINKFILEparancs párhuzamosan futtatható másDBCC SHRINKFILEparancsokkal, hogy egyszerre több fájlt zsugorítsen, és csökkentse a zsugorodás teljes idejét, a nagyobb erőforrás-használat és a felhasználói lekérdezések blokkolásának nagyobb esélye mellett, ha a zsugorodás során hajtják végre őket. - Ha a fájl farka nem tartalmaz adatokat, sokkal gyorsabban csökkentheti a lefoglalt fájlméretet az
TRUNCATEONLYargumentum megadásával. Ehhez nincs szükség a fájlon belüli adatáthelyezésre.
- Ezekről a zsugorítási parancsokról további információt a DBCC SHRINKDATABA Standard kiadás és a DBCC SHRINKFILE című témakörben talál.
Az alábbi példákat a célfelhasználói adatbázishoz való csatlakozáskor kell végrehajtani, nem pedig az adatbázishoz master .
DBCC SHRINKDATABASE Egy adott adatbázis összes adatának és naplófájljának zsugorítása:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
Az Azure SQL Database-ben előfordulhat, hogy egy adatbázis egy vagy több adatfájllal rendelkezik, amelyek az adatok növekedésével automatikusan létrejönnek. Az adatbázis fájlelrendezésének meghatározásához, beleértve az egyes fájlok használt és lefoglalt méretét, az alábbi példaszkripttel kérdezheti le a sys.database_files katalógusnézetet:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
A zsugorítást csak egy fájlon keresztül hajthatja végre, DBCC SHRINKFILE például:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Vegye figyelembe az adatbázisfájlok zsugorításának lehetséges negatív teljesítményhatását, lásd : Indexkarbantartás zsugorodás után.
Tranzakciónapló-fájl zsugorítása
Az adatfájlokkal ellentétben az Azure SQL Database automatikusan zsugorítja a tranzakciónapló-fájlt a túlzott területhasználat elkerüléséhez, ami a nem elegendő terület miatti hibákhoz vezethet. Az ügyfeleknek általában nem kell zsugorítaniuk a tranzakciónapló-fájlt.
Prémium és üzletileg kritikus szolgáltatási szinteken, ha a tranzakciónapló nagy lesz, jelentősen hozzájárulhat a helyi tárterület-felhasználáshoz a maximális helyi tárterület-korlát felé. Ha a helyi tárterület-felhasználás megközelíti a korlátot, az ügyfelek dönthetnek úgy, hogy a DBCC SHRINKFILE paranccsal csökkentik a tranzakciónaplót, ahogy az az alábbi példában látható. Ez a parancs befejeződése után azonnal felszabadítja a helyi tárolót, anélkül, hogy várnia kell az automatikus automatikus zsugorítási műveletre.
Az alábbi példát a célfelhasználói adatbázishoz való csatlakozáskor kell végrehajtani, nem az adatbázishoz master .
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Automatikus zsugorodás
Az adatfájlok manuális zsugorításának alternatívaként az automatikus zsugorodás engedélyezhető egy adatbázishoz. Az automatikus zsugorodás azonban kevésbé lehet hatékony a fájlterület és a DBCC SHRINKDATABASE DBCC SHRINKFILE.
Alapértelmezés szerint az automatikus zsugorodás le van tiltva, ami a legtöbb adatbázis esetében ajánlott. Ha szükségessé válik az automatikus zsugorodás engedélyezése, javasoljuk, hogy tiltsa le a helykezelési célok elérése után, ahelyett, hogy véglegesen engedélyezve lenne. For more information, see Considerations for AUTO_SHRINK.
Az automatikus zsugorodás például abban az esetben lehet hasznos, ha egy rugalmas készlet sok olyan adatbázist tartalmaz, amelyek jelentős növekedést és a felhasznált adatfájlterület csökkenését tapasztalják, ami miatt a készlet eléri a maximális méretkorlátot. Ez nem gyakori forgatókönyv.
Az automatikus zsugorítás engedélyezéséhez hajtsa végre a következő parancsot, miközben csatlakozik az adatbázishoz (nem az master adatbázishoz).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
A parancsról további információt a DATABA Standard kiadás Standard kiadás T beállításaiban talál.
Indexkarbantartás zsugorodás után
Az adatfájlokon végzett zsugorítási művelet után az indexek töredezetté válhatnak. Ez csökkenti a teljesítményoptimalizálás hatékonyságát bizonyos számítási feladatok, például a nagy vizsgálatokat használó lekérdezések esetében. Ha a teljesítménycsökkenés a zsugorítási művelet befejezése után következik be, fontolja meg az indexkarbantartást az indexek újraépítéséhez. Ne feledje, hogy az index-újraépítések szabad helyet igényelnek az adatbázisban, ezért a lefoglalt terület növekedhet, ami ellensúlyozza a zsugorodás hatását.
Az indexkarbantartásról további információt az indexkarbantartás optimalizálása a lekérdezési teljesítmény javítása és az erőforrás-felhasználás csökkentése érdekében című témakörben talál.
Nagyméretű adatbázisok zsugorítása
Ha az adatbázis lefoglalt területe több száz gigabájt vagy nagyobb, a zsugorodás jelentős időt igényelhet, gyakran órákban vagy napokban mérve több terabájtos adatbázisok esetében. Vannak olyan folyamatoptimalizálások és ajánlott eljárások, amelyek segítségével hatékonyabbá és kevésbé befolyásolhatóvá teheti ezt a folyamatot az alkalmazás számítási feladatai számára.
A területhasználat alapkonfigurációinak rögzítése
A zsugorítás megkezdése előtt rögzítse az aktuálisan használt és lefoglalt területet az egyes adatbázisfájlokban a következő területhasználati lekérdezés végrehajtásával:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
A zsugorítás befejezése után ismét végrehajthatja ezt a lekérdezést, és összehasonlíthatja az eredményt a kezdeti alapkonfigurációval.
Adatfájlok csonkálása
Javasoljuk, hogy először hajtsa végre a zsugorítást a TRUNCATEONLY paraméterrel rendelkező összes adatfájl esetében. Így, ha a fájl végén van lefoglalt, de nem használt terület, a rendszer gyorsan és adatátvitel nélkül eltávolítja azt. Az alábbi mintaparancs csonkolja az adatfájlt a 4. file_id:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Ha ezt a parancsot minden adatfájlhoz végrehajtja, újrafuttathatja a területhasználati lekérdezést, hogy láthassa a lefoglalt terület csökkenését, ha van ilyen. Az azure portalon megtekintheti az adatbázis lefoglalt területét is.
Indexlap sűrűségének kiértékelése
Ha az adatfájlok csonkolása nem eredményezte a lefoglalt terület megfelelő csökkenését, az adatfájlokat zsugorítania kell. Nem kötelező, de ajánlott lépésként azonban először meg kell határoznia az adatbázis indexeinek átlagos oldalsűrűségét. Azonos mennyiségű adat esetén a zsugorodás gyorsabban befejeződik, ha az oldalsűrűség magas, mivel kevesebb oldalt kell áthelyeznie. Ha egyes indexek esetében alacsony az oldalsűrűség, érdemes lehet karbantartást végezni ezeken az indexeken, hogy növelje az oldalsűrűséget az adatfájlok zsugorítása előtt. Ez lehetővé teszi a zsugorítást a lefoglalt tárterület mélyebb csökkentése érdekében.
Az adatbázis összes indexe oldalsűrűségének meghatározásához használja az alábbi lekérdezést. Az oldalsűrűség az oszlopban avg_page_space_used_in_percent van feltüntetve.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Ha vannak olyan indexek, amelyeknek az oldalsűrűsége 60-70%-nál alacsonyabb, érdemes újraépíteni vagy átrendezni ezeket az indexeket az adatfájlok zsugorítása előtt.
Megjegyzés:
Nagyobb adatbázisok esetén az oldalsűrűséget meghatározó lekérdezés végrehajtása hosszú időt (órákat) vehet igénybe. Emellett a nagy indexek újraépítése vagy átrendezése jelentős időt és erőforrás-használatot is igényel. Az oldalsűrűség növelésével, a zsugorítás időtartamának csökkentésével és a nagyobb helytakarékosság elérésével egy másik oldalon kompromisszumot lehet elérni.
Ha több, alacsony lapsűrűségű index van, a folyamat felgyorsítása érdekében több adatbázis-munkamenetben is újraépítheti őket párhuzamosan. Győződjön meg arról, hogy ezzel nem közelíti meg az adatbázis erőforráskorlátait, és hagyja meg a megfelelő erőforrás-fejteret az esetleg futó alkalmazások számítási feladataihoz. Figyelje az erőforrás-felhasználást (CPU, adat IO, napló IO) az Azure Portalon vagy a sys.dm_db_resource_stats nézet használatával, és csak akkor kezdjen további párhuzamos újraépítéseket, ha az erőforrások kihasználtsága ezen dimenziók mindegyikén lényegesen alacsonyabb, mint 100%. Ha a processzor-, adat-IO- vagy napló-IO-kihasználtság 100%-os, felskálázhatja az adatbázist, hogy több processzormaggal rendelkezzen, és növelje az IO átviteli sebességét. Ez további párhuzamos újraépítéseket is lehetővé tehet a folyamat gyorsabb befejezéséhez.
Mintaindex újraépítési parancsa
Az alábbiakban egy mintaparancsot követünk egy index újraépítéséhez és az oldalsűrűség növeléséhez az ALTER INDEX utasítás használatával:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Ez a parancs online és újrakezdhető index-újraépítést kezdeményez. Ez lehetővé teszi, hogy az egyidejű számítási feladatok továbbra is használják a táblát, amíg az újraépítés folyamatban van, és lehetővé teszi az újraépítés folytatását, ha bármilyen okból megszakad. Az ilyen típusú újraépítés azonban lassabb, mint egy offline újraépítés, amely letiltja a táblához való hozzáférést. Ha más számítási feladatoknak nem kell hozzáférnie a táblához az újraépítés során, állítsa be és RESUMABLE távolítsa el a WAIT_AT_LOW_PRIORITY záradékot és a ONLINE beállításokatOFF.
Az indexkarbantartásról további információt az indexkarbantartás optimalizálása a lekérdezési teljesítmény javítása és az erőforrás-felhasználás csökkentése érdekében című témakörben talál.
Több adatfájl zsugorítása
Ahogy korábban már említettük, az adatáthelyezéssel való zsugorodás egy hosszú ideig futó folyamat. Ha az adatbázis több adatfájllal rendelkezik, felgyorsíthatja a folyamatot több adatfájl párhuzamos zsugorításával. Ezt úgy teheti meg, hogy több adatbázis-munkamenetet nyit meg, és minden munkameneten más file_id értéket használDBCC SHRINKFILE. Az indexek korábbi újraépítéséhez hasonlóan minden új párhuzamos zsugorítási parancs indítása előtt győződjön meg arról, hogy elegendő erőforrás-kezelőtér (CPU, Adat IO, Napló IO) áll rendelkezésre.
Az alábbi mintaparancs 4-es file_id méretre zsugorítja az adatfájlt, és 52 000 MB-ra próbálja csökkenteni a lefoglalt méretet a fájlban lévő oldalak áthelyezésével:
DBCC SHRINKFILE (4, 52000);
Ha a lehető legkisebbre szeretné csökkenteni a fájl lefoglalt területét, a célméret megadása nélkül hajtsa végre az utasítást:
DBCC SHRINKFILE (4);
Ha egy számítási feladat egyidejűleg zsugorítással fut, a zsugorítással felszabadított tárterületet használhatja, mielőtt a zsugorítás befejeződik, és csonkolja a fájlt. Ebben az esetben a zsugorítás nem tudja csökkenteni a megadott cél számára lefoglalt területet.
Ezt csökkentheti az egyes fájlok kisebb lépésekben történő zsugorításával. Ez azt jelenti, hogy a DBCC SHRINKFILE parancsban a célérték valamivel kisebb, mint a fájl aktuális lefoglalt területe, ahogyan az az alapterület-használati lekérdezés eredményeiben látható. Ha például a 4-es file_id fájl lefoglalt területe 200 000 MB, és 100 000 MB-ra szeretné csökkenteni, a célértéket először 170 000 MB-ra állíthatja be:
DBCC SHRINKFILE (4, 170000);
A parancs befejeződése után csonkolja a fájlt, és 170 000 MB-ra csökkentette a lefoglalt méretét. Ezután megismételheti ezt a parancsot, a célértéket először 140 000 MB-ra, majd 110 000 MB-ra stb. állíthatja be, amíg a fájl a kívánt méretre nem csökken. Ha a parancs befejeződött, de a fájl nem csonkolt, használjon kisebb lépéseket, például 30 000 MB helyett 15 000 MB-ot.
Az egyidejűleg futó zsugorodási munkamenetek zsugorítási folyamatának figyeléséhez használja a következő lekérdezést:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Megjegyzés:
Előfordulhat, hogy a zsugorítási folyamat nem lineáris, és az percent_complete oszlop értéke hosszú ideig gyakorlatilag változatlan marad, annak ellenére, hogy a zsugorítás még folyamatban van.
Ha a zsugorítás befejeződött az összes adatfájl esetében, futtassa újra a területhasználati lekérdezést (vagy ellenőrizze az Azure Portalon), hogy megállapíthassa a lefoglalt tárterület méretének csökkenését. Ha továbbra is nagy a különbség a használt terület és a lefoglalt terület között, újraépítheti az indexeket a korábban leírtak szerint. Ez ideiglenesen tovább növelheti a lefoglalt területet, azonban az indexek újraépítése után az adatfájlok újra zsugorítása a lefoglalt terület mélyebb csökkenését eredményezheti.
Átmeneti hibák a zsugorodás során
Időnként előfordulhat, hogy a zsugorítási parancsok különböző hibákkal, például időtúllépésekkel és holtpontokkal meghiúsulnak. Ezek a hibák általában átmenetiek, és nem fordulnak elő újra, ha ugyanaz a parancs ismétlődik. Ha a zsugorítás hiba miatt meghiúsul, az adatlapok áthelyezése során eddig elért előrehaladás megmarad, és ugyanez a zsugorítási parancs ismét végrehajtható a fájl zsugorításának folytatásához.
Az alábbi példaszkript bemutatja, hogyan futtatható a zsugorítás egy újrapróbálkozási ciklusban, hogy automatikusan újrapróbálkozjon egy konfigurálható hányszor, amikor időtúllépési hiba vagy holtpont-hiba lép fel. Ez az újrapróbálkozási módszer számos más, a zsugorodás során előforduló hibára is alkalmazható.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Az időtúllépések és holtpontok mellett a zsugorodás bizonyos ismert problémák miatt hibákba ütközhet.
A visszaadott hibák és a hibaelhárítási lépések a következők:
- Hibaszám: 49503, hibaüzenet: %.*ls: A(z) %d:%d oldal nem helyezhető át, mert az egy soron kívüli állandó verziótárlap. Az oldal várakoztatásának oka: %ls. Az oldal várakoztatási időbélyege: %I64d.
Ez a hiba akkor fordul elő, ha hosszú ideig futó aktív tranzakciók sorverziókat generáltak az állandó verziótárban (PVS). Az ilyen sorverziókat tartalmazó lapok nem helyezhetők át zsugorítással, ezért nem tudnak előrehaladást elérni, és ezzel a hibával meghiúsulnak.
A enyhítés érdekében meg kell várnia, amíg ezek a hosszú ideig futó tranzakciók befejeződnek. Azt is megteheti, hogy azonosítja és leállítja ezeket a hosszú ideig futó tranzakciókat, de ez hatással lehet az alkalmazásra, ha nem kezeli a tranzakciós hibákat. A hosszú ideig futó tranzakciók keresésének egyik módja, ha az alábbi lekérdezést futtatja abban az adatbázisban, ahol a zsugorítási parancsot futtatta:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
A tranzakciót a KILL parancs használatával és a lekérdezés eredményéből származó társított session_id érték megadásával fejezheti be:
KILL 4242; -- replace 4242 with the session_id value from query results
Figyelmeztetés
A tranzakció leállása negatív hatással lehet a számítási feladatokra.
A hosszú ideig futó tranzakciók leállása vagy befejezése után egy belső háttérfeladat egy idő után törli a már nem szükséges sorverziókat. A PVS-méret monitorozásával felmérheti a törlés állapotát az alábbi lekérdezéssel. Futtassa a lekérdezést abban az adatbázisban, ahol a zsugorítási parancsot futtatta:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Ha az oszlopban jelentett PVS-méret jelentősen csökken az persistent_version_store_size_gb eredeti méretéhez képest, az újrafuttatásnak sikeresnek kell lennie.
- Hibaszám: 5223, hibaüzenet: %.*ls: A(z) %d:%d üres oldal nem oldható fel.
Ez a hiba akkor fordulhat elő, ha folyamatban vannak az indexkarbantartási műveletek, például ALTER INDEX. A műveletek befejezése után próbálkozzon újra a zsugorítási paranccsal.
Ha a hiba továbbra is fennáll, előfordulhat, hogy a társított indexet újra kell felépíteni. Az újraépítendő index megkereséséhez hajtsa végre a következő lekérdezést ugyanabban az adatbázisban, ahol a zsugorítási parancsot futtatta:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
A lekérdezés végrehajtása előtt cserélje le a <file_id> helyőrzőket <page_id> a kapott hibaüzenet tényleges értékeire. Ha például az üzenet Üres oldal 1:62669, akkor nem lehet felszabadítani, akkor <file_id> az és 1 <page_id> az 62669is.
Építse újra a lekérdezés által azonosított indexet, és próbálkozzon újra a zsugorítási paranccsal.
- Hibaszám: 5201, hibaüzenet: DBCC SHRINKDATABA Standard kiadás: A(z) %d adatbázis-azonosító %d fájlazonosítójának fájlazonosítója ki lett hagyva, mert a fájl nem rendelkezik elegendő szabad területtel a visszaigényléshez.
Ez a hiba azt jelenti, hogy az adatfájl nem zsugoríthető tovább. Továbbléphet a következő adatfájlra.
Következő lépések
További információ az adatbázis maximális méretéről:
- Azure SQL Database virtuális magalapú vásárlási modell korlátai egyetlen adatbázishoz
- Erőforráskorlátok önálló adatbázisokhoz a DTU-alapú vásárlási modellel
- Azure SQL Database virtuális magalapú vásárlási modell korlátai rugalmas készletekhez
- Rugalmas készletek erőforráskorlátai a DTU-alapú vásárlási modell használatával
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: