Valós idejű big data-elemzés felgyorsítása a Spark-összekötővel
A következőre vonatkozik:![]() Azure SQL Database
Azure SQL Database![]() Felügyelt Azure SQL-példány
Felügyelt Azure SQL-példány
Megjegyzés:
2020 szeptemberétől ezt az összekötőt nem tartjuk aktívan karban. Az SQL Serverhez és az Azure SQL-hez készült Apache Spark Csatlakozás or azonban már elérhető, a Python- és R-kötések támogatásával, az adatok tömeges beszúrását megkönnyítő felülettel és számos egyéb fejlesztéssel. Határozottan javasoljuk, hogy ne ezt, hanem az új összekötőt értékelje ki és használja. A régi összekötőre (ezen az oldalon) vonatkozó információk csak archiválási célból maradnak meg.
A Spark-összekötő lehetővé teszi, hogy az Azure SQL Database, az Azure SQL Managed Instance és az SQL Server adatbázisai bemeneti adatforrásként vagy kimeneti adatgyűjtőként működjenek a Spark-feladatokhoz. Lehetővé teszi, hogy valós idejű tranzakciós adatokat használjon fel a big data-elemzésekben, és megőrizze az eredményeket alkalmi lekérdezésekhez vagy jelentésekhez. A beépített JDBC-összekötőhöz képest ez az összekötő lehetővé teszi az adatok tömeges beszúrását az adatbázisba. 10-20-szor gyorsabb teljesítménnyel képes felülmúlni a sorról sorra történő beszúrást. A Spark-összekötő támogatja a Microsoft Entra-azonosítóval (korábbi nevén Azure Active Directory) való hitelesítést az Azure SQL Database-hez és a felügyelt Azure SQL-példányhoz való csatlakozáshoz, lehetővé téve az adatbázis azure Databricksből való csatlakoztatását a Microsoft Entra-fiókjával. Hasonló interfészeket biztosít a beépített JDBC-összekötőhöz. Az új összekötő használatához egyszerűen migrálhatja a meglévő Spark-feladatokat.
Megjegyzés:
A Microsoft Entra ID az Azure Active Directory (Azure AD) új neve. Jelenleg frissítjük a dokumentációt.
Spark-összekötő letöltése és létrehozása
A lapról korábban csatolt régi összekötő GitHub-adattára nincs aktívan karbantartva. Ehelyett határozottan javasoljuk, hogy értékelje ki és használja az új összekötőt.
Hivatalos támogatott verziók
| Összetevő | Verzió |
|---|---|
| Apache Spark | 2.0.2 vagy újabb |
| Scala | 2.10 vagy újabb |
| Microsoft JDBC-illesztőprogram SQL Serverhez | 6.2 vagy újabb |
| Microsoft SQL Server | SQL Server 2008 vagy újabb |
| Azure SQL Database | Supported |
| Azure SQL Managed Instance | Supported |
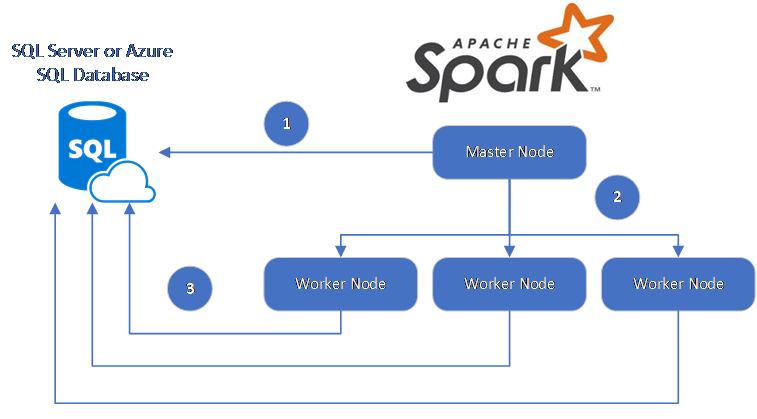
A Spark-összekötő az SQL ServerHez készült Microsoft JDBC-illesztőprogramot használja az adatok Spark-feldolgozó csomópontok és adatbázisok közötti áthelyezéséhez:
Az adatfolyam a következő:
- A Spark fő csomópontja az SQL Database vagy az SQL Server adatbázisaihoz csatlakozik, és adatokat tölt be egy adott táblából vagy egy adott SQL-lekérdezés használatával.
- A Spark fő csomópontja osztja el az adatokat a feldolgozó csomópontok között átalakítás céljából.
- A Feldolgozó csomópont az SQL Database-hez és az SQL Serverhez csatlakozó adatbázisokhoz csatlakozik, és adatokat ír az adatbázisba. A felhasználó választhatja a sorról sorra történő beszúrást vagy a tömeges beszúrást.
Az alábbi ábra az adatfolyamot szemlélteti.
A Spark-összekötő létrehozása
Az összekötő projekt jelenleg maven-t használ. Ha függőségek nélkül szeretné létrehozni az összekötőt, futtassa a következőt:
- mvn tiszta csomag
- Töltse le a JAR legújabb verzióit a kiadási mappából
- Az SQL Database Spark JAR-jának belefoglalása
adatok Csatlakozás és olvasása a Spark-összekötővel
Az SQL Database-ben és az SQL Serverben lévő adatbázisokhoz Spark-feladatból csatlakozhat az adatok olvasásához vagy írásához. DML- vagy DDL-lekérdezést is futtathat az SQL Database és az SQL Server adatbázisaiban.
Adatok olvasása az Azure SQL-ből és az SQL Serverről
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Adatok olvasása az Azure SQL-ből és az SQL Serverről megadott SQL-lekérdezéssel
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Adatok írása az Azure SQL-be és az SQL Serverbe
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
DML- vagy DDL-lekérdezés futtatása az Azure SQL-ben és az SQL Serveren
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Csatlakozás a Sparkból Microsoft Entra-hitelesítéssel
Microsoft Entra-hitelesítéssel csatlakozhat az SQL Database-hez és a felügyelt SQL-példányhoz. A Microsoft Entra-hitelesítéssel központilag kezelheti az adatbázis-felhasználók identitásait, és alternatívaként használhatja az SQL-hitelesítést.
ActiveDirectoryPassword hitelesítési mód Csatlakozás
Beállítási követelmény
Ha ActiveDirectoryPassword hitelesítési módot használ, le kell töltenie a microsoft-authentication-library-for-java fájlt és annak függőségeit, és fel kell vennie őket a Java buildelési útvonalára.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Csatlakozás hozzáférési jogkivonat használatával
Beállítási követelmény
Ha hozzáférési jogkivonat-alapú hitelesítési módot használ, le kell töltenie a Microsoft-authentication-library-for-Java-t és annak függőségeit, és fel kell vennie őket a Java buildelési útvonalára.
A Microsoft Entra-hitelesítés használatával megtudhatja, hogyan szerezhet be hozzáférési jogkivonatot az adatbázishoz az Azure SQL Database-ben vagy a felügyelt Azure SQL-példányban.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Adatok írása tömeges beszúrással
A hagyományos jdbc-összekötő sorról sorra történő beszúrással adatokat ír az adatbázisba. A Spark-összekötővel tömeges beszúrással adatokat írhat az Azure SQL-be és az SQL Serverbe. Jelentősen javítja az írási teljesítményt nagy adathalmazok betöltésekor, vagy az adatok olyan táblákba való betöltésekor, ahol oszloptároló-indexet használnak.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
További lépések
Ha még nem tette meg, töltse le a Spark-összekötőt az Azure-sqldb-spark GitHub-adattárból, és fedezze fel az adattár további erőforrásait:
Érdemes lehet áttekinteni az Apache Spark SQL, a DataFrames és az Adatkészletek útmutatóját , valamint az Azure Databricks dokumentációját is.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: