Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az adattermékek olyan adatok, amelyek termékként kerülnek kiszolgálásra, és amelyeket poliglott állandóssági szolgáltatások számítanak ki, mentenek el, és szolgáltatnak, és bizonyos használati esetek megkívánhatnak. Az adattermék létrehozásának és kiszolgálásának folyamata olyan szolgáltatásokat és technológiákat igényelhet, amelyek nem szerepelnek az adat-kezdőzónában alapvető szolgáltatásokban. Ilyen például a speciális követelményekkel kapcsolatos jelentéskészítés, mint például a megfelelőségi és adózási jelentések.
Tervezési szempontok
Az adat-kezdőzóna több adatterméket is kiszolgálhat, amelyek úgy jönnek létre, hogy adatokat kell beszedni ugyanabból az adat-célzónából vagy több adat-kezdőzónából. Ez az alábbi ábrán látható.
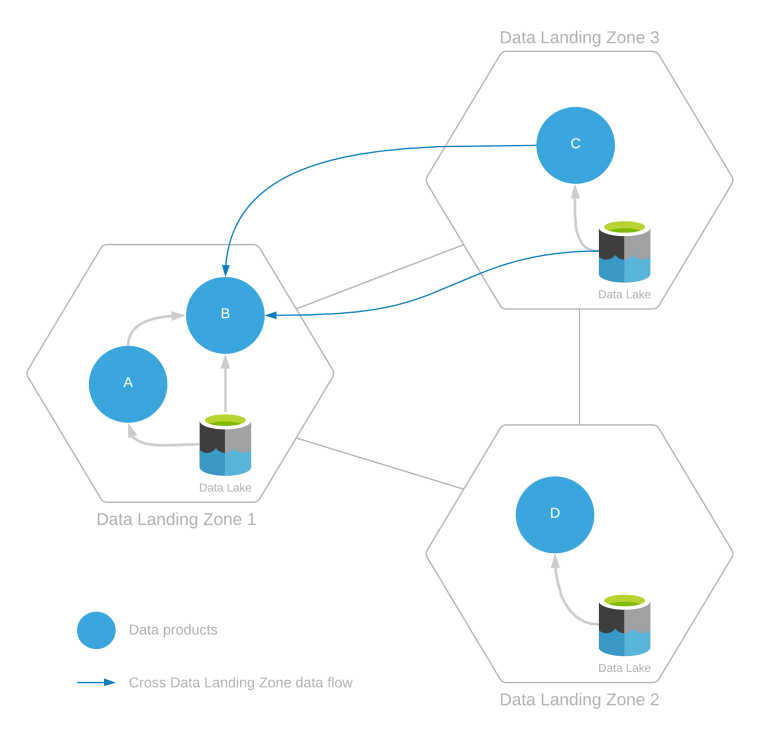
A fenti példa a következőt mutatja:
- Intrazonális adatfelhasználás
- A B adattermék az A adattermékből, valamint a saját célzónán belül a data lake-ben meglévő egyéb adatokból vagy adattermékekből származó adatokat használja fel.
- A C és D adattermékek csak a saját adat-kezdőzónájukból használnak fel adatokat.
- Zónaközi adatfelhasználás:
- A B adattermék a C adattermékből és a 3. célzóna adattójában lévő adatokból is felhasznál adatokat.
Fontos
Az övezetek közötti adatfelhasználás esetében, mivel a B adattermék a 3. adat-célzóna beolvasásával jön létre, az olvasási hozzáféréshez az adat-célzóna-műveletek és integrációs műveletek 3. adat-célzóna-csapatok jóváhagyása szükséges.
Fontos
A B adattermék az A és A adattermékekből származó adatokat használja fel. Mielőtt ez bekövetkezne, a B adatterméknek adatmegosztási megállapodásokon keresztül regisztrálnia kell az adattermékek felhasználását. Ennek az adatmegosztási szerződésnek frissítenie kell az A adattermékről a B adattermékre és a C adattermékről a B adattermékre való származást.
Az adattermék erőforráscsoportja tartalmazza a létrehozásukhoz és karbantartásához szükséges összes szolgáltatást. Ezt az erőforráscsoportot adatalkalmazásnak hívhatjuk. Az adatalkalmazások részét képező szolgáltatások közé tartozhatnak például az Azure Functions, az Azure App Service, a Logic Apps, az Azure Analysis Services, az Azure AI-szolgáltatások, az Azure Machine Learning, az Azure SQL Database, az Azure Database for MySQL és az Azure Cosmos DB.
Az adattermékek READ olyan adatforrásokból származó adatokkal rendelkeznek, amelyeken valamilyen adatátalakítást alkalmaztak. Ilyen lehet például egy újonnan összeállított adathalmaz vagy egy BI-jelentés.
Tervezési javaslatok
Adattermékeket hozhat létre az adat-kezdőzónában az olyan tervezési alapelvek betartásával, amelyek lehetővé teszik az adatszabályozással való skálázást. Az alábbi szakaszok tervezési javaslatokat nyújtanak az adatalkalmazás ökoszisztémájának megtervezéséhez.
Több erőforráscsoport üzembe helyezése
Minden adatalkalmazás egy erőforráscsoport. Mivel az adatalkalmazások számítási szolgáltatások, többplatformos adatmegőrzési szolgáltatások vagy mindkettő, ezekre csak bizonyos használati esetektől függően lehet szükség. Ezért választható adat-kezdőzóna-összetevőnek minősülnek. Azokban az esetekben, amikor szükség van adatalkalmazásra, hozzon létre több erőforráscsoportot adatalkalmazásonként az alábbi ábrán látható módon.

Védőkorlátok beállítása
Az Azure Policy az adat-kezdőzónán belüli szolgáltatások alapértelmezett konfigurációját vezérli. Az operatív elemzést több erőforráscsoportnak tekintheti, amelyeket az adattermék-csapat egy standard szolgáltatáskatalógusból kérhet le. Az Azure Policy használatával konfigurálhatja a biztonsági határt és a szükséges funkciókészletet.
Fontos
A konzisztencia érdekében konfiguráljon egy Azure Policyt minden adatalkalmazáshoz.
Adatok felhasználása több helyről
Az adatalkalmazások több adategységből származó adatokat kezelnek, rendszereznek és értelmeznek, és minden megszerzett megállapítást bemutatnak. Az adattermék egy vagy több adatalkalmazás adatainak eredménye az adat-kezdőzónákban. Szükség esetén lehetővé teszi az adatalkalmazások számára, hogy több és különböző forrásból származó adatokat férjenek hozzá.
Igény szerint skálázás
Az adatalkalmazásokat alkotó szolgáltatások fokozatos üzembe helyezést jelentenek az adatfogadó zónában. Igény szerint skálázza az adatalkalmazásokat.
Adatfelderítés engedélyezése
Regisztrálja automatikusan az adattermékeit egy adatkatalógusban, például a Microsoft Purview-ben, az adatvizsgálat engedélyezéséhez.
Az adattermékek azonosítása
Az adat-kezdőzóna tervezésekor szükség szerint azonosítsa a lehető legtöbb adatterméket (és az azokat kiíró és karbantartó adatalkalmazásokat) az adattermék-alkalmazásarchitektúra kialakításához. A megvalósított platformszabályozásnak való megfelelőségnek kell a legnagyobb szerepet játszania a döntésekben.
Összpontosítson arra, hogy adatalkalmazásai miként működnek adattermelőként és -fogyasztóként mások számára. Tegyük fel például, hogy azonosított egy adattermékcsomagot (A, B, C és D), amelyek olyan adatok, amelyek előállításra és felhasználásra kerülnek. A B adattermékhez A és D adattermékekre van szükség a B adatalkalmazás adataihoz. A B adattermék az A és D adattermékekből származó adatokból jön létre. A B adatalkalmazás maga is adattermelőként működik, és a C adattermékhez is adatokat állít elő.
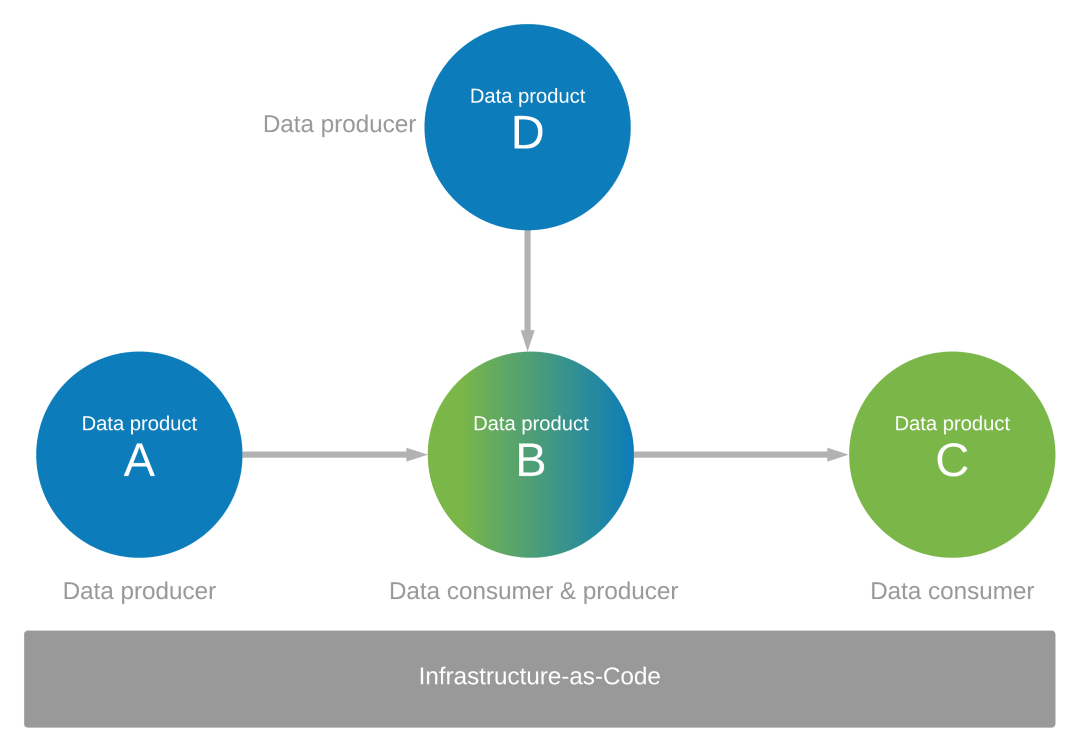
Az adatalkalmazási környezet kezelése kód-alapú infrastruktúrával
A szabályozásnak és az infrastruktúra mint kódnak szabályoznia kell az adatalkalmazási környezetet az adattermékek ökoszisztémájában, ahogy az az előző ábrán is látható.
Adatmodellek közzététele
Az adattermék-csapatoknak közzé kell tenniük az adatmodelleket egy modellezési adattárban.
Az adattermék-felhasználókkal kapcsolatos elvárások beállítása
Frissítse adatmegosztási szerződéseit szolgáltatásszintű szerződésekkel és minősítésekkel az adattermékekhez, hogy pontos elvárásokat közvetítsen az adattermék potenciális felhasználóinak.
A származási vonal rögzítése
Ha a B adattermék az A és D adattermékekből származó adatokból jön létre, akkor az A és D forrásból a B-re történő eredetkövetést rögzíteni kell. További eredetkövetést kell rögzíteni a C adattermékhez is, mivel ez a B adattermékből származó adatokkal hozható létre. Az adattermék minden kiadása előtt frissített eredetkövetést kell rögzíteni egy adatszármazás-alkalmazásba.
Jegyzet
Az Azure Pipelines használatával jóváhagyási kapukat hozhat létre, és olyan függvényeket hívhat meg, amelyek biztosítják, hogy a metaadatok, a lineage és az SLA-k regisztrálva legyenek a megfelelő szabályozási szolgáltatásban.
Adatalkalmazás-architektúra definiálása
Minden adattermékhez létre kell hoznia egy részletes architektúrát, amely teljes mértékben meghatározza a más adattermékekkel való kapcsolatát, függőségeit és hozzáférési követelményeit.