Particionálás az Apache Cassandra-hoz készült Azure Cosmos DB-ben
A KÖVETKEZŐKRE VONATKOZIK: ![]() Cassandra
Cassandra
Ez a cikk azt ismerteti, hogyan működik a particionálás az Apache Cassandra-hoz készült Azure Cosmos DB-ben.
A Cassandra API particionálással skálázza az egyes táblákat egy kulcstérben az alkalmazás teljesítményigényének megfelelően. A partíciók a tábla egyes rekordjaihoz társított partíciókulcs értéke alapján jönnek létre. A partíció összes rekordja ugyanazzal a partíciókulcs-értékkel rendelkezik. Az Azure Cosmos DB transzparens módon és automatikusan kezeli a partíciók fizikai erőforrások közötti elhelyezését a tábla méretezhetőségének és teljesítményigényének hatékony kielégítése érdekében. Az alkalmazások átviteli sebességének és tárolási követelményeinek növekedésével az Azure Cosmos DB áthelyezi és kiegyensúlyozza az adatokat nagyobb számú fizikai gépen.
Fejlesztői szempontból a particionálás ugyanúgy működik az Apache Cassandra Azure Cosmos DB-jében, mint a natív Apache Cassandra esetében. Vannak azonban különbségek a színfalak mögött.
Különbségek az Apache Cassandra és az Azure Cosmos DB között
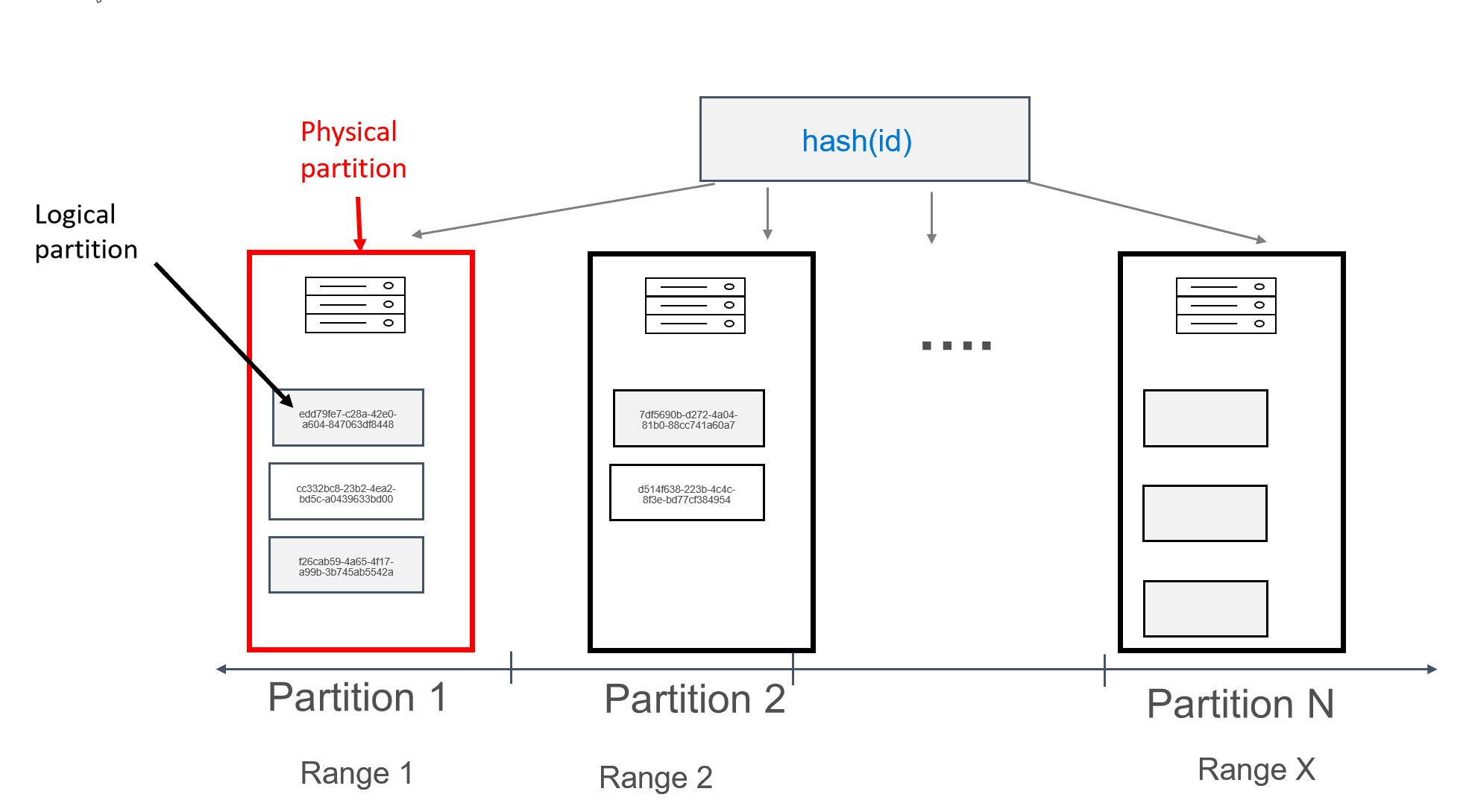
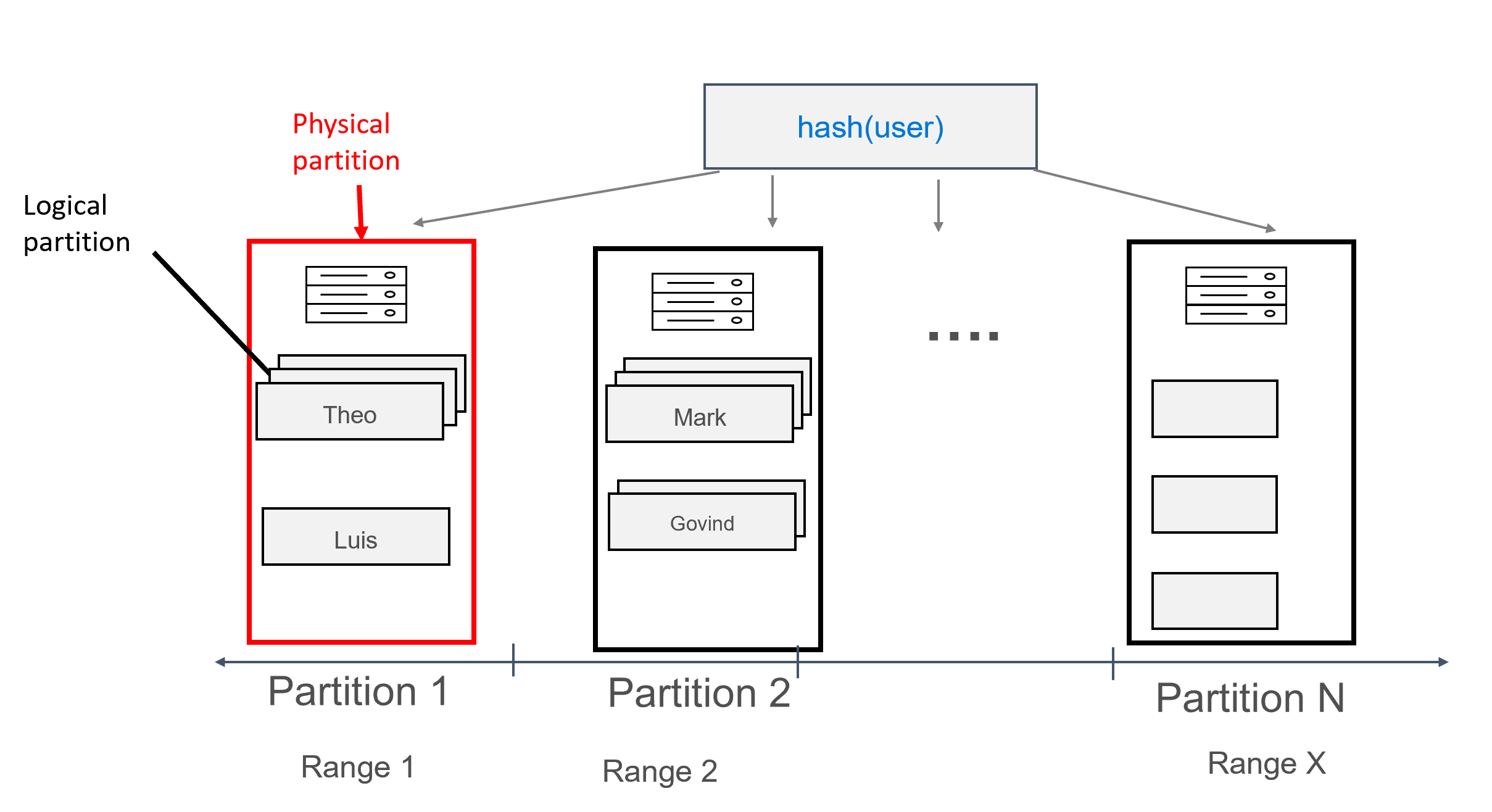
Az Azure Cosmos DB-ben minden olyan gép, amelyen a partíciókat tárolják, fizikai partíciónak nevezzük. A fizikai partíció hasonlít egy virtuális géphez; egy dedikált számítási egység vagy fizikai erőforrások készlete. A számítási egységben tárolt minden partíciót logikai partíciónak nevezünk az Azure Cosmos DB-ben. Ha már ismeri az Apache Cassandra-t, a logikai partíciók ugyanúgy gondolkodhatnak, mint a Cassandra normál partíciói.
Az Apache Cassandra 100 MB-os korlátot javasol a partíción tárolható adatok méretére vonatkozóan. Az Azure Cosmos DB-hez készült Cassandra API logikai partíciónként legfeljebb 20 GB, fizikai partíciónként pedig akár 30 GB adatot is lehetővé tesz. Az Azure Cosmos DB-ben az Apache Cassandrával ellentétben a fizikai partícióban elérhető számítási kapacitás egyetlen, kérelemegységnek nevezett metrika használatával van kifejezve, amely lehetővé teszi, hogy a számítási feladatokat másodpercenkénti kérések (olvasások vagy írások) szempontjából tekintse, nem pedig magokat, memóriát vagy IOPS-t. Így a kapacitástervezést egyszerűbbé teheti, ha már tisztában van az egyes kérések költségével. Minden fizikai partíció legfeljebb 10000 számítási kérelemegységet tartalmazhat. A méretezhetőségi lehetőségekről a Cassandra API rugalmas skálázásáról szóló cikkünkből tudhat meg többet.
Az Azure Cosmos DB-ben minden fizikai partíció replikák készletéből áll, más néven replikakészletekből, partíciónként legalább 4 replikával. Ez ellentétben áll az Apache Cassandra-sal, ahol 1-es replikációs tényező beállítása lehetséges. Ez azonban alacsony rendelkezésre álláshoz vezet, ha az adatokkal rendelkező egyetlen csomópont leáll. A Cassandra API-ban mindig 4 replikációs tényező van (3 kvórum). Az Azure Cosmos DB automatikusan kezeli a replikakészleteket, ezeket azonban az Apache Cassandra különböző eszközeivel kell karbantartani.
Az Apache Cassandra rendelkezik a tokenek fogalmával, amelyek a partíciókulcsok kivonatai. A jogkivonatok egy murmur3 64 bájtos kivonaton alapulnak, és -2^63 és -2^63 – 1 közötti értékeket tartalmaznak. Ezt a tartományt gyakran nevezik "token ringnek" az Apache Cassandra-ban. A jogkivonat-gyűrű jogkivonattartományokba van osztva, és ezek a tartományok a natív Apache Cassandra-fürtben található csomópontok között vannak elosztva. Az Azure Cosmos DB particionálása hasonló módon történik, kivéve, ha egy másik kivonatoló algoritmust használ, és nagyobb belső jogkivonat-gyűrűvel rendelkezik. Külsőleg azonban ugyanazt a tokentartományt tesszük elérhetővé, mint az Apache Cassandra, azaz -2^63–-2^63 – 1.
Elsődleges kulcs
A Cassandra API-ban minden táblának definiáltnak primary key kell lennie. Az elsődleges kulcs szintaxisa az alábbiakban látható:
column_name cql_type_definition PRIMARY KEY
Tegyük fel, hogy létre szeretnénk hozni egy felhasználói táblát, amely különböző felhasználók számára tárol üzeneteket:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
Ebben a tervben elsődleges kulcsként definiáltuk a id mezőt. Az elsődleges kulcs a tábla rekordjának azonosítójaként működik, és partíciókulcsként is használatos az Azure Cosmos DB-ben. Ha az elsődleges kulcs a korábban leírt módon van definiálva, az egyes partíciókban csak egyetlen rekord lesz. Ez tökéletesen vízszintes és méretezhető eloszlást eredményez, amikor adatokat ír az adatbázisba, és ideális kulcs-érték keresési használati esetekhez. Az alkalmazásnak meg kell adnia az elsődleges kulcsot, amikor adatokat olvas a táblából, hogy maximalizálja az olvasási teljesítményt.
Összetett elsődleges kulcs
Az Apache Cassandra a compound keys. Egy összetett primary key több oszlopból áll; az első oszlop a partition key, és minden további oszlop a clustering keys. A szintaxis compound primary key az alábbiakban látható:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Tegyük fel, hogy módosítani szeretnénk a fenti kialakítást, és lehetővé szeretnénk tenni az üzenetek hatékony lekérését egy adott felhasználó számára:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
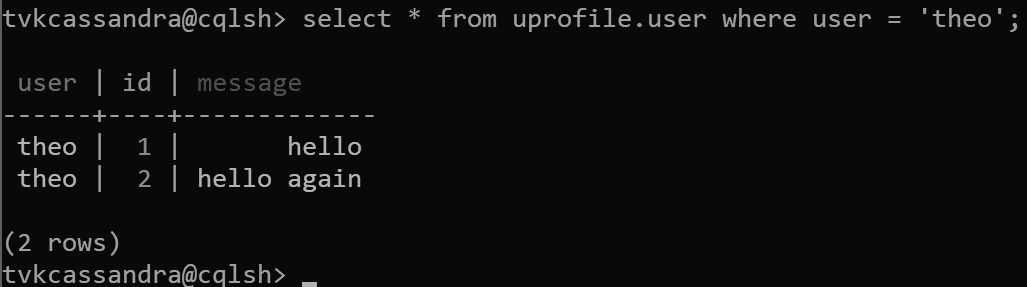
Ebben a kialakításban most partíciókulcsként és id fürtkulccsal határozzuk meguser. Tetszőleges számú fürtkulcsot definiálhat, de a fürtözési kulcs minden értékének (vagy értékkombinációjának) egyedinek kell lennie ahhoz, hogy több rekordot is hozzáadhasson ugyanahhoz a partícióhoz, például:
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Az adatok visszaadásakor a rendszer a fürtkulccsal rendezi az adatokat az Apache Cassandra által várt módon:
Figyelmeztetés
Ha összetett elsődleges kulccsal rendelkező táblában lévő adatok lekérdezésekor a partíciókulcsra és a fürtkulccon kívül más nem indexelt mezőkre szeretne szűrni, győződjön meg arról, hogy explicit módon hozzáad egy másodlagos indexet a partíciókulcshoz:
CREATE INDEX ON uprofile.user (user);
Az Apache Cassandra-hoz készült Azure Cosmos DB alapértelmezés szerint nem alkalmaz indexeket a partíciókulcsokra, és ebben a forgatókönyvben az index jelentősen javíthatja a lekérdezési teljesítményt. További információért tekintse át a másodlagos indexelésről szóló cikkünket.
Az ilyen módon modellezett adatokkal több rekord rendelhető hozzá minden partícióhoz, felhasználó szerint csoportosítva. Így kibocsáthatunk egy lekérdezést, amelyet hatékonyan irányít a (ebben az esetbenuser) az partition key adott felhasználó összes üzenetének lekéréséhez.
Összetett partíciókulcs
Az összetett partíciókulcsok lényegében ugyanúgy működnek, mint az összetett kulcsok, kivéve, hogy több oszlopot is megadhat összetett partíciókulcsként. Az összetett partíciókulcsok szintaxisa alább látható:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Például a következővel rendelkezhet, ahol a partíciókulcs egyedi kombinációja firstname és lastname formája, valamint id a fürtkulccsal is rendelkezhet:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Következő lépések
- További információ a particionálásról és a horizontális skálázásról az Azure Cosmos DB-ben.
- Ismerje meg a kiosztott átviteli sebességet az Azure Cosmos DB-ben.
- A globális terjesztés ismertetése az Azure Cosmos DB-ben.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: