Ajánlott eljárások felhőalapú elemzéssel rendelkező adatelemzési projektekhez az Azure-ban
Ezeket az ajánlott eljárásokat javasoljuk, ha felhőalapú elemzéseket használ a Microsoft Azure-ban az adatelemzési projektek üzembe viteléhez.
Sablon fejlesztése
Olyan sablont fejleszthet, amely az adatelemzési projektekhez kapcsolódó szolgáltatások készletét köti össze. A különböző adatelemzési csapatok használati eseteinek konzisztenciájának biztosításához használjon olyan sablont, amely szolgáltatáscsomagokat köt össze. Javasoljuk, hogy egységes tervet dolgozzon ki sablontárház formájában. Ezt az adattárat a vállalaton belüli különböző adatelemzési projektekhez használhatja az üzembe helyezési idők lerövidítéséhez.
Az adatelemzési sablonokra vonatkozó irányelvek
Az alábbi irányelvekkel fejleszthet adatelemzési sablont a szervezet számára:
Az Azure Machine Tanulás-munkaterület üzembe helyezéséhez kódként (IaC) létrehozott infrastruktúrasablonokat fejleszthet. Tartalmazzon olyan erőforrásokat, mint a kulcstartó, a tárfiók, a tárolóregisztrációs adatbázis és az alkalmazás Elemzések.
Ezekben a sablonokban vegye fel az adattárak és számítási célok beállítását, például a számítási példányokat, a számítási fürtöket és az Azure Databrickset.
Ajánlott üzembe helyezési eljárások
Valós idejű
- Azure Data Factory- vagy Azure Synapse-üzembe helyezés belefoglalása sablonokba és Azure Cognitive Servicesbe.
- A sablonoknak minden szükséges eszközt biztosítaniuk kell az adatelemzési feltárási fázis és a modell kezdeti üzembehelyezéséhez.
A kezdeti beállítás szempontjai
Bizonyos esetekben előfordulhat, hogy a szervezet adattudósai egy környezetet igényelnek a gyors, igény szerinti elemzéshez. Ez a helyzet akkor gyakori, ha egy adatelemzési projekt formálisan nincs beállítva. Előfordulhat például, hogy hiányzik egy projektmenedzser, költségkód vagy költséghely, amelyre szükség lehet az Azure-on belüli keresztterheléshez, mert a hiányzó elemnek jóváhagyásra van szüksége. Előfordulhat, hogy a szervezet vagy csapat felhasználóinak hozzá kell férnie egy adatelemzési környezethez az adatok megértéséhez és a projekt megvalósíthatóságának kiértékeléséhez. Emellett előfordulhat, hogy egyes projektek nem igényelnek teljes adatelemzési környezetet a kevés adattermék miatt.
Más esetekben teljes körű adatelemzési projektre lehet szükség, amely dedikált környezettel, projektkezeléssel, költségkóddal és költségközponttal van kiegészítve. A teljes adatelemzési projektek több csapattag számára hasznosak, akik közösen szeretnének dolgozni, megosztják az eredményeket, és a feltárási fázis sikeres végrehajtása után működésbe kell helyezniük a modelleket.
A beállítási folyamat
A sablonokat a beállításuk után projektenként kell üzembe helyezni. Minden projektnek legalább két példányt kell kapnia a fejlesztési és éles környezetek elkülönítéséhez. Éles környezetben egyetlen személy sem rendelkezhet hozzáféréssel, és minden üzembe helyezhető folyamatos integrációs vagy folyamatos fejlesztési folyamatokkal és szolgáltatásnévvel. Ezek az éles környezet alapelvei azért fontosak, mert az Azure Machine Tanulás nem biztosít részletes szerepköralapú hozzáférés-vezérlési modellt a munkaterületen belül. A felhasználók hozzáférését nem korlátozhatja bizonyos kísérletekhez, végpontokhoz vagy folyamatokhoz.
Ugyanezek a hozzáférési jogosultságok általában különböző típusú összetevőkre vonatkoznak. Fontos elkülöníteni a fejlesztést az élestől, hogy megakadályozza az éles folyamatok vagy végpontok törlését egy munkaterületen. A sablonnal együtt létre kell tenni egy folyamatot, amely lehetővé teszi az adattermék-csapatok számára az új környezetek kérését.
Javasoljuk, hogy projektenként állítson be különböző AI-szolgáltatásokat, például az Azure Cognitive Servicest. Ha projektenként különböző AI-szolgáltatásokat állít be, az egyes adattermék-erőforráscsoportok esetében üzembe helyezés történik. Ez a szabályzat egyértelmű elkülönítést hoz létre az adathozzáférés szempontjából, és csökkenti a nem megfelelő csapatok jogosulatlan adathozzáférésének kockázatát.
Streamelési forgatókönyv
Valós idejű és streamelési használati esetek esetén az üzemelő példányokat tesztelni kell egy lesüllyesztett Azure Kubernetes Service-en (AKS). A tesztelés a fejlesztési környezetben is lehet, hogy költségmegtakarítást eredményez, mielőtt üzembe helyezené az éles AKS-ben vagy a tárolókhoz készült Azure-alkalmazás szolgáltatásban. Egyszerű bemeneti és kimeneti teszteket kell végeznie, hogy a szolgáltatások a várt módon válaszoljanak.
Ezután modelleket helyezhet üzembe a kívánt szolgáltatásban. Ez az üzembe helyezési számítási cél az egyetlen, amely általánosan elérhető és ajánlott éles számítási feladatokhoz egy AKS-fürtben. Ez a lépés akkor szükséges, ha grafikus feldolgozási egységre (GPU) vagy mezőre programozható kaputömb-támogatásra van szükség. A hardverkövetelményeket támogató egyéb natív üzembehelyezési lehetőségek jelenleg nem érhetők el az Azure Machine Tanulás.
Az Azure Machine Tanulás egy-az-egyhez leképezést igényel az AKS-fürtökhöz. Az Azure Machine Tanulás-munkaterület minden új kapcsolata megszakítja az AKS és az Azure Machine Tanulás közötti előző kapcsolatot. A korlátozás enyhítése után javasoljuk, hogy központi AKS-fürtöket helyezzen üzembe megosztott erőforrásként, és csatolja őket a megfelelő munkaterületekhez.
Egy másik központi teszt AKS-példányt kell üzemeltetni, ha stresszteszteket kell végezni a modell éles AKS-be való áthelyezése előtt. A tesztkörnyezetnek ugyanazt a számítási erőforrást kell biztosítania, mint az éles környezetben, hogy az eredmények a lehető legnagyobb mértékben hasonlíthassanak az éles környezethez.
Batch-forgatókönyv
Nem minden használati esethez van szükség AKS-fürt üzembe helyezésére. A használati esethez nincs szükség AKS-fürt üzembe helyezésére, ha a nagy adatmennyiségek csak rendszeres pontozást igényelnek, vagy eseményen alapulnak. A nagy adatmennyiségek például attól függhetnek, hogy az adatok mikor kerülnek egy adott tárfiókba. Az ilyen típusú forgatókönyvek során az Azure Machine Tanulás-folyamatokat és az Azure Machine Tanulás számítási fürtöket kell használni az üzembe helyezéshez. Ezeket a folyamatokat a Data Factoryben kell összehangolni és végrehajtani.
A megfelelő számítási erőforrások azonosítása
Mielőtt üzembe helyez egy modellt az Azure Machine Tanulás egy AKS-ben, a felhasználónak meg kell adnia azokat az erőforrásokat, mint a CPU, a RAM és a GPU, amelyeket az adott modellhez kell lefoglalni. Ezeknek a paramétereknek a meghatározása összetett és fárasztó folyamat lehet. A paraméterek jó készletének azonosításához különböző konfigurációkkal kell stresszteszteket végeznie. Ezt a folyamatot egyszerűsítheti az Azure Machine Tanulás modellprofilozási funkciójával, amely egy hosszú ideig futó feladat, amely különböző erőforrás-foglalási kombinációkat tesztel, és azonosított késést és utazási időt (RTT) használ az optimális kombinációk ajánlásához. Ezek az információk segíthetnek a modell tényleges üzembe helyezésében az AKS-en.
Az Azure Machine Tanulás modelljeinek biztonságos frissítéséhez a csapatoknak a szabályozott bevezetési funkcióval (előzetes verzió) kell minimalizálni az állásidőt, és konzisztensen kell tartaniuk a modell REST-végpontját.
Ajánlott eljárások és az MLOps munkafolyamata
Mintakód belefoglalása adatelemzési adattárakba
Egyszerűsítheti és felgyorsíthatja az adatelemzési projekteket, ha a csapatok bizonyos összetevőket és ajánlott eljárásokat alkalmaznak. Javasoljuk, hogy olyan összetevőket hozzon létre, amelyeket minden adatelemzési csapat használhat az Azure Machine Tanulás és az adattermék-környezet megfelelő eszközeinek használata során. Az adat- és gépi tanulási mérnököknek létre kell hozniuk és biztosítaniuk kell az összetevőket.
Az összetevőknek tartalmazniuk kell a következőket:
Mintajegyzetfüzetek, amelyek a következő lépéseket mutatják be:
- Adattermékek betöltése, csatlakoztatása és használata.
- Naplómetrikák és paraméterek.
- Betanítási feladatok elküldése számítási fürtöknek.
Az üzemeltetéshez szükséges összetevők:
- Azure Machine-Tanulás-folyamatok mintája
- Azure Pipelines-minta
- További szkriptek szükségesek a folyamatok végrehajtásához
Dokumentáció
Folyamatok üzembe helyezése jól megtervezett összetevők használatával
Az összetevők felgyorsíthatják az adatelemzési projektek feltárási és üzemeltetési fázisait. A DevOps-elágaztatási stratégia segíthet ezeknek az összetevőknek az összes projektre kiterjedő skálázásában. Mivel ez a beállítás elősegíti a Git használatát, a felhasználók és az általános automatizálási folyamat kihasználhatja a megadott összetevők előnyeit.
Tipp.
Az Azure Machine Tanulás mintafolyamatokat a Python szoftverfejlesztői készlettel (SDK) vagy a YAML nyelv alapján kell felépíteni. Az új YAML-élmény időtállóbb lesz, mivel az Azure Machine Tanulás termékcsapata jelenleg egy új SDK-n és parancssori felületen (CLI) dolgozik. Az Azure Machine Tanulás termékcsapata biztos abban, hogy a YAML az Azure Machine Tanulás összes összetevőjének definíciónyelve lesz.
A mintafolyamatok nem működnek ki az egyes projektek dobozából, de alapkonfigurációként használhatók. A projektek mintafolyamatait módosíthatja. A folyamatoknak tartalmazniuk kell az egyes projektek legrelevánsabb szempontjait. Egy folyamat például hivatkozhat egy számítási célra, hivatkozhat adattermékekre, definiálhat paramétereket, definiálhat bemeneteket, és meghatározhatja a végrehajtási lépéseket. Ugyanezt a folyamatot kell elvégezni az Azure Pipelines esetében is. Az Azure Pipelinesnak az Azure Machine Tanulás SDK-t vagy parancssori felületet is használnia kell.
A folyamatoknak be kell mutatniuk, hogyan:
- Csatlakozás egy munkaterületre egy DevOps-folyamaton belülről.
- Ellenőrizze, hogy elérhető-e a szükséges számítás.
- Feladat elküldése.
- Modell regisztrálása és üzembe helyezése.
Az összetevők nem minden projekthez használhatók, és testreszabást igényelhetnek, de az alapozás felgyorsíthatja a projekt üzembe helyezését és üzembe helyezését.
Az MLOps-adattár felépítése
Előfordulhat, hogy a felhasználók nem tudják nyomon követni, hogy hol találhatják meg és tárolhatják az összetevőket. Az ilyen helyzetek elkerülése érdekében több időt kell kérnie a kommunikációra, és létre kell készítenie egy legfelső szintű mappastruktúrát a standard adattárhoz. Minden projektnek követnie kell a mappastruktúrát.
Feljegyzés
Az ebben a szakaszban említett fogalmak a helyszínen, az Amazon Web Servicesben, a Palantirban és az Azure-környezetben használhatók.
Az MLOps(gépi tanulási műveletek) adattár javasolt legfelső szintű mappastruktúráját az alábbi ábra szemlélteti:
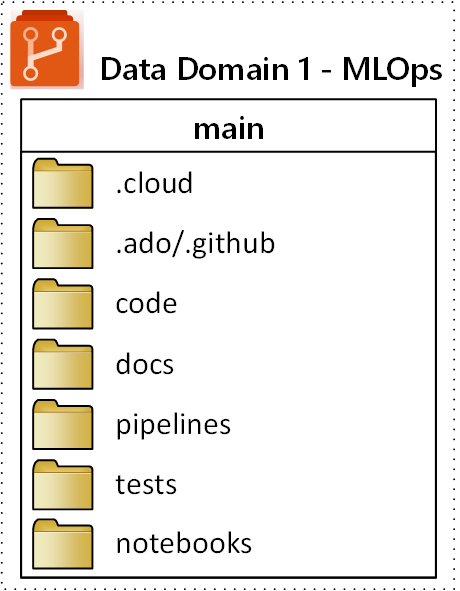
A következő célok vonatkoznak az adattár egyes mappáira:
| Mappa | Cél |
|---|---|
.cloud |
Ebben a mappában tárolhatja a felhőspecifikus kódot és összetevőket. Az összetevők közé tartoznak az Azure Machine Tanulás-munkaterület konfigurációs fájljai, beleértve a számítási céldefiníciókat, a feladatokat, a regisztrált modelleket és a végpontokat. |
.ado/.github |
Ebben a mappában tárolhat Azure DevOps- vagy GitHub-összetevőket, például YAML-folyamatokat vagy kódtulajdonosokat. |
code |
Adja meg a projekt részeként kifejlesztett tényleges kódot ebben a mappában. Ez a mappa tartalmazhat Python-csomagokat és a gépi tanulási folyamat megfelelő lépéseihez használt szkripteket. Javasoljuk az egyes lépések elkülönítését, amelyeket ebben a mappában kell elvégezni. Gyakori lépések az előfeldolgozás, a modell betanítása és a modellregisztráció. Minden mappához definiáljon függőségeket, például Conda-függőségeket, Docker-lemezképeket vagy másokat. |
docs |
Ezt a mappát dokumentációs célokra használhatja. Ez a mappa Markdown-fájlokat és képeket tárol a projekt leírásához. |
pipelines |
Ebben a mappában tárolhatja az Azure Machine Tanulás folyamatdefinícióit a YAML-ben vagy a Pythonban. |
tests |
Olyan egység- és integrációs teszteket írhat, amelyeket a mappában található projekt korai szakaszában kell felderíteni a hibák és problémák felderítéséhez. |
notebooks |
Különítse el a Jupyter-jegyzetfüzeteket a tényleges Python-projekttől ezzel a mappával. A mappában minden egyes személynek rendelkeznie kell egy almappával a jegyzetfüzetek beadásához és a Git-egyesítési ütközések megelőzéséhez. |
Következő lépés
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: