Particionált gráfok használata az Azure Cosmos DB-ben
A KÖVETKEZŐKRE VONATKOZIK: ![]() Gremlin
Gremlin
Az Azure Cosmos DB Gremlin API-jának egyik fő funkciója a nagyméretű gráfok vízszintes skálázáson keresztüli kezelése. A tárolók a tárolás és az átviteli sebesség szempontjából egymástól függetlenül méretezhetők. Létrehozhat tárolókat az Azure Cosmos DB-ben, amelyek automatikusan skálázhatók gráfadatok tárolására. Az adatok automatikusan kiegyensúlyozottak a megadott partíciókulcs alapján.
A particionálás belsőleg történik, ha a tároló mérete várhatóan meghaladja a 20 GB-ot, vagy ha másodpercenként több mint 10 000 kérelemegységet (kérelemegységet) szeretne lefoglalni. Az adatok a megadott partíciókulcs alapján automatikusan particionálásra kerülnek. Partíciókulcsra akkor van szükség, ha gráftárolókat hoz létre az Azure Portalról, vagy a Gremlin-illesztőprogramok 3.x vagy újabb verzióiból. A Partíciókulcs nem szükséges, ha a Gremlin-illesztőprogramok 2.x vagy annál alacsonyabb verzióját használja.
Az Azure Cosmos DB particionálási mechanizmusának általános alapelvei az alábbiakban ismertetett néhány gráfspecifikus optimalizálással érvényesek.
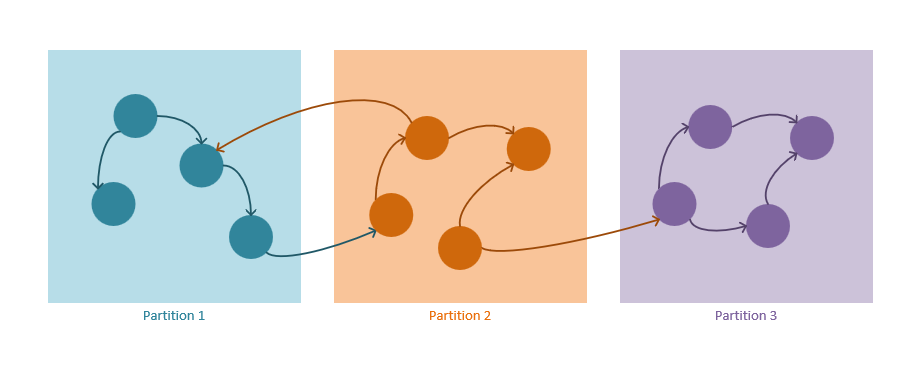
Gráfparticionálási mechanizmus
Az alábbi irányelvek az Azure Cosmos DB particionálási stratégiájának működését írják le:
Mind a csúcsok, mind az élek JSON-dokumentumokként vannak tárolva.
A csúcspontokhoz partíciókulcs szükséges. Ez a kulcs határozza meg, hogy melyik partícióban tárolja a csúcspontot egy kivonatoló algoritmus. A partíciókulcs tulajdonságának neve új tároló létrehozásakor van definiálva, és formátuma a következő:
/partitioning-key-name.Az élek a forrás csúcspontjukkal lesznek tárolva. Más szóval minden csúcshoz a partíciókulcs határozza meg, hogy hol vannak tárolva a kimenő élekkel együtt. Ez az optimalizálás a többpartíciós lekérdezések elkerülése érdekében történik, amikor a
out()számosságot gráfos lekérdezésekben használja.Az élek azokra a csúcsokra mutató hivatkozásokat tartalmaznak, amelyekre mutatnak. A rendszer minden élet az általuk mutató csúcsok partíciókulcsaival és azonosítóival tárol. Ez a számítás azt teszi lehetővé, hogy az irány
out()lekérdezései mindig hatókörrel rendelkező particionált lekérdezések legyenek, nem pedig vak partíciók közötti lekérdezések.A gráfos lekérdezéseknek meg kell adniuk egy partíciókulcsot. Az Azure Cosmos DB horizontális particionálásának teljes kihasználásához a partíciókulcsot egyetlen csúcs kijelölésekor kell megadni, amikor csak lehetséges. A particionált gráfok egy vagy több csúcsának kiválasztására szolgáló lekérdezések a következők:
/idés/labelnem támogatott partíciókulcsként a Gremlin API-ban lévő tárolókhoz.Válasszon ki egy csúcspontot azonosító szerint, majd a
.has()lépéssel adja meg a partíciókulcs tulajdonságát:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Csúcs kijelölése egy rekord megadásával, beleértve a partíciókulcs értékét és azonosítóját:
g.V(['partitionKey_value', 'vertex_id'])Csúcspontok halmazának kiválasztása az azonosítójukkal és a partíciókulcs-értékek listájának megadása:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)A partícióstratégia használata a lekérdezés elején, és egy partíció megadása a Gremlin-lekérdezés többi részének hatóköréhez:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Ajánlott eljárások particionált gráfok használatakor
A következő irányelvekkel biztosíthatja a teljesítményt és a méretezhetőséget particionált gráfok korlátlan tárolókkal való használatakor:
Csúcsok lekérdezésekor mindig adja meg a partíciókulcs értékét. A csúcspontok egy ismert partícióról való lekérése a teljesítmény elérésének egyik módja. Minden későbbi szomszédos művelet mindig egy partícióra lesz hatóköre, mivel az Edge-objektumok referenciaazonosítót és partíciókulcsot tartalmaznak a cél csúcspontjaikhoz.
Ha lehetséges, használja a kimenő irányt az élek lekérdezéséhez. Ahogy fentebb említettük, a rendszer a széleket a forrás csúcsaival együtt tárolja a kimenő irányban. Így a partíciók közötti lekérdezések alkalmazásának esélye minimálisra csökken, ha az adatokat és lekérdezéseket ezzel a mintával tervezték. Éppen ellenkezőleg, a
in()lekérdezés mindig egy drága kirakott lekérdezés lesz.Válasszon egy partíciókulcsot, amely egyenletesen osztja el az adatokat a partíciók között. Ez a döntés nagymértékben függ a megoldás adatmodellétől. További információ a megfelelő partíciókulcs létrehozásáról a particionálásban és a méretezésben az Azure Cosmos DB-ben.
Lekérdezések optimalizálása a partíciók határain belüli adatok lekéréséhez. Az optimális particionálási stratégia a lekérdezési mintákhoz igazodik. Az egyetlen partícióból adatokat lekérő lekérdezések a lehető legjobb teljesítményt nyújtják.
Következő lépések
Ezután a következő cikkeket olvashatja el:
- További információ a partícióról és a méretezésről az Azure Cosmos DB-ben.
- További információ a Gremlin API Gremlinhez való támogatásáról.
- Tudnivalók az API gremlinhez való bevezetéséről.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: