Jegyzet
Az oldalhoz való hozzáférés engedélyezést igényel. Próbálhatod be jelentkezni vagy könyvtárat váltani.
Az oldalhoz való hozzáférés engedélyezést igényel. Megpróbálhatod a könyvtár váltását.
Az Azure Cosmos DB egy sémafüggetlen adatbázis, amely lehetővé teszi az alkalmazás iterálását anélkül, hogy sémával vagy indexkezeléssel kellene foglalkoznia. Alapértelmezés szerint az Azure Cosmos DB automatikusan indexeli a tároló összes elemének minden tulajdonságát anélkül, hogy sémát kellene definiálnia vagy másodlagos indexeket kellene konfigurálnia.
Ez a cikk azt ismerteti, hogy az Azure Cosmos DB hogyan indexeli az adatokat, és hogyan használja az indexeket a lekérdezési teljesítmény javítása érdekében. Javasoljuk, hogy az indexelési szabályzatok testreszabása előtt tekintse át ezt a szakaszt.
Elemektől a fákig
Minden alkalommal, amikor egy elem tárolóban van tárolva, annak tartalma JSON-dokumentumként lesz kivetítve, majd faábrázolássá alakul. Ez az átalakítás azt jelenti, hogy az elem minden tulajdonsága csomópontként jelenik meg egy fán. A rendszer egy álgyökércsomópontot hoz létre szülőként az elem összes első szintű tulajdonságához. A levélcsomópontok tartalmazzák az elem által hordozott tényleges skaláris értékeket.
Vegyük például ezt az elemet:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
Ez a fa a JSON-példaelemet jelöli:
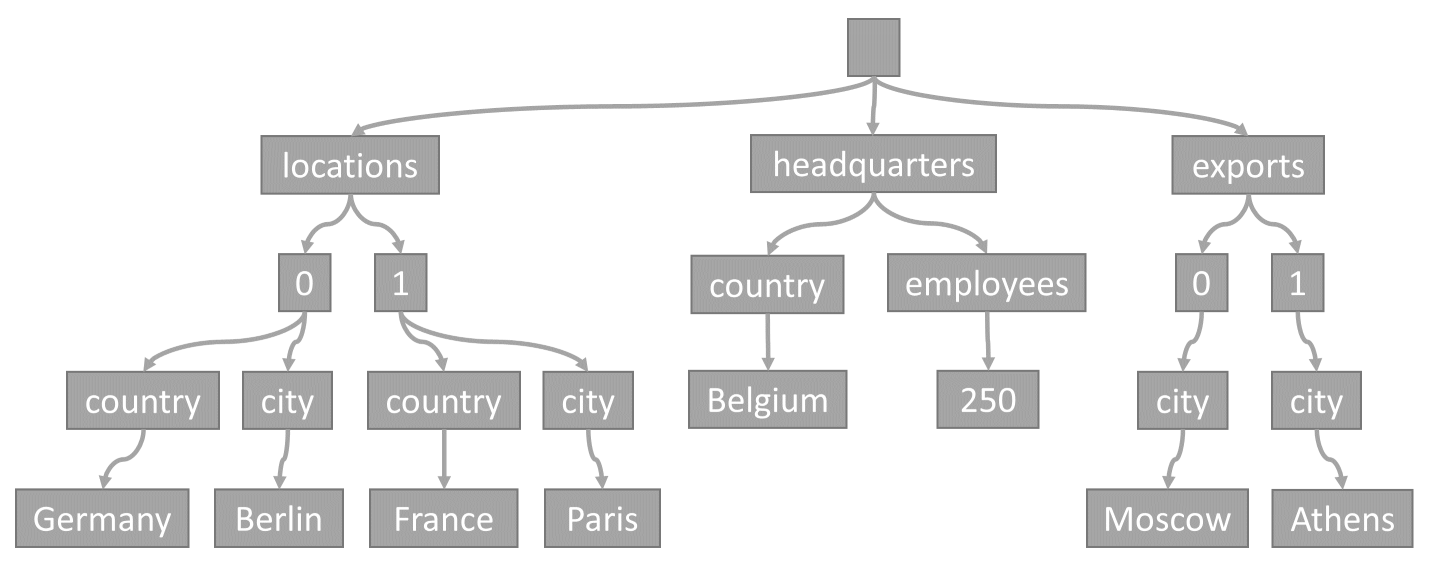
Figyelje meg, hogy a tömbök hogyan vannak kódolva a fában: egy tömb minden bejegyzése kap egy köztes csomópontot, amely a tömbön belül az adott bejegyzés indexével van megjelölve (0, 1 stb.).
Fáktól a tulajdonságútvonalakig
Az Azure Cosmos DB fákká alakítja az elemeket, mert lehetővé teszi a rendszer számára, hogy a fákon belüli elérési útjukkal hivatkozzon a tulajdonságokra. Egy tulajdonság elérési útjának lekéréséhez a gyökércsomóponttól az adott tulajdonságig bejárhatjuk a fát, és összefűzhetjük az egyes bejárt csomópontok címkéit.
Az egyes tulajdonságok elérési útjai a korábban ismertetett példaelemből származnak:
-
/locations/0/country: "Németország" -
/locations/0/city: "Berlin" -
/locations/1/country: "Franciaország" -
/locations/1/city: "Párizs" -
/headquarters/country: "Belgium" -
/headquarters/employees: 250 -
/exports/0/city: "Moszkva" -
/exports/1/city: "Athén"
Az Azure Cosmos DB hatékonyan indexeli az egyes tulajdonságok elérési útját és annak megfelelő értékét egy elem írásakor.
Indextípusok
Az Azure Cosmos DB jelenleg három indextípust támogat. Ezeket az indextípusokat az indexelési szabályzat meghatározásakor konfigurálhatja.
Tartományindex
A tartományindexek rendezett faszerű szerkezeten alapulnak. A tartományindex típusa a következőhöz használatos:
Egyenlőségi lekérdezések:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")Egyenlőségegyezés tömbelemen
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")Tartomány-lekérdezések:
SELECT * FROM container c WHERE c.property > 'value'Feljegyzés
A következőhöz használható:
>,<,>=,<=!=Tulajdonság jelenlétének ellenőrzése:
SELECT * FROM c WHERE IS_DEFINED(c.property)Karakterlánc-rendszerbeli függvények
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYLekérdezések:SELECT * FROM container c ORDER BY c.propertyJOINLekérdezések:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
A tartományindexek skaláris értékeken (sztringen vagy számon) használhatók. Az újonnan létrehozott tárolók alapértelmezett indexelési szabályzata minden sztring vagy szám esetében tartományindexeket kényszerít. A tartományindexek konfigurálásáról további információt az Indexelési szabályzatok kezelése az Azure Cosmos DB-ben című témakörben talál.
Feljegyzés
Az ORDER BY záradéknak, amely egyetlen tulajdonság szerint rendez, mindig szüksége van tartományindexre, és meghiúsul, ha az útvonal, amire hivatkozik, nem rendelkezik ilyennel. Hasonlóképpen, a ORDER BY több tulajdonsággal rendelést tartalmazó lekérdezésnek mindig összetett indexre van szüksége.
Térbeli index
A térbeli indexek hatékony lekérdezéseket tesznek lehetővé térinformatikai objektumokon, például pontokon, vonalakon, sokszögeken és többpógonyokon. Ezek a lekérdezések ST_DISTANCE, ST_WITHIN, ST_INTERSECTS kulcsszavakat használnak. Az alábbi példák térbeli indextípust használnak:
Térinformatikai távolságra vonatkozó lekérdezések:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40Térinformatika a lekérdezéseken belül:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })Térinformatikai metszet-lekérdezések:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
A térbeli indexek megfelelően formázott GeoJSON-objektumokon használhatók. A pontok, a LineStrings, a Sokszögek és a Többpoligonok jelenleg támogatottak. A térbeli indexek konfigurálásának megismeréséhez tekintse meg az Indexelési szabályzatok kezelése az Azure Cosmos DB-ben című témakört.
Összetett indexek
Az összetett indexek növelik a hatékonyságot, ha több mezőn hajt végre műveleteket. Az összetett indextípus a következő célokra használható:
ORDER BYlekérdezések több tulajdonságon:SELECT * FROM container c ORDER BY c.property1, c.property2Lekérdezések a szűrővel és
ORDER BYhasználatával. Ezek a lekérdezések összetett indexet használhatnak, ha a szűrőtulajdonság hozzá van adva aORDER BYzáradékhoz.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2Két vagy több tulajdonság szűrőjével rendelkező lekérdezések, ahol legalább egy tulajdonság egyenlőségszűrő:
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
Mindaddig, amíg egy szűrő predikátum az indextípusok egyikét használja, a lekérdezési motor először kiértékeli a többit. Például, ha van egy SQL-lekérdezése, mint például SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu"):
Ez a lekérdezés először kiszűri azokat a bejegyzéseket, ahol a firstName = "Andrew" az index használatával. Ezután átadja az összes firstName = "Andrew" bejegyzést egy későbbi folyamaton a CONTAINS szűrő predikátum kiértékeléséhez.
Felgyorsíthatja a lekérdezéseket, és elkerülheti a teljes tárolóvizsgálatot, ha olyan függvényeket használ, amelyek teljes vizsgálatot végeznek, például a CONTAINS-t. További szűrő predikátumokat is hozzáadhat, amelyek az index használatával felgyorsítják ezeket a lekérdezéseket. A szűrési záradékok sorrendje nem fontos. A lekérdezési motor kitalálja, hogy mely predikátumok szelektívebbek, és ennek megfelelően futtassa a lekérdezést.
Az összetett indexek konfigurálásáról az Indexelési szabályzatok kezelése az Azure Cosmos DB-ben című témakörben olvashat.
Vektorindexek
A vektorindexek növelik a hatékonyságot a vektorkeresések rendszerfüggvény használatával VectorDistance történő végrehajtásakor. A vektorkeresések jelentősen alacsonyabb késéssel, nagyobb átviteli sebességgel és kevesebb RU-használattal rendelkeznek vektorindex használata esetén. Az Azure Cosmos DB for NoSQL bármilyen vektoros beágyazást (szöveg, kép, multimodális stb.) támogat 4096 méret alatt.
A vektorindexek konfigurálásának megismeréséhez tekintse meg a vektorindexelési szabályzat példáit.
ORDER BYvektorkeresési lekérdezések:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)A vektorkeresési lekérdezések hasonlósági pontszámának előrejelzése:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)Tartományszűrők a hasonlósági pontszámon.
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
Fontos
A vektorszabályzatok és a vektorindexek jelenleg nem módosíthatók a létrehozás után. A módosítások elvégzéséhez hozzon létre egy új gyűjteményt.
Indexhasználat
A lekérdezési motor ötféleképpen értékelheti ki a lekérdezési szűrőket, a leghatékonyabb és a legkevésbé hatékony szerint rendezve:
- Indexkeresés
- Pontos indexvizsgálat
- Bővített indexvizsgálat
- Teljes indexvizsgálat
- Teljes vizsgálat
A tulajdonságútvonalak indexelésekor a lekérdezési motor automatikusan a lehető leghatékonyabban használja az indexet. Az új tulajdonságútvonalak indexelése mellett semmit sem kell konfigurálnia az index használatának optimalizálásához. A lekérdezések RU-díja az indexhasználatból származó RU-díj és az elemek betöltéséből származó RU-díj kombinációja.
Az alábbi táblázat az Azure Cosmos DB-ben használt indexek különböző felhasználási módjait foglalja össze:
| Indexkeresés típusa | Leírás | Gyakori példák | RU-díj az indexhasználatból | A tranzakciós adattárból származó elemek betöltésekor felmerülő RU-díjak |
|---|---|---|---|---|
| Indexkeresés | Olvassa el csak a szükséges indexelt értékeket, és töltsön be csak az egyező elemeket a tranzakciós adattárból. | Egyenlőségi szűrők, IN | Egyenlőségi szűrőnkénti állandó | A lekérdezési eredményekben szereplő elemek száma alapján növekszik |
| Pontos indexvizsgálat | Indexelt értékek bináris keresése, és csak a tranzakciós adattárból származó egyező elemek betöltése | Tartomány-összehasonlítások (>, <, <= vagy >=), StartsWith | Az indexkereséshez hasonlóan, az indexelt tulajdonságok számossága alapján kissé növekszik. | A lekérdezési eredményekben szereplő elemek száma alapján növekszik |
| Bővített indexvizsgálat | Indexelt értékek optimalizált (de bináris keresésnél kevésbé hatékony) keresés, és csak a tranzakciós adattárból származó egyező elemek betöltése | StartsWith (kis- és nagybetűket nem különbözteti meg), StringEquals (kis- és nagybetűket nem különbözteti meg) | Az indexelt tulajdonságok számossága alapján kissé nő | A lekérdezési eredményekben szereplő elemek száma alapján növekszik |
| Teljes indexvizsgálat | Eltérő indexelt értékek olvasása és csak a tranzakciós adattárból származó egyező elemek betöltése | Tartalmazza, Végződik, RegexEgyezés, LIKE | Lineáris növekedés az indexelt tulajdonságok számossága alapján | A lekérdezési eredményekben szereplő elemek száma alapján növekszik |
| Teljes vizsgálat | Az összes elem betöltése a tranzakciós adattárból | Felső, Alsó | n/a | A tárolóban lévő elemek száma alapján növekszik |
Lekérdezések írásakor olyan szűrő predikátumokat kell használnia, amelyek a lehető leghatékonyabban használják az indexet. Ha például vagy StartsWith, vagy Contains megfelel a használati esetnél, érdemes a StartsWith-t választani, mivel az pontos indexvizsgálatot végez a teljes indexvizsgálat helyett.
Indexhasználat részletei
Ez a szakasz további részleteket tartalmaz arról, hogy a lekérdezések hogyan használják az indexeket. Ez a részletességi szint nem szükséges az Azure Cosmos DB használatának megkezdéséhez, de a kíváncsi felhasználók számára részletesen dokumentálva van. A dokumentum korábbi részében megosztott példaelemre hivatkozunk:
Példaelemek:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Az Azure Cosmos DB fordított indexet használ. Az index úgy működik, hogy megfelelteti az egyes JSON-elérési utakat az adott értéket tartalmazó elemek készletének. Az elemazonosító leképezése a tároló különböző indexoldalain jelenik meg. Az alábbi mintadiagram egy olyan tároló invertált indexét mutatja be, amely a két példaelemet tartalmazza:
| Elérési útvonal | Érték | Elemazonosítók listája |
|---|---|---|
| /helyszínek/0/ország | Németország | 1 |
| /helyszínek/0/ország | Írország | 2 |
| /locations/0/város | Berlin | 1 |
| /locations/0/város | Dublin | 2 |
| /locations/1/country | Franciaország | 1 |
| /helyszinek/1/varos | Párizs | 1 |
| /székhely/ország | Belgium | 1, 2 |
| /székhely/alkalmazottak | 200 | 2 |
| /székhely/alkalmazottak | 250 | 1 |
Az invertált index két fontos attribútummal rendelkezik:
- Egy adott elérési út esetében az értékek növekvő sorrendben vannak rendezve. Ezért a lekérdezési motor könnyen képes kiszolgálni
ORDER BYaz indexből. - Egy adott elérési út esetében a lekérdezési motor a lehetséges értékek különböző halmazán keresztül vizsgálhatja azokat az indexlapokat, ahol vannak eredmények.
A lekérdezési motor négy különböző módon tudja használni az invertált indexet:
Indexkeresés
Fontolja meg a következő lekérdezést:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
A lekérdezési predikátum (olyan elemek szűrése, ahol bármely hely "Franciaország" országként vagy régióként szerepel) megfelelne az ábrán kiemelt útvonalnak:
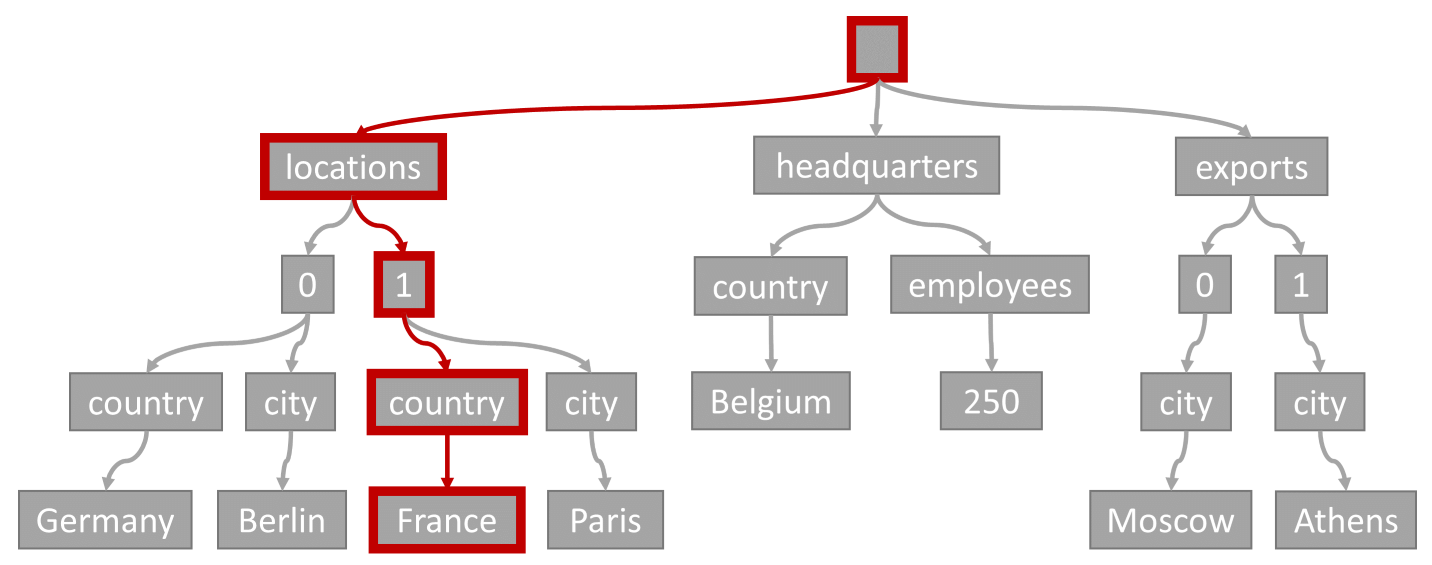
Mivel a lekérdezés egyenlőségszűrővel rendelkezik, a fa bejárása után gyorsan azonosíthatjuk a lekérdezés eredményeit tartalmazó indexoldalakat. Ebben az esetben a lekérdezési motor felolvassa az 1. elemet tartalmazó indexoldalakat. Az indexkeresés a leghatékonyabb módszer az index használatára. Az indexkereséssel csak a szükséges indexoldalakat olvassuk be, és csak a lekérdezés eredményében szereplő elemeket töltjük be. Ezért az indexkeresési idő és az indexkeresés ru-díja hihetetlenül alacsony, függetlenül a teljes adatmennyiségtől.
Pontos indexvizsgálat
Fontolja meg a következő lekérdezést:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
A lekérdezési predikátum (a több mint 200 alkalmazottat tartalmazó elemek szűrése) az elérési út pontos indexvizsgálatával headquarters/employees értékelhető ki. A pontos indexvizsgálat során a lekérdezési motor az érték 200 helyét keresi a headquarters/employees útvonalon, a lehetséges értékek megkülönböztetett készletének bináris keresésével. Mivel az egyes elérési utak értékei növekvő sorrendben vannak rendezve, a lekérdezési motor egyszerűen hajthat végre bináris keresést. Miután a lekérdezési motor megtalálta az értéket 200, megkezdi az összes fennmaradó indexoldal olvasását (növekvő irányban haladva).
Mivel a lekérdezési motor képes bináris keresésre a szükségtelen indexlapok vizsgálatának elkerülése érdekében, a pontos indexvizsgálatok általában hasonló késéssel és RU-díjakkal járnak az indexkeresési műveletekhez.
Bővített indexvizsgálat
Fontolja meg a következő lekérdezést:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
A lekérdezési predikátum (az elemek szűrése olyan helyen, amelynek székhelye kis- és nagybetűktől függetlenül "United"-del kezdődik) a headquarters/country út kibővített indexvizsgálatával értékelhető ki. A bővített indexvizsgálatot végező műveletek optimalizálása segít elkerülni, hogy minden indexlapot beolvassunk, de valamivel drágábbak, mint egy pontos indexvizsgálat bináris keresése.
A kis- és nagybetűk érzéketlen StartsWithkiértékelésekor például a lekérdezési motor ellenőrzi az indexet a kis- és nagybetűk különböző lehetséges kombinációihoz. Ez az optimalizálás lehetővé teszi a lekérdezési motor számára, hogy elkerülje a legtöbb indexlap olvasását. A különböző rendszerfüggvények különböző optimalizálásokkal rendelkeznek, amelyekkel elkerülhetik az összes indexlap olvasását, így széles körben kiterjesztett indexvizsgálatként vannak kategorizálva.
Teljes indexvizsgálat
Fontolja meg a következő lekérdezést:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
A lekérdezési predikátum (azoknak az elemeknek a szűrése, amelyek központja egy "United" szót tartalmazó helyen található) az headquarters/country útvonal indexelt bejárásával értékelhető ki. A pontos indexvizsgálattól eltérően a teljes indexvizsgálat mindig a lehetséges értékek különböző halmazán halad végig, hogy azonosítsa azokat az indexoldalakat, ahol vannak eredmények. Ebben az esetben CONTAINS fut az indexen. Az indexkeresési idő és az indexvizsgálatok RU-díja az elérési út kardinalitásának növekedésével nő. Más szóval minél több különböző értéket kell a lekérdezési motornak megvizsgálnia, annál nagyobb a késés és a teljes indexvizsgálathoz szükséges ru-díj.
Vegyük például két tulajdonságot: town és country. A város népessége 5000, a country népessége pedig 200. Íme két példa lekérdezés, amelyek mindegyike tartalmaz egy olyan rendszerfüggvényt , amely teljes indexvizsgálatot végez a town tulajdonságon. Az első lekérdezés több kérelemegységet használ, mint a második lekérdezés, mert a város számossága magasabb, mint country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
Teljes vizsgálat
Bizonyos esetekben előfordulhat, hogy a lekérdezési motor nem tudja kiértékelni a lekérdezésszűrőt az index használatával. Ebben az esetben a lekérdezési motornak be kell töltenie az összes elemet a tranzakciós tárolóból a lekérdezésszűrő kiértékeléséhez. A teljes átvizsgálások nem használják az indexet, és a teljes adatmérettel lineárisan növekvő RU-díjat számítanak fel. Szerencsére a teljes vizsgálatot igénylő műveletek ritkák.
Vektorkeresési lekérdezések definiált vektorindex nélkül
Ha nem határoz meg vektorindex-szabályzatot, és a VectorDistance rendszerfüggvényt egy ORDER BY záradékban használja, akkor ez teljes vizsgálatot eredményez, és a vektorindex-szabályzatnál magasabb ru-díjjal rendelkezik. Ha a VectorDistance brute force logikai értéke igaz értékre van állítva, és nincs flat index definiálva a vektorútvonalhoz, akkor teljes vizsgálat történik.
Összetett szűrőkifejezéseket tartalmazó lekérdezések
A korábbi példákban csak olyan lekérdezéseket vettünk figyelembe, amelyek egyszerű szűrőkifejezésekkel rendelkeztek (például egyetlen egyenlőség- vagy tartományszűrővel rendelkező lekérdezések). A valóságban a legtöbb lekérdezés sokkal összetettebb szűrőkifejezésekkel rendelkezik.
Fontolja meg a következő lekérdezést:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
A lekérdezés végrehajtásához a lekérdezési motornak indexkeresést kell végeznieheadquarters/employees, és teljes indexvizsgálatot kell végeznie.headquarters/country A lekérdezési motor belső heurisztikusokkal rendelkezik, amelyekkel a lekérdezésszűrő kifejezés a lehető leghatékonyabban kiértékelhető. Ebben az esetben a lekérdezési motornak nem kell elolvasnia a szükségtelen indexoldalakat az indexkeresés első lépésével. Ha például csak 50 elem felelt meg az egyenlőségi szűrőnek, a lekérdezési motornak csak az 50 elemet tartalmazó indexlapokon kell kiértékelnie CONTAINS . Nincs szükség a tároló teljes indexvizsgálatára.
Skaláris összesítő függvények indexkihasználtsága
Az aggregátumfüggvényeket tartalmazó lekérdezések csak az indexre támaszkodhatnak a használatukhoz.
Bizonyos esetekben az index hamis pozitív értékeket adhat vissza. Az index kiértékelésekor CONTAINS például az indexben lévő egyezések száma meghaladhatja a lekérdezési eredmények számát. A lekérdezési motor betölti az összes index egyezést, kiértékeli a szűrőt a betöltött elemeken, és csak a megfelelő eredményeket adja vissza.
A legtöbb lekérdezés esetében a hamis pozitív index-egyezések betöltése nem befolyásolja az index kihasználtságát.
Lásd példaként az alábbi lekérdezést:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Előfordulhat, hogy a CONTAINS rendszerfüggvény hamis pozitív egyezéseket ad vissza, ezért a lekérdezési motornak ellenőriznie kell, hogy minden betöltött elem megfelel-e a szűrőkifejezésnek. Ebben a példában előfordulhat, hogy a lekérdezési motornak csak néhány további elemet kell betöltenie, így az index kihasználtságára és a kérelemegység-terhelésre gyakorolt hatás minimális.
Az aggregátumfüggvényeket tartalmazó lekérdezések azonban kizárólag az indexre támaszkodhatnak a használatukhoz. Vegyük például a következő lekérdezést összesítéssel COUNT :
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Az első példához hasonlóan a CONTAINS rendszerfüggvény is visszaadhat néhány hamis pozitív egyezést. A SELECT * lekérdezéssel ellentétben azonban a COUNT lekérdezés nem tudja kiértékelni a betöltött elemek szűrőkifejezését az összes index egyezésének ellenőrzéséhez. A COUNT lekérdezésnek kizárólag az indexre kell támaszkodnia, így ha van rá esély, hogy egy szűrőkifejezés hamis pozitív egyezéseket ad vissza, a lekérdezési motor teljes vizsgálathoz folyamodik.
Az alábbi összesítő függvényekkel rendelkező lekérdezések kizárólag az indexre támaszkodhatnak, ezért egyes rendszerfüggvények kiértékeléséhez teljes vizsgálatra van szükség.