Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A KÖVETKEZŐKRE VONATKOZIK:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Gremlin
Gremlin
Fontos
Az Azure Cosmos DB tükrözése a Microsoft Fabricben már elérhető a NoSql API-hoz. Ez a funkció az Azure Synapse Link összes funkcióját biztosítja jobb elemzési teljesítménnyel, lehetővé teszi az adatvagyon egységesítését a Fabric OneLake-tel, és delta parquet formátumban nyithatja meg az adatokhoz való hozzáférést. Ha az Azure Synapse Linket fontolgatja, javasoljuk, hogy próbálkozzon tükrözéssel a szervezet általános megfelelőségének felméréséhez. Ismerkedés a tükrözéssel a Microsoft Fabricben.
Az Azure Synapse Link használatának megkezdéséhez látogasson el az "Azure Synapse Link használatának első lépései" című lapra .
Az Azure Cosmos DB elemzési tár egy teljesen elkülönített oszloptároló, amely lehetővé teszi a nagy méretű elemzéseket az Azure Cosmos DB működési adataival szemben anélkül, hogy ez hatással lenne a tranzakciós számítási feladatokra.
Az Azure Cosmos DB tranzakciós tároló sémafüggetlen, és lehetővé teszi a tranzakciós alkalmazások iterálását anélkül, hogy sémával vagy indexkezeléssel kellene foglalkoznia. Ezzel szemben az Azure Cosmos DB elemzési tárolója séma szerint van kialakítva, hogy optimalizálja az elemzési lekérdezések teljesítményét. Ez a cikk részletesen ismerteti az elemzési tárterületet.
A működési adatok nagy léptékű elemzésével kapcsolatos kihívások
Az Azure Cosmos DB-tárolók többmodelles működési adatait belsőleg egy indexelt soralapú "tranzakciós tárolóban" tárolja a rendszer. A sortár formátum úgy lett kialakítva, hogy lehetővé tegye a gyors tranzakciós olvasást és írást az ezredmásodpercek sorrendjében a válaszidőkben és az operatív lekérdezésekben. Ha az adathalmaz nagy méretűre nő, az összetett elemzési lekérdezések költségesek lehetnek az ebben a formátumban tárolt adatok kiosztott átviteli sebessége szempontjából. A kiosztott átviteli sebesség magas kihasználtsága hatással van a valós idejű alkalmazások és szolgáltatások által használt tranzakciós számítási feladatok teljesítményére.
A nagy mennyiségű adat elemzéséhez a rendszer a működési adatokat az Azure Cosmos DB tranzakciós tárolójából nyeri ki, és egy külön adatrétegben tárolja. Az adatok tárolása például egy adattárházban vagy egy adattóban történik megfelelő formátumban. Ezeket az adatokat később nagy léptékű elemzésekhez használják, és olyan számítási motorokkal elemzik őket, mint az Apache Spark-fürtök. Az elemzés és a működési adatok elkülönítése késést eredményez azoknak az elemzőknek, amelyek a legfrissebb adatokat szeretnék használni.
Az ETL-folyamatok a működési adatok frissítéseinek kezelésekor is összetettek lesznek, ha csak az újonnan betöltött működési adatok kezelésére van szükség.
Oszloporientált elemzési tár
Az Azure Cosmos DB elemzési tár a hagyományos ETL-folyamatokkal kapcsolatos összetettségi és késési kihívásokat kezeli. Az Azure Cosmos DB elemzési tára automatikusan szinkronizálhatja a működési adatokat egy külön oszloptárolóba. Az oszloptároló formátum alkalmas nagy léptékű elemzési lekérdezések optimalizált végrehajtására, ami javítja az ilyen lekérdezések késését.
Az Azure Synapse Link használatával mostantól nem ETL HTAP-megoldásokat hozhat létre, ha közvetlenül kapcsolódik az Azure Cosmos DB elemzési tárához az Azure Synapse Analyticsből. Lehetővé teszi, hogy közel valós idejű, nagy léptékű elemzéseket futtasson a működési adatokon.
Az elemzési tár funkciói
Ha engedélyezi az elemzési tárat egy Azure Cosmos DB-tárolón, a rendszer belsőleg létrehoz egy új oszloptárolót a tároló működési adatai alapján. Ez az oszloptároló a tároló sororientált tranzakciós tárolójától elkülönítve, egy belső előfizetésben, az Azure Cosmos DB által teljes mértékben felügyelt tárfiókban marad. Az ügyfeleknek nem kell időt tölteniük a tárterület felügyeletével. A rendszer automatikusan szinkronizálja a műveleti adatok beszúrásait, frissítéseit és törlését az elemzési tárba. Az adatok szinkronizálásához nincs szükség a változáscsatornára vagy az ETL-ra.
Oszloptár a működési adatok elemzési számítási feladataihoz
Az elemzési számítási feladatok általában a kijelölt mezők összesítését és szekvenciális vizsgálatát foglalják magukban. Az adatelemzési tároló oszlop-fő sorrendben van tárolva, így az egyes mezők értékei adott esetben együtt szerializálhatók. Ez a formátum csökkenti az adott mezők statisztikáinak vizsgálatához vagy kiszámításához szükséges IOPS-t. Jelentősen javítja a nagy adatkészleteken végzett vizsgálatok lekérdezési válaszidejének alakulását.
Ha például az operatív táblák a következő formátumban vannak:
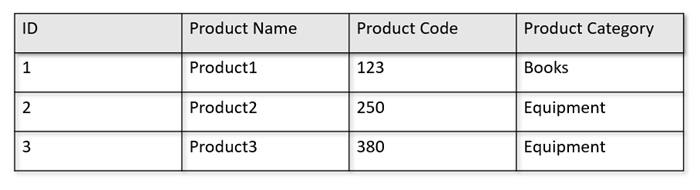
A sortároló soronként szerializált formátumban tárolja a fenti adatokat a lemezen. Ez a formátum gyorsabb tranzakciós olvasási, írási és működési lekérdezéseket tesz lehetővé, például "Az 1. termék adatainak visszaadása". Mivel azonban az adathalmaz nagy méretűre nő, és összetett elemzési lekérdezéseket szeretne futtatni az adatokon, az költséges lehet. Ha például a "Berendezések" kategória alá tartozó termék értékesítési trendjeit szeretné lekérni különböző üzleti egységekben és hónapokban, akkor összetett lekérdezést kell futtatnia. Az adathalmazon végzett nagy vizsgálatok költségessé tehetik a kiosztott átviteli sebességet, és hatással lehetnek a valós idejű alkalmazásokat és szolgáltatásokat áramoló tranzakciós számítási feladatok teljesítményére is.
Az elemzési tár, amely egy oszloptároló, jobban megfelel az ilyen lekérdezéseknek, mivel szerializálja a hasonló adatmezőket, és csökkenti a lemez IOPS-ját.
Az alábbi képen a tranzakciós sortároló és az elemzési oszloptároló látható az Azure Cosmos DB-ben:
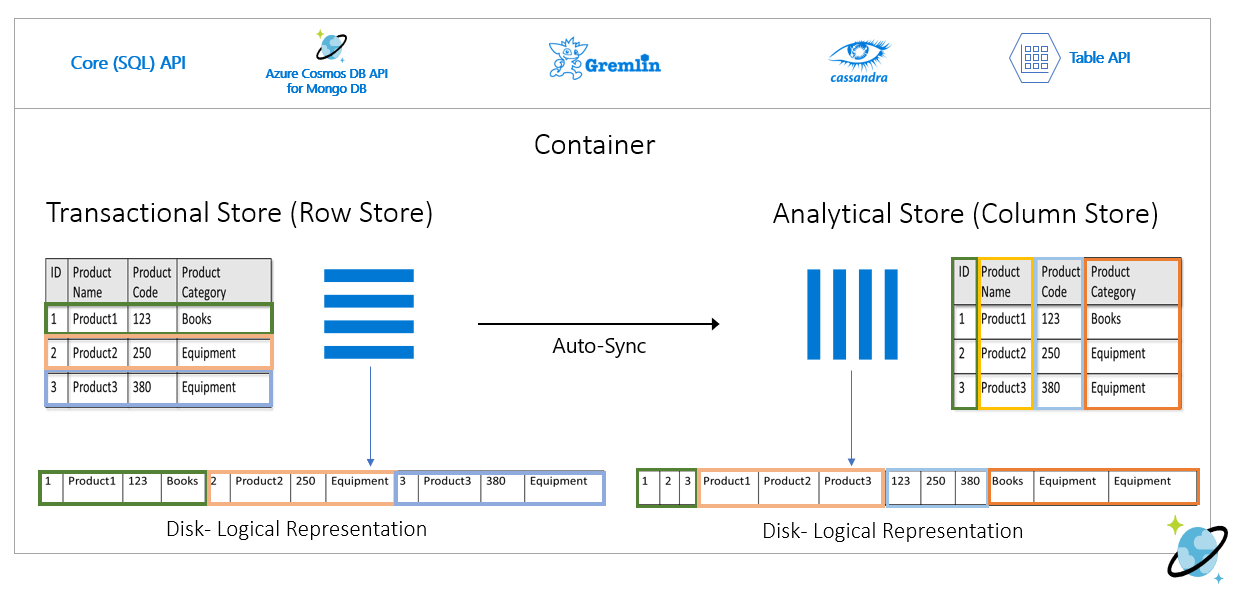
Az elemzési számítási feladatok leválasztott teljesítménye
Az elemzési lekérdezések miatt nincs hatással a tranzakciós számítási feladatok teljesítményére, mivel az elemzési tár külön van a tranzakciós tártól. Az elemzési tárhoz nincs szükség külön kérelemegységek (KÉRELEM) lefoglalására.
Automatikus szinkronizálás
Az automatikus szinkronizálás az Azure Cosmos DB teljes körűen felügyelt funkciójára utal, ahol a rendszer közel valós időben automatikusan szinkronizálja a beszúrásokat, frissítéseket és törléseket az operatív adatokra a tranzakciós tárból az elemzési tárba. Az automatikus szinkronizálás késése általában 2 percen belül van. Nagy számú tárolóval rendelkező megosztott átviteli sebességű adatbázisok esetén az egyes tárolók automatikus szinkronizálási késése magasabb lehet, és akár 5 percet is igénybe vehet.
Az automatikus szinkronizálási folyamat minden végrehajtásának végén a tranzakciós adatok azonnal elérhetők lesznek az Azure Synapse Analytics-futtatókörnyezetekhez:
Az Azure Synapse Analytics Spark-készletei az összes adatot, beleértve a legújabb frissítéseket is, automatikusan frissülő Spark-táblákon vagy a
spark.readparancson keresztül olvashatják be, amelyek mindig az adatok utolsó állapotát olvassák be.Az Azure Synapse Analytics SQL Kiszolgáló nélküli készletei az összes adatot, beleértve a legújabb frissítéseket is, automatikusan frissített nézeteken keresztül
SELECTvagy aOPENROWSETparancsokkal együtt olvashatják be, amelyek mindig az adatok legfrissebb állapotát olvassák.
Feljegyzés
A tranzakciós adatok akkor is szinkronizálódnak az elemzési tárba, ha a tranzakciós élettartam (TTL) kisebb, mint 2 perc.
Feljegyzés
Vegye figyelembe, hogy a tároló törlésekor az elemzési tár is törlődik.
Méretezhetőség és rugalmasság
Az Azure Cosmos DB tranzakciós tárolója horizontális particionálással rugalmasan skálázza a tárterületet és az átviteli sebességet állásidő nélkül. A tranzakciós tároló horizontális particionálása skálázhatóságot és rugalmasságot biztosít az automatikus szinkronizálásban, hogy az adatok közel valós időben szinkronizálva legyenek az elemzési tárzal. Az adatszinkronizálás a tranzakciós forgalom átviteli sebességétől függetlenül történik, függetlenül attól, hogy 1000 művelet/mp vagy 1 millió művelet/mp, és ez nem befolyásolja a tranzakciós tárolóban kiosztott átviteli sebességet.
Sémafrissítések automatikus kezelése
Az Azure Cosmos DB tranzakciós tároló sémafüggetlen, és lehetővé teszi a tranzakciós alkalmazások iterálását anélkül, hogy sémával vagy indexkezeléssel kellene foglalkoznia. Ezzel szemben az Azure Cosmos DB elemzési tárolója séma szerint van kialakítva, hogy optimalizálja az elemzési lekérdezések teljesítményét. Az automatikus szinkronizálási funkcióval az Azure Cosmos DB kezeli a sémakövető következtetést a tranzakciós tár legújabb frissítései alapján. Emellett kezeli a sémaképet az elemzési tárban, amely magában foglalja a beágyazott adattípusok kezelését is.
Ahogy a séma fejlődik, és az új tulajdonságok idővel hozzáadódnak, az elemzési tár automatikusan egy egyesített sémát jelenít meg a tranzakciós tár összes előzményséma között.
Feljegyzés
Az elemzési tár kontextusában a következő struktúrákat tekintjük tulajdonságnak:
- JSON "elements" vagy "string-value pairs separateed by
:". - JSON-objektumok, elválasztó
{}és . - JSON-tömbök, tagolt
[és].
Sémakorlátozások
Az Azure Cosmos DB működési adataira az alábbi korlátozások vonatkoznak, ha engedélyezi az elemzési tár számára a séma automatikus következtetését és helyes megjelenítését:
Legfeljebb 1000 tulajdonsággal rendelkezhet a dokumentumséma összes beágyazott szintjén, és legfeljebb 127 beágyazási mélységtel.
- Csak az első 1000 tulajdonság jelenik meg az elemzési tárban.
- Csak az első 127 beágyazott szint jelenik meg az elemzési tárban.
- A JSON-dokumentumok első szintje a gyökérszintje
/. - A dokumentum első szintjén lévő tulajdonságok oszlopként jelennek meg.
Példaforgatókönyvek:
- Ha a dokumentum első szintje 2000 tulajdonsággal rendelkezik, a szinkronizálási folyamat az első 1000-et jelöli.
- Ha a dokumentumok öt olyan szinttel rendelkeznek, amelyek mindegyike 200 tulajdonsággal rendelkezik, a szinkronizálási folyamat az összes tulajdonságot képviseli.
- Ha a dokumentumok 10 szinttel rendelkeznek, amelyek mindegyike 400 tulajdonsággal rendelkezik, a szinkronizálási folyamat teljes mértékben a két első szintet és a harmadik szintnek csak a felét fogja képviselni.
Az alábbi hipotetikus dokumentum négy tulajdonságot és három szintet tartalmaz.
- A szintek a ,
rootmyArrayés a beágyazott struktúra amyArray. - A tulajdonságok a következők
id: ,myArraymyArray.nested1ésmyArray.nested2. - Az elemzési tár ábrázolása két oszlopból
idésmyArray. A Spark- vagy T-SQL-függvényekkel a beágyazott struktúrákat oszlopként is elérhetővé teheti.
- A szintek a ,
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
Bár a JSON-dokumentumok (és az Azure Cosmos DB-gyűjtemények/-tárolók) megkülönböztetik a kis- és nagybetűket az egyediség szempontjából, az elemzési tár nem.
-
Ugyanabban a dokumentumban: Az azonos szintű tulajdonságok neveinek egyedinek kell lenniük a kis- és nagybetűk megkülönböztetése esetén. A következő JSON-dokumentum például azonos szinten tartalmazza a "Name" és a "name" (Név) értéket. Bár ez egy érvényes JSON-dokumentum, nem felel meg az egyediség korlátozásának, ezért nem jelenik meg teljes mértékben az elemzési tárban. Ebben a példában a "Név" és a "név" megegyezik a kis- és nagybetűk megkülönböztetése esetén. Csak
"Name": "fred"az elemzési tárban jelenik meg, mert ez az első előfordulás. És"name": "john"egyáltalán nem lesz képviselve.
{"id": 1, "Name": "fred", "name": "john"}-
Különböző dokumentumokban: Az azonos szintű és azonos nevű tulajdonságok, de különböző esetekben ugyanabban az oszlopban jelennek meg az első előfordulás névformátumával. A következő JSON-dokumentumok például azonos szintűek és
"Name"azonos szintűek"name". Mivel az első dokumentumformátum,"Name"a rendszer ezt fogja használni a tulajdonság nevének az elemzési tárban való megjelenítéséhez. Más szóval az elemzési tár oszlopneve a következő lesz"Name": . Mindkettőt"fred", és"john"az oszlopban is megjelenik"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}-
Ugyanabban a dokumentumban: Az azonos szintű tulajdonságok neveinek egyedinek kell lenniük a kis- és nagybetűk megkülönböztetése esetén. A következő JSON-dokumentum például azonos szinten tartalmazza a "Name" és a "name" (Név) értéket. Bár ez egy érvényes JSON-dokumentum, nem felel meg az egyediség korlátozásának, ezért nem jelenik meg teljes mértékben az elemzési tárban. Ebben a példában a "Név" és a "név" megegyezik a kis- és nagybetűk megkülönböztetése esetén. Csak
A gyűjtemény első dokumentuma határozza meg a kezdeti elemzési tár sémáját.
- A kezdeti sémánál több tulajdonságokkal rendelkező dokumentumok új oszlopokat hoznak létre az elemzési tárban.
- Az oszlopok nem távolíthatók el.
- A gyűjtemény összes dokumentumának törlése nem állítja vissza az elemzési tár sémáját.
- Nincs sémaverzió. A tranzakciós tárból kikövetkelő utolsó verzió az elemzési tárban látható.
Az Azure Synapse Spark jelenleg nem tud olyan tulajdonságokat olvasni, amelyek speciális karaktereket tartalmaznak a nevükben. A kiszolgáló nélküli Azure Synapse SQL nem érintett.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- „
Feljegyzés
A fehér szóközök a korlátozás elérésekor visszaadott Spark-hibaüzenetben is láthatók. De hozzáadtunk egy speciális kezelést a fehér terek számára, kérjük, tekintse meg a további részleteket az alábbi elemekben.
- Ha a fenti karaktereket használó tulajdonságok nevei vannak, az alternatív lehetőségek a következők:
- A karakterek elkerülése érdekében módosítsa előre az adatmodellt.
- Mivel jelenleg nem támogatjuk a séma alaphelyzetbe állítását, módosíthatja az alkalmazást úgy, hogy egy hasonló nevű redundáns tulajdonságot adjon hozzá, elkerülve ezeket a karaktereket.
- A Változáscsatorna használatával materializált nézetet hozhat létre a tárolóról anélkül, hogy ezek a karakterek szerepeljenek a tulajdonságok neveiben.
-
dropColumnA Spark beállítással figyelmen kívül hagyhatja az érintett oszlopokat, és betölthet minden más oszlopot egy DataFrame-be. A szintaxis a következő:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- Az Azure Synapse Spark mostantól támogatja a fehér szóközökkel rendelkező tulajdonságokat a nevükben. Ehhez a
allowWhiteSpaceInFieldNamesSpark beállítással kell betöltenie az érintett oszlopokat egy DataFrame-be, megtartva az eredeti nevet. A szintaxis a következő:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
A következő BSON-adattípusok nem támogatottak, és nem jelennek meg az elemzési tárban:
- Decimális128
- Reguláris kifejezés
- ADATBÁZIS-mutató
- JavaScript
- Szimbólum
- MinKey/MaxKey
Ha az ISO 8601 UTC szabványt követő DateTime-sztringeket használ, a következő viselkedésre számíthat:
- Az Azure Synapse Spark-készletei ezeket az oszlopokat jelölik.
string - Az Azure Synapse kiszolgáló nélküli SQL-készletei ezeket az oszlopokat képviselik .
varchar(8000)
- Az Azure Synapse Spark-készletei ezeket az oszlopokat jelölik.
A típusokat tartalmazó
UNIQUEIDENTIFIER (guid)tulajdonságok az elemzési tárban jelennek megstring, és a megfelelő vizualizáció érdekében SQL-benVARCHARvagy Sparkbankell átalakítanistring.Az Azure Synapse kiszolgáló nélküli SQL-készletei legfeljebb 1000 oszlopot tartalmazó eredménykészleteket támogatnak, és a beágyazott oszlopok felfedése is beleszámít a korlátba. Érdemes megfontolni ezeket az információkat a tranzakciós adatarchitektúrában és a modellezésben.
Ha átnevez egy tulajdonságot egy vagy több dokumentumban, az új oszlopnak minősül. Ha ugyanazt az átnevezést hajtja végre a gyűjtemény összes dokumentumában, az összes adat át lesz migrálva az új oszlopba, a régi oszlop pedig értékekkel
NULLjelenik meg.
Sémaábrázolás
Az elemzési tárban két sémaábrázolási módszer létezik, amelyek az adatbázisfiók összes tárolójára érvényesek. Kompromisszumok vannak a lekérdezési élmény egyszerűsége és a többalakú sémák befogadóbb oszlopos ábrázolásának kényelme között.
- Jól definiált sémaábrázolás, az API alapértelmezett beállítása a NoSQL- és Gremlin-fiókokhoz.
- Teljes hűségséma-ábrázolás, alapértelmezett beállítás az API-hoz MongoDB-fiókokhoz.
Jól definiált sémaábrázolás
A jól definiált sémaábrázolás egyszerű táblázatos ábrázolásokat hoz létre a tranzakciós tárolóban található séma-agnosztikus adatokról. A jól definiált sémaábrázolás a következő szempontokat veszi figyelembe:
- Az első dokumentum határozza meg az alapsémát, és a tulajdonságoknak mindig azonos típusúnak kell lenniük az összes dokumentumban. Az egyetlen kivétel a következő:
- Az Azure Synapse szerver nélküli SQL-készletei esetében:
NULLadattípusról bármely más adattípusra. Az első nem null előfordulás határozza meg az oszlop adattípusát. Az elemzési tárban nem jelenik meg minden olyan dokumentum, amely nem követi az első nem null adattípust. - Spark-készletek és Az Azure Data Factory adatrögzítésének módosítása az Azure Synapse-ban: From
NULLtoINT. Az Azure Synapse-ben, a Spark-készletek és az Azure Data Factory változás-adatrögzítés nem támogatja a null tulajdonságoktól való fejlődést az INT-től eltérő adattípusokra. Az első nem null értéknek egész számnak kell lennie, és a más adattípusú dokumentumok nem lesznek ábrázolva az elemzési tárban. -
float-tólinteger-ig. Minden dokumentum az elemzési tárban jelenik meg. -
integer-tólfloat-ig. Minden dokumentum az elemzési tárban jelenik meg. Ha azonban az adatokat kiszolgáló nélküli Azure Synapse SQL-készletekkel szeretné beolvasni, az oszlopvarcharkonvertálásához with záradékot kell használnia. A kezdeti átalakítás után újra átalakítható számmá. Ellenőrizze az alábbi példát, ahol a szám kezdeti értéke egész szám volt, a második pedig lebegőpontos.
- Az Azure Synapse szerver nélküli SQL-készletei esetében:
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
Az alapséma adattípusát nem követő tulajdonságok nem jelennek meg az elemzési tárban. Vegyük például az alábbi dokumentumokat: az első definiálta az elemzési tár alapsémát. A második dokumentum, ahol
idvan"2", nem rendelkezik jól definiált sémával, mivel a tulajdonság"code"egy sztring, és az első dokumentum számként van"code"megadva. Ebben az esetben az elemzési tár a tároló élettartamának adattípusát"code"integerregisztrálja. A második dokumentum továbbra is szerepel az elemzési tárban, de tulajdonsága"code"nem.{"id": "1", "code":123}{"id": "2", "code": "123"}
Feljegyzés
A fenti feltétel nem vonatkozik a tulajdonságokra NULL . Például {"a":123} and {"a":NULL} még mindig jól definiált.
Feljegyzés
A fenti feltétel nem változik, ha a dokumentumot "code" sztringre frissíti "1" a tranzakciós tárban. Az elemzési tárban a rendszer megmarad, "code" mivel integer jelenleg nem támogatjuk a séma alaphelyzetbe állítását.
- A tömbtípusoknak egyetlen ismétlődő típust kell tartalmazniuk. Például nem egy jól definiált séma,
{"a": ["str",12]}mert a tömb egész számokat és sztringtípusokat tartalmaz.
Feljegyzés
Ha az Azure Cosmos DB elemzési tár a jól definiált sémamegjelenést követi, és a fenti specifikációt bizonyos elemek megsértik, ezek az elemek nem lesznek belefoglalva az elemzési tárba.
Eltérő viselkedés várható a jól definiált sémák különböző típusai tekintetében:
- Az Azure Synapse Spark-készletei ezeket az értékeket képviselik.
undefined - Az Azure Synapse kiszolgáló nélküli SQL-készletei ezeket az értékeket képviselik.
NULL
- Az Azure Synapse Spark-készletei ezeket az értékeket képviselik.
Eltérő viselkedés várható az explicit
NULLértékek tekintetében:- Az Azure Synapse Spark-készletei ezeket az értékeket (nulla) olvassák
0be, ésundefinedamint az oszlop nem null értékű. - Az Azure Synapse kiszolgáló nélküli SQL-készletei ezeket az értékeket a következőképpen
NULLolvassák fel: .
- Az Azure Synapse Spark-készletei ezeket az értékeket (nulla) olvassák
Eltérő viselkedés várható a hiányzó oszlopok tekintetében:
- Az Azure Synapse Spark-készletei ezeket az oszlopokat jelölik.
undefined - Az Azure Synapse kiszolgáló nélküli SQL-készletei ezeket az oszlopokat képviselik .
NULL
- Az Azure Synapse Spark-készletei ezeket az oszlopokat jelölik.
A reprezentációs kihívások kerülő megoldásai
Lehetséges, hogy egy helytelen sémával rendelkező régi dokumentumot használt a tároló elemzési tár alapséma létrehozásához. A fent bemutatott szabályok alapján előfordulhat, hogy bizonyos tulajdonságokat kap NULL az elemzési tár Azure Synapse Link használatával történő lekérdezésekor. A problémás dokumentumok törlése vagy frissítése nem segít, mert az alapséma alaphelyzetbe állítása jelenleg nem támogatott. A lehetséges megoldások a következők:
- Ha új tárolóba szeretné migrálni az adatokat, győződjön meg arról, hogy minden dokumentum rendelkezik a megfelelő sémával.
- Ha nem a megfelelő sémával szeretné megszüntetni a tulajdonságot, és újat szeretne hozzáadni egy másik névvel, amely minden dokumentumban a megfelelő sémával rendelkezik. Példa: Több milliárd dokumentum található az Orders tárolóban, ahol az állapottulajdonság egy sztring. A tároló első dokumentuma azonban egész számmal van definiálva. Így egy dokumentum állapota helyesen jelenik meg, és az összes többi dokumentumnak megfelelően jelenik meg
NULL. Az állapot2 tulajdonságot hozzáadhatja az összes dokumentumhoz, és elkezdheti használni az eredeti tulajdonság helyett.
Teljes hűségséma-ábrázolás
A teljes hűségséma-ábrázolás úgy lett kialakítva, hogy a séma-agnosztikus működési adatok polimorf sémáinak teljes szélességét kezelje. Ebben a sémaábrázolásban a rendszer nem távolít el elemeket az elemzési tárból, még akkor sem, ha a jól definiált sémakorlátok (vagyis nem vegyes adattípusú mezők vagy vegyes adattípusú tömbök) sérülnek.
Ez úgy érhető el, hogy az operatív adatok levéltulajdonságait JSON-párokként key-value fordítja az elemzési tárolóba, ahol az adattípus az key , a tulajdonság tartalma pedig a value. Ez a JSON-objektumábrázolás kétértelmű lekérdezéseket tesz lehetővé, és egyenként elemezheti az egyes adattípusokat.
Más szóval a teljes hűségséma-ábrázolásban az egyes dokumentumok minden tulajdonságának minden adattípusa létrehoz egy párot key-valueaz adott tulajdonsághoz tartozó JSON-objektumban. Mindegyik az 1000 maximális tulajdonságkorlát egyikének számít.
Vegyük például a következő mintadokumentumot a tranzakciós tárolóban:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
A beágyazott objektum address egy tulajdonság a dokumentum gyökérszintén, és oszlopként jelenik meg. Az objektum minden levéltulajdonságát address JSON-objektumként jeleníti meg: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
A jól definiált sémaábrázolástól eltérően a teljes hűségmetódus lehetővé teszi az adattípusok variációját. Ha a fenti példa gyűjteményének következő dokumentuma sztringként jelenik streetNo meg, akkor az elemzési tárban "streetNo":{"string":15850}a következőképpen jelenik meg. A jól definiált sémametódusban ez nem jelenik meg.
Adattípusok leképezése teljes hűségséma esetén
Íme egy térkép a MongoDB adattípusairól és azok ábrázolásáról az elemzési tárban teljes hűségséma-ábrázolásban. Az alábbi térkép nem érvényes a NoSQL API-fiókokra.
| Eredeti adattípus | Toldalék | Példa |
|---|---|---|
| Kétszeres | ".float64" | 24,99 |
| Tömb | .array | ["a", "b"] |
| Bináris | ".binary" | 0 |
| Logikai | ".bool" | Igaz |
| Int32 | ".int32" | 123 |
| Int64 | ".int64" | 255486129307 |
| NULLA | ". NULL" | NULLA |
| Sztring | ".string" | "ABC" |
| Időbélyegző | ".időbélyeg" | Időbélyeg(0; 0) |
| ObjectId (objektumazonosító) | ".objectId" | ObjectId("5f3f7b59330ec25c132623a2") |
| Bizonylat | ".object" | {"a": "a"} |
Eltérő viselkedés várható az explicit
NULLértékek tekintetében:- Az Azure Synapse Spark-készletei ezeket az értékeket (nulla) értékként
0olvassák fel. - Az Azure Synapse kiszolgáló nélküli SQL-készletei ezeket az értékeket a következőképpen
NULLfogják olvasni: .
- Az Azure Synapse Spark-készletei ezeket az értékeket (nulla) értékként
Eltérő viselkedés várható a hiányzó oszlopok tekintetében:
- Az Azure Synapse Spark-készletei ezeket az oszlopokat jelölik.
undefined - Az Azure Synapse kiszolgáló nélküli SQL-készletei ezeket az oszlopokat képviselik .
NULL
- Az Azure Synapse Spark-készletei ezeket az oszlopokat jelölik.
Eltérő viselkedés várható az értékek tekintetében
timestamp:- Az Azure Synapse Spark-készletei ezeket az értékeket
TimestampTypeaz ,DateTypevagyFloat. Ez a tartománytól és az időbélyeg létrehozásának módjától függ. - Az Azure Synapse kiszolgáló nélküli SQL-készletei ezeket az értékeket
DATETIME2a következőképpen olvassák fel: .0001-01-019999-12-31Az ezen tartományon túli értékek nem támogatottak, és végrehajtási hibát okoznak a lekérdezésekben. Ha ez a helyzet, a következőt teheti:- Távolítsa el az oszlopot a lekérdezésből. A reprezentáció megtartásához létrehozhat egy új tulajdonságtükrözést, amely tükrözi az oszlopot, de a támogatott tartományon belül. És használja a lekérdezésekben.
- Az adatrögzítés módosítása az elemzési tárból, kérelemegység-költség nélkül, az adatok új formátumba való átalakításához és betöltéséhez a támogatott fogadók egyikén belül.
- Az Azure Synapse Spark-készletei ezeket az értékeket
Teljes hűségséma használata a Sparkkal
A Spark minden adattípust oszlopként kezel, amikor betölt egy DataFrame. Tegyük fel, hogy az alábbi dokumentumokat tartalmazó gyűjteményt.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
Míg az első dokumentum számként és rating UTC formátumban van timestamp megadva, a második dokumentum sztringként és rating sztringként is szerepeltimestamp. Feltételezve, hogy ez a gyűjtemény adatátalakítás nélkül lett betöltve DataFrame , a df.printSchema() következő kimenete lesz:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
A jól definiált sémaábrázolásban sem a második, sem ratingtimestamp a második dokumentum nem jelenik meg. A teljes megbízhatósági sémában az alábbi példák segítségével egyenként férhet hozzá az egyes adattípusok minden értékéhez.
Az alábbi példában egy összesítést futtathatunk PySpark :
df.groupBy(df.item.string).sum().show()
Az alábbi példában egy másik összesítést is futtathatunk PySQL :
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
Teljes hűségséma használata az SQL-vel
A következő szintaxisos példát használhatja a fenti Spark-példa dokumentumaival:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
Átalakításokat hajthat végre az adatok manipulálásához a cast T-SQL-függvények vagy más T-SQL-függvények használatávalconvert. Az összetett adattípus-struktúrákat nézetek használatával is elrejtheti.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
A MongoDB _id mező használata
A MongoDB _id mező alapvető fontosságú a MongoDB összes gyűjteményében, és eredetileg hexadecimális ábrázolású. Ahogy a fenti táblázatban látható, a teljes hűségséma megőrzi a jellemzőit, ami kihívást jelent a vizualizációhoz az Azure Synapse Analyticsben. A helyes vizualizációhoz az alábbi módon kell átalakítania az _id adattípust:
A MongoDB _id mező használata a Sparkban
Az alábbi példa a Spark 2.x és a 3.x verziókon működik:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
MongoDB-mező _id használata az SQL-ben
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
A MongoDB id mező használata
A id MongoDB-tárolókban lévő tulajdonságot a rendszer automatikusan felülbírálta a "_id" tulajdonság Base64-ábrázolásával mind az elemzési tárban. Az "id" mező a MongoDB-alkalmazások belső használatára szolgál. Jelenleg az egyetlen áthidaló megoldás, ha az "id" tulajdonságot nem az "id" névre átnevezi.
Teljes hűségséma a NoSQL- vagy Gremlin-fiókok API-hoz
A NoSQL-fiókokhoz készült API teljes hűségséma az alapértelmezett beállítás helyett a sématípus beállításával használható, amikor először engedélyezi a Synapse Linket egy Azure Cosmos DB-fiókon. Az alapértelmezett sémaábrázolás típusának módosításával kapcsolatos szempontok:
- Jelenleg, ha engedélyezi a Synapse Linket a NoSQL API-fiókjában az Azure Portal használatával, az engedélyezve lesz, valamint egy jól definiált séma is.
- Ha jelenleg teljes hűségsémát szeretne használni NoSQL- vagy Gremlin API-fiókokkal, akkor azt fiókszinten kell beállítania ugyanabban a PARANCSSOR- vagy PowerShell-parancsban, amely fiókszinten engedélyezi a Synapse Linket.
- A MongoDB-hez készült Azure Cosmos DB jelenleg nem kompatibilis a sémaábrázolás módosításának lehetőségével. Minden MongoDB-fiók teljes hűségséma-ábrázolási típussal rendelkezik.
- A fent említett teljes Fidelity-séma adattípus-leképezés nem érvényes a JSON-adattípusokat használó NoSQL API-fiókokra. Példaként az
floatintegerértékek az elemzési tárban jelenneknummeg. - Nem lehet alaphelyzetbe állítani a sémaábrázolás típusát a jól definiálttól a teljes hűségig, vagy fordítva.
- Az elemzési tár tárolósémái jelenleg a tároló létrehozásakor vannak definiálva, még akkor is, ha a Synapse Link nincs engedélyezve az adatbázisfiókban.
- A Synapse Link engedélyezése előtt létrehozott tárolók és grafikonok fiókszinten teljes hűségsémával rendelkeznek, és jól definiált sémával rendelkeznek.
- A Synapse Link engedélyezése után létrehozott tárolók és grafikonok fiókszinten teljes hűségsémával rendelkeznek.
A sémaábrázolás típusáról úgy kell dönteni, hogy a Synapse Link engedélyezve van a fiókon az Azure CLI vagy a PowerShell használatával.
Az Azure CLI-vel:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
Feljegyzés
A fenti parancsban cserélje le createupdate a meglévő fiókokra.
A PowerShell használatával:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
Feljegyzés
A fenti parancsban cserélje le New-AzCosmosDBAccountUpdate-AzCosmosDBAccount a meglévő fiókokra.
Elemzési élettartam (TTL)
Az elemzési TTL (ATTL) azt jelzi, hogy mennyi ideig kell megőrizni az adatokat az elemzési tárolóban egy tárolóhoz.
Az elemzési tár akkor engedélyezve van, ha az ATTL értéke nem és NULLnem 0 . Ha engedélyezve van, a rendszer automatikusan szinkronizálja a beszúrásokat, frissítéseket és törléseket a tranzakciós tárolóból az elemzési tárolóba, függetlenül a tranzakciós TTL (TTTL) konfigurációjától. Az elemzési tárban lévő tranzakciós adatok megőrzését a AnalyticalStoreTimeToLiveInSeconds tulajdonság tárolószinten szabályozhatja.
A lehetséges ATTL-konfigurációk a következők:
Ha az érték a következőre
0van állítva: az elemzési tár le van tiltva, és a rendszer nem replikál adatokat a tranzakciós tárolóból az elemzési tárolóba. Nyisson meg egy támogatási esetet az elemzési tár letiltásához a tárolókban.Ha a mező nincs megadva, semmi sem történik, és az előző érték megmarad.
Ha az érték a következőre
-1van állítva: az elemzési tár megőrzi az összes előzményadatot, függetlenül a tranzakciós tárolóban lévő adatok megőrzésétől. Ez a beállítás azt jelzi, hogy az elemzési tár végtelenül megőrzi a működési adatokatHa az érték pozitív egész
nszámra van állítva: az elemek a tranzakciós tároló utolsó módosítási ideje után másodperccel lejárnak az elemzési tárbóln. Ez a beállítás akkor használható, ha a működési adatokat korlátozott ideig szeretné megőrizni az elemzési tárban, függetlenül attól, hogy a tranzakciós tárolóban lévő adatok megtarthatók-e
Néhány megfontolandó szempont:
- Miután az elemzési tár ATTL-értékkel van engedélyezve, később frissíthető egy másik érvényes értékre.
- Bár a TTTL a tároló vagy az elem szintjén állítható be, az ATTL jelenleg csak a tároló szintjén állítható be.
- A működési adatok hosszabb megőrzést érhetnek el az elemzési tárolóban az ATTL >= TTTL tárolószinten történő beállításával.
- Az elemzési tár az ATTL = TTTL beállításával tükrözhető a tranzakciós tárolóban.
- Ha az ATTL nagyobb, mint a TTTL, egy adott időpontban olyan adatokkal fog rendelkezni, amelyek csak az elemzési tárban léteznek. Ezek az adatok csak olvashatók.
- Jelenleg nem törölünk adatokat az elemzési tárból. Ha az ATTL-t bármilyen pozitív egész számra állítja be, az adatok nem lesznek belefoglalva a lekérdezésekbe, és nem fognak fizetni érte. Ha azonban az ATTL-t visszaváltja
-1, az összes adat ismét megjelenik, a rendszer elkezdi kiszámlázni az összes adatkötetet.
Elemzési tároló engedélyezése tárolón:
Az Azure Portalon az ATTL beállítás bekapcsolva a -1 alapértelmezett értékre van állítva. Ezt az értéket "n" másodpercre módosíthatja, ha az Adatkezelőben a tárolóbeállításokra navigál.
Az Azure Management SDK-ban, az Azure Cosmos DB SDK-ban, a PowerShellben vagy az Azure CLI-ben az ATTL-beállítás -1 vagy "n" másodpercre állításával engedélyezhető.
További információkért tekintse meg , hogyan konfigurálhat elemzési TTL-t egy tárolón.
Költséghatékony elemzés az előzményadatokon
Az adatrétegezés az adatok elkülönítését jelenti a különböző forgatókönyvekhez optimalizált tárolási infrastruktúrák között. Ezáltal javul a teljes körű adatverem általános teljesítménye és költséghatékonysága. Az elemzési tár használatával az Azure Cosmos DB mostantól támogatja az adatok automatikus rétegezését a tranzakciós tárolóból az elemzési tárba különböző adatelrendezésekkel. A tranzakciós tárhoz képest a tárolási költség szempontjából optimalizált elemzési tár lehetővé teszi a működési adatok sokkal hosszabb horizontjának megőrzését az előzményelemzéshez.
Az elemzési tár engedélyezése után a tranzakciós számítási feladatok adatmegőrzési igényei alapján úgy konfigurálhatja transactional TTL a tulajdonságot, hogy bizonyos idő elteltével a rekordok automatikusan törlődjenek a tranzakciós tárolóból. Hasonlóképpen lehetővé analytical TTL teszi az elemzési tárban tárolt adatok életciklusának kezelését, függetlenül a tranzakciós tárolótól. Az elemzési tár engedélyezésével, valamint a tranzakciós és elemzési TTL tulajdonságok konfigurálásával zökkenőmentesen rétegzheti és definiálhatja a két tároló adatmegőrzési idejét.
Feljegyzés
Ha analytical TTL értéknél transactional TTL nagyobb értékre van állítva, a tároló olyan adatokkal fog rendelkezni, amelyek csak az elemzési tárban léteznek. Ezek az adatok csak olvashatók, és jelenleg nem támogatjuk a dokumentumszintet TTL az elemzési tárban. Ha a tároló adatainak frissítésre vagy törlésre lehet szüksége a jövőben egy adott időpontban, ne használjon analytical TTL nagyobbat, mint transactional TTL. Ez a funkció olyan adatok esetében ajánlott, amelyekhez a jövőben nem lesz szükség frissítésekre vagy törlésekre.
Feljegyzés
Ha a forgatókönyv nem igényel fizikai törlést, alkalmazhat logikai törlési/frissítési megközelítést. Szúrja be a tranzakciós tárolóba ugyanannak a dokumentumnak egy másik verzióját, amely csak az elemzési tárban létezik, de logikai törlésre/frissítésre van szükség. Lehet, hogy egy jelölő jelzi, hogy ez egy törlés vagy egy lejárt dokumentum frissítése. Ugyanannak a dokumentumnak mindkét verziója együtt fog létezni az elemzési tárban, és az alkalmazásnak csak az utolsót kell figyelembe vennie.
Rugalmasság
Az elemzési tár az Azure Storage-ra támaszkodik, és a következő védelmet nyújtja a fizikai hibák ellen:
- Alapértelmezés szerint az Azure Cosmos DB-adatbázisfiókok az elemzési tárat helyileg redundáns tárfiókokban (LRS) foglalják le. Az LRS legalább 99,9999999999999%-os (11 kilences) tartósságot biztosít az objektumoknak egy adott évben.
- Ha az adatbázisfiók bármely georégiója zónaredundánsra van konfigurálva, a rendszer zónaredundáns tárfiókokban (ZRS) foglalja le. Engedélyeznie kell a rendelkezésre állási zónákat az Azure Cosmos DB-adatbázisfiókjuk egy régiójában, hogy a régió elemzési adatai zónaredundáns tárolóban legyenek tárolva. A ZRS legalább 99,9999999999999999%-os (12 9-es) tárolási erőforrások tartósságát biztosítja egy adott évben.
Az Azure Storage tartósságáról ezen a hivatkozáson talál további információt.
Biztonsági másolat
Bár az elemzési tár beépített védelmet nyújt a fizikai hibák ellen, biztonsági mentésre lehet szükség a tranzakciós tárolóban történt véletlen törlésekhez vagy frissítésekhez. Ezekben az esetekben visszaállíthat egy tárolót, és a visszaállított tárolóval feltöltheti az adatokat az eredeti tárolóban, vagy szükség esetén teljesen újraépítheti az elemzési tárolót.
Feljegyzés
Az elemzési tár jelenleg nem készít biztonsági másolatot, ezért nem állítható vissza. A biztonsági mentési szabályzatot nem lehet erre alapozni.
A Synapse Link és az elemzési tár ennek következtében különböző kompatibilitási szinteket biztosít az Azure Cosmos DB biztonsági mentési módokkal:
- A rendszeres biztonsági mentési mód teljes mértékben kompatibilis a Synapse Linkkel, és ez a két funkció ugyanabban az adatbázisfiókban használható.
- A folyamatos biztonsági mentési módot használó adatbázisfiókokhoz készült Synapse Link ga.
- A Synapse Link-kompatibilis fiókok folyamatos biztonsági mentési módja nyilvános előzetes verzióban érhető el. Jelenleg nem migrálhat folyamatos biztonsági mentésre, ha letiltotta a Synapse Linket a Cosmos DB-fiókban lévő gyűjtemények egyikén.
Biztonsági mentési szabályzatok
Két lehetséges biztonsági mentési szabályzat létezik, és a használatuk megértéséhez nagyon fontosak az Azure Cosmos DB biztonsági mentéseinek alábbi részletei:
- Az eredeti tároló mindkét biztonsági mentési módban elemzési tár nélkül lesz visszaállítva.
- Az Azure Cosmos DB nem támogatja, hogy a tárolók felülírják a visszaállítást.
Most lássuk, hogyan használható a biztonsági mentés és a visszaállítás az elemzési tár szempontjából.
Tároló visszaállítása TTTL >= ATTL használatával
Ha transactional TTL egyenlő vagy nagyobb, mint analytical TTL, az elemzési tár összes adata továbbra is létezik a tranzakciós tárolóban. Visszaállítás esetén két lehetséges helyzet áll fenn:
- A visszaállított tároló használata az eredeti tároló cseréjeként. Az elemzési tár újraépítéséhez csak engedélyezze a Synapse Linket fiókszinten és tárolószinten.
- Ha a visszaállított tárolót adatforrásként szeretné használni az eredeti tároló adatainak feltöltéséhez vagy frissítéséhez. Ebben az esetben az elemzési tár automatikusan tükrözi az adatműveleteket.
Tároló visszaállítása TTTL < ATTL használatával
Ha transactional TTL kisebb, mint analytical TTL, bizonyos adatok csak az elemzési tárban léteznek, és nem lesznek a visszaállított tárolóban. Ismét két lehetséges helyzet áll rendelkezésére:
- A visszaállított tároló használata az eredeti tároló cseréjeként. Ebben az esetben, ha tárolószinten engedélyezi a Synapse Linket, csak a tranzakciós tárolóban lévő adatok lesznek belefoglalva az új elemzési tárba. Vegye figyelembe azonban, hogy az eredeti tároló elemzési tárolója mindaddig elérhető marad a lekérdezésekhez, amíg az eredeti tároló létezik. Előfordulhat, hogy módosítani szeretné az alkalmazást, hogy mindkettőt lekérdezhesse.
- Ha a visszaállított tárolót adatforrásként szeretné használni az eredeti tároló adatainak feltöltéséhez vagy frissítéséhez:
- Az elemzési tár automatikusan tükrözi a tranzakciós tárolóban lévő adatok adatműveletét.
- Ha olyan adatokat szúr be újra, amelyeket korábban eltávolítottak a tranzakciós tárból
transactional TTL, az adatok duplikálva lesznek az elemzési tárban.
Példa:
- A tároló
OnlineOrdersTTTL-értéke egy hónap, az ATTL pedig egy évre van beállítva. - Amikor visszaállítja a tárolót
OnlineOrdersNew, és bekapcsolja az elemzési tárat az újraépítéshez, csak egy hónapnyi adat lesz mind a tranzakciós, mind az elemzési tárban. - Az eredeti tároló
OnlineOrdersnem törlődik, és az elemzési tárolója továbbra is elérhető. - Az új adatok csak a betöltésbe kerülnek
OnlineOrdersNew. - Az elemzési lekérdezések egy UNION ALL-t végeznek az elemzési tárolókból, míg az eredeti adatok továbbra is relevánsak.
Ha törölni szeretné az eredeti tárolót, de nem szeretné elveszíteni az elemzési tár adatait, az eredeti tároló elemzési tárát egy másik Azure-beli adatszolgáltatásban is megőrizheti. A Synapse Analytics képes összekapcsolást végezni a különböző helyeken tárolt adatok között. Példa: Egy Synapse Analytics-lekérdezés összekapcsolja az elemzési tár adatait az Azure Blob Storage-ban, az Azure Data Lake Store-ban stb. található külső táblákkal.
Fontos megjegyezni, hogy az elemzési tár adatai más sémával rendelkeznek, mint a tranzakciós tárolóban. Bár létrehozhat pillanatképeket az elemzési tár adatairól, és bármely Azure Data service-be exportálhatja azokat, kérelemegység-költségek nélkül nem garantálhatjuk, hogy a pillanatkép használatával visszatápláljuk a tranzakciós tárolót. Ez a folyamat nem támogatott.
Globális terjesztés
Ha globálisan elosztott Azure Cosmos DB-fiókkal rendelkezik, miután engedélyezte az elemzési tárat egy tárolóhoz, az a fiók minden régiójában elérhető lesz. A működési adatok minden módosítása globálisan replikálódik minden régióban. Az elemzési lekérdezéseket hatékonyan futtathatja az adatok legközelebbi regionális példányán az Azure Cosmos DB-ben.
Particionálás
Az elemzési tár particionálása teljesen független a tranzakciós tároló particionálásától. Alapértelmezés szerint az elemzési tár adatai nincsenek particionált állapotban. Ha az elemzési lekérdezések gyakran használnak szűrőket, lehetősége van ezen mezők alapján particionálásra a jobb lekérdezési teljesítmény érdekében. További információ: az egyéni particionálás bemutatása és az egyéni particionálás konfigurálása.
Biztonság
Hitelesítés az elemzési tárral – A támogatott hitelesítési módszerek attól függően változnak, hogy engedélyezve vannak-e a hálózati funkciók.
Kulcsalapú hitelesítés: Ez a forgatókönyv minden esetben támogatott minden fiók esetében, beleértve a privát végpontokat vagy a virtuális hálózatot nem engedélyező fiókokat is.
Szolgáltatásnév vagy felügyelt identitás: Az Entra-azonosító vagy a felügyelt identitás hitelesítése csak olyan fiókok esetében támogatott, amelyek nem használnak privát végpontokat, vagy nem engedélyezik a virtuális hálózatok elérését. Az ilyen típusú hitelesítés használatához a felhasználóknak RBAC-adatsíkot kell alkalmazniuk, és új írásvédett szerepkört kell létrehozniuk az alábbi adatműveletekkel.
- Adjon hozzá egy egyéni MyAnalyticsReadOnlyRole-t a PowerShell használatával, és képezje le a "readMetadata" és a "readAnalytics" RBAC-műveleteket a szerepkörre.
$resourceGroupName = "<myResourceGroup>" $accountName = "<myCosmosAccount>" New-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -Type CustomRole -RoleName 'MyAnalyticsReadOnlyRole' ` -DataAction @( ` 'Microsoft.DocumentDB/databaseAccounts/readMetadata', 'Microsoft.DocumentDB/databaseAccounts/readAnalytics' ) ` -AssignableScope "/"- Listázhatja a fiók szerepkördefinícióit az új szerepkördefiníció-azonosító lekéréséhez.
$roleDefinitionId = Get-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName- Hozza létre a szerepkör-hozzárendelést úgy, hogy az új szerepkört a Synapse MSI-tagnak adja.
$synapsePrincipalId = "<Synapse MSI Principal>" New-AzCosmosDBSqlRoleAssignment -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -RoleDefinitionId $readOnlyRoleDefinitionId ` -Scope "/" ` -PrincipalId $synapsePrincipalId
Hálózatelkülönítés privát végpontokkal – A tranzakciós és elemzési tárolókban lévő adatokhoz való hálózati hozzáférést egymástól függetlenül szabályozhatja. A hálózatelkülönítés az egyes tárolókhoz külön felügyelt privát végpontok használatával történik az Azure Synapse-munkaterületek felügyelt virtuális hálózataiban. További információkért tekintse meg, hogyan konfigurálhatja a privát végpontokat az elemzési tár cikkéhez. Megjegyzés: ennek engedélyezésekor kulcsalapú hitelesítést kell használnia. Lásd az előző szakaszt.
Inaktív adattitkosítás – Az elemzési tár titkosítása alapértelmezés szerint engedélyezve van.
Adattitkosítás ügyfél által kezelt kulcsokkal – Az adatokat zökkenőmentesen titkosíthatja tranzakciós és elemzési tárolókban ugyanazokkal az ügyfél által felügyelt kulcsokkal automatikusan és átlátható módon. Az Azure Synapse Link csak az Azure Cosmos DB-fiók felügyelt identitásával támogatja az ügyfél által felügyelt kulcsok konfigurálását. Az Azure Synapse Link fiókon való engedélyezése előtt konfigurálnia kell a fiók felügyelt identitását az Azure Key Vault hozzáférési szabályzatában. További információkért tekintse meg, hogyan konfigurálhat ügyfél által felügyelt kulcsokat az Azure Cosmos DB-fiókok felügyelt identitásainak használatával.
Feljegyzés
Ha az adatbázisfiókot rendszer- vagy felhasználó által hozzárendelt azonosítóra módosítja, és engedélyezi az Azure Synapse Linket az adatbázisfiókban, nem fog tudni visszatérni a First Party identitáshoz, mivel nem tudja letiltani a Synapse Linket az adatbázisfiókból.
Több Azure Synapse Analytics-futtatókörnyezet támogatása
Az elemzési tár úgy van optimalizálva, hogy skálázhatóságot, rugalmasságot és teljesítményt biztosítson az elemzési számítási feladatokhoz anélkül, hogy a számítási futásidők függenek. A tárolási technológia önkiszolgálóan optimalizálja az elemzési számítási feladatokat manuális erőfeszítések nélkül.
Az Azure Cosmos DB elemzési tárában lévő adatok egyszerre kérdezhetők le az Azure Synapse Analytics által támogatott különböző elemzési futtatókörnyezetekből. Az Azure Synapse Analytics támogatja az Apache Sparkot és a kiszolgáló nélküli SQL-készletet az Azure Cosmos DB elemzési tárával.
Feljegyzés
Az elemzési tárból csak azure Synapse Analytics-futtatókörnyezetek használatával olvashat. És az ellenkezője is igaz, az Azure Synapse Analytics-futtatókörnyezetek csak az elemzési tárból tudnak olvasni. Csak az automatikus szinkronizálási folyamat módosíthatja az adatokat az elemzési tárban. Az Azure Cosmos DB tranzakciós tárolóba az Azure Synapse Analytics Spark-készlet használatával, a beépített Azure Cosmos DB OLTP SDK használatával írhat vissza adatokat.
Díjszabás
Az elemzési tár egy fogyasztásalapú díjszabási modellt követ, amelyért díjat kell fizetnie:
Tárolás: az elemzési tárban tárolt adatok mennyisége havonta, beleértve az elemzési TTL által meghatározott előzményadatokat is.
Elemzési írási műveletek: a tranzakciós tárolóból az elemzési tárba irányuló operatív adatfrissítések teljes körűen felügyelt szinkronizálása (automatikus szinkronizálás)
Elemzési olvasási műveletek: az Azure Synapse Analytics Spark-készletből az elemzési tárolón és a kiszolgáló nélküli SQL-készlet futási idejein végzett olvasási műveletek.
Az elemzési tár díjszabása eltér a tranzakciós tár díjszabási modelljétől. Az elemzési tárban nincs kiépített kérelemegység. Az elemzési tár díjszabási modelljének részletes leírását az Azure Cosmos DB díjszabási oldalán találja.
Az elemzési tár adatai csak az Azure Synapse Linken keresztül érhetők el, amely az Azure Synapse Analytics futtatókörnyezeteiben történik: Az Azure Synapse Apache Spark-készletek és az Azure Synapse kiszolgáló nélküli SQL-készletek. Az elemzési tár adatainak eléréséhez tekintse meg az Azure Synapse Analytics díjszabási oldalát a tarifamodellről.
Annak érdekében, hogy magas szintű költségbecslést kapjon egy Azure Cosmos DB-tároló elemzési tárának engedélyezéséhez, az elemzési tár szempontjából használhatja az Azure Cosmos DB Kapacitástervezőt , és megbecsülheti az elemzési tárolási és írási műveletek költségeit.
Az elemzési tár olvasási műveleteinek becslései nem szerepelnek az Azure Cosmos DB költségkalkulátorában, mivel ezek az elemzési számítási feladatok függvényei. Magas szintű becslésként azonban az elemzési tárban lévő 1 TB-os adatok vizsgálata általában 130 000 elemzési olvasási művelethez vezet, és 0,065 usd költséget eredményez. Ha például az Azure Synapse kiszolgáló nélküli SQL-készleteit használja az 1 TB-os vizsgálat elvégzéséhez, az 5,00 dollárba kerül az Azure Synapse Analytics díjszabási oldalának megfelelően. Az 1 TB-os vizsgálat végső teljes költsége 5,065 dollár lenne.
Míg a fenti becslés 1 TB adat elemzési tárolóban történő vizsgálatára vonatkozik, a szűrők alkalmazása csökkenti a beolvasott adatok mennyiségét, és ez határozza meg az elemzési olvasási műveletek pontos számát a fogyasztási díjszabási modell alapján. Az elemzési számítási feladatokra vonatkozó megvalósíthatósági igazolások részletesebb becslést nyújtanak az elemzési olvasási műveletekről. Ez a becslés nem tartalmazza az Azure Synapse Analytics költségeit.
Következő lépések
További információért tekintse meg a következő dokumentumokat:
Tekintse meg a hibrid tranzakciós és elemzési feldolgozás Azure Synapse Analytics használatával történő tervezésével kapcsolatos képzési modult
Az Azure Cosmos DB-hez készült Azure Synapse Link használatának első lépései
Gyakori kérdések az Azure Cosmos DB-hez készült Azure Synapse Linkkel kapcsolatban
Azure Cosmos DB-hez készült Azure Synapse Link használati esetek