Beszédelemek címkézése a Language Studióban
Miután létrehozott egy sémát a projekthez, betanítási beszédelemeket kell hozzáadnia a projekthez. A kimondott szövegeknek hasonlónak kell lenniük ahhoz, amit a felhasználók használni fognak a projekttel való interakció során. Kimondott szöveg hozzáadásakor ki kell osztania, hogy melyik szándékhoz tartozik. A kimondott szöveg hozzáadása után címkézze fel a kimondott szöveg azon szavait, amelyeket entitásként szeretne kinyerni.
Az adatcímkézés kulcsfontosságú lépés a fejlesztési életciklusban; ezeket az adatokat a következő lépésben fogjuk használni a modell betanításakor, hogy a modell tanulhassa a címkézett adatokból. Ha már rendelkezik kimondott szövegekkel, közvetlenül importálhatja a projektbe, de meg kell győződnie arról, hogy az adatok megfelelnek az elfogadott adatformátumnak. A címkézett adatok projektbe való importálásáról további információt a Projekt létrehozása című témakörben talál. A címkézett adatok tájékoztatják a modellt a szöveg értelmezéséről, és a betanításhoz és a kiértékeléshez használatosak.
Előfeltételek
Az adatok címkézéséhez a következőkre van szükség:
- Egy sikeresen létrehozott projekt.
További információért tekintse meg a projektfejlesztési életciklust .
Adatcímkézési irányelvek
A séma létrehozása és a projekt létrehozása után fel kell címkéznie az adatokat. Az adatok címkézése fontos, hogy a modell tudja, mely szavak és mondatok lesznek társítva a projekt szándékaival és entitásaival. Időt szeretne tölteni a kimondott szövegek címkézésével – a modellek betanításához használt adatok bevezetésével és finomításával.
A kimondott szövegek hozzáadása és címkézése során tartsa szem előtt a következőket:
A gépi tanulási modellek az Ön által megadott címkézett példák alapján általánosulnak; minél több példát ad meg, annál több adatpontra van szüksége a modellnek, hogy jobb általánosításokat hozzon létre.
A címkézett adatok pontossága, következetessége és teljessége kulcsfontosságú tényező a modell teljesítményének meghatározásához.
- Pontos címkézés: Minden szándékot és entitást mindig a megfelelő típusra címkézzen. Csak a besorolni és kinyerni kívánt adatokat foglalja bele, kerülje a felesleges adatokat a címkékben.
- Következetes címkézés: Ugyanazon entitásnak minden kimondott szövegben ugyanazzal a címkével kell rendelkeznie.
- Teljes címkézés: Változatos kimondott szövegeket adhat meg minden szándékhoz. Címkézze fel az entitás összes példányát az összes kimondott szövegben.
Kimondott szövegek egyértelmű címkézése
Győződjön meg arról, hogy az entitások által hivatkozott fogalmak jól definiáltak és elválaszthatók. Ellenőrizze, hogy könnyen meg tudja-e állapítani a különbségeket megbízhatóan. Ha nem, ez arra utalhat, hogy a tanult összetevő is nehézségekbe ütközik.
Ha van hasonlóság az entitások között, győződjön meg arról, hogy az adatoknak van olyan aspektusa, amely jelzi a különbséget.
Ha például egy repülőjáratok lefoglalására szolgáló modellt készített, a felhasználók olyan beszédelemeket használhatnak, mint a "Szeretnék egy járatot Bostonból Seattle-be". Az ilyen kimondott szövegek forrás- és célvárosa várhatóan hasonló lesz. A "Forrás város" megkülönböztetésére az lehet a jelzés, hogy ezt gyakran megelőzi a "from" szó.
Győződjön meg arról, hogy a betanítási és a tesztelési adatokban minden entitáspéldányt címkéz. Az egyik módszer a keresési függvény használata egy szó vagy kifejezés összes előfordulásának megkeresésére az adatokban annak ellenőrzéséhez, hogy helyesen vannak-e címkézve.
A tesztelési adatok címkézése olyan entitások esetében, amelyek nem rendelkeznek tanult összetevővel , valamint azokhoz is, amelyek igen. Ez segít biztosítani, hogy a kiértékelési metrikák pontosak legyenek.
Többnyelvű projektek esetén a beszédelemek más nyelveken való hozzáadása növeli a modell teljesítményét ezeken a nyelveken, de ne duplikálja az adatokat az összes támogatott nyelven. Ha például egy calender-robot teljesítményét szeretné javítani a felhasználókkal, a fejlesztők többnyire angolul, néhányat pedig spanyolul vagy franciául is hozzáadhatnak. Az alábbiakhoz hasonló beszédelemeket adhatnak hozzá:
- "Holnap 12-kor találkozunk Matttel és Kevinnel." (angol)
- "Válasz feltételesként a heti frissítési értekezletre." (angol)
- "Cancelar mi próxima reunión." (spanyol)
Beszédelemek címkézése
A kimondott szövegek címkézéséhez kövesse az alábbi lépéseket:
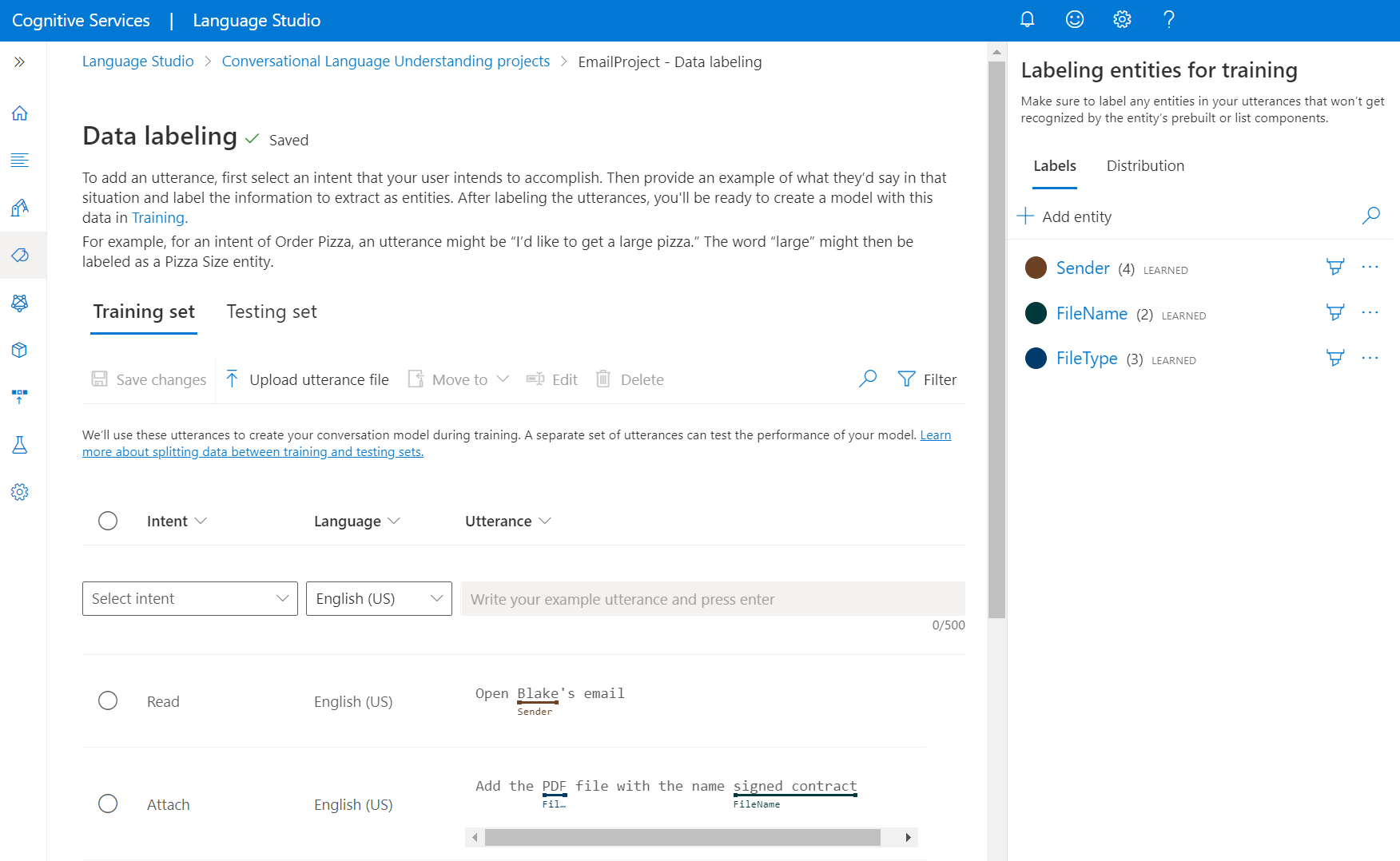
Nyissa meg a projekt lapját a Language Studióban.
A bal oldali menüben válassza az Adatok címkézése lehetőséget. Ezen a lapon elkezdheti a kimondott szöveg hozzáadását és címkézését. A kimondott szöveget közvetlenül is feltöltheti a felső menü Kimondott szöveg feltöltése fájljának feltöltése elemére kattintva, és győződjön meg arról, hogy az megfelel az elfogadott formátumnak.
A felső kimutatásokban módosíthatja a nézetet betanítási vagytesztelési készletre. További információ a betanítási és tesztelési készletekről , valamint a modellek betanításához és értékeléséhez való használatukról.
Tipp
Ha a tesztelési csoport automatikus felosztását tervezi a betanítási adatok felosztásából , adja hozzá az összes kimondott szöveget a betanítási készlethez.
A Szándék kiválasztása legördülő menüben válassza ki az egyik szándékot, a kimondott szöveg nyelvét (többnyelvű projektek esetén) és magát a kimondott szöveget. Nyomja le az enter billentyűt a kimondott szöveg szövegmezőjében a kimondott szöveg hozzáadásához.
Egy kimondott szövegben kétféleképpen címkézhet entitásokat:
Beállítás Leírás Címke ecsettel Válassza a jobb oldali panelen az entitás melletti ecset ikont, majd jelölje ki a címkézni kívánt kimondott szöveg szövegét. Címke beágyazott menüvel Jelölje ki az entitásként címkézni kívánt szót, és megjelenik egy menü. Jelölje ki azt az entitást, amellyel fel szeretné címkézni ezeket a szavakat. A jobb oldali panel Címkék kimutatása alatt megtalálhatja a projekt összes entitástípusát és a címkézett példányok számát egyenként.
A Terjesztési kimutatás alatt megtekintheti a betanítási és tesztelési csoportok közötti eloszlást. Két lehetősége van a megtekintésre:
- Összes példány címkézett entitásonként , ahol megtekintheti egy adott entitás összes címkézett példányának számát.
- Egyedi kimondott szövegek címkézett entitásonként , ahol az egyes kimondott szövegek meg vannak számlálva, ha az entitás legalább egy címkézett példányát tartalmazza.
- Kimondott szövegek szándékonként , ahol megtekintheti a kimondott szövegek szándékonkénti számát.


Megjegyzés
A lista- és előre összeállított összetevők nem jelennek meg az adatcímkézési oldalon, és az összes címke csak a tanult összetevőre vonatkozik.
Címke eltávolítása:
- A kimondott szövegen belül válassza ki azt az entitást, amelyből címkét szeretne eltávolítani.
- Görgessen végig a megjelenő menün, és válassza a Címke eltávolítása lehetőséget.
Entitás törlése:
- Válassza ki a szerkeszteni kívánt entitást a jobb oldali panelen.
- Válassza ki az entitás melletti három elemet, és válassza ki a kívánt lehetőséget a legördülő menüből.
Kimondott szövegek ajánlása az Azure OpenAI-val
A CLU-ban az Azure OpenAI használatával javasoljon kimondott szövegeket a projekthez GPT-modellek használatával. Először hozzáférést kell kérnie, és létre kell hoznia egy erőforrást az Azure OpenAI-ban. Ezután létre kell hoznia egy üzembe helyezést a GPT-modellekhez. Kövesse az előfeltételként szükséges lépéseket itt.
Az első lépések előtt a kimondott szövegek javasolása funkció csak akkor érhető el, ha a nyelvi erőforrás a következő régiókban található:
- USA keleti régiója
- USA déli középső régiója
- Nyugat-Európa
Az Adatcímkézés lapon:
- Válassza a Kimondott szövegek javasolása gombot. A jobb oldalon megnyílik egy panel, amely arra kéri, hogy válassza ki az Azure OpenAI-erőforrást és -üzembe helyezést.
- Egy Azure OpenAI-erőforrás kiválasztása esetén válassza a Csatlakozás lehetőséget, amely lehetővé teszi, hogy a nyelvi erőforrás közvetlen hozzáféréssel rendelkezzen az Azure OpenAI-erőforráshoz. Hozzárendeli a nyelvi erőforrás szerepkörét
Cognitive Services Useraz Azure OpenAI-erőforráshoz, amely lehetővé teszi, hogy az aktuális nyelvi erőforrás hozzáférjen az Azure OpenAI szolgáltatásához. Ha a kapcsolat sikertelen, kövesse az alábbi lépéseket a megfelelő szerepkör manuális hozzáadásához az Azure OpenAI-erőforráshoz. - Az erőforrás csatlakoztatása után válassza ki az üzembe helyezést. Az Azure OpenAI üzembe helyezéséhez ajánlott modell a következő
text-davinci-002: . - Válassza ki azt a szándékot, amelyhez javaslatokat szeretne kapni. Győződjön meg arról, hogy a kiválasztott szándékban legalább 5 mentett kimondott szöveg van engedélyezve a kimondott szövegjavaslatokhoz. Az Azure OpenAI javaslatai az adott szándékhoz hozzáadott legutóbbi kimondott szövegeken alapulnak.
- Válassza a Kimondott szövegek létrehozása lehetőséget. Ha elkészült, a javasolt kimondott szövegek pontozott vonallal jelennek meg körülötte, a következő megjegyzéssel: AI által generált. Ezeket a javaslatokat el kell fogadni vagy el kell utasítani. Ha elfogad egy javaslatot, egyszerűen hozzáadja a projekthez, mintha saját maga adta volna hozzá. Az elutasítás teljes egészében törli a javaslatot. Csak az elfogadott kimondott szövegek lesznek a projekt részei, és betanításra vagy tesztelésre használhatók. Az egyes kimondott szövegek melletti zöld pipa vagy piros mégse gombra kattintva elfogadhatja vagy elutasíthatja azokat. Az eszköztáron a és
Reject allaAccept allgombot is használhatja.

Ennek a funkciónak a használata az Azure OpenAI-erőforrást terheli a létrehozott javasolt kimondott szövegekhez hasonló számú jogkivonatért. Az Azure OpenAI díjszabásának részletei itt találhatók.
Szükséges konfigurációk hozzáadása az Azure OpenAI-erőforráshoz
Ha nem sikerül csatlakoztatni a nyelvi erőforrást egy Azure OpenAI-erőforráshoz, kövesse az alábbi lépéseket:
Engedélyezze az identitáskezelést a nyelvi erőforráshoz az alábbi beállításokkal:
A nyelvi erőforrásnak identitáskezeléssel kell rendelkeznie az Azure Portal használatával való engedélyezéséhez:
- Nyissa meg a nyelvi erőforrást
- A bal oldali menü Erőforrás-kezelés szakaszában válassza az Identitás lehetőséget
- A Rendszer által hozzárendelt lapon győződjön meg arról, hogy be van kapcsolva az Állapot
A felügyelt identitás engedélyezése után rendelje hozzá a szerepkört Cognitive Services User az Azure OpenAI-erőforráshoz a language erőforrás felügyelt identitásával.
- Jelentkezzen be a Azure Portal, és navigáljon az Azure OpenAI-erőforráshoz.
- Válassza a bal oldali Access Control (IAM) lapot.
- Válassza a Szerepkör-hozzárendelés hozzáadása > lehetőséget.
- Válassza a "Feladatfüggvényszerepkörök" lehetőséget, majd kattintson a Tovább gombra.
- Válasszon
Cognitive Services Usera szerepkörök listájából, és kattintson a Tovább gombra. - Válassza a Hozzáférés hozzárendelése a "Felügyelt identitáshoz" lehetőséget, majd válassza a "Tagok kiválasztása" lehetőséget.
- A "Felügyelt identitás" területen válassza a "Nyelv" lehetőséget.
- Keresse meg az erőforrást, és válassza ki. Ezután kattintson az alábbi Kiválasztás gombra, majd a folyamat befejezéséhez.
- Tekintse át a részleteket, és válassza a Véleményezés + Hozzárendelés lehetőséget.

Néhány perc múlva frissítse a Language Studiót, és sikeresen csatlakozhat az Azure OpenAI-hoz.