Adatgnosztikus betöltési motor
Ez a cikk azt ismerteti, hogyan valósíthat meg adatelemzési betöltési motor forgatókönyveket a PowerApps, az Azure Logic Apps és a metaadatokon alapuló másolási feladatok kombinációjával az Azure Data Factoryben.
Az adatelemzési motor forgatókönyvei általában arra összpontosítanak, hogy a nem műszaki (nem adatmérnök) felhasználók adategységeket tegyenek közzé a Data Lake-ben további feldolgozás céljából. A forgatókönyv implementálásához olyan előkészítési képességekkel kell rendelkeznie, amelyek lehetővé teszik:
- Adategység-regisztráció
- Munkafolyamat kiépítése és metaadatok rögzítése
- Betöltési ütemezés
Láthatja, hogy ezek a képességek hogyan működnek együtt:

1. ábra: Az adatregisztrációs képességek interakciói.
Az alábbi ábra bemutatja, hogyan implementálhatja ezt a folyamatot az Azure-szolgáltatások kombinációjával:

2. ábra: Automatizált betöltési folyamat.
Adategység-regisztráció
Az automatikus betöltéshez használt metaadatok megadásához adategység-regisztrációra van szükség. A rögzített adatok a következőket tartalmazzák:
- Technikai információ: Adategység neve, forrásrendszere, típusa, formátuma és gyakorisága.
- Irányítási információk: Tulajdonos, gondnokok, láthatóság (felderítési célokra) és bizalmasság.
A PowerApps az egyes adategységeket leíró metaadatok rögzítésére szolgál. Modellalapú alkalmazással adja meg az egyéni Dataverse-táblában tárolt adatokat. Ha a dataverse-ben metaadatok jönnek létre vagy frissülnek, egy automatizált felhőfolyamatot aktivál, amely további feldolgozási lépéseket hív meg.

3. ábra: Adategység-regisztráció.
Munkafolyamat/metaadat-rögzítés kiépítése
A kiépítési munkafolyamat szakaszában érvényesítheti és megőrizheti a regisztrációs szakaszban gyűjtött adatokat a metaadattárban. Mind a műszaki, mind az üzleti érvényesítési lépéseket végrehajtjuk, beleértve a következőket:
- Bemeneti adatcsatorna ellenőrzése
- Jóváhagyási munkafolyamat aktiválása
- Logic processing to trigger persistence of metadata to the metadata store
- Tevékenységnaplózás
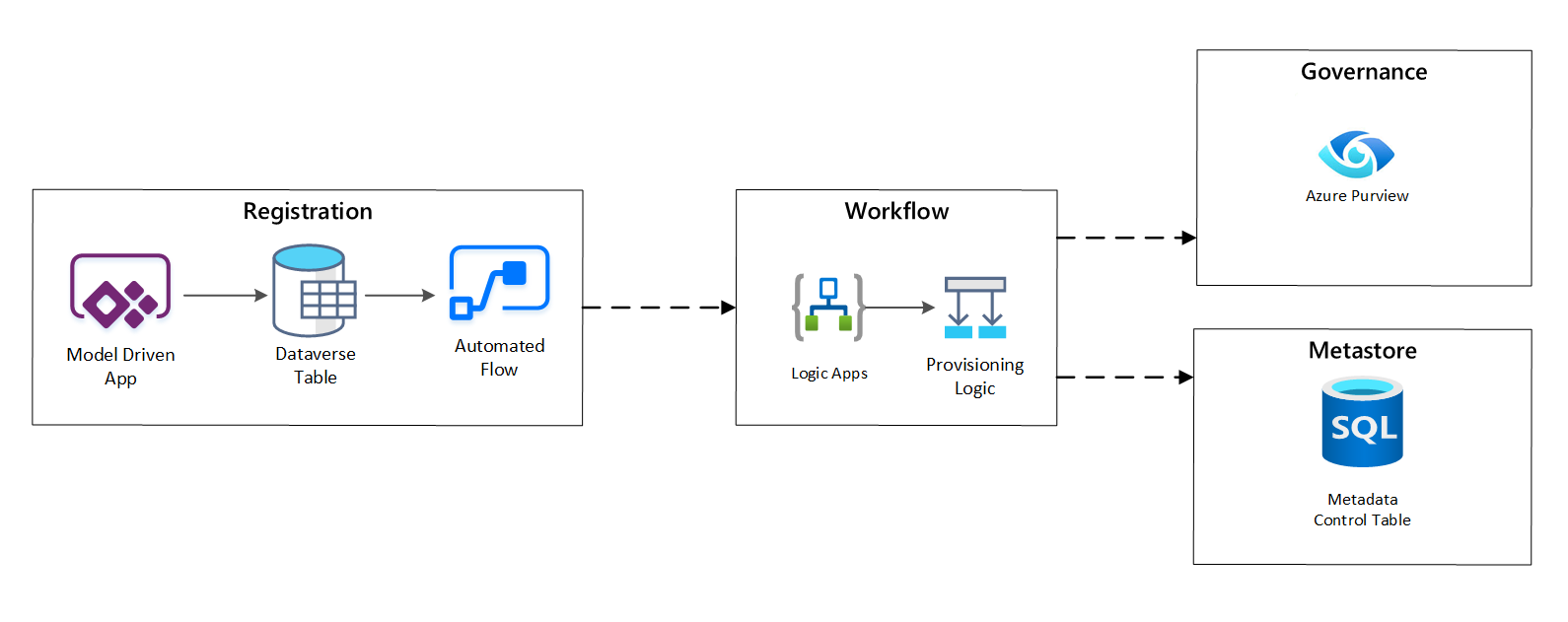
4. ábra: Regisztrációs munkafolyamat.
A betöltési kérelmek jóváhagyása után a munkafolyamat az Azure Purview REST API használatával szúrja be a forrásokat az Azure Purview-ba.
Részletes munkafolyamat az adattermékek előkészítéséhez

5. ábra: Az új adathalmazok betöltése (automatizált).
Az 5. ábra az új adatforrások betöltésének automatizálására szolgáló részletes regisztrációs folyamatot mutatja be:
- A forrásadatok regisztrálva vannak, beleértve az éles és az adat-előállító környezeteket is.
- A rendszer rögzíti az adatalakzatot, a formátumot és a minőségre vonatkozó korlátozásokat.
- Az adatalkalmazási csapatoknak jelezniük kell, hogy az adatok bizalmasak-e (Személyes adatok). Ez a besorolás vezérli a Data Lake-mappák létrehozásának folyamatát a nyers, bővített és válogatott adatok betöltéséhez. A forrás a nyers és bővített adatokat, valamint az adattermék-neveket válogatott adatoknak nevezi.
- Szolgáltatásnév- és biztonsági csoportok jönnek létre az adatkészletek betöltéséhez és hozzáférésének biztosításához.
- A data factory metaadat-adattárban létrejön egy betöltési feladat.
- Az API beszúrja az adatdefiníciót az Azure Purview-ba.
- Az adatforrás ellenőrzésének és az ops csapat általi jóváhagyásának függvényében a részletek közzé lesznek téve egy Data Factory-metaadattárban.
Betöltési ütemezés
Az Azure Data Factoryben a metaadatalapú másolási feladatok olyan funkciókat biztosítanak, amelyek lehetővé teszik a vezénylési folyamatokat az Azure SQL Database-ben tárolt vezérlőtáblák sorai alapján. Az Adatmásolás eszközzel előre létrehozhat metaadatalapú folyamatokat.
Miután létrehozott egy folyamatot, a kiépítési munkafolyamat bejegyzéseket ad hozzá a vezérlőtáblához, hogy támogassa az adategység-regisztrációs metaadatok által azonosított forrásokból történő betöltést. Az Azure Data Factory-folyamatok és a Control Table-metaadattárat tartalmazó Azure SQL Database is létezhet az egyes adat-kezdőzónákban új adatforrások létrehozásához és adat-kezdőzónákba való betöltéséhez.

6. ábra: Az adategységek betöltésének ütemezése.
Részletes munkafolyamat új adatforrások betöltéséhez
Az alábbi ábra bemutatja, hogyan kérhetők le regisztrált adatforrások a Data Factory SQL Database metaadattárában, és hogyan történik az adatok első betöltése:

A Data Factory betöltési főfolyamata beolvassa a konfigurációkat egy Data Factory SQL Database-metaadattárból, majd iteratív módon futtatja a megfelelő paraméterekkel. Az adatok a forrástól a nyers rétegig haladnak az Azure Data Lake-ben, és alig változnak. Az adatalakzat érvényesítése a Data Factory metaadattára alapján történik. A fájlformátumok Apache Parquet- vagy Avro-formátumokká alakulnak, majd átmásolódnak a bővített rétegbe.
A betöltött adatok egy Azure Databricks-adatelemzési és -mérnöki munkaterülethez csatlakoznak, és egy adatdefiníció jön létre az Apache Hive adat-kezdőzónában.
Ha kiszolgáló nélküli Azure Synapse SQL-készletet kell használnia az adatok felfedéséhez, az egyéni megoldásnak nézeteket kell létrehoznia a tóban lévő adatokról.
Ha sorszintű vagy oszlopszintű titkosítást igényel, az egyéni megoldásnak az adatokat a data lake-ben kell leküldnie, majd közvetlenül az SQL-készletek belső tábláiba kell beszednie az adatokat, és megfelelő biztonságot kell beállítania az SQL-készletek számítási adataihoz.
Rögzített metaadatok
Automatizált adatbetöltés használatakor lekérdezheti a társított metaadatokat, és irányítópultokat hozhat létre a következőre:
- Nyomon követheti a függvényekhez kapcsolódó adattermékek feladatait és a legújabb adatbetöltési időbélyegeket.
- Az elérhető adattermékek nyomon követése.
- Adatmennyiségek növelése.
- Valós idejű frissítések beszerzése a feladathibákról.
A működési metaadatok a következő nyomon követésére használhatók:
- Feladatok, feladatlépések és függőségeik.
- Feladatteljesítmény és teljesítményelőzmények.
- Adatmennyiség növekedése.
- Feladathibák.
- A forrás metaadatainak változásai.
- Adattermékektől függő üzleti függvények.
Adatok felderítése az Azure Purview REST API használatával
Az Azure Purview REST API-kat az adatok kezdeti betöltése során történő regisztrálásához kell használni. Az API-k segítségével az adatok nem sokkal a betöltés után elküldhetők az adatkatalógusba.
További információ: Azure Purview REST API-k használata.
Adatforrások regisztrálása
Az alábbi API-hívással regisztrálhat új adatforrásokat:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
Az adatforrás URI-paraméterei:
| Név | Kötelező | Típus | Leírás |
|---|---|---|---|
accountName |
Igaz | Sztring | Az Azure Purview-fiók neve |
dataSourceName |
Igaz | Sztring | Az adatforrás neve |
Az Azure Purview REST API használata regisztrációhoz
Az alábbi példák bemutatják, hogyan lehet az Azure Purview REST API használatával adatforrásokat regisztrálni hasznos adatokkal:
Azure Data Lake Storage Gen2-adatforrás regisztrálása:
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
SQL Database-adatforrás regisztrálása:
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Feljegyzés
Ez <collection-name>egy Azure Purview-fiókban található jelenlegi gyűjtemény.
Vizsgálat létrehozása
Megtudhatja, hogyan hozhat létre hitelesítő adatokat források hitelesítéséhez az Azure Purview-ban a vizsgálat beállítása és futtatása előtt.
Az adatforrások vizsgálatához használja a következő API-hívást:
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
Vizsgálat URI-paraméterei:
| Név | Kötelező | Típus | Leírás |
|---|---|---|---|
accountName |
Igaz | Sztring | Az Azure Purview-fiók neve |
dataSourceName |
Igaz | Sztring | Az adatforrás neve |
newScanName |
Igaz | Sztring | Az új vizsgálat neve |
Az Azure Purview REST API használata vizsgálathoz
Az alábbi példák bemutatják, hogyan használhatja az Azure Purview REST API-t az adatforrások hasznos adatokkal való vizsgálatára:
Azure Data Lake Storage Gen2-adatforrás vizsgálata:
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
SQL Database-adatforrás vizsgálata:
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Az adatforrások vizsgálatához használja a következő API-hívást:
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run
Következő lépések
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: