A Microsoft Azure SQL Database teljesítményének monitorozása dinamikus felügyeleti nézetek használatával
A következőre vonatkozik:![]() Azure SQL Database
Azure SQL Database
A Microsoft Azure SQL Database lehetővé teszi a dinamikus felügyeleti nézetek egy részhalmazát a teljesítményproblémák diagnosztizálásához, amelyeket blokkolt vagy hosszan futó lekérdezések, erőforrás szűk keresztmetszetek, gyenge lekérdezési tervek és egyebek okozhatnak.
Ez a cikk tájékoztatást nyújt arról, hogyan észlelhetők a gyakori teljesítményproblémák a dinamikus felügyeleti nézetek T-SQL-en keresztüli lekérdezésével. Bármilyen lekérdezési eszközt használhat, például:
Jogosultságok
Az Azure SQL Database-ben a számítási mérettől és az üzembe helyezési lehetőségtől függően előfordulhat, hogy a DMV lekérdezéséhez VIEW DATABA Standard kiadás STATE vagy VIEW Standard kiadás RVER STATE engedély szükséges. Az utóbbi engedély a kiszolgálói szerepkör tagságával ##MS_ServerStateReader## adható meg.
Ha a VIEW DATABA Standard kiadás STATE engedélyt egy adott adatbázis-felhasználónak szeretné adni, futtassa például a következő lekérdezést:
GRANT VIEW DATABASE STATE TO database_user;
Ha tagságot szeretne adni a ##MS_ServerStateReader## kiszolgálói szerepkörnek a logikai kiszolgálóhoz való bejelentkezéshez az Azure-ban, csatlakozzon az master adatbázishoz, majd futtassa példaként a következő lekérdezést:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login];
Az SQL Server egy példányában és a felügyelt Azure SQL-példányban a dinamikus felügyeleti nézetek a kiszolgáló állapotadatait adják vissza. Az Azure SQL Database-ben csak az aktuális logikai adatbázissal kapcsolatos információkat adnak vissza.
A CPU-teljesítmény problémáinak azonosítása
Ha a processzorhasználat hosszabb ideig meghaladja a 80%-ot, vegye figyelembe az alábbi hibaelhárítási lépéseket, hogy a cpu-probléma mostvagy a múltban történt-e.
A cpu-probléma most jelentkezik
Ha a probléma jelenleg is fennáll, két lehetséges forgatókönyv lehetséges:
Sok egyedi lekérdezés, amelyek halmozottan magas processzorhasználatot használnak fel
A leggyakoribb lekérdezési kivonatok azonosításához használja a következő lekérdezést:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--'; SELECT TOP 10 GETDATE() runtime, * FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text" FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats GROUP BY query_hash) AS t ORDER BY Total_Request_Cpu_Time_Ms DESC;
Jelenleg is futnak hosszan futó, CPU-t használó lekérdezések
A következő lekérdezésekkel azonosíthatja ezeket a lekérdezéseket:
PRINT '--top 10 Active CPU Consuming Queries by sessions--'; SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY cpu_time DESC; GO
A processzorral kapcsolatos probléma a múltban fordult elő
Ha a probléma a múltban történt, és alapvető okelemzést szeretne végezni, használja a Lekérdezéstárat. Az adatbázis-hozzáféréssel rendelkező felhasználók a T-SQL használatával kérdezhetik le a lekérdezéstár adatait. A Lekérdezéstár alapértelmezett konfigurációi 1 órás részletességet használnak.
Az alábbi lekérdezéssel megtekintheti a magas processzorhasználatú lekérdezések tevékenységeit. Ez a lekérdezés a 15 processzort használó lekérdezést adja vissza. Ne felejtse el módosítani
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE():-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Miután azonosította a problémás lekérdezéseket, ideje hangolni ezeket a lekérdezéseket a processzorhasználat csökkentése érdekében. Ha nincs ideje a lekérdezések hangolására, az adatbázis SLO-ját is frissítheti a probléma megoldásához.
Az Azure SQL Database processzorteljesítményével kapcsolatos problémák kezelésével kapcsolatos további információkért lásd az Azure SQL Database magas processzorhasználatának diagnosztizálása és hibaelhárítása című témakört.
I/O-teljesítménnyel kapcsolatos problémák azonosítása
A tárolási bemeneti/kimeneti (I/O) teljesítményproblémák azonosításakor az I/O-problémákhoz társított leggyakoribb várakozási típusok a következők:
PAGEIOLATCH_*Adatfájl I/O-problémái esetén (beleértve a
PAGEIOLATCH_SH,PAGEIOLATCH_EX).PAGEIOLATCH_UPHa a várakozási típus neve I/O-ra mutat, az egy I/O-problémára mutat. Ha nincs I/O az oldal retesz várakozási nevére, az egy másik típusú problémára mutat (példáultempdbversengés).WRITE_LOGTranzakciónapló I/O-problémái esetén.
Ha az I/O-probléma jelenleg jelentkezik
A sys.dm_exec_requests vagy a sys.dm_os_waiting_tasks használatával megtekintheti az és wait_timea wait_type .
Adatok és napló I/O-használat azonosítása
Az alábbi lekérdezés használatával azonosíthatja az adatokat, és naplózhatja az I/O-használatot. Ha az adatok vagy a napló I/O-száma meghaladja a 80%-ot, az azt jelenti, hogy a felhasználók a rendelkezésre álló I/O-t használták az Azure SQL Database szolgáltatásszinthez.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'CPU Utilization In % of Limit' = rs.avg_cpu_percent
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
, 'Memory Usage In % of Limit' = rs.avg_memory_usage_percent
, 'In-Memory OLTP Storage in % of Limit' = rs.xtp_storage_percent
, 'Concurrent Worker Threads in % of Limit' = rs.max_worker_percent
, 'Concurrent Sessions in % of Limit' = rs.max_session_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
További példákat sys.dm_db_resource_statsa cikk későbbi, erőforrás-használati figyelési szakaszában talál.
Ha elérte az I/O-korlátot, két lehetősége van:
- A számítási méret vagy a szolgáltatásszint frissítése
- Azonosítsa és hangolja a legtöbb I/O-t használó lekérdezéseket.
Pufferrel kapcsolatos I/O megtekintése a Lekérdezéstár használatával
A 2. lehetőségnél a következő lekérdezést használhatja a Lekérdezéstárban a pufferrel kapcsolatos I/O-műveletekhez a nyomon követett tevékenység utolsó két órájának megtekintéséhez:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
A TELJES napló I/O megtekintése a WRITELOG-várakozásokhoz
Ha a várakozás típusa az WRITELOG, a következő lekérdezéssel megtekintheti a teljes napló I/O-utasítását:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Tempdb-teljesítményproblémák azonosítása
Az I/O teljesítményproblémáinak azonosításakor a problémákhoz tempdb társított leggyakoribb várakozási típusok a PAGELATCH_* (nem PAGEIOLATCH_*). A PAGELATCH_* várakozások azonban nem mindig jelentik azt, hogy versengés van tempdb . A várakozás annak a jele is lehet, hogy a felhasználó és az objektum adatlapjai között van versengés, mivel egyszerre több kérés célozza ugyanazt az adatlapot. A versengés további megerősítéséhez tempdb használja a sys.dm_exec_requests annak ellenőrzésére, hogy a wait_resource 2-vel tempdb kezdődő 2:x:y érték az adatbázis-azonosító, x a fájlazonosító és yaz oldalazonosító.
A versengés esetében tempdb gyakori módszer a támaszkodó alkalmazáskód csökkentése vagy átírása tempdb. Gyakori tempdb használati területek a következők:
- Ideiglenes táblák
- Ideiglenes változók
- Ideiglenes értékű paraméterek
- Verziótár használata (hosszú ideig futó tranzakciókhoz társítva)
- Lekérdezések, amelyek lekérdezési terve rendezéseket, kivonatillesztéseket és sorba állításokat használ.
További információ: tempdb az Azure SQL-ben.
Táblaváltozókat és ideiglenes táblákat használó leggyakoribb lekérdezések
A következő lekérdezés használatával azonosíthatja a táblaváltozókat és ideiglenes táblákat használó leggyakoribb lekérdezéseket:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Hosszú ideig futó tranzakciók azonosítása
A hosszú ideig futó tranzakciók azonosításához használja az alábbi lekérdezést. A hosszú ideig futó tranzakciók megakadályozzák az állandó verziótár (PVS) törlését. További információk: Felgyorsított adatbázis-helyreállítás hibaelhárítása.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Memóriahasználati várakozási teljesítménnyel kapcsolatos problémák azonosítása
Ha a legnagyobb várakozási típus, RESOURCE_SEMAPHORE és nincs magas processzorhasználati problémája, előfordulhat, hogy memóriakivételi várakozási problémát tapasztal.
Annak meghatározása, hogy a RESOURCE_Standard kiadás MAPHORE-várakozás a legmagasabb várakozás-e
Az alábbi lekérdezéssel megállapíthatja, hogy a RESOURCE_SEMAPHORE várakozás a legnagyobb várakozási idő-e. Az is jelzésértékű lenne, ha a közelmúltban emelkedne a várakozási RESOURCE_SEMAPHORE idő. A memóriakiadás várakozási problémáinak elhárításáról további információt az SQL Server memóriahasználati problémáinak lassú vagy kevés memóriaproblémáinak elhárítása című témakörben talál.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Nagy memóriaigényű utasítások azonosítása
Ha memóriahiba lépett fel az Azure SQL Database-ben, tekintse át sys.dm_os_out_of_memory_events. További információ: Az Azure SQL Database memóriakihasználtságával kapcsolatos hibák elhárítása.
Először módosítsa az alábbi szkriptet, hogy frissítse a megfelelő értékeket és start_timeend_time. Ezután futtassa a következő lekérdezést a nagy memóriaigényű utasítások azonosításához:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
GO
;WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
A 10 legfontosabb aktív memóriatámogatás azonosítása
Az alábbi lekérdezés segítségével azonosíthatja a 10 legfontosabb aktív memória-támogatást:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Kapcsolatok figyelése
A sys.dm_exec_connections nézetben lekérheti az adott adatbázishoz vagy rugalmas készlethez létesített kapcsolatok adatait, valamint az egyes kapcsolatok részleteit. Emellett a sys.dm_exec_sessions nézet hasznos az összes aktív felhasználói kapcsolatra és belső feladatra vonatkozó információk lekérésekor.
Aktuális munkamenetek megtekintése
Az alábbi lekérdezés az aktuális kapcsolat adatait kéri le. Az összes munkamenet megtekintéséhez távolítsa el a záradékot WHERE .
Az összes végrehajtó munkamenet csak akkor jelenik meg az adatbázisban, ha RENDELKEZik VIEW DATABA Standard kiadás STATE engedéllyel az adatbázison a nézetek és sys.dm_exec_sessions a sys.dm_exec_requests nézetek végrehajtásakor. Ellenkező esetben csak az aktuális munkamenet jelenik meg.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Erőforrás-használat figyelése
Az Azure SQL Database-erőforrások használatát a lekérdezés szintjén is monitorozhatja az SQL Database Query Performance Insights használatával az Azure Portalon vagy a Lekérdezéstárban.
A használatot az alábbi nézetekkel is figyelheti:
sys.dm_db_resource_stats
A sys.dm_db_resource_stats nézetet minden adatbázisban használhatja. A sys.dm_db_resource_stats nézet a szolgáltatási szinthez viszonyított legutóbbi erőforrás-használati adatokat jeleníti meg. A processzor, az adat I/O, a naplóírás és a memória átlagos százalékos aránya 15 másodpercenként van rögzítve, és 1 órán keresztül tartható fenn.
Mivel ez a nézet részletesebben szemlélteti az erőforrások használatát, először használja sys.dm_db_resource_stats az aktuális állapotelemzéshez vagy hibaelhárításhoz. Ez a lekérdezés például az aktuális adatbázis átlagos és maximális erőforrás-használatát mutatja az elmúlt egy órában:
SELECT
Database_Name = DB_NAME(),
tier_limit = COALESCE(rs.dtu_limit, cpu_limit), --DTU or vCore limit
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent'
FROM sys.dm_db_resource_stats AS rs --past hour only
GROUP BY rs.dtu_limit, rs.cpu_limit;
Egyéb lekérdezések esetén lásd a sys.dm_db_resource_stats példákat.
sys.resource_stats
Az adatbázis sys.resource_stats nézete master további információkkal rendelkezik, amelyek segíthetnek az adatbázis teljesítményének az adott szolgáltatási szinten és számítási méretben történő monitorozásában. Az adatokat 5 percenként gyűjtjük, és körülbelül 14 napig tartjuk karban. Ez a nézet hasznos lehet az adatbázis erőforrásainak hosszabb távú előzményelemzéséhez.
Az alábbi grafikon egy prémium szintű adatbázis processzorerőforrás-használatát mutatja be egy hét minden órájában p2 számítási mérettel. Ez a grafikon hétfőn kezdődik, öt munkanapot jelenít meg, majd egy hétvégét jelenít meg, amikor sokkal kevesebb történik az alkalmazásban.
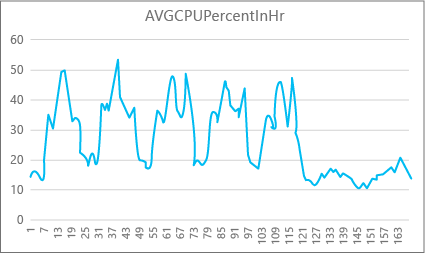
Az adatok alapján ez az adatbázis jelenleg a P2 számítási mérethez képest (kedd délben) valamivel több mint 50 százalékos processzorhasználati csúcsterheléssel rendelkezik. Ha a CPU az alkalmazás erőforrásprofiljának domináns tényezője, akkor dönthet úgy, hogy a P2 a megfelelő számítási méret, hogy a számítási feladat mindig illeszkedjen. Ha azt várja, hogy egy alkalmazás idővel növekedni fog, érdemes további erőforrás-pufferrel rendelkeznie, hogy az alkalmazás soha ne érje el a teljesítményszintű korlátot. Ha növeli a számítási méretet, elkerülheti az ügyfél által látható hibákat, amelyek akkor fordulhatnak elő, ha egy adatbázis nem rendelkezik elegendő erőforrással a kérelmek hatékony feldolgozásához, különösen a késésre érzékeny környezetekben. Ilyen például egy adatbázis, amely egy olyan alkalmazást támogat, amely weblapokat fest az adatbázis-hívások eredményei alapján.
Más alkalmazástípusok eltérően értelmezhetik ugyanazt a gráfot. Ha például egy alkalmazás naponta próbál bérszámfejtési adatokat feldolgozni, és ugyanazzal a diagrammal rendelkezik, az ilyen típusú "kötegelt feladat" modell P1 számítási méretben is jól működik. A P1 számítási méret 100 DTU-val rendelkezik, szemben a 200 DTU-val a P2 számítási méretnél. A P1 számítási méret a P2 számítási méret teljesítményének felét biztosítja. A P2 processzorhasználatának 50 százaléka tehát 100 százalékos processzorhasználatot biztosít a P1-ben. Ha az alkalmazás nem rendelkezik időtúllépéssel, akkor nem számít, hogy egy feladat befejezése 2 órát vagy 2,5 órát vesz igénybe, ha ma végez. Az ebben a kategóriában lévő alkalmazások valószínűleg használhatnak P1 számítási méretet. Kihasználhatja azt a tényt, hogy a nap folyamán vannak olyan időszakok, amikor az erőforrás-használat alacsonyabb, így bármely "nagy csúcs" átfolyhat az egyik vályúba a nap későbbi részében. A P1 számítási mérete jó lehet az ilyen alkalmazásokhoz (és pénzt takaríthat meg), amíg a feladatok minden nap időben befejeződnek.
Az adatbázismotor minden aktív adatbázishoz elérhetővé teszi a felhasznált erőforrás-információkat az sys.resource_statsmaster egyes kiszolgálók adatbázisának nézetben. A táblázat adatai 5 perces időközönként összesítve lesznek. Az Alapszintű, a Standard és a Prémium szolgáltatási szinttel az adatok több mint 5 percet is igénybe vehetnek a táblázatban való megjelenéshez, így ezek az adatok inkább hasznosak az előzményelemzéshez, mint a közel valós idejű elemzéshez. A nézet lekérdezésével sys.resource_stats megtekintheti egy adatbázis legutóbbi előzményeit, és ellenőrizheti, hogy a választott foglalás teljesítette-e a kívánt teljesítményt, amikor szükséges.
Feljegyzés
Az Azure SQL Database-ben az alábbi példákban való lekérdezéshez sys.resource_stats csatlakoznia kell az master adatbázishoz.
Ez a példa bemutatja, hogyan vannak közzétéve az adatok ebben a nézetben:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
A következő példa különböző módszereket mutat be, amelyekkel a sys.resource_stats katalógusnézet segítségével információkat kaphat arról, hogy az adatbázis hogyan használja az erőforrásokat:
A felhasználói adatbázis
userdb1múlt heti erőforrás-használatának megtekintéséhez futtassa ezt a lekérdezést a saját adatbázis nevének helyettesítésével:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Annak a kiértékeléséhez, hogy a számítási feladatok mennyire felelnek meg a számítási méretnek, minden szempontból részletesen elemeznie kell az erőforrás metrikáit: a processzort, az olvasásokat, az írásokat, valamint a feldolgozók és a munkamenetek számát. Íme egy módosított lekérdezés az erőforrásmetrikák átlagának és maximális értékének jelentésére
sys.resource_statsaz adatbázis által kiépített minden egyes szolgáltatási szint esetében:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.Storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Average Requests In %' = AVG(rs.max_worker_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Average Sessions In %' = AVG(rs.max_session_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Az egyes erőforrásmetrikák átlagával és maximális értékeivel kapcsolatos információk segítségével felmérheti, hogy a számítási feladatok mennyire illeszkednek a választott számítási mérethez. Az átlagos értékek
sys.resource_statsáltalában jó alapkonfigurációt biztosítanak a célmérethez képest. Az elsődleges mérőpálcának kell lennie.DTU-vásárlási modelladatbázisok esetén:
Előfordulhat például, hogy a Standard szolgáltatási szintet használja S2 számítási mérettel. A processzor- és I/O-olvasások és -írások átlagos használati aránya 40 százalék alatt van, a feldolgozók átlagos száma 50 alatt van, a munkamenetek átlagos száma pedig 200 alatt van. Előfordulhat, hogy a számítási feladat belefér az S1 számítási méretébe. Könnyen áttekinthető, hogy az adatbázis megfelel-e a feldolgozó és a munkamenet korlátainak. Annak megállapításához, hogy egy adatbázis kisebb számítási méretre illeszkedik-e, ossza el az alacsonyabb számítási méret DTU-számát az aktuális számítási méret DTU-számával, majd szorozza meg az eredményt 100-zal:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Az eredmény a két számítási méret százalékos relatív teljesítménybeli különbsége. Ha az erőforrás-használat nem haladja meg ezt az összeget, előfordulhat, hogy a számítási feladat elfér az alacsonyabb számítási méretben. Meg kell azonban vizsgálnia az erőforrás-használati értékek összes tartományát, és százalékban meg kell határoznia, hogy az adatbázis számítási feladatai milyen gyakran férnek el az alacsonyabb számítási mérethez. A következő lekérdezés az erőforrásdimenziónkénti illesztési százalékot adja ki a példában kiszámított 40 százalékos küszöbérték alapján:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Az adatbázis-szolgáltatási szint alapján eldöntheti, hogy a számítási feladat megfelel-e az alacsonyabb számítási méretnek. Ha az adatbázis számítási feladatainak célkitűzése 99,9 százalék, és az előző lekérdezés mind a három erőforrásdimenzió esetében 99,9 százaléknál nagyobb értékeket ad vissza, akkor a számítási feladat valószínűleg az alacsonyabb számítási mérethez illeszkedik.
Az illesztési arány alapján azt is megtudhatja, hogy a cél eléréséhez a következő nagyobb számítási méretre kell-e váltania. Például egy mintaadatbázis processzorhasználata az elmúlt héten:
Átlagos processzorhasználati százalék Maximális processzorhasználati százalék 24.5 100,00 Az átlagos PROCESSZOR a számítási méret korlátjának körülbelül negyede, ami jól illeszkedik az adatbázis számítási méretéhez.
DTU-vásárlási modell és virtuális mag vásárlási modell adatbázisai esetén:
A maximális érték azt mutatja, hogy az adatbázis eléri a számítási méret korlátját. Át kell lépnie a következő nagyobb számítási méretre? Nézze meg, hogy a számítási feladat hányszor éri el a 100%-ot, majd hasonlítsa össze az adatbázis számítási feladataival.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Ezek a százalékos értékek az aktuális számítási mérethez illeszkedő minták száma. Ha ez a lekérdezés 99,9 százaléknál kisebb értéket ad vissza a három erőforrásdimenzió bármelyikére vonatkozóan, a mintavételezett átlagos számítási feladat túllépte a korlátokat. Fontolja meg, hogy a következő nagyobb számítási méretre lép, vagy alkalmazáshangolási technikákkal csökkenti az adatbázis terhelését.
Feljegyzés
Rugalmas készletek esetén az ebben a szakaszban leírt technikákkal az adatbáziskészlet egyes adatbázisait is figyelheti. A készlet egészét is figyelheti. További információkért lásd: Rugalmas készlet figyelése és kezelése.
Egyidejű kérelmek maximális száma
Az egyidejű kérések aktuális számának megtekintéséhez futtassa ezt a lekérdezést a felhasználói adatbázisban:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R;
Egy adatbázis számítási feladatainak elemzéséhez módosítsa ezt a lekérdezést úgy, hogy az az elemezni kívánt adatbázisra szűrjön. Először frissítse az adatbázis nevét a kívánt adatbázisra MyDatabase , majd futtassa a következő lekérdezést az adatbázisban lévő egyidejű kérések számának megkereséséhez:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R
INNER JOIN sys.databases AS D
ON D.database_id = R.database_id
AND D.name = 'MyDatabase';
Ez csak pillanatkép egy adott időpontban. A számítási feladatok és az egyidejű kérések követelményeinek jobb megismeréséhez idővel számos mintát kell összegyűjtenie.
Egyidejű bejelentkezési események maximális száma
A felhasználói és alkalmazásminták elemzésével képet kaphat a bejelentkezési események gyakoriságáról. A valós terheléseket tesztkörnyezetben is futtathatja, így meggyőződhet arról, hogy nem éri el ezt vagy a cikkben tárgyalt egyéb korlátokat. Nincs egyetlen lekérdezési vagy dinamikus felügyeleti nézet (DMV), amely megjelenítheti az egyidejű bejelentkezések számát vagy előzményeit.
Ha több ügyfél ugyanazt a kapcsolati sztring használja, a szolgáltatás minden bejelentkezést hitelesít. Ha 10 felhasználó egyidejűleg ugyanazzal a felhasználónévvel és jelszóval csatlakozik egy adatbázishoz, 10 egyidejű bejelentkezés lenne. Ez a korlát csak a bejelentkezés és a hitelesítés időtartamára vonatkozik. Ha ugyanaz a 10 felhasználó egymás után csatlakozik az adatbázishoz, az egyidejű bejelentkezések száma soha nem lenne nagyobb 1-nél.
Feljegyzés
Ez a korlát jelenleg nem vonatkozik a rugalmas készletekben lévő adatbázisokra.
Munkamenetek maximális száma
Az aktuális aktív munkamenetek számának megtekintéséhez futtassa ezt a lekérdezést az adatbázisban:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections;
Ha SQL Server-számítási feladatot elemez, módosítsa úgy a lekérdezést, hogy egy adott adatbázisra összpontosítson. Ez a lekérdezés segít meghatározni az adatbázis lehetséges munkamenet-igényeit, ha az Azure-ba történő áthelyezést fontolgatja. Először frissítse az adatbázis nevét a kívánt adatbázisra MyDatabase , majd futtassa a következő lekérdezést:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections AS C
INNER JOIN sys.dm_exec_sessions AS S
ON (S.session_id = C.session_id)
INNER JOIN sys.databases AS D
ON (D.database_id = S.database_id)
WHERE D.name = 'MyDatabase';
Ezek a lekérdezések ismét időponthoz kötött számot adnak vissza. Ha több mintát gyűjt idővel, akkor a legjobban ismeri a munkamenet-használatot.
A munkamenetek előzménystatisztikáit a sys.resource_stats katalógusnézet lekérdezésével és az active_session_count oszlop áttekintésével szerezheti be.
Adatbázis- és objektumméretek kiszámítása
Az alábbi lekérdezés visszaadja az adatbázis méretét (megabájtban):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Az alábbi lekérdezés visszaadja az adatbázisban található egyes objektumok méretét (megabájtban):
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Lekérdezési teljesítmény figyelése
A lassú vagy hosszú ideig futó lekérdezések jelentős rendszererőforrásokat használhatnak fel. Ez a szakasz bemutatja, hogyan lehet dinamikus felügyeleti nézetekkel észlelni néhány gyakori lekérdezési teljesítményproblémát a sys.dm_exec_query_stats dinamikus felügyeleti nézet használatával. A nézet lekérdezési utasításonként egy sort tartalmaz a gyorsítótárazott terven belül, és a sorok élettartama magához a tervhez van kötve. Ha egy tervet eltávolít a gyorsítótárból, a megfelelő sorok törlődnek ebből a nézetből.
Leggyakoribb lekérdezések keresése processzoridő szerint
Az alábbi példa az első 15 lekérdezés adatait adja vissza a végrehajtásonkénti átlagos cpu-idő alapján rangsorolva. Ez a példa a lekérdezéseket a lekérdezés kivonata alapján összesíti, így a logikailag egyenértékű lekérdezések az összesített erőforrás-felhasználásuk szerint vannak csoportosítva.
SELECT TOP 15 query_stats.query_hash AS "Query Hash",
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS "Avg CPU Time",
MIN(query_stats.statement_text) AS "Statement Text"
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY 2 DESC;
Lekérdezéstervek monitorozása az összesített CPU-időhöz
A nem hatékony lekérdezési terv a processzorhasználatot is növelheti. Az alábbi példa azt határozza meg, hogy melyik lekérdezés használja a legutóbbi előzmények legnagyobb összegző processzorát.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Letiltott lekérdezések figyelése
A lassú vagy hosszú ideig futó lekérdezések hozzájárulhatnak a túlzott erőforrás-felhasználáshoz, és a blokkolt lekérdezések következményei lehetnek. A blokkolás oka lehet az alkalmazás rossz kialakítása, a rossz lekérdezési tervek, a hasznos indexek hiánya stb.
A nézet segítségével sys.dm_tran_locks információkat kaphat az adatbázis aktuális zárolási tevékenységéről. Lásd például a sys.dm_tran_locks. A blokkolás hibaelhárításával kapcsolatos további információkért tekintse meg és oldja meg az Azure SQL blokkolási problémáit.
Holtpontok monitorozása
Bizonyos esetekben két vagy több lekérdezés egymás kölcsönösen blokkolhatja egymást, ami holtpontot eredményez.
Az Azure SQL Database-ben kiterjesztett eseményeket hozhat létre, amelyek rögzítik a holtponti eseményeket, majd megkereshetik a kapcsolódó lekérdezéseket és azok végrehajtási terveit a Lekérdezéstárban. További információ az Azure SQL Database holtpontok elemzésében és megelőzésében, beleértve az AdventureWorksLT holtpontot okozó tesztkörnyezetét is. További információ a holtpontra ható erőforrástípusokról.
Következő lépések
- Bevezetés az Azure SQL Database és a felügyelt Azure SQL-példány használatába
- Magas processzorhasználat diagnosztizálása és hibaelhárítása az Azure SQL Database esetében
- Alkalmazások és adatbázisok teljesítményhangolása az Azure SQL Database-ben
- Az Azure SQL Database blokkolási problémáinak ismertetése és megoldása
- Holtpontok elemzése és megakadályozása az Azure SQL Database-ben
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: