Adat-kezdőzónák
Az adat-célzónák virtuális hálózat (VNet) társviszony-létesítéssel csatlakoznak az adatkezelési célzónához . Az egyes adat-célzónák az Azure-beli célzóna architektúrához kapcsolódó célzónának minősülnek.
Fontos
Az adat-célzóna kiépítése előtt győződjön meg arról, hogy a DevOps és a CI/CD operációs modell működik, és üzembe helyez egy adatkezelési célzónát.
Minden adat-kezdőzóna több rétegből áll, amelyek rugalmasságot tesznek lehetővé a benne található szolgáltatásadat-integrációkhoz és adattermékekhez. Egy új adat-célzóna olyan szabványos szolgáltatáskészlettel telepíthető, amely lehetővé teszi, hogy az adat-kezdőzóna megkezdje az adatok betöltését és elemzését.
Az adat-kezdőzónához társított Azure-előfizetés a következő struktúrával rendelkezik:
Megjegyzés:
Az adatalkalmazások egy vagy több adatterméket állítanak elő.
Adat-kezdőzóna architektúrája
Az adat-kezdőzóna architektúrája az egyes erőforráscsoportok rétegeit, erőforráscsoportjait és szolgáltatásait mutatja be. Az architektúra áttekintést nyújt az adat-kezdőzónához társított összes csoportról és szerepkörről, valamint a vezérlő- és adatsíkokhoz való hozzáférésük mértékéről.

Tipp.
Mielőtt üzembe helyez egy adat-kezdőzónát, vegye figyelembe az üzembe helyezni kívánt kezdeti adat-kezdőzónák számát.
Használja ezt az architektúrát kiindulási pontként. Töltse le a Visio-fájlt , és módosítsa úgy, hogy megfeleljen az adott üzleti és műszaki követelményeknek az adat-kezdőzóna implementálásának tervezésekor.
Alapszolgáltatások rétege
Az alapvető szolgáltatási réteg tartalmazza az összes olyan szolgáltatást, amely az adat-kezdőzónának a felhőalapú elemzés kontextusában való engedélyezéséhez szükséges. Az alábbi táblázat felsorolja azokat az erőforráscsoportokat, amelyek minden üzembe helyezett adat-kezdőzónában biztosítják az elérhető szolgáltatások standard csomagját.
| Erőforráscsoport | Kötelező | Leírás |
|---|---|---|
| network-rg | Igen | Networking |
| databricks-monitoring-rg | Lehetséges | Azure Databricks-munkaterületek monitorozása |
| hive-rg | Lehetséges | Hive metaadattár az Azure Databrickshez |
| storage-rg | Igen | Data Lakes-szolgáltatások |
| external-data-rg | Igen | Betöltési tárterület feltöltése |
| runtimes-rg | Igen | Megosztott integrációs futtatókörnyezetek |
| mgmt-rg | Igen | CI/CD-ügynökök |
| metadata-ingestion-rg | Lehetséges | Adatgnosztikus betöltés |
| databricks-monitoring-rg | Lehetséges | Log Analytics-munkaterület a célzónában lévő Databricks-munkaterületekhez |
| shared-synapse-rg | Lehetséges | Megosztott Azure Synapse |
| shared-databricks-rg | Lehetséges | Megosztott Azure Databricks-munkaterület |
Networking
A hálózati erőforráscsoport olyan alapvető összetevőket tartalmaz, mint az Azure Network Watcher, a hálózati biztonsági csoportok (NSG) és a virtuális hálózat. Ezek a szolgáltatások egyetlen erőforráscsoportba vannak üzembe helyezve.
Az adat-kezdőzóna virtuális hálózata automatikusan társviszonyba kerül az adatkezelési célzóna virtuális hálózatával és a kapcsolati előfizetés virtuális hálózatával.
Azure Databricks-munkaterületek monitorozása
Ez az erőforráscsoport nem kötelező, és csak az Azure Databricks használatával telepíthető.
Az Azure-beli kezdőzóna-minta azt javasolja, hogy minden naplót küldjön egy központi Log Analytics-munkaterületre. Azonban minden adat-kezdőzóna tartalmaz egy monitorozási erőforráscsoportot is a Spark-naplók Databricksből való rögzítéséhez. Minden erőforráscsoport tartalmaz egy megosztott Log Analytics-munkaterületet és egy Azure Key Vaultot a Log Analytics-kulcsok tárolásához.
Fontos
Az Azure Databricks Spark-naplók rögzítéséhez csak a Databricks monitorozási erőforráscsoportjának Log Analytics-munkaterületét használja.
További információ: Az Azure Databricks monitorozása.
Hive metaadattár az Azure Databrickshez
Ez az erőforráscsoport nem kötelező, és csak az Azure Databricksben lehet üzembe helyezni.
Az Azure Databricks Hive metaadattára kiépít egy Azure Database for MySQL-adatbázist és egy kulcstartót. Az adat-célzóna összes Azure Databricks-munkaterülete ezt a metaadattárat használja külső Apache Hive-metaadattárként.
További információ: Külső Apache Hive metaadattár.
Data lake-szolgáltatások
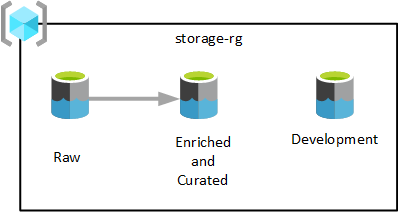
Ahogy az előző ábrán is látható, három Azure Data Lake Storage Gen2-fiók van kiépítve egyetlen Data Lake Services-erőforráscsoportban. A különböző fázisokban átalakított adatok az adat-kezdőzóna egyik adattójában lesznek mentve. Az adatok felhasználhatók az elemzési, adatelemzési és vizualizációs csapatok számára.
A Data Lake-rétegek a technológiától és a szállítótól függően eltérő terminológiát használnak. Ez a táblázat útmutatást nyújt a felhőalapú elemzések feltételeinek alkalmazásához:
| Felhőméretű elemzések | Delta Lake | Egyéb feltételek | Leírás |
|---|---|---|---|
| Nyers | Bronze | Leszállás és megfelelőség | Betöltési táblák |
| Dúsított | Silver | Szabványosítási zóna | Finomított táblák. Tárolt teljes entitás, fogyasztásra kész rekordhalmazok a rekordrendszerekből. |
| Kurátora | Gold | Termékzóna | Funkció- vagy összesített táblák. Elsődleges zóna az alkalmazások, csapatok és felhasználók számára az adattermékek felhasználásához. |
| Fejlesztés | -- | Fejlesztési zóna | Adatmérnökök és tudósok helye, amely egy elemzési tesztkörnyezetből és egy termékfejlesztési zónából áll. |
Megjegyzés:
Az előző ábrán minden adat-kezdőzóna három adattóval rendelkezik. A követelményektől függően azonban érdemes lehet a nyers, dúsított és válogatott rétegeket egy tárfiókba konszolidálni, és egy másik, "fejlesztésnek" nevezett tárfiókot fenntartani az adatfelhasználók számára, hogy más hasznos adattermékeket hozzanak létre.
For more information, see:
- Az Azure Data Lake Storage áttekintése felhőalapú elemzésekhez
- Adatszabványosítás
- Azure Data Lake Storage Gen2-fiókok kiépítése az egyes adat-kezdőzónákhoz
- Az Azure Data Lake Storage főbb szempontjai
- Hozzáférés-vezérlés és data lake-konfigurációk az Azure Data Lake Storage-ban
Betöltési tárterület feltöltése
A külső adatkiadóknak adatokat kell lekérniük a platformon, hogy az adatalkalmazási csapatok le tudják őket húzni a saját adattóikba. Az alábbi ábrán látható módon a feltöltési tárolási erőforráscsoport lehetővé teszi blobtárolók kiépítését harmadik felek számára.
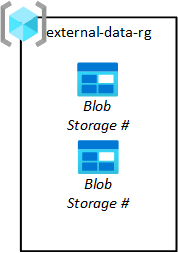
Az adatalkalmazás-csapatok kérik ezeket a tárolóblobokat. A kéréseket ezután az adat-kezdőzóna műveleti csapata hagyja jóvá. Az adatokat el kell távolítani a forrástároló-blobból, miután lekérte őket a tárolóblobból nyersre.
Fontos
Mivel az Azure Storage-blobok ki vannak építve igény szerint, először egy üres storage-szolgáltatási erőforráscsoportot kell üzembe helyeznie az egyes adat-kezdőzónákban.
Megosztott integrációs futtatókörnyezetek
Saját üzemeltetésű integrációs modulokkal rendelkező virtuális gép üzembe helyezése az adat-kezdőzónában. A megosztott integrációs erőforráscsoportban üzemeltetheti. Ez az üzembe helyezés lehetővé teszi, hogy gyorsan előkészítse az adattermékeket az adat-kezdőzónába.
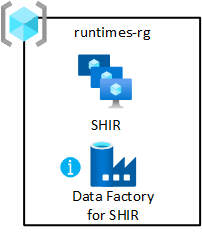
Az erőforráscsoport engedélyezése:
- Hozzon létre legalább egy Azure Data Factoryt az adat-kezdőzóna megosztott integrációs erőforráscsoportjában. Csak a megosztott, saját üzemeltetésű integrációs modul összekapcsolására használható, adatfolyamokhoz nem.
- Saját üzemeltetésű integrációs modul létrehozása és konfigurálása a virtuális gépen.
- Társítsa a saját üzemeltetésű integrációs modult az adat-kezdőzóna(ka)ban található Azure-adat-előállítókkal.
- Állítsa be az Azure Automationt a saját üzemeltetésű integrációs modul rendszeres frissítésére.
Megjegyzés:
A fenti üzembe helyezés egyetlen virtuálisgép-üzembe helyezést biztosít saját üzemeltetésű integrációs futtatókörnyezetekkel. Egy saját üzemeltetésű integrációs modult több helyszíni géphez vagy azure-beli virtuális géphez is társíthat. Ezeket a gépeket csomópontoknak nevezzük. Egy saját üzemeltetésű integrációs modulhoz legfeljebb négy csomópont társítható. A logikai átjáróhoz telepített átjáróval rendelkező helyszíni gépek több csomópontjának előnyei a következők:
- A saját üzemeltetésű integrációs futtatókörnyezet magasabb rendelkezésre állása, hogy többé ne ez legyen a big data-megoldás vagy a felhőbeli adatintegráció egyetlen meghibásodási pontja. Ez a rendelkezésre állás biztosítja a folytonosságot, ha legfeljebb négy csomópontot használ.
- Jobb teljesítmény és átviteli sebesség a helyszíni és a felhőbeli adattárak közötti adatáthelyezés során. További információ a teljesítmény-összehasonlításokról.
Több csomópontot is társíthat, ha telepíti a saját üzemeltetésű integrációs modul szoftverét a Letöltőközpontból. Ezután regisztrálja a New-AzDataFactoryV2IntegrationRuntimeKey parancsmagból beszerzett hitelesítési kulcsok egyikével, az oktatóanyagban leírtak szerint.
A futher-információkat az Azure Datafactory magas rendelkezésre állása és méretezhetősége tartalmazza.
Fontos
A megosztott integrációs modulokat a lehető legközelebb helyezzen üzembe az adatforráshoz. Az üzembe helyezésük nem korlátozza az integrációs futtatókörnyezetek adat-kezdőzónában vagy külső felhőkben való üzembe helyezését. Ehelyett tartalékot biztosít a natív felhőbeli, régión belüli adatforrásokhoz.
CI/CD-ügynökök
A CI/CD-ügynökök segítenek az adatalkalmazások üzembe helyezésében és az adat-kezdőzónában végzett módosításokban.
További információ: Azure Pipeline-ügynökök.
Adatgnosztikus betöltés
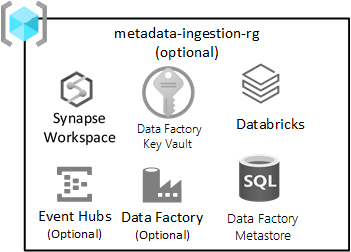
Ez az erőforráscsoport nem kötelező, és nem tiltja meg a kezdőzóna üzembe helyezését.
Ez az erőforráscsoport akkor érvényes, ha rendelkezik (vagy fejleszt) egy adatelemzési betöltési motort az adatok automatikus betöltéséhez a metaadatok regisztrálása alapján (beleértve a kapcsolati sztring, az adatok másolási útvonalát és a betöltési ütemezést). A betöltési és feldolgozási erőforráscsoport kulcsfontosságú szolgáltatásokkal rendelkezik az ilyen típusú keretrendszerekhez.
Helyezzen üzembe egy Azure SQL Database-példányt az Azure Data Factory által használt metaadatok tárolásához. Azure Key Vault kiépítése az automatizált betöltési szolgáltatásokhoz kapcsolódó titkos kódok tárolására. Ezek a titkos kódok a következők lehetnek:
- Azure Data Factory metaadattár hitelesítő adatai
- Szolgáltatásnév hitelesítő adatai az automatizált betöltési folyamathoz
További információ: Hogyan támogatják az automatizált betöltési keretrendszerek a felhőalapú elemzéseket az Azure-ban.
Az erőforráscsoportban szereplő szolgáltatások a következők:
| Szolgáltatás | Szükséges | Guidelines |
|---|---|---|
| Azure Data Factory | Igen | Az Azure Data Factory az adatelemzés vezénylési motorja. |
| Azure SQL DB | Igen | Az Azure SQL DB az Azure Data Factory metaadattára. |
| Event Hubs vagy IoT Hub | Lehetséges | Az Event Hubs vagy az IoT Hub valós idejű streamelést biztosít az Event Hubsba, valamint kötegelt és streamelési feldolgozást egy Databricks mérnöki munkaterületen keresztül. |
| Azure Databricks | Lehetséges | Üzembe helyezheti az Azure Databrickset vagy az Azure Synapse Sparkot az adatbetöltési motorral való használatra. |
| Azure Synapse | Lehetséges | Üzembe helyezheti az Azure Databrickset vagy az Azure Synapse Sparkot az adatbetöltési motorral való használatra. |
Megosztott Databricks
Ez az erőforráscsoport nem kötelező, és csak az Azure Databricks használatával telepíthető. Az adat-kezdőzónában mindenki használhat Databricks-munkaterületet.
Az Azure Databricks az Azure Data Lake Storage szolgáltatás kulcsfontosságú felhasználója. Az atomi fájlműveletek Spark-elemzési motorokhoz vannak optimalizálva. Ez az optimalizálás felgyorsítja az Azure Databricks szolgáltatás által problémákat okozó Spark-feladatok befejezését.
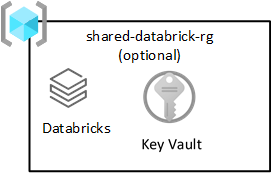
Fontos
Egy Azure Databricks-munkaterület, az Azure Databricks (elemzési) munkaterület minden adatelemző és DataOps számára ki van építve, ahogyan az a megosztott termékek erőforráscsoportjában látható.
Ezt a munkaterületet úgy konfigurálhatja, hogy csatlakozzon az Azure Data Lake-hez a Microsoft Entra átengedés vagy a táblahozzáférés-vezérlés használatával. A használati esettől függően a feltételes hozzáférést másik biztonsági mértékként is konfigurálhatja.
Kövesse a felhőalapú elemzés ajánlott eljárásait az Azure Databricks integrálásához:
- Biztonságos hozzáférés az Azure Data Lake Gen2-hez az Azure Databricksből
- Azure Databricks – ajánlott eljárások
Az Azure-beli kezdőzóna-minta azt javasolja, hogy minden naplót küldjön egy központi Log Analytics-munkaterületre. Az adat-kezdőzónák azonban egy monitorozási erőforráscsoportot is tartalmaznak a Spark-naplók Databricksből való rögzítéséhez.
Megosztott Azure Synapse Analytics
Ez az erőforráscsoport nem kötelező.
Az adat-kezdőzóna kezdeti beállítása során egyetlen Azure Synapse Analytics-munkaterület lesz üzembe helyezve a megosztott termékek erőforráscsoportjának összes adatelemzője és tudósa számára.
Ha költségkezelésre és feltöltésre van szükség, több synapse-munkaterületet is beállíthat adattermékekhez. Az adatalkalmazás-csapatok dedikált Azure Synapse Analytics-munkaterületeket használhatnak dedikált Azure SQL Database-készletek létrehozásához a vizualizációs réteg által használt olvasási adattárként.
Fontos
A megosztott Azure Synapse-munkaterület adattermék-létrehozáshoz való használatának megakadályozásához zárolja a munkaterületet, hogy csak igény szerinti SQL-lekérdezéseket engedélyezzen. Csak kizsákmányoló célokra létezik.
Adatalkalmazás
Minden adat-kezdőzóna több adatterméket tartalmazhat. Ezeket az adattermékeket úgy hozhatja létre, hogy adatokat használ a forrásból. Adattermékeket más adattermékekből is létrehozhat ugyanahhoz az adat-célzónához vagy más adat-célzónához. Az adattermékek adattermék-létrehozásának feltétele az adatgondnok jóváhagyása.
Adattermék erőforráscsoportja
Az adattermék erőforráscsoport terméke tartalmazza az adattermék létrehozásához szükséges összes szolgáltatást. Például egy Azure Database szükséges a MySQL-hez, amelyet egy vizualizációs eszköz használ. Az adatokat be kell venni és át kell alakítani, mielőtt azok a MySQL-adatbázisba kerülnek. Ebben az esetben üzembe helyezheti az Azure Database for MySQL-t és egy Azure Data Factoryt az adattermék-erőforráscsoportban.
Tipp.
Ha úgy dönt, hogy nem implementál egy adatelemzési motort a működési forrásokból való egyszeri betöltéshez, vagy ha az adatelemzési motor nem segíti elő az összetett kapcsolatokat, hozzon létre egy forráshoz igazított adatalkalmazást. További információ: Adatalkalmazások (forráshoz igazított)
Az adattermékek előkészítéséről további információt a felhőalapú elemzési adattermékek az Azure-ban című témakörben talál.
Visualization
Minden adat-kezdőzónához létrejön egy üres vizualizációs erőforráscsoport. Töltse ki ezt az erőforráscsoportot a vizualizációs megoldás implementálásához szükséges szolgáltatásokkal. A meglévő virtuális hálózat használatával a megoldás csatlakozhat az adattermékekhez.
Ez az erőforráscsoport képes virtuális gépeket üzemeltetni külső vizualizációs szolgáltatásokhoz.
Tipp.
A licencelési költségek miatt gazdaságosabb lehet külső vizualizációs termékeket üzembe helyezni az adatkezelési célzónában, és ezeknek a termékeknek az adat-kezdőzónák között csatlakozniuk az adatok visszahívásához.